基本概念
1.简介
GridSearchCV的sklearn官方网址:
http://scikit-learn.org/stable/modules/generated/sklearn.model_selection.GridSearchCV.html#sklearn.model_selection.GridSearchCV
GridSearchCV,它存在的意义就是自动调参,只要把参数输进去,就能给出最优化的结果和参数。但是这个方法适合于小数据集,一旦数据的量级上去了,很难得出结果。这个时候就是需要动脑筋了。数据量比较大的时候可以使用一个快速调优的方法——坐标下降。它其实是一种贪心算法:拿当前对模型影响最大的参数调优,直到最优化;再拿下一个影响最大的参数调优,如此下去,直到所有的参数调整完毕。这个方法的缺点就是可能会调到局部最优而不是全局最优,但是省时间省力,巨大的优势面前,还是试一试吧,后续可以再拿bagging再优化。
通常算法不够好,需要调试参数时必不可少。比如SVM的惩罚因子C,核函数kernel,gamma参数等,对于不同的数据使用不同的参数,结果效果可能差1-5个点,sklearn为我们提供专门调试参数的函数grid_search。
2.参数说明
class sklearn.model_selection.GridSearchCV(estimator, param_grid, scoring=None, fit_params=None, n_jobs=1, iid=True, refit=True, cv=None, verbose=0, pre_dispatch=‘2*n_jobs’, error_score=’raise’, return_train_score=’warn’)
(1)estimator
选择使用的分类器,并且传入除需要确定最佳的参数之外的其他参数。每一个分类器都需要一个scoring参数,或者score方法:如estimator=RandomForestClassifier(min_samples_split=100,min_samples_leaf=20,max_depth=8,max_features=’sqrt’,random_state=10),
(2)param_grid
需要最优化的参数的取值,值为字典或者列表,例如:param_grid =param_test1,param_test1 = {‘n_estimators’:range(10,71,10)}。
(3)scoring=None
模型评价标准,默认None,这时需要使用score函数;或者如scoring=’roc_auc’,根据所选模型不同,评价准则不同。字符串(函数名),或是可调用对象,需要其函数签名形如:scorer(estimator, X, y);如果是None,则使用estimator的误差估计函数。具体值的选取看本篇第三节内容。
(4)fit_params=None
(5)n_jobs=1
n_jobs: 并行数,int:个数,-1:跟CPU核数一致, 1:默认值
(6)iid=True
iid:默认True,为True时,默认为各个样本fold概率分布一致,误差估计为所有样本之和,而非各个fold的平均。
(7)refit=True
默认为True,程序将会以交叉验证训练集得到的最佳参数,重新对所有可用的训练集与开发集进行,作为最终用于性能评估的最佳模型参数。即在搜索参数结束后,用最佳参数结果再次fit一遍全部数据集。
(8)cv=None
交叉验证参数,默认None,使用三折交叉验证。指定fold数量,默认为3,也可以是yield训练/测试数据的生成器。
(9)verbose=0, scoring=None
verbose:日志冗长度,int:冗长度,0:不输出训练过程,1:偶尔输出,>1:对每个子模型都输出。
(10)pre_dispatch=‘2*n_jobs’
指定总共分发的并行任务数。当n_jobs大于1时,数据将在每个运行点进行复制,这可能导致OOM,而设置pre_dispatch参数,则可以预先划分总共的job数量,使数据最多被复制pre_dispatch次
(11)error_score=’raise’
(12)return_train_score=’warn’
如果“False”,cvresults属性将不包括训练分数。
回到sklearn里面的GridSearchCV,GridSearchCV用于系统地遍历多种参数组合,通过交叉验证确定最佳效果参数。
3. Scoring parameter:评价标准参数详细说明
Model-evaluation tools using cross-validation (such as model_selection.cross_val_score andmodel_selection.GridSearchCV) rely on an internal scoring strategy. This is discussed in the section The scoring parameter: defining model evaluation rules.
