说起pandas这个是python数据清洗的利器,它可以让你像sql一样操作数据,同时可以对数据进行各种计算,转换完成后还可以方便的存储到excel,转化为array、Matrix供进一步(模型)使用。但是网上关于pandas的知识点比较散,本文就按照笔者的理解,分门别类的来介绍pandas的常用函数。本文可能稍微有点长,但是能够满足你对于pandas学习的所有需要,本文介绍的函数在实际中也很常用。本文较长,也可以当做参考使用。
以下数据的操作,基于这几个基础数据。
data_a1 2 3 40 0 1 2 31 4 5 6 72 8 9 10 11data_bA B C D0 1.0 1.0 2 2.01 2.0 3.0 2 2.02 2.0 3.0 1 4.03 2.0 3.0 2 2.0data_c0 1 20 1.0 2.0 3.01 NaN NaN 2.02 NaN NaN NaN3 8.0 8.0 NaN
发现大家大于axis=0和axis=1参数到底怎么用不了解,经常混淆,到底是对列还是对行操作。其实这么理解比较好,axis=0是默认的,按行进行操作,其实就是对列进行一系列操作;axis=1需要自己设置,按列进行操作,其实就是对行进行一系列操作。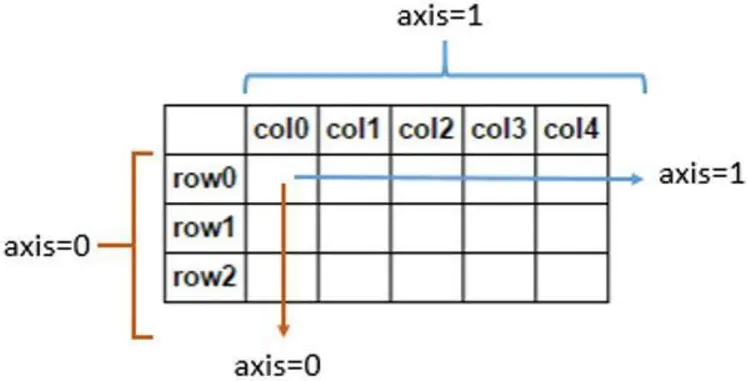
axis=0和axis=1理解
1.数据操作函数
数据操作函数包括数据的读取、检查、规整等操作,是数据清洗的开始阶段。
read系列函数
这个知识点比较多,因为pandas可读的数据类型非常多,所以我单独写一篇介绍这个知识点,但是最常用的还是read_csv,这个函数尤其要注意编码问题。
columns、index
严格说这两个不叫函数而是叫属性,但为了介绍方便,姑且放到函数里,分别返回列名和行名,这个没啥好说的,注意使用的时候不要打括号。
head和tail函数
这两个函数分别取你的dataframe的前几行和后几行数据,只有一个参数n,就是你想看几行就head或tail几行。
rename函数
这个函数是对列名进行更改,通常在读数据的时候可以设置header=True读取第一行作为列名,或者人为给定columns参数,但是很多时候我们需要对列名进行更改,此时用rename函数,基本用法为rename(mapper=None, index=None, columns=None, axis=None, copy=True, inplace=False, level=None)。rename函数也可以通过指定axis参数或者index,column参数设置修改行名或者列名,这里还有一个参数比较有用就是inplace,默认为false即返回新的dataframe,如果为true则在原dataframe上进行操作。最常用的就是利用字典改名,用键值对的形式将原列名和现列名对应起来。当然还有一种笨办法直接通过df.columns = list[],这个list要求和df的colunms长度完全相同,否则报错。
data_b.rename(index=str, columns={"A": "a", "B": "c"})-- 输出Out[127]:a c C D0 1.0 1.0 2 2.01 2.0 3.0 2 2.02 2.0 3.0 1 4.03 2.0 3.0 2 2.0
reindex函数
reindex函数是为series或dataframe增加或减少索引、列名用的,注意不可以用它为index改名(改名还是要用rename,设置axis=1),增加索引,没有默认值定义为为Nan,减少索引相当于对index进行切片了。reindex官方文档给了很多参数,但只有几个很重要,column、index,即控制对行、列的操作,fill_value控制默认缺省值。
data_b.reindex(columns=['A','B','C','D','E'],fill_value=3.0)-- 输出A B C D E0 1.0 1.0 2 2.0 3.01 2.0 3.0 2 2.0 3.02 2.0 3.0 1 4.0 3.03 2.0 3.0 2 2.0 3.0data_b.reindex(index=['0','1','2','3'],fill_value=3.0)--输出A B C D0 3.0 3.0 3.0 3.01 3.0 3.0 3.0 3.02 3.0 3.0 3.0 3.03 3.0 3.0 3.0 3.0
set_index函数和reset_index函数
set_index可以设置单索引或者多索引,基本用法为set_index(keys, drop=True, append=False, inplace=False, verify_integrity=False) 大部分情况下我们只需要关注keys这个指标,其他指标可以不关注。reset_index()就是取消索引,重新变为整数索引那种形式。
