初识ID3
回顾决策树的基本知识,其构建过程主要有下述三个重要的问题:
(1)数据是怎么分裂的
(2)如何选择分类的属性
(3)什么时候停止分裂
从上述三个问题出发,以实际的例子对ID3算法进行阐述。
例:通过当天的天气、温度、湿度和季节预测明天的天气
表1 原始数据**
| 当天天气 | 温度 | 湿度 | 季节 | 明天天气 |
|---|---|---|---|---|
| 晴 | 25 | 50 | 春天 | 晴 |
| 阴 | 21 | 48 | 春天 | 阴 |
| 阴 | 18 | 70 | 春天 | 雨 |
| 晴 | 28 | 41 | 夏天 | 晴 |
| 雨 | 8 | 65 | 冬天 | 阴 |
| 晴 | 18 | 43 | 夏天 | 晴 |
| 阴 | 24 | 56 | 秋天 | 晴 |
| 雨 | 18 | 76 | 秋天 | 阴 |
| 雨 | 31 | 61 | 夏天 | 晴 |
| 阴 | 6 | 43 | 冬天 | 雨 |
| 晴 | 15 | 55 | 秋天 | 阴 |
| 雨 | 4 | 58 | 冬天 | 雨 |
1.数据分割
对于离散型数据,直接按照离散数据的取值进行分裂,每一个取值对应一个子节点,以“当前天气”为例对数据进行分割,如图1所示。
对于连续型数据,ID3原本是没有处理能力的,只有通过离散化将连续性数据转化成离散型数据再进行处理。
连续数据离散化是另外一个课题,本文不深入阐述,这里直接采用等距离数据划分的李算话方法。该方法先对数据进行排序,然后将连续型数据划分为多个区间,并使每一个区间的数据量基本相同,以温度为例对数据进行分割,如图2所示。
2. 选择最优分裂属性
<br />ID3采用信息增益作为选择最优的分裂属性的方法,选择熵作为衡量节点纯度的标准,信息增益的计算公式如下:<br /> 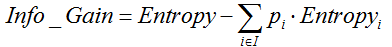
其中,  表示父节点的熵;
表示父节点的熵;  表示节点i的熵,熵越大,节点的信息量越多,越不纯;
表示节点i的熵,熵越大,节点的信息量越多,越不纯;  表示子节点i的数据量与父节点数据量之比。
表示子节点i的数据量与父节点数据量之比。  越大,表示分裂后的熵越小,子节点变得越纯,分类的效果越好,因此选择
越大,表示分裂后的熵越小,子节点变得越纯,分类的效果越好,因此选择  最大的属性作为分裂属性。
最大的属性作为分裂属性。
对上述的例子的跟节点进行分裂,分别计算每一个属性的信息增益,选择信息增益最大的属性进行分裂。
天气属性:(数据分割如上图1所示)

温度:(数据分割如上图2所示)

湿度:

季节:

由于 最大,所以选择属性“季节”作为根节点的分裂属性。
最大,所以选择属性“季节”作为根节点的分裂属性。
3.停止分裂的条件
<br />停止分裂的条件已经在**决策树**中阐述,这里不再进行阐述。<br />
(1)最小节点数
当节点的数据量小于一个指定的数量时,不继续分裂。两个原因:一是数据量较少时,再做分裂容易强化噪声数据的作用;二是降低树生长的复杂性。提前结束分裂一定程度上有利于降低过拟合的影响。
(2)熵或者基尼值小于阀值。
<br />由上述可知,熵和基尼值的大小表示数据的复杂程度,当熵或者基尼值过小时,表示数据的纯度比较大,如果熵或者基尼值小于一定程度时,节点停止分裂。<br />
(3)决策树的深度达到指定的条件
节点的深度可以理解为节点与决策树跟节点的距离,如根节点的子节点的深度为1,因为这些节点与跟节点的距离为1,子节点的深度要比父节点的深度大1。决策树的深度是所有叶子节点的最大深度,当深度到达指定的上限大小时,停止分裂。
(4)所有特征已经使用完毕,不能继续进行分裂
<br />被动式停止分裂的条件,当已经没有可分的属性时,直接将当前节点设置为叶子节点。
程序设计及源代码(C#版本)
(1)数据处理
用二维数组存储原始的数据,每一行表示一条记录,前n-1列表示数据的属性,第n列表示分类的标签。
static double[][] allData;
为了方便后面的处理,对离散属性进行数字化处理,将离散值表示成数字,并用一个链表数组进行存储,数组的第一个元素表示属性1的离散值。
static List<String>[] featureValues;
那么经过处理后的表1数据可以转化为如表2所示的数据:
表2 初始化后的数据
| 当天天气 | 温度 | 湿度 | 季节 | 明天天气 |
|---|---|---|---|---|
| 1 | 25 | 50 | 1 | 1 |
| 2 | 21 | 48 | 1 | 2 |
| 2 | 18 | 70 | 1 | 3 |
| 1 | 28 | 41 | 2 | 1 |
| 3 | 8 | 65 | 3 | 2 |
| 1 | 18 | 43 | 2 | 1 |
| 2 | 24 | 56 | 4 | 1 |
| 3 | 18 | 76 | 4 | 2 |
| 3 | 31 | 61 | 2 | 1 |
| 2 | 6 | 43 | 3 | 3 |
| 1 | 15 | 55 | 4 | 2 |
| 3 | 4 | 58 | 3 | 3 |
其中,对于当天天气属性,数字{1,2,3}分别表示{晴,阴,雨};对于季节属性{1,2,3,4}分别表示{春天、夏天、冬天、秋天};对于明天天气{1,2,3}分别表示{晴、阴、雨}。
**
(2)两个类:节点类和分裂信息
a)节点类Node
<br />该类存储了节点的信息,包括节点的数据量、节点选择的分裂属性、节点输出类、子节点的个数、子节点的分类误差等。
class Node{/// <summary>/// 各个子节点的取值/// </summary>public List<String> features { get; set; }/// <summary>/// 分裂属性的类型/// </summary>public String feature_Type { get; set; }/// <summary>/// 分裂的属性/// </summary>public String SplitFeature { get; set; }/// <summary>/// 节点对应各个分类的数目/// </summary>public double[] ClassCount { get; set; }/// <summary>/// 各个孩子节点/// </summary>public List<Node> childNodes { get; set; }/// <summary>/// 父亲节点(未用到)/// </summary>public Node Parent { get; set; }/// <summary>/// 占比最大的类别/// </summary>public String finalResult { get; set; }/// <summary>/// 数的深度/// </summary>public