1. faster RCNN
faster RCNN作为two stage目标检测的代表,在RPN层和最后的分类回归时均有使用到boundingbox regression(BBR),RPN层相当于对anchor出来的候选框做初筛,选出其中的1000个框,再对1000个框做二次筛选,进一步回归和分类。
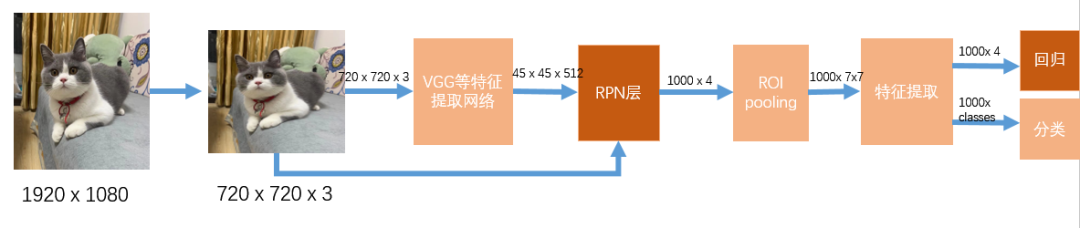
在介绍BBR之前先理解下目标检测中的anchor机制。anchor称为锚框,它是固定的大小不同的框,后续的框回归是基于anchor框,通过神经网络预测出的偏移量去变换位置和大小,但anchor本身是不变的
目标检测任务需要将目标在图片中的位置框出来,那怎么找到这个位置呢,faster RCNN提出了anchor机制,具体来说,在特征提取,720x720大小的图片,下采样成45x45x512,不考虑通道数,45x45对应到原图上,每个框的感受野为16x16:

以每个框的中心点为坐标,faster RCNN中anchor框有9个,基于每个框中心点生成9个anchor框,对整张图片有45x45x9个候选框了,对于每个候选框来说,他一般不能直接框到目标,所以需要对框做修正。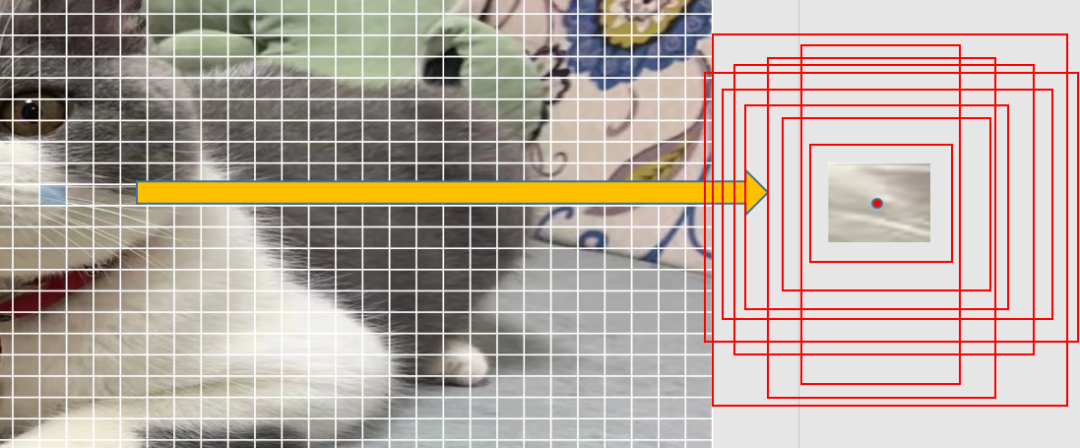

所以在RPN层中特征提取后,分成两路,一路生成454518,对45459个框做前后背景的分类(前后背景分类每个Anchor需要2个信息),另一路对45459个框做回归(回归每个Anchor需要4个信息,中心坐标偏移量和宽高)。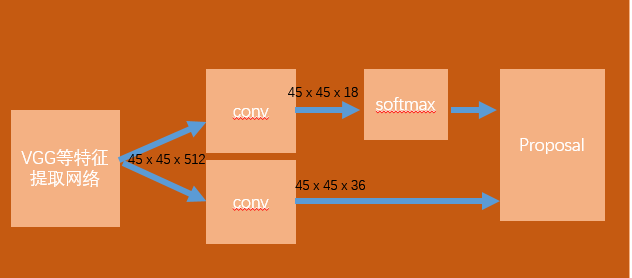

怎么回归呢,能不能直接回归呢?比如上图中cat的框左上角坐标为(100,60),右下角坐标为(600,640),能不能直接学习回归到这两个坐标上呢,答案当然是不能的,不然也不至于兜兜转转。主要原因在我们信息提取使用的是CNN卷积,卷积具有平移不变性和旋转不变性。

如上图,这里默认CNN提取特征为两只猫的特征是一样的,边框回归同函数求解一样,输入一个值,给出一个解,现在输入两个相同的特征,输出的坐标值应该是一样的,无法满足输出两个坐标框的要求,那怎样基于两个相同的特征输出相同的值,怎么对应到两个坐标上呢?通过相对坐标,相对于候选框。候选框的位置和大小不一样所以对应的相对坐标的位置和大小也就不一样了,完美解决了基于相同特征虽然输出相同的值,但是最后回归到不同位置和长宽的问题。