data_b.set_index(['A','B'])--输出C DA B1.0 1.0 2 2.02.0 3.0 2 2.03.0 1 4.03.0 2 2.0data_b.reset_index()--输出index A B C D0 0 1.0 1.0 2 2.01 1 2.0 3.0 2 2.02 2 2.0 3.0 1 4.03 3 2.0 3.0 2 2.0
describe函数
这个函数真是良心,没有任何参数,直接对着你的数据框用就可以了,输出的是对于你数据框整体数据的描述。
data_a.describe()--输出1 2 3 4count 3.0 3.0 3.0 3.0mean 4.0 5.0 6.0 7.0std 4.0 4.0 4.0 4.0min 0.0 1.0 2.0 3.025% 2.0 3.0 4.0 5.050% 4.0 5.0 6.0 7.075% 6.0 7.0 8.0 9.0max 8.0 9.0 10.0 11.0
info函数
这个函数用来查看数据的类型,有没有缺失值,在进行特征工程的时候比较好用。
data_a.info()--输出Data columns (total 4 columns):1 3 non-null int642 3 non-null int643 3 non-null int644 3 non-null int64dtypes: int64(4)memory usage: 176.0 bytes
shape函数
values函数
df.duplicated函数
df.drop_duplicates函数
这个函数用于去除重复值,基本用法为data.drop_duplicates(subset=[‘A’,’B’],keep=’first’,inplace=True),其中subset指明了要去除重复值的列,keep指明要保留的列。用法比较简单,看个例子。
data_b.drop_duplicates(subset=['A'],keep='first')-- 输出A B C D0 1.0 1.0 2 2.01 2.0 3.0 2 2.0
drop函数
用于删除数据框中的某一行或者某一列,基本用法为drop(labels=None,axis=0, index=None, columns=None, inplace=False),默认删除的是行,如果想删除列的话,得指定axis=1。也可以直接指定index或columns确定要删除的行或列。
data_b.drop(columns=['A'])data_b.drop('A',axis=1)-- 输出B C D0 1.0 2 2.01 3.0 2 2.02 3.0 1 4.03 3.0 2 2.0
replace函数
用于数据的替换,基本用法是replace(to_replace=None, value=None, inplace=False, limit=None, regex=False, method=’pad’),其中to_replace的字段可以用字典表示。
data_b.replace({'A':1,'B':3},10)-- 输出A B C D0 10.0 1.0 2 2.01 2.0 10.0 2 2.02 2.0 10.0 1 4.03 2.0 10.0 2 2.0
cut函数
cut函数用来对数组进行切分,就是把连续的数据划分为几个区间,基本使用方法是cut(x, bins, right=True, labels=None, retbins=False, precision=3, include_lowest=False, duplicates=’raise’)。x是要划分的series,必须是series不能是dataframe。bins可以是整数也可以是自己定义的区间。labels这个参数用于给你切分完以后生成的数据进行类别标记。其他参数可以忽略。这个的用法只能是pd.cut(),不能用其他写法,如果是指定的分组区间,那么是左不包含,这点需要注意。
0 01 12 13 1Name: A, dtype: categoryCategories (2, int64): [0 < 1]
get_dummies函数
这个函数用来实现onehot编码显然适用于数据挖掘,使用以后会进行index-column的转换,基本用法是getdummies(data, prefix=None, prefix_sep=’‘, dummy_na=False, columns=None, sparse=False, drop_first=False)。案例说明一下。
pd.get_dummies(data_b.C)-- 输出1 20 0 11 0 12 1 03 0 1
isnull函数和notnull函数
这两个函数是对元素级别的操作,即对每一个位置判断是否是空值,isnull的功能是如果是空值就返回Ture,否则返回False,notnull和isnull的作用相反。由于是元素级的操作,因此返回的是和原dataframe行列一样的包含逻辑True和False的dataframe,用于布尔型的逻辑判断。因为原来的data_b没有空数据,做个shift处理先,shift函数会在后边说,这里先用。