int deep { get; set; }/// <summary>/// 该节点占比最大的类标号/// </summary>public int result { get; set; }/// <summary>/// 节点的数量/// </summary>public int rowCount{ get; set; }public void setClassCount(double[] count){this.ClassCount = count;double max = ClassCount[0];int result = 0;for (int i = 1; i < ClassCount.Length; i++){if (max < ClassCount[i]){max = ClassCount[i];result = i;}}//wrong = Convert.ToInt32(nums.Count - ClassCount[result]);this.result = result;}}
b)分裂信息类SplitInfo
<br />该类存储节点进行分裂的信息,包括各个子节点的行坐标、子节点各个类的数目、该节点分裂的属性、属性的类型等。
class SplitInfo{/// <summary>/// 分裂的列下标/// </summary>public int splitIndex { get; set; }/// <summary>/// 数据类型/// </summary>public int type { get; set; }/// <summary>/// 分裂属性的取值/// </summary>public List<String> features { get; set; }/// <summary>/// 各个节点的行坐标链表/// </summary>public List<int>[] temp { get; set; }/// <summary>/// 每个节点各类的数目/// </summary>public double[][] class_Count { get; set; }}
(3)节点分裂方法findBestSplit(Node node,List nums,int[] isUsed),该方法对节点进行分裂,返回值Node
其中:
- node表示即将进行分裂的节点;
- nums表示节点数据对应的行坐标列表;
- isUsed表示到该节点位置所有属性的使用情况(1:表示该属性不能再次使用,0:表示该属性可以使用);
findBestSplit主要有以下几个组成部分:
1)节点分裂停止的判定
判断节点是否需要继续分裂,分裂判断条件如上文所述。源代码如下
public static Object[] ifEnd(Node node, double entropy,int[] isUsed){try{double[] count = node.ClassCount;int rowCount = node.rowCount;int maxResult = 0;double maxRate = 0;#region 数达到某一深度int deep = node.deep;if (deep >= maxDeep){maxResult = node.result + 1;node.feature_Type=("result");node.features=(new List<String>() { maxResult + "" });return new Object[] { true, node };}#endregion#region 纯度(其实跟后面的有点重了,记得要修改)//maxResult = 1;//for (int i = 1; i < count.Length; i++)//{// if (count[i] / rowCount >= 0.95)// {// node.setFeatureType("result");// node.setFeatures(new List<String> { "" + (i + 1) });// return new Object[] { true, node };// }//}//node.setLeafWrong(rowCount - Convert.ToInt32(count[maxResult - 1]));#endregion#region 熵为0if (entropy == 0){maxRate = count[0] / rowCount;maxResult = 1;for (int i = 1; i < count.Length; i++){if (count[i] / rowCount >= maxRate){maxRate = count[i] / rowCount;maxResult = i + 1;}}node.feature_Type=("result");node.features=(new List<String> { maxResult + "" });return new Object[] { true, node };}#endregion#region 属性已经分完//int[] isUsed = node.;bool flag = true;for (int i = 0; i < isUsed.Length - 1; i++){if (isUsed[i] == 0){flag = false;break;}}if (flag){maxRate = count[0] / rowCount;maxResult = 1;for (int i = 1; i < count.Length; i++){if (count[i] / rowCount >= maxRate){maxRate = count[i] / rowCount;maxResult = i + 1;}}node.feature_Type=("result");node.features=(new List<String> { "" + (maxResult) });return new Object[] { true, node };}#endregion#region 数据量少于100if (rowCount < Limit_Node){maxRate = count[0] / rowCount;maxResult = 1;for (int i = 1; i < count.Length; i++){if (count[i] / rowCount >= maxRate){maxRate = count[i] / rowCount;maxResult = i + 1;}}node.feature_Type=("result");node.features=(new List<String> { "" + (maxResult) });return new Object[] { true, node };}#endregionreturn new Object[] { false, node };}catch (Exception e){return new Object[] { false, node };}}