For the most common use cases, you can designate a scorer object with the scoring parameter; the table below shows all possible values. All scorer objects follow the convention that higher return values are better than lower return values. Thus metrics which measure the distance between the model and the data, like metrics.mean_squared_error, are available as neg_mean_squared_error which return the negated value of the metric.
4.属性
(1)cvresults : dict of numpy (masked) ndarrays
具有键作为列标题和值作为列的dict,可以导入到DataFrame中。注意,“params”键用于存储所有参数候选项的参数设置列表。
(2)bestestimator : estimator
通过搜索选择的估计器,即在左侧数据上给出最高分数(或指定的最小损失)的估计器。 如果refit = False,则不可用。
(3)bestscore : float best_estimator的分数
(4)bestparams : dict 在保存数据上给出最佳结果的参数设置
(5)bestindex : int 对应于最佳候选参数设置的索引(cvresults数组)。
search.cvresults [‘params’] [search.bestindex]中的dict给出了最佳模型的参数设置,给出了最高的平均分数(search.bestscore)。
(6)scorer : function
Scorer function used on the held out data to choose the best parameters for the model.
(7)n_splits : int**
The number of cross-validation splits (folds/iterations).
5.进行预测的常用方法和属性
grid.fit():运行网格搜索
gridscores:给出不同参数情况下的评价结果
bestparams:描述了已取得最佳结果的参数的组合
bestscore:提供优化过程期间观察到的最好的评分
6.网格搜索实例
6.1 随机森林
(1)http://ju.outofmemory.cn/entry/329943 转自“ 蓝鲸网站分析博客 ”。
(2)http://blog.csdn.net/u010159842/article/details/79317828利用sklearn api gridsearch 进行keras参数调优
1. param_test1 ={'n_estimators':range(10,71,10)}2. gsearch1= GridSearchCV(estimator =RandomForestClassifier(min_samples_split=100,3. min_samples_leaf=20,max_depth= 8,max_features='sqrt',random_state=10),4. param_grid =param_test1,scoring='roc_auc',cv=5)5. gsearch1.fit(X,y)6. gsearch1.grid_scores_, gsearch1.best_params_, gsearch1.best_score_
输出结果如下:
([mean: 0.80681, std:0.02236, params: {‘n_estimators’: 10},
mean: 0.81600, std: 0.03275, params:{‘n_estimators’: 20},
mean: 0.81818, std: 0.03136, params:{‘n_estimators’: 30},
mean: 0.81838, std: 0.03118, params:{‘n_estimators’: 40},
mean: 0.82034, std: 0.03001, params:{‘n_estimators’: 50},
mean: 0.82113, std: 0.02966, params:{‘n_estimators’: 60},
mean: 0.81992, std: 0.02836, params:{‘n_estimators’: 70}],
{‘n_estimators’: 60},
0.8211334476626017)
如果有transform,使用Pipeline简化系统搭建流程,将transform与分类器串联起来(Pipelineof transforms with a final estimator)