data_b.shift()-- 输出A B C D0 NaN NaN NaN NaN1 1.0 1.0 2.0 2.02 2.0 3.0 2.0 2.03 2.0 3.0 1.0 4.0data_b.shift().isnull()-- 输出A B C D0 True True True True1 False False False False2 False False False False3 False False False Falsedata_b.shift().notnull()-- 输出A B C D0 False False False False1 True True True True2 True True True True3 True True True True
dropna函数
dropna这个函数就是移除缺失值,但是针对series和dataframe它的操作逻辑是不一样的。对于series只是把NA值删除,而对于dataframe是把包括NA值的行或列都删除,默认axis=0。更多用法参考请参考官方文档。dropna(axis=0, how=’any’, thresh=None, subset=None, inplace=False),介绍一个thresh参数如果设置了这个值,那么只有含大于这个值的非空行/列才会保留,还有subset参数指定删除哪一行或者哪一列包含空值的数据。
data_b.shift().A.dropna()-- 输出1 1.02 2.03 2.0Name: A, dtype: float64data_b.shift().dropna()-- 输出A B C D1 1.0 1.0 2.0 2.02 2.0 3.0 2.0 2.03 2.0 3.0 1.0 4.0data_b.shift().dropna(axis=1)-- 输出Empty DataFrameColumns: []Index: [0, 1, 2, 3]
fillna函数
对缺失值进行填充处理,fillna(value=None, method=None, axis=0) ,method包括’backfill’, ‘bfill’, ‘pad’, ‘ffill’, None这几个用法各不相同。首先fillna只有一个value,就是全部空值填充。当然value也可以用字典填充,指定特定的列填充不同的值{‘A’:10,’B’:20}。说完这个接着说method,pad和ffill类似,都是前项填充,backfill和bfill都是后项填充,可以用limit限制最多向前寻找几个值,用axis设置填充方向。
data_c.fillna(10)--输出0 1 20 1.0 2.0 3.01 10.0 10.0 2.02 10.0 10.0 10.03 8.0 8.0 10.0data_c.fillna(method = 'bfill')-- 输出0 1 20 1.0 2.0 3.01 8.0 8.0 2.02 8.0 8.0 NaN3 8.0 8.0 NaNdata_c.fillna(method = 'ffill',limit=2)-- 输出0 1 20 1.0 2.0 3.01 1.0 2.0 2.02 1.0 2.0 2.03 8.0 8.0 2.0
2.数据处理函数
数据处理函数是对数据进行切片、格式转换、排序以及对数据框进行连接等操作。
reshape函数
很遗憾这个函数python已经不支持了,各位看官要用reshape去numpy里的ndarray用吧。
stack和unstack函数
stack和unstack函数是对行列索引进行转换用的,stack将columns变为index,unstack相反,将index变为columns,这个对于多层索引应用效果比较好,其实是为了聚合统计方便的。这两个函数知识点比较多,要弄清楚还是去查官方文档。
data_b.stack()-- 输出0 A 1.0B 1.0C 2.0D 2.01 A 2.0B 3.0C 2.0D 2.02 A 2.0B 3.0C 1.0D 4.03 A 2.0B 3.0C 2.0D 2.0dtype: float64data_b.stack().unstack()-- 输出A B C D0 1.0 1.0 2.0 2.01 2.0 3.0 2.0 2.02 2.0 3.0 1.0 4.03 2.0 3.0 2.0 2.0
pivot和pivot_table
这两个函数真的可以让你像操作excel的数据透视表一样操作dataframe,pivot函数功能简单,就是做一个展示,不能进行聚合操作,而pivottable可以做聚合操作。通过例子来感受一下。
