原文链接
1. 感受野(Receptive Field)
感受野指的是卷积神经网络每一层输出的特征图(feature map)上每个像素点映射回输入图像上的区域大小,神经元感受野的范围越大表示其能接触到的原始图像范围就越大,也意味着它能学习更为全局,语义层次更高的特征信息,相反,范围越小则表示其所包含的特征越趋向局部和细节。因此感受野的范围可以用来大致判断每一层的抽象层次,并且我们可以很明显地知道网络越深,神经元的感受野越大
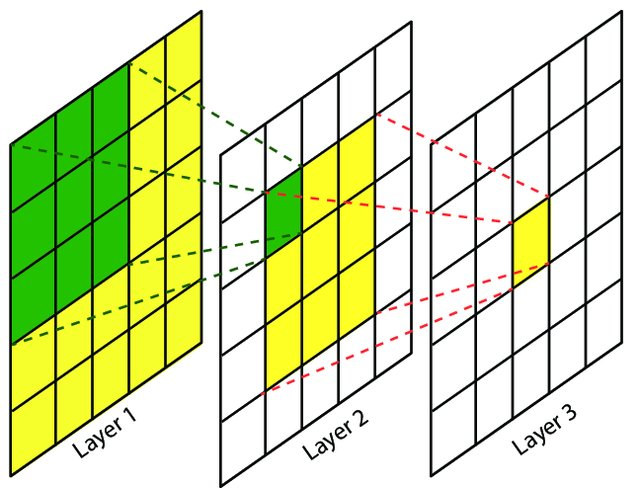
2. 计算公式
2.1从后往前
- 初始feature map层的感受野是1
- 每经过一个convkxk s=1的卷积层,感受野 r = r + (k - 1),常用k=3感受野 r = r + 2, k=5感受野r = r + 4
- 每经过一个convkxk s=2的卷积层或max/avg pooling层,感受野 r = (r x 2) + (k -2),常用卷积核k=3, s=2,感受野 r = r x 2 + 1,卷积核k=7, s=2, 感受野r = r x 2 + 5
- 每经过一个maxpool2x2 s2的max/avg pooling下采样层,感受野 r = r x 2
- 特殊情况,经过conv1x1 s1不会改变感受野,经过FC层和GAP层,感受野就是整个输入图像
- 经过多分枝的路径,按照感受野最大支路计算,shotcut也一样所以不会改变感受野
- ReLU, BN,dropout等元素级操作不会影响感受野
- 全局步进等于经过所有层的步进累乘,
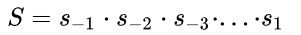
- 经过的所有层所加padding都可以等效加在输入图像,等效值P,直接用卷积的输入输出公式
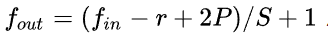 反推出P即可
反推出P即可
2.2从前往后
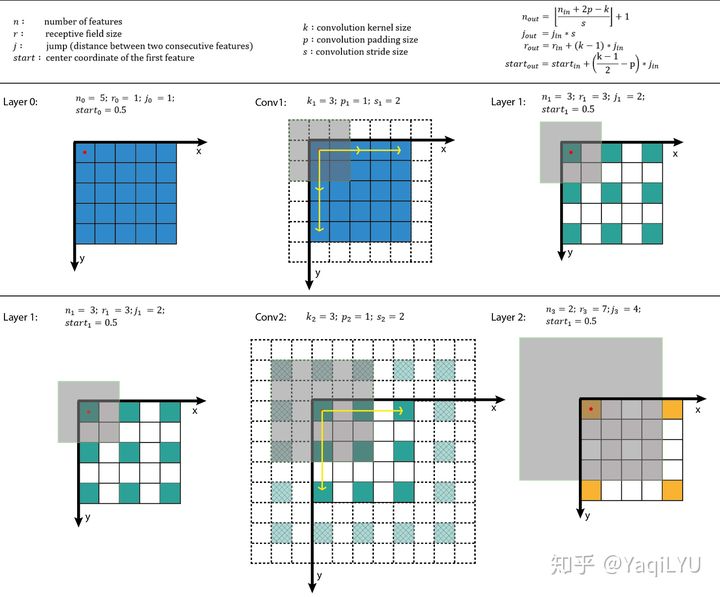
3.案例
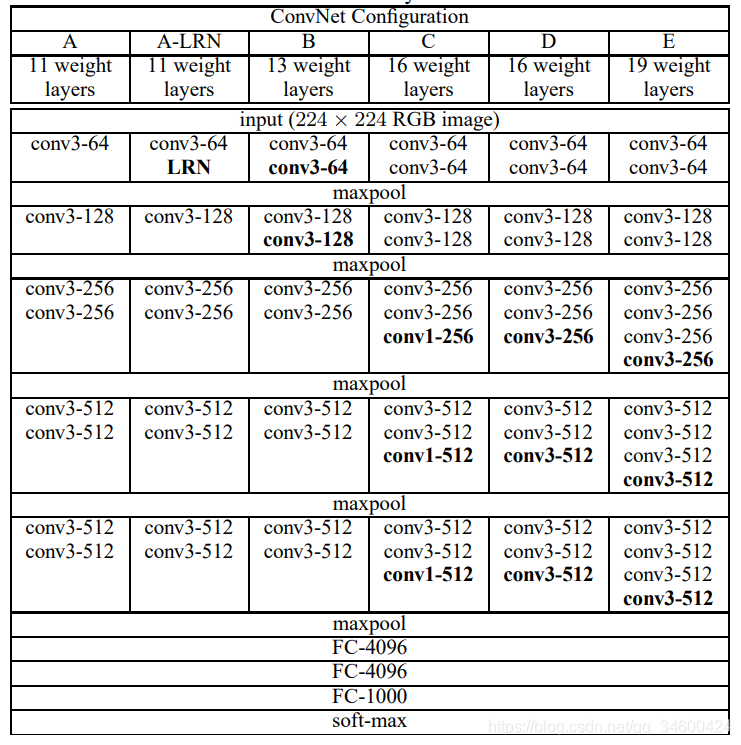
先来计算SSD中第一个feature map输出层的感受野,结构是conv4-3 backbone + conv3x3 classifier (为了写起来简单省掉了左边括号):