1. pipeline= Pipeline([("features", combined_features), ("svm", svm)])2. param_grid= dict(features__pca__n_components=[1, 2, 3],3. features__univ_select__k=[1,2],4. svm__C=[0.1, 1, 10])5.6. grid_search= GridSearchCV(pipeline, param_grid=param_grid, verbose=10)7. grid_search.fit(X,y)8. print(grid_search.best_estimator_)
http://scikit-learn.org/stable/modules/model_evaluation.html
网格搜索算法与K折交叉验证
网格搜索算法和K折交叉验证法是机器学习入门的时候遇到的重要的概念。
网格搜索算法是一种通过遍历给定的参数组合来优化模型表现的方法。
以决策树为例,当我们确定了要使用决策树算法的时候,为了能够更好地拟合和预测,我们需要调整它的参数。在决策树算法中,我们通常选择的参数是决策树的最大深度。
于是我们会给出一系列的最大深度的值,比如 {‘max_depth’: [1,2,3,4,5]},我们会尽可能包含最优最大深度。
不过,我们如何知道哪一个最大深度的模型是最好的呢?我们需要一种可靠的评分方法,对每个最大深度的决策树模型都进行评分,这其中非常经典的一种方法就是交叉验证,下面我们就以K折交叉验证为例,详细介绍它的算法过程。
首先我们先看一下数据集是如何分割的。我们拿到的原始数据集首先会按照一定的比例划分成训练集和测试集。比如下图,以8:2分割的数据集: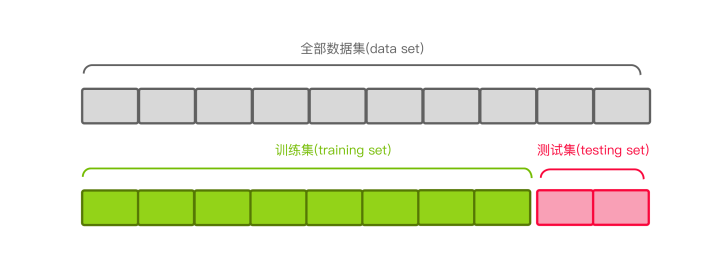
训练集用来训练我们的模型,它的作用就像我们平时做的练习题;测试集用来评估我们训练好的模型表现如何,它的作用像我们做的高考题,这是要绝对保密不能提前被模型看到的。
因此,在K折交叉验证中,我们用到的数据是训练集中的所有数据。我们将训练集的所有数据平均划分成K份(通常选择K=10),取第K份作为验证集,它的作用就像我们用来估计高考分数的模拟题,余下的K-1份作为交叉验证的训练集。
对于我们最开始选择的决策树的5个最大深度 ,以 max_depth=1 为例,我们先用第2-10份数据作为训练集训练模型,用第1份数据作为验证集对这次训练的模型进行评分,得到第一个分数;然后重新构建一个 max_depth=1 的决策树,用第1和3-10份数据作为训练集训练模型,用第2份数据作为验证集对这次训练的模型进行评分,得到第二个分数……以此类推,最后构建一个 max_depth=1 的决策树用第1-9份数据作为训练集训练模型,用第10份数据作为验证集对这次训练的模型进行评分,得到第十个分数。于是对于 max_depth=1 的决策树模型,我们训练了10次,验证了10次,得到了10个验证分数,然后计算这10个验证分数的平均分数,就是 max_depth=1 的决策树模型的最终验证分数。
对于 max_depth = 2,3,4,5 时,分别进行和 max_depth=1 相同的交叉验证过程,得到它们的最终验证分数。然后我们就可以对这5个最大深度的决策树的最终验证分数进行比较,分数最高的那一个就是最优最大深度,我们利用最优参数在全部训练集上训练一个新的模型,整个模型就是最优模型。
下面提供一个简单的利用决策树预测乳腺癌的例子:
from sklearn.model_selection import GridSearchCV, KFold, train_test_splitfrom sklearn.metrics import make_scorer, accuracy_scorefrom sklearn.tree import DecisionTreeClassifierfrom sklearn.datasets import load_breast_cancerdata = load_breast_cancer()X_train, X_test, y_train, y_test = train_test_split(data['data'], data['target'], train_size=0.8, random_state=0)regressor = DecisionTreeClassifier(random_state=0)parameters = {'max_depth': range(1, 6)}scoring_fnc = make_scorer(accuracy_score)kfold = KFold(n_splits=10)grid = GridSearchCV(regressor, parameters, scoring_fnc, cv=kfold)grid = grid.fit(X_train, y_train)reg = grid.best_estimator_print('best score: %f'%grid.best_score_)print('best parameters:')for key in parameters.keys():print('%s: %d'%(key, reg.get_params()[key]))print('test score: %f'%reg.score(X_test, y_test))import pandas as pdpd.DataFrame(grid.cv_results_).T
直接用决策树得到的分数大约是92%,经过网格搜索优化以后,我们可以在测试集得到95.6%的准确率:
best score: 0.938462best parameters:max_depth: 4test score: 0.956140


若有收获,就点个赞吧
0 人点赞