data = {'date': ['2018-08-01', '2018-08-02', '2018-08-03', '2018-08-01', '2018-08-03', '2018-08-03','2018-08-01', '2018-08-02'],'variable': ['A','A','A','B','B','C','C','C'],'value': [3.0 ,4.0 ,6.0 ,2.0 ,8.0 ,4.0 ,10.0 ,1.0 ]}df = pd.DataFrame(data=data, columns=['date', 'variable', 'value'])df1 = df.pivot(index='date', columns='variable', values='value')print(df1)-- 输出variable A B Cdate2018-08-01 3.0 2.0 10.02018-08-02 4.0 NaN 1.02018-08-03 6.0 8.0 4.0df = pd.DataFrame({"A": ["foo", "foo", "foo", "foo", "foo","bar", "bar", "bar", "bar"],"B": ["one", "one", "one", "two", "two","one", "one", "two", "two"],"C": ["small", "large", "large", "small","small", "large", "small", "small","large"],"D": [1, 2, 2, 3, 3, 4, 5, 6, 7]})print(pd.pivot_table(df, index=['A', 'B'], columns=['C'], values=['D'], aggfunc=[np.mean, np.sum, max]))-- 输出mean sum maxD D DC large small large small large smallA Bbar one 4.0 5.0 4.0 5.0 4.0 5.0two 7.0 6.0 7.0 6.0 7.0 6.0foo one 2.0 1.0 4.0 1.0 2.0 1.0two NaN 3.0 NaN 6.0 NaN 3.0
loc和iloc函数
操作任何一个数据类型,切片都是必须要掌握的,通过切片可以取值和进行赋值操作。dataframe切片最简单的是通过columns和index直接取值,有两种模式比如df[‘列A’]和df.列A。但是要取到具体某一列某个index的数据,就需要采用loc和iloc函数了。loc这个函数有两个参数,index名和columns名,只能用名字,不能用索引,columns省略时默认返回所有列,注意取列的时候用方括号括起来。loc函数还有一个作用就是根据逻辑值进行切片。
data_b.loc[0,['A']]-- 输出A 1.0Name: 0, dtype: float64data_b.loc[data_b['A']==1]-- 输出A B C D0 1.0 1.0 2 2.0
相比于loc,iloc就比较友好了,可以用index名和columns名也可以用位置索引,混用这种写法真是太好了。
data_b.iloc[1,0:3]-- 输出A 2.0B 3.0C 2.0Name: 1, dtype: float64
ix函数
sort_index函数和sort_values函数
这是排序函数,sort_index函数目前不建议使用了,统一用sort_values函数。其实参数都是差不多的,sort_values(by, axis=0, ascending=True, inplace=False, kind=’quicksort’, na_position=’last’),这个by就是按照哪一列排序,其他参数根据字面意思可以理解。
data_b.sort_values(by='A',ascending=False)--输出A B C D1 2.0 3.0 2 2.02 2.0 3.0 1 4.03 2.0 3.0 2 2.00 1.0 1.0 2 2.0
数据格式转换函数
因为一些原因我们总要进行数据类型的转换,最常用的就是astype函数,这个是元素级别的操作,要对某一列数据进行操作,df.A.astype(‘int’)。还有比较常用的是to_numbric函数和to_datetime函数。先手to_datetime函数,这个函数常用的参数也就那么两个,to_datetime(‘13000101’, format=’%Y%m%d’, errors=’ignore’),第一个是要转换的字符串,第二个是要转换的日期格式,其他参数可以忽略。to_numbric函数就更简单了,只要传给指定的参数,如果符合纯数字特征就转换为数字。还有一种方法就是对某一列数据使用apply(int)、apply(str)等方法。
重点说一下日期格式的转换,这个只能对pandas对象使用,比如pd.to_datetime([],format=)是对的,如果是pd[列A].to_datetime()用法确实错的。
- 关于format =’’,我给大家提供如下的格式标准。
- %d 日期, 01-31
- %f 小数形式的秒,SS.SSS
- %H 小时, 00-23
- %j 算出某一天是该年的第几天,001-366
- %m 月份,00-12
- %M 分钟, 00-59
- %s 从1970年1月1日到现在的秒数