怎么基于候选框学习相对坐标?faster RCNN中,基于anchor框先做中心点的平移再做长宽的缩放。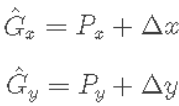
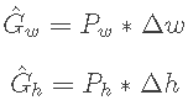


如上公式,其中 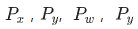 为候选框的坐标与长宽,
为候选框的坐标与长宽,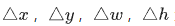 为要偏移和缩放的值,这些值没有直接按照绝对坐标值回归,而是基于相对坐标,根据下述公式得到:
为要偏移和缩放的值,这些值没有直接按照绝对坐标值回归,而是基于相对坐标,根据下述公式得到: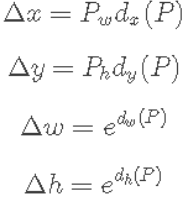
P为特征输出,本文中为vgg特征提取网络的最后一层输出, 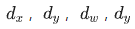 即为要学习的中心点相对回归值,其原因有两点:一是考虑到训练,候选框和gt框的大小差异大,相对的值更容易收敛;二是对于长宽的缩放值,一定是大于0的值,所以使用exp函数保证,整体上看:
即为要学习的中心点相对回归值,其原因有两点:一是考虑到训练,候选框和gt框的大小差异大,相对的值更容易收敛;二是对于长宽的缩放值,一定是大于0的值,所以使用exp函数保证,整体上看:
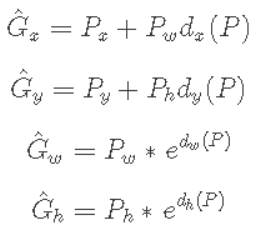
但是我们发现这里学习到的是 与真实的Groudtruth之间还有差距:
这里是理想表达,意思是理想情况下我们应该学习到groudtruth,使得候选框能够回归到gt上,在实际学习中,一般只能学习到 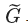 与gt接近,即可默认为训练成功。所以在测试时,根据模型学习的权重得到信息提取特征P,基于学习的权重值得到
与gt接近,即可默认为训练成功。所以在测试时,根据模型学习的权重得到信息提取特征P,基于学习的权重值得到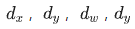 ,再根据映射到原图上的anchor得到的候选框对各个框平移缩放,得到 的预测框。
,再根据映射到原图上的anchor得到的候选框对各个框平移缩放,得到 的预测框。
在训练的时候,则是通过缩小GT与anchor生成的proposal之间的gap,完成训练,因为要学习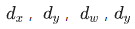 ,所以将上述公式翻过来写下:
,所以将上述公式翻过来写下: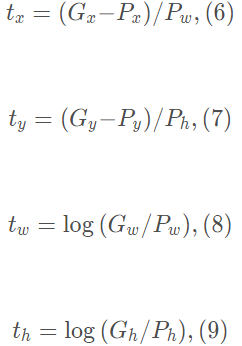
为了与学习到的最终权值区分开,这里用 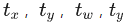 代替
代替 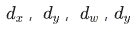 实际上指的是一个东西。通过loss对其监督学习,得到bbox的回归。
实际上指的是一个东西。通过loss对其监督学习,得到bbox的回归。
2. Yolov2/3/4
Yolov2,v3和v4的BBR策略一样,均是基于anchor回归bbox的,这里只讲Yolov3, 与faster RCNN不同的是,其长宽的回归策略一样,坐标点的回归策略不同。faster RCNN通过候选框的中心点回归的,v3是预测anchor中心点所对应的grid单元格,相对其左上角坐标的偏移,如下图: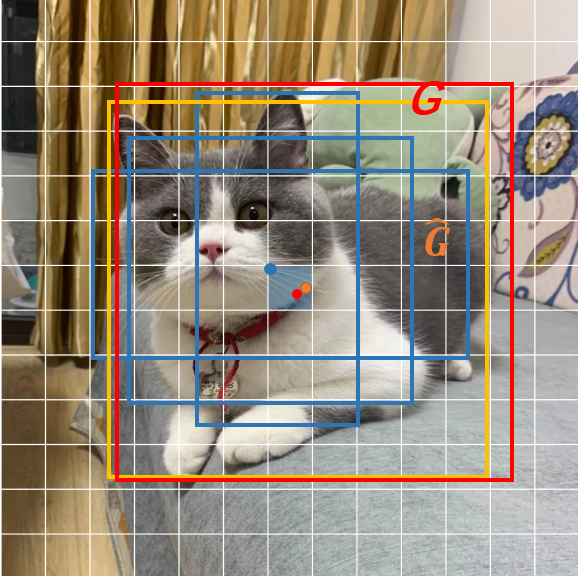
如下图,其中  为anchor的长宽,
为anchor的长宽, 为该grid离图片左上角的距离
为该grid离图片左上角的距离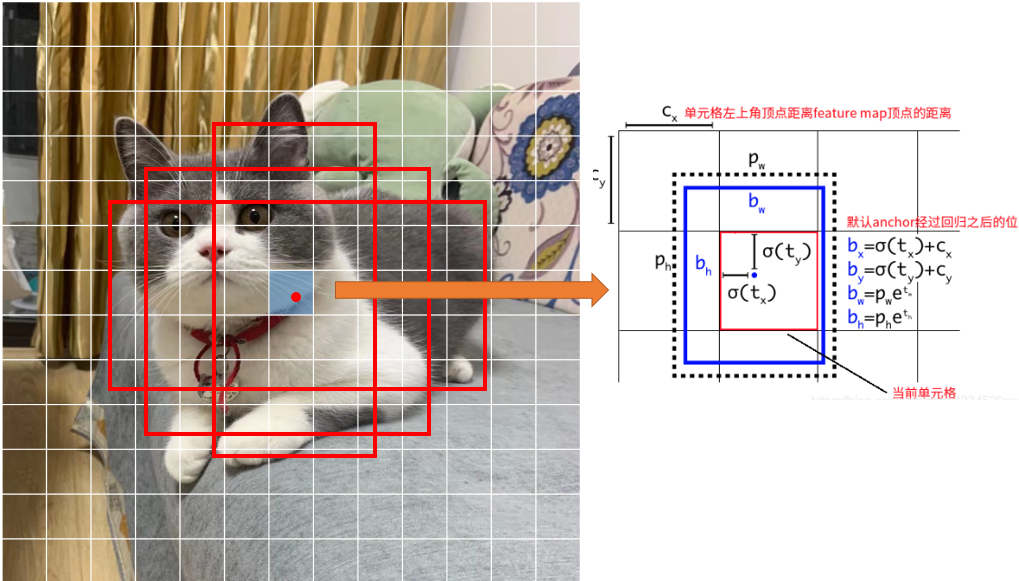
anchor回归时,长宽回归同faster RCNN,中心点回归不是基于anchor中心点,而是基于所在grid左上角坐标的偏移值,偏移值也是相对于grid长宽的一个相对值,怎么样知道用哪个grid呢,yolov3 有三个网络层,对应9个anchor,从小到大,三个anchor对应一个网络层,在训练时,先计算anchor与gt的IOU(计算IOU值时不考虑坐标,只考虑形状,因为anchor没有坐标xy信息,所以先将anchor与ground truth的中心点都移动到同一位置(原点),然后计算出对应的IOU值,即计算所有Anchor和GT的IOU),IOU值最大的那个先验框anchor与ground truth匹配(正样本),该anchor所对应的网络层用来训练该gt,该gt的中心点落在该网络层的哪个grid上,对应grid上的之前IOU匹配最大的那个anchor作为正样本,训练预测这个ground truth。(这与faster RCNN中训练时,只要与gt的IOU大于阈值的均为正样本不同,yolov3 训练的正样本为与gt IOU值最大的那个anchor).
