前面我们多次提到一个累加器的例子,示例代码如下。在这个例子中,add10K() 这个方法不是线程安全的,问题就出在变量 count 的可见性和 count+=1 的原子性上。可见性问题可以用 volatile 来解决,而原子性问题我们前面一直都是采用的互斥锁方案。
public class Test {long count = 0;void add10K() {int idx = 0;while(idx++ < 10000) {count += 1;}}}
其实对于简单的原子性问题,还有一种无锁方案。Java SDK 并发包将这种无锁方案封装提炼之后,实现了一系列的原子类。不过,在深入介绍原子类的实现之前,我们先看看如何利用原子类解决累加器问题,这样你会对原子类有个初步的认识。<br />在下面的代码中,我们将原来的 long 型变量 count 替换为了原子类 AtomicLong,原来的 count +=1 替换成了 count.getAndIncrement(),仅需要这两处简单的改动就能使 add10K() 方法变成线程安全的,原子类的使用还是挺简单的。
public class Test {AtomicLong count =new AtomicLong(0);void add10K() {int idx = 0;while(idx++ < 10000) {count.getAndIncrement();}}}
无锁方案相对互斥锁方案,最大的好处就是性能。互斥锁方案为了保证互斥性,需要执行加锁、解锁操作,而加锁、解锁操作本身就消耗性能;同时拿不到锁的线程还会进入阻塞状态,进而触发线程切换,线程切换对性能的消耗也很大。 相比之下,无锁方案则完全没有加锁、解锁的性能消耗,同时还能保证互斥性,既解决了问题,又没有带来新的问题,可谓绝佳方案。那它是如何做到的呢?
无锁方案的实现原理
其实原子类性能高的秘密很简单,硬件支持而已。CPU 为了解决并发问题,提供了 CAS 指令(CAS,全称是 Compare And Swap,即“比较并交换”)。CAS 指令包含 3 个参数:共享变量的内存地址 A、用于比较的值 B 和共享变量的新值 C;并且只有当内存中地址 A 处的值等于 B 时,才能将内存中地址 A 处的值更新为新值 C。作为一条 CPU 指令,CAS 指令本身是能够保证原子性的。
你可以通过下面 CAS 指令的模拟代码来理解 CAS 的工作原理。在下面的模拟程序中有两个参数,一个是期望值 expect,另一个是需要写入的新值 newValue,只有当目前 count 的值和期望值 expect 相等时,才会将 count 更新为 newValue。
class SimulatedCAS{int count;synchronized int cas(int expect, int newValue){// 读目前count的值int curValue = count;// 比较目前count值是否==期望值if(curValue == expect){// 如果是,则更新count的值count = newValue;}// 返回写入前的值return curValue;}}
你仔细地再次思考一下这句话,“**只有当目前 count 的值和期望值 expect 相等时,才会将 count 更新为 newValue**。”要怎么理解这句话呢?<br />对于前面提到的累加器的例子,count += 1 的一个核心问题是:基于内存中 count 的当前值 A 计算出来的 count+=1 为 A+1,在将 A+1 写入内存的时候,很可能此时内存中 count 已经被其他线程更新过了,这样就会导致错误地覆盖其他线程写入的值(如果你觉得理解起来还有困难,建议你再重新看看《01 | 可见性、原子性和有序性问题:并发编程 Bug 的源头》)。也就是说,只有当内存中 count 的值等于期望值 A 时,才能将内存中 count 的值更新为计算结果 A+1,这不就是 CAS 的语义吗!<br />使用 CAS 来解决并发问题,一般都会伴随着自旋,而所谓自旋,其实就是循环尝试。例如,实现一个线程安全的count += 1操作,“CAS+ 自旋”的实现方案如下所示,首先计算 newValue = count+1,如果 cas(count,newValue) 返回的值不等于 count,则意味着线程在执行完代码①处之后,执行代码②处之前,count 的值被其他线程更新过。那此时该怎么处理呢?可以采用自旋方案,就像下面代码中展示的,可以重新读 count 最新的值来计算 newValue 并尝试再次更新,直到成功。
class SimulatedCAS{volatile int count;// 实现count+=1addOne(){do {newValue = count+1; //①}while(count !=cas(count,newValue) //②}// 模拟实现CAS,仅用来帮助理解synchronized int cas(int expect, int newValue){// 读目前count的值int curValue = count;// 比较目前count值是否==期望值if(curValue == expect){// 如果是,则更新count的值count= newValue;}// 返回写入前的值return curValue;}}