- %S 秒, 00-59
- %w 星期, 0-6 (0是星期天)
- %W 算出某一天属于该年的第几周, 01-53
- %Y 年, YYYY
- %% 百分号
start = pd.to_datetime("5-1-2012")#只有pd.to_datetime这一种写法-- 输出2012-05-01 00:00:00
merge函数
这个函数是将两个dataframe进行合并,需要指明用于合并的列,即on参数,可以理解为sql的join操作。基本用法为merge(df1,df2, how=‘inner’, on=None, left_on=None, right_on=None, left_index=False,right_index=False, sort=False, suffixes=(’_x’, ‘_y’)),要解释的参数是how,选择连接的方式,有outer、inner、left、right四个参数可供选择,跟sql一样,不多说了。left_on和right_on指定左右连接的主键,如果两个主键名字一样,用on就行了。left_index和right_index指定用左右的索引作为连接键。suffixes列名重复了怎么办,用下划线区分。最后注意一点,一次只能merge两个dataframe。
data_a.merge(data_b,left_index=True,right_index=True,how='outer')-- 输出1 2 3 4 A B C D0 0.0 1.0 2.0 3.0 1.0 1.0 2 2.01 4.0 5.0 6.0 7.0 2.0 3.0 2 2.02 8.0 9.0 10.0 11.0 2.0 3.0 1 4.03 NaN NaN NaN NaN 2.0 3.0 2 2.0
concat函数
数据拼接函数,可以拼接series,dataframe等,与merge不同,concat可以连接很多个dataframe,基本用法为pd.concat(objs, axis=0, join=’outer’, join_axes=None, ignore_index=False,
keys=None, levels=None, names=None, verify_integrity=False),默认是按行的方向堆叠。其他参数都不是特别重要,一般也不用设置,当然有时候根据使用场景还是要调整一下。这个要注意objs参数是dataframe或者series构成的列表。不能写一个dataframe,否则会报错。
pd.concat([data_b,data_b])-- 输出A B C D0 1.0 1.0 2 2.01 2.0 3.0 2 2.02 2.0 3.0 1 4.03 2.0 3.0 2 2.00 1.0 1.0 2 2.01 2.0 3.0 2 2.02 2.0 3.0 1 4.03 2.0 3.0 2 2.0pd.concat([data_a,data_b],axis=1)-- 输出1 2 3 4 A B C D0 0.0 1.0 2.0 3.0 1.0 1.0 2 2.01 4.0 5.0 6.0 7.0 2.0 3.0 2 2.02 8.0 9.0 10.0 11.0 2.0 3.0 1 4.03 NaN NaN NaN NaN 2.0 3.0 2 2.0
join函数
3.数据聚合函数
数据聚合操作是对数据进行统计意义上的操作或者自定义函数进行计算。
groupby函数
为什么把groupby函数放到第一个讲呢,因为有很多时候你做统计除了针对行列,更多时候是要基于分组的,大部分聚合函数要在分组的基础上做。
groupby有两种典型用法:
(1)grouped=df[‘列a’].groupby([df[‘列b’],df[‘列c’])
(2)grouped=df.groupby([‘列b’,’列c’])[‘列a’]
这两种写法是一样的意思,用哪个都可以,但是应用的时候要注意特殊的写法。
map和applymap函数
map函数是元素级别的操作,这个要注意什么呢,你不能对着一个dataframe进行map操作,要用map首先得是一个series,然后是对里边的元素进行操作。如果你想对数据框进行操作怎么办,有一个applymap函数,是对数据框里的所有元素进行操作。
lambda x: x*xdata_b.map(lambda x: x*x)data_b.applymap(lambda x: x*x)--第一个输出报错File "/Users/elliot/anaconda3/lib/python3.7/site-packages/pandas/core/generic.py", line 4376, in __getattr__return object.__getattribute__(self, name)AttributeError: 'DataFrame' object has no attribute 'map'-- 第二个输出A B C D0 1.0 1.0 4 4.01 4.0 9.0 4 4.02 4.0 9.0 1 16.03 4.0 9.0 4 4.0