在推理时,根据模型学习的权重得到信息提取特征P,基于学习的权重值得到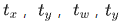 ,为了将边界框中心点约束在当前网格中,使用sigmoid函数来处理偏移值,使预测偏移值在(0,1)范围内,即保证中心点在该grid范围内,得到
,为了将边界框中心点约束在当前网格中,使用sigmoid函数来处理偏移值,使预测偏移值在(0,1)范围内,即保证中心点在该grid范围内,得到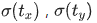 ,再根据映射到原图上的anchor得到的候选框对各个框缩放,长宽缩放使用exp函数的原因同faster RCNN,得到大量的预测框,如上图所示将得到13133个候选框,再通过后处理过滤得到 的预测框。所以在yolov3中BBR中,只有回归的长宽与anchor的长宽有关,回归的坐标回归与grid有关。
,再根据映射到原图上的anchor得到的候选框对各个框缩放,长宽缩放使用exp函数的原因同faster RCNN,得到大量的预测框,如上图所示将得到13133个候选框,再通过后处理过滤得到 的预测框。所以在yolov3中BBR中,只有回归的长宽与anchor的长宽有关,回归的坐标回归与grid有关。
3. Yolov5
Yolov5的BBR与yolov2/3/4的稍有不同: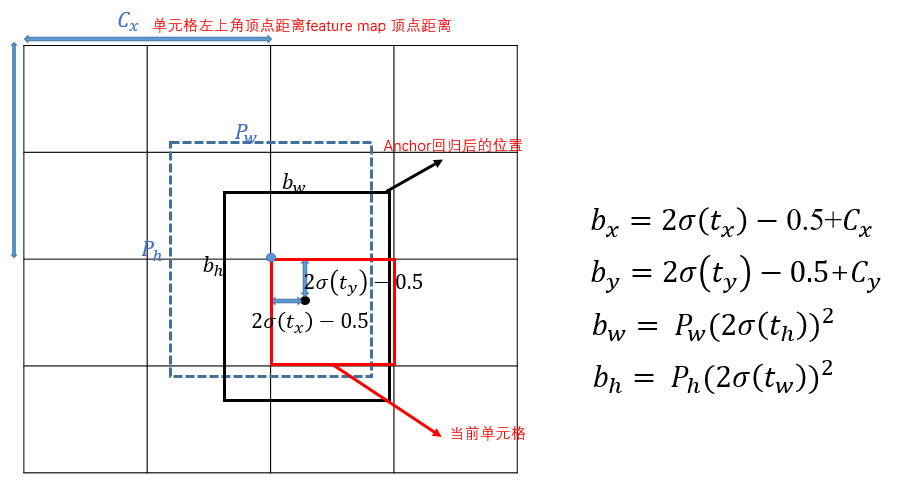
这里也是要预测偏移量 ,但与yolov2/3/4有以下几点不同:
,但与yolov2/3/4有以下几点不同:
- 宽高的计算:相对于Yolov2/3/4只对
 进行sigmoid函数处理,对
进行sigmoid函数处理,对 不进行sigmoid函数处理,yolov5的
不进行sigmoid函数处理,yolov5的 要经过sigmoid函数处理,同时对
要经过sigmoid函数处理,同时对 进行2倍的sigmoid,宽高的回归也从之前的exp函数改成
进行2倍的sigmoid,宽高的回归也从之前的exp函数改成 ,主要原因是在于作者认为原始的yolo /darknet框方程式存在严重缺陷,宽度和高度虽然永远>0,但不受限制,因为它们只是out=exp(in),这种指数的运算很危险,易导致梯度不稳定,训练难度加大,使用 既能够保证宽高>0,也能对宽高限制,最大值为anchor框宽高的4倍