通过上面的示例代码,想必你已经发现了,CAS 这种无锁方案,完全没有加锁、解锁操作,即便两个线程完全同时执行 addOne() 方法,也不会有线程被阻塞,所以相对于互斥锁方案来说,性能好了很多。<br />但是在 CAS 方案中,有一个问题可能会常被你忽略,那就是 ABA 的问题。什么是 ABA 问题呢?<br />前面我们提到“如果 cas(count,newValue) 返回的值**不等于**count,意味着线程在执行完代码①处之后,执行代码②处之前,count 的值被其他线程**更新过**”,那如果 cas(count,newValue) 返回的值**等于**count,是否就能够认为 count 的值没有被其他线程**更新过**呢?显然不是的,假设 count 原本是 A,线程 T1 在执行完代码①处之后,执行代码②处之前,有可能 count 被线程 T2 更新成了 B,之后又被 T3 更新回了 A,这样线程 T1 虽然看到的一直是 A,但是其实已经被其他线程更新过了,这就是 ABA 问题。<br />可能大多数情况下我们并不关心 ABA 问题,例如数值的原子递增,但也不能所有情况下都不关心,例如原子化的更新对象很可能就需要关心 ABA 问题,因为两个 A 虽然相等,但是第二个 A 的属性可能已经发生变化了。所以在使用 CAS 方案的时候,一定要先 check 一下。
看 Java 如何实现原子化的 count += 1
在本文开始部分,我们使用原子类 AtomicLong 的 getAndIncrement() 方法替代了count += 1,从而实现了线程安全。原子类 AtomicLong 的 getAndIncrement() 方法内部就是基于 CAS 实现的,下面我们来看看 Java 是如何使用 CAS 来实现原子化的count += 1的。
在 Java 1.8 版本中,getAndIncrement() 方法会转调 unsafe.getAndAddLong() 方法。这里 this 和 valueOffset 两个参数可以唯一确定共享变量的内存地址。
final long getAndIncrement() {return unsafe.getAndAddLong(this, valueOffset, 1L);}
unsafe.getAndAddLong() 方法的源码如下,该方法首先会在内存中读取共享变量的值,之后循环调用 compareAndSwapLong() 方法来尝试设置共享变量的值,直到成功为止。compareAndSwapLong() 是一个 native 方法,只有当内存中共享变量的值等于 expected 时,才会将共享变量的值更新为 x,并且返回 true;否则返回 fasle。compareAndSwapLong 的语义和 CAS 指令的语义的差别仅仅是返回值不同而已。
public final long getAndAddLong(Object o, long offset, long delta){long v;do {// 读取内存中的值v = getLongVolatile(o, offset);} while (!compareAndSwapLong(o, offset, v, v + delta));return v;}//原子性地将变量更新为x//条件是内存中的值等于expected//更新成功则返回truenative boolean compareAndSwapLong(Object o, long offset,long expected,long x);
另外,需要你注意的是,getAndAddLong() 方法的实现,基本上就是 CAS 使用的经典范例。所以请你再次体会下面这段抽象后的代码片段,它在很多无锁程序中经常出现。Java 提供的原子类里面 CAS 一般被实现为 compareAndSet(),compareAndSet() 的语义和 CAS 指令的语义的差别仅仅是返回值不同而已,compareAndSet() 里面如果更新成功,则会返回 true,否则返回 false。
do {// 获取当前值oldV = xxxx;// 根据当前值计算新值newV = ...oldV...}while(!compareAndSet(oldV,newV);
原子类概览
Java SDK 并发包里提供的原子类内容很丰富,我们可以将它们分为五个类别:原子化的基本数据类型、原子化的对象引用类型、原子化数组、原子化对象属性更新器和原子化的累加器。这五个类别提供的方法基本上是相似的,并且每个类别都有若干原子类,你可以通过下面的原子类组成概览图来获得一个全局的印象。下面我们详细解读这五个类别。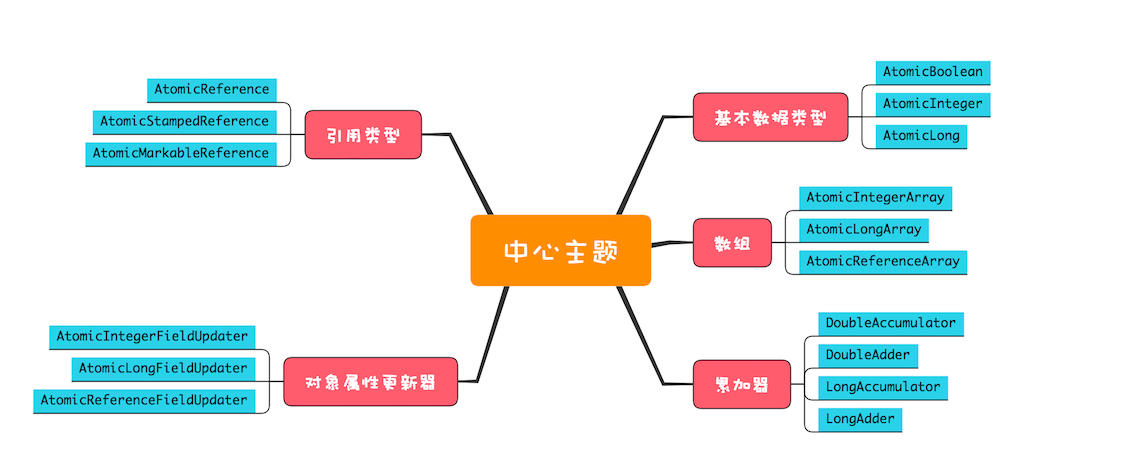
原子类组成概览图
1. 原子化的基本数据类型
相关实现有 AtomicBoolean、AtomicInteger 和 AtomicLong,提供的方法主要有以下这些,详情你可以参考 SDK 的源代码,都很简单,这里就不详细介绍了。
getAndIncrement() //原子化i++getAndDecrement() //原子化的i--incrementAndGet() //原子化的++idecrementAndGet() //原子化的--i//当前值+=delta,返回+=前的值getAndAdd(delta)//当前值+=delta,返回+=后的值addAndGet(delta)//CAS操作,返回是否成功compareAndSet(expect, update)//以下四个方法//新值可以通过传入func函数来计算getAndUpdate(func)updateAndGet(func)getAndAccumulate(x,func)accumulateAndGet(x,func)