apply函数
apply是pandas里对行、列级元素进行操作的函数,也就是计算时按行或者列为最小单位进行。这个函数使用灵活,因此最常被使用。基本用法为:apply(func, axis=0, broadcast=None, raw=False, reduce=None, result_type=None, args=args=(), **kwds),洋洋洒洒写了这么多参数,其实能用到的也就是func和axis了,func就是你要应用的函数,axis决定对行或者对列进行操作。
data_b.apply(sum)-- 输出A 7.0B 10.0C 7.0D 10.0dtype: float64
agg函数
agg函数和apply函数其实是一样的,只不过它可以指定不同的列用不同的函数,或者指定所有列用不同的函数,可供选择的范围更广。
agg函数也有两种写法:
(1)df.groupby([‘列b’]).agg([sum,mean,max])
(2)df.groupby([‘列b’]).agg({‘列a’:sum,’列b’:np.mean})
data_b.groupby(['B','C']).agg([sum,np.mean,max])--输出A Dsum mean max sum mean maxB C1.0 2 1.0 1.0 1.0 2.0 2.0 2.03.0 1 2.0 2.0 2.0 4.0 4.0 4.02 4.0 2.0 2.0 4.0 2.0 2.0data_b.groupby(['B']).agg({'A':sum,'B':np.mean})-- 输出A BB1.0 1.0 1.03.0 6.0 3.0
以下的所有函数,除极个别外都可以配合上面的分组和应用函数使用。
sum函数
求和函数,没有什么好说的。基本用法为sum(a,axis=0),默认是沿着行方向进行的加和,也就是对列求和,axis=1表示沿着列方向求和,也就是对行求和。
mean函数
求均值的函数,注意求均值就是mean,可没有什么avg函数,还有你正常对数据框或者series用mean这些都没问题,但是要用在apply等函数里,最好还是加一个np,用np.mean,目前其他函数没发现这个问题,大家用的时候注意吧。
count函数和value_counts函数
计数函数,对dataframe里的数据进行非NA值的统计。这个是对所有元素进行的无差别操作,就是有一个非NA值就加1。但是有的时候我们需要对于某一列中有哪些不同元素进行计数统计,这个时候就要用value_counts函数,由于这是元素级别的操作,所以这个只能对dataframe的某一列就是series使用。
data_b.count()data_b['A'].value_counts()--输出A 4B 4C 4D 42.0 31.0 1
unique函数
unique函数返回的是某一列的不重复值,是对列进行的操作,常用的方法是df.列A.unique(),这个不啰嗦了,只注意一点,unique返回值是数组。
min和max函数
median函数
std和var函数
mode函数
这个函数的作用是沿着某个轴返回一组众数,为什么说是一组呢,因为有可能众数不止一个。基本用法为:mode(axis=0, numeric_only=False),也就是说不仅可以对数字操作还可以对字符类型进行操作,默认是沿着行方向返回众数。这个需要案例说明,可以看出返回的是一个dataframe,因为众数不止一个会按顺序输出,行数跟众数最多的那一列的众数个数相同,缺失值以NaN填充。但是众数我们只需要一个,这个时候用iloc切片操作,即data_b.mode().iloc[0,:]。
data_b = pd.DataFrame({'A':[1,2,3,4],'B':[1,3,3,4],'C':[2,2,1,2]})data_b.mode()data_b.mode(axis = 1)--输出1A B C0 1 3.0 2.01 2 NaN NaN2 3 NaN NaN3 4 NaN NaN--输出200 11 22 33 4
corr函数
这个函数返回的是各列的相关系数,[-1,1]之间,1代表严格正相关,-1代表严格负相关。基本用法为:corr(method=’pearson’, min_periods=1),其中method可选{‘pearson’, ‘kendall’, ‘spearman’},默认用pearson,min_periods样本最少的数据量,默认是1。举个栗子感受一下。
data_b.corr()--输出A B C DA 1.000000 1.000000 -0.333333 0.333333B 1.000000 1.000000 -0.333333 0.333333C -0.333333 -0.333333 1.000000 -1.000000D 0.333333 0.333333 -1.000000 1.000000
argmax函数和argmin函数(idxmax和idxmin)