,主要原因是在于作者认为原始的yolo /darknet框方程式存在严重缺陷,宽度和高度虽然永远>0,但不受限制,因为它们只是out=exp(in),这种指数的运算很危险,易导致梯度不稳定,训练难度加大,使用 既能够保证宽高>0,也能对宽高限制,最大值为anchor框宽高的4倍
2. 偏移的计算:Yolov5相对于该grid左上角坐标的偏移量的计算公式如下 ,先对
,先对 sigmoid处理后,再对其两倍计算后减去0.5,这样中心点的位置则可能出现在如下图的黄色区域内。
sigmoid处理后,再对其两倍计算后减去0.5,这样中心点的位置则可能出现在如下图的黄色区域内。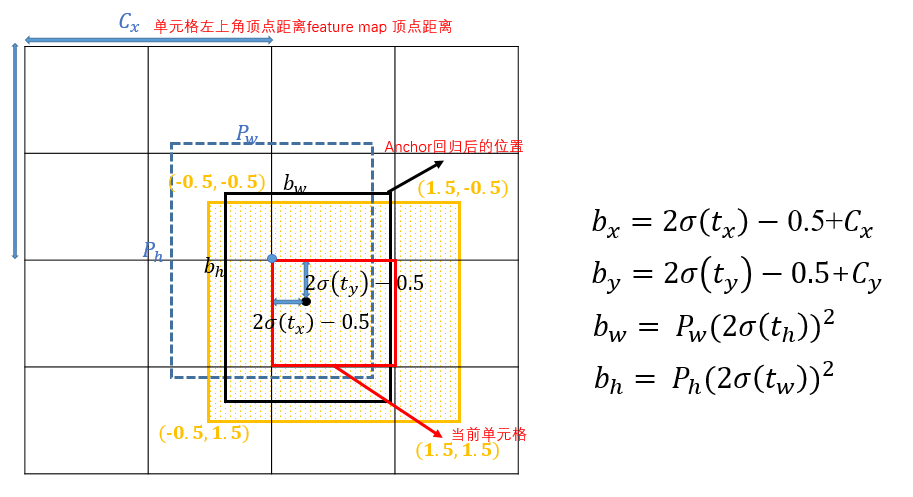
这个与yolov5的正样本定义有关,与yolov2/v3/v4正负样本定义不同,yolov5中,做了两个变动,1是匹配规则变化,2是筛选框变化。
1. 匹配规则变化:从IOU匹配变成shape匹配,先计算gt与9个anchor的长宽比,如果长宽比小于设定阈值,说明该gt和对应的anchor匹配,一个gt可能与几个anchor均能匹配上,因为同之前yolo一样,yolov5有三层网络,9个anchor, 从小到大,每3个anchor对应一层网络,所以一个gt可能在不同的网络层上做预测训练,大大增加了正样本的数量,当然也会出现gt与所有anchor都匹配不上的情况,这样gt就会被当成背景,不参与训练,说明anchor框尺寸设计的不好。
2. 筛选框变化:gt框与anchor框匹配后,得到anchor框对应的网络层的grid,看gt中心点落在哪个grid上,不仅取该grid中和gt匹配的anchor作为正样本,还取相邻的的两个grid中的anchor为正样本,如下图所示,绿色的gt框中心点落在红色grid的第三象限里,那不仅取该grid,还要取左边的grid和下面的grid,这样就有三个正样本,同时gt不仅与一个anchor框匹配,如果跟几个anchor框都匹配上,而且anchor不在同一个网络层上,所以可能有3-9个正样本,增大正样本数量。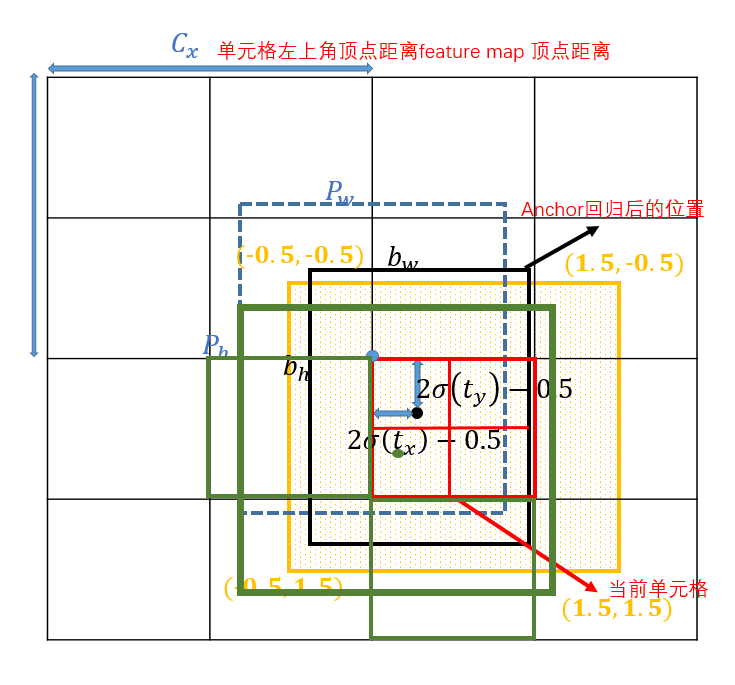

若有收获,就点个赞吧
0 人点赞