2. 原子化的对象引用类型
相关实现有 AtomicReference、AtomicStampedReference 和 AtomicMarkableReference,利用它们可以实现对象引用的原子化更新。AtomicReference 提供的方法和原子化的基本数据类型差不多,这里不再赘述。不过需要注意的是,对象引用的更新需要重点关注 ABA 问题,AtomicStampedReference 和 AtomicMarkableReference 这两个原子类可以解决 ABA 问题。
解决 ABA 问题的思路其实很简单,增加一个版本号维度就可以了,这个和我们在《18 | StampedLock:有没有比读写锁更快的锁?》介绍的乐观锁机制很类似,每次执行 CAS 操作,附加再更新一个版本号,只要保证版本号是递增的,那么即便 A 变成 B 之后再变回 A,版本号也不会变回来(版本号递增的)。AtomicStampedReference 实现的 CAS 方法就增加了版本号参数,方法签名如下:
boolean compareAndSet(V expectedReference,V newReference,int expectedStamp,int newStamp)
AtomicMarkableReference 的实现机制则更简单,将版本号简化成了一个 Boolean 值,方法签名如下:
boolean compareAndSet(V expectedReference,V newReference,boolean expectedMark,boolean newMark)
3. 原子化数组
相关实现有 AtomicIntegerArray、AtomicLongArray 和 AtomicReferenceArray,利用这些原子类,我们可以原子化地更新数组里面的每一个元素。这些类提供的方法和原子化的基本数据类型的区别仅仅是:每个方法多了一个数组的索引参数,所以这里也不再赘述了。
4. 原子化对象属性更新器
相关实现有 AtomicIntegerFieldUpdater、AtomicLongFieldUpdater 和 AtomicReferenceFieldUpdater,利用它们可以原子化地更新对象的属性,这三个方法都是利用反射机制实现的,创建更新器的方法如下:
public static <U>AtomicXXXFieldUpdater<U>newUpdater(Class<U> tclass,String fieldName)
需要注意的是,对象属性必须是 volatile 类型的,只有这样才能保证可见性;如果对象属性不是 volatile 类型的,newUpdater() 方法会抛出 IllegalArgumentException 这个运行时异常。<br />你会发现 newUpdater() 的方法参数只有类的信息,没有对象的引用,而更新对象的属性,一定需要对象的引用,那这个参数是在哪里传入的呢?是在原子操作的方法参数中传入的。例如 compareAndSet() 这个原子操作,相比原子化的基本数据类型多了一个对象引用 obj。原子化对象属性更新器相关的方法,相比原子化的基本数据类型仅仅是多了对象引用参数,所以这里也不再赘述了。
boolean compareAndSet(T obj,int expect,int update)
5. 原子化的累加器
DoubleAccumulator、DoubleAdder、LongAccumulator 和 LongAdder,这四个类仅仅用来执行累加操作,相比原子化的基本数据类型,速度更快,但是不支持 compareAndSet() 方法。如果你仅仅需要累加操作,使用原子化的累加器性能会更好。
总结
无锁方案相对于互斥锁方案,优点非常多,首先性能好,其次是基本不会出现死锁问题(但可能出现饥饿和活锁问题,因为自旋会反复重试)。Java 提供的原子类大部分都实现了 compareAndSet() 方法,基于 compareAndSet() 方法,你可以构建自己的无锁数据结构,但是建议你不要这样做,这个工作最好还是让大师们去完成,原因是无锁算法没你想象的那么简单。
Java 提供的原子类能够解决一些简单的原子性问题,但你可能会发现,上面我们所有原子类的方法都是针对一个共享变量的,如果你需要解决多个变量的原子性问题,建议还是使用互斥锁方案。原子类虽好,但使用要慎之又慎。
课后思考
下面的示例代码是合理库存的原子化实现,仅实现了设置库存上限 setUpper() 方法,你觉得 setUpper() 方法的实现是否正确呢?
public class SafeWM {class WMRange{final int upper;final int lower;WMRange(int upper,int lower){//省略构造函数实现}}final AtomicReference<WMRange>rf = new AtomicReference<>(new WMRange(0,0));// 设置库存上限void setUpper(int v){WMRange nr;WMRange or = rf.get();do{// 检查参数合法性if(v < or.lower){throw new IllegalArgumentException();}nr = newWMRange(v, or.lower);}while(!rf.compareAndSet(or, nr));}}

若有收获,就点个赞吧
0 人点赞