r = 1 + 2 + 2+ 2+ 2 ) x 2 + 2 + 2 + 2) x 2 + 2 + 2) x 2 + 2 + 2 = 108S = 2 x 2 x 2 = 8P = floor(r/2 - 0.5) = 53
以上结果表示感受野的分布方式是:
在paddding=53(上下左右都加) 的输入224x224图像上,大小为108x108的正方形感受野区域以stride=8平铺。
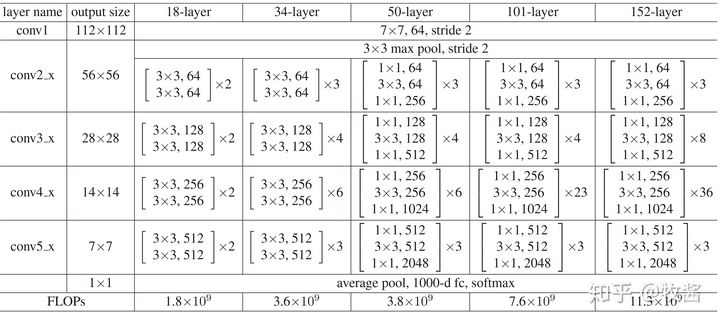
renet-50中conv2_3步长全为1,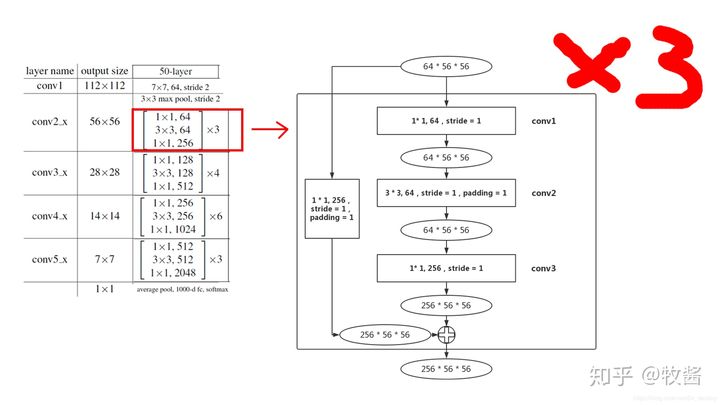
conv3,conv4,conv5第一个块block中的3x3卷积核步长为2其余都为1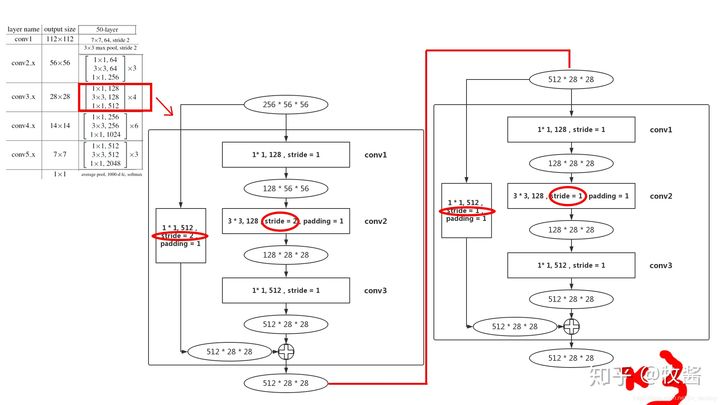
Faster R-CNN+++和R-FCN等采用的重要backbone的ResNet,常见ResNet-50和ResNet-101,结构特点是block由conv1x1+conv3x3+conv1x1构成,下采样block中conv3x3 s2影响感受野。先计算ResNet-50在conv4-6 + RPN的感受野 (为了写起来简单堆叠卷积层合并在一起):
r = 1 +2 +2x5 )x2+1 +2x3 )x2+1 +2x3 )x2+1 )x2+5 = 299S = 2x2x2x2 = 16P = floor(r/2 - 0.5) = 149
P不是整数,表示conv7x7 s2卷积有多余部分。分布方式为在paddding=149的输入224x224图像上,大小为299x299的正方形感受野区域以stride=16平铺。
4.结论
- 步进1的卷积层线性增加感受野,深度网络可以通过堆叠多层卷积增加感受野
- 步进2的下采样层乘性增加感受野,但受限于输入分辨率不能随意增加
- 步进1的卷积层加在网络后面位置,会比加在前面位置增加更多感受野,如stage4加卷积层比stage3的感受野增加更多
- 深度CNN的感受野往往是大于输入分辨率的,如上面ResNet-101的843比输入分辨率大3.7倍
- 深度CNN为保持分辨率每个conv都要加padding,所以等效到输入图像的padding非常大

若有收获,就点个赞吧
0 人点赞