这两个函数也是元素级别操作的函数,因此也可以再series中使用而不可以再dataframe中使用。未来argmax函数和argmin函数就不支持了,以后直接用idxmax和idxmin函数。
data_b['A'].idxmax()--输出1
cumsum函数和cumprod函数
这个是对行列操作的函数,返回的是与原dataframe大小完全一样的dataframe,不过是对结果进行累加和累乘操作了。
data_b.cumsum()data_b.cumprod()-- 输出A B C D0 1.0 1.0 2.0 2.01 3.0 4.0 4.0 4.02 5.0 7.0 5.0 8.03 7.0 10.0 7.0 10.0A B C D0 1.0 1.0 2.0 2.01 2.0 3.0 4.0 4.02 4.0 9.0 4.0 16.03 8.0 27.0 8.0 32.0
cummin函数和cummax函数
累计最大和最小值,工作中其实没遇到,但是这个显然是有用的,同样作用于dataframe,返回的是每一行/列,截止到当前元素的最大值和最小值。
data_b.cummin()data_b.cummax()--输出A B C D0 1.0 1.0 2.0 2.01 1.0 1.0 2.0 2.02 1.0 1.0 1.0 2.03 1.0 1.0 1.0 2.0A B C D0 1.0 1.0 2.0 2.01 2.0 3.0 2.0 2.02 2.0 3.0 2.0 4.03 2.0 3.0 2.0 4.0
pct_change函数
这个函数,特别适合时间序列相关的操作,算的是前后数据的差距百分比,就是后数减前数除以前数。返回的也是和原dataframe行列数一样的dataframe。
data_b.pct_change()-- 输出A B C D0 NaN NaN NaN NaN1 1.0 2.0 0.0 0.02 0.0 0.0 -0.5 1.03 0.0 0.0 1.0 -0.5
diff函数
这个函数和上面那个pct_change函数一样也是用于时间序列的操作,就是向前或者向后截取数据,截取不到的取空,返回的是和原dataframe行列数一样的dataframe。基本用法为diff(periods=1, axis=0),axis我就不解释了,这个periods就是移动的步数,可取正或者负,正就是往下走一步,负就是往上走一步。
data_b.diff(-1)data_b.diff(1)--输出1A B C D0 -1.0 -2.0 0.0 0.01 0.0 0.0 1.0 -2.02 0.0 0.0 -1.0 2.03 NaN NaN NaN NaN--输出20 NaN NaN NaN NaN1 1.0 2.0 0.0 0.02 0.0 0.0 -1.0 2.03 0.0 0.0 1.0 -2.0
shift函数
如果不理解上面两个函数的操作,那么来讲一下shift操作,其实就是数据的移动,是上面两个函数计算的中间步骤。基本用法为shift(periods=1, freq=None, axis=0),这个和diff函数一样一样的,这个freq我稍微解释一下就是按什么技术,默认就是int,还有datetime的例子,因为这个一般用于时间序列的处理。
data_b.shift()-- 输出A B C D0 NaN NaN NaN NaN1 1.0 1.0 2.0 2.02 2.0 3.0 2.0 2.03 2.0 3.0 1.0 4.0
4.数据高阶操作
这部分是笔者在进行一次聚类分析判断nickname是否是全为英文或者汉字字符时发现的,非常好用。
.dt
.str
isalpha ( ) 判断是否全是字母
isdigit ( ) 判断是否全是数字
isalnum ( ) 是否全是数字或字母
isupper ( ) … 大写字母
islower ( ) … 小写字母
istitle ( ) … 首字母大写
isspace() … 空白字符
5.数据保存和转换函数
to_csv函数
这个函数是dataframe的函数,作用是将你计算得到的dataframe转回到excel中以方便下一步的操作。官方给的参数特别多,to_csv(path_or_buf=None, sep=’, ‘, na_rep=’’, float_format=None, columns=None, header=True, index=True, index_label=None, mode=’w’, encoding=None, compression=’infer’, quoting=None, quotechar=’”‘, line_terminator=None, chunksize=None, tupleize_cols=None, date_format=None, doublequote=True, escapechar=None, decimal=’.’)。其实重要的就是指定路径和文件名,指定是否要第一行,是否要索引和列名,指定分隔符,其他都不是特别重要。这个函数我就不写例子了。

若有收获,就点个赞吧
0 人点赞