2)寻找最优的分裂属性
寻找最优的分裂属性需要计算每一个分裂属性分裂后的信息增益,计算公式上文已给出,其中熵的计算代码如下:
public static double CalEntropy(double[] counts, int countAll){try{double allShang = 0;for (int i = 0; i < counts.Length; i++){if (counts[i] == 0){continue;}double rate = counts[i] / countAll;allShang = allShang + rate * Math.Log(rate, 2);}return -allShang;}catch (Exception e){return 0;}}
3)进行分裂,同时子节点也执行相同的分类步骤
其实就是递归的过程,对每一个子节点执行findBestSplit方法进行分裂。
全部源代码:
#region ID3核心算法/// <summary>/// 测试/// </summary>/// <param name="node"></param>/// <param name="data"></param>public static String findResult(Node node, String[] data){List<String> featrues = node.features;String type = node.feature_Type;if (type == "result"){return featrues[0];}int split = Convert.ToInt32(node.SplitFeature);List<Node> childNodes = node.childNodes;double[] resultCount = node.ClassCount;if (type == "连续"){for (int i = 0; i < featrues.Count; i++){double value = Convert.ToDouble(featrues[i]);if (Convert.ToDouble(data[split]) <= value){return findResult(childNodes[i], data);}}return findResult(childNodes[featrues.Count], data);}else{for (int i = 0; i < featrues.Count; i++){if (data[split] == featrues[i]){return findResult(childNodes[i], data);}if (i == featrues.Count - 1){double count = resultCount[0];int maxInt = 0;for (int j = 1; j < resultCount.Length; j++){if (count < resultCount[j]){count = resultCount[j];maxInt = j;}}return findResult(childNodes[0], data);}}}return null;}/// <summary>/// 判断是否还需要分裂/// </summary>/// <param name="node"></param>/// <returns></returns>public static Object[] ifEnd(Node node, double entropy,int[] isUsed){try{double[] count = node.ClassCount;int rowCount = node.rowCount;int maxResult = 0;double maxRate = 0;#region 数达到某一深度int deep = node.deep;if (deep >= maxDeep){maxResult = node.result + 1;node.feature_Type=("result");node.features=(new List<String>() { maxResult + "" });return new Object[] { true, node };}#endregion#region 纯度(其实跟后面的有点重了,记得要修改)//maxResult = 1;//for (int i = 1; i < count.Length; i++)//{// if (count[i] / rowCount >= 0.95)// {// node.setFeatureType("result");// node.setFeatures(new List<String> { "" + (i + 1) });// return new Object[] { true, node };// }//}//node.setLeafWrong(rowCount - Convert.ToInt32(count[maxResult - 1]));#endregion#region 熵为0if (entropy == 0){maxRate = count[0] / rowCount;maxResult = 1;for (int i = 1; i < count.Length; i++){if (count[i] / rowCount >= maxRate){maxRate = count[i] / rowCount;maxResult = i + 1;}}node.feature_Type=("result");node.features=(new List<String> { maxResult + "" });return new Object[] { true, node };}#endregion#region 属性已经分完//int[] isUsed = node.;bool flag = true;for (int i = 0; i < isUsed.Length - 1; i++){if (isUsed[i] == 0){flag = false;break;}}if (flag){maxRate = count[0] / rowCount;maxResult = 1;for (int i = 1; i < count.Length; i++){if (count[i] / rowCount >= maxRate){maxRate = count[i] / rowCount;maxResult = i + 1;}}node.feature_Type=("result");node.features=(new List<String> { "" + (maxResult) });return new Object[] { true, node };}#endregion#region 数据量少于100if (rowCount < Limit_Node){maxRate = count[0] / rowCount;maxResult = 1;for (int i = 1; i < count.Length; i++){if (count[i] / rowCount >= maxRate){maxRate = count[i] / rowCount;maxResult = i + 1;}}node.feature_Type=("result");node.features=(new List<String> { "" + (maxResult) });return new Object[] { true, node };}#endregionreturn new Object[] { false, node };}catch (Exception e){return new Object[] { false, node };}}#region 排序算法public static void InsertSort(double[] values, List<int> arr, int StartIndex, int endIndex){for (int i = StartIndex + 1; i <= endIndex; i++){int key = arr[i];double init = values[i];int j = i - 1;while (j >= StartIndex && values[j] > init){arr[j + 1] = arr[j];values[j + 1] = values[j];j--;}arr[j + 1] = key;values[j + 1] = init;}}static int SelectPivotMedianOfThree(double[] values, List<int> arr, int low, int high){int mid = low + ((high - low) >> 1);//计算数组中间的元素的下标//使用三数取中法选择枢轴if (values[mid] > values[high])//目标: arr[mid] <= arr[high]{swap(values, arr, mid, high);}if (values[low] > values[high])//目标: arr[low] <= arr[high]{swap(values, arr, low, high);}if (values[mid] > values[low]) //目标: arr[low] >= arr[mid]{swap(values, arr, mid, low);}//此时,arr[mid] <= arr[low] <= arr[high]return low;//low的位置上保存这三个位置中间的值//分割时可以直接使用low位置的元素作为枢轴,而不用改变分割函数了}static void swap(double[] values, List<int> arr, int t1, int t2){double temp = values[t1];values[t1] = values[t2];values[t2] = temp;int key = arr[t1];arr[t1] = arr[t2];arr[t2] = key;}static void QSort(double[] values, List<int> arr, int low, int high){int first = low;int last = high;int left = low;int right = high;int leftLen = 0;int rightLen = 0;if (high - low + 1 < 10){InsertSort(values, arr, low, high);return;}//一次分割int key = SelectPivotMedianOfThree(values, arr, low, high);//使用三数取中法选择枢轴double inti = values[key];int currentKey = arr[key];while (low < high){while (high > low && values[high] >= inti){if (values[high] == inti)//处理相等元素{swap(values, arr, right, high);right--;rightLen++;}high--;}arr[low] = arr[high];values[low] = values[high];while (high > low && values[low] <= inti){if (values[low] == inti){swap(values, arr, left, low);left++;leftLen++;}low++;}arr[high] = arr[low];values[high] = values[low];}arr[low] = currentKey;values[low] = values[key];//一次快排结束//把与枢轴key相同的元素移到枢轴最终位置周围int i = low - 1;int j = first;while (j < left && values[i] != inti){swap(values, arr, i, j);i--;j++;}i = low + 1;j = last;while (j > right && values[i] != inti){swap(values, arr, i, j);i++;j--;}QSort(values, arr, first, low - 1 - leftLen);QSort(values, arr, low + 1 + rightLen, last);}#endregion/// <summary>/// 寻找最佳的分裂点/// </summary>/// <param name="num"></param>/// <param name="node"></param>public static Node findBestSplit(Node node, int lastCol,List<int> nums,int[] isUsed){try{//判断是否继续分裂double totalShang = CalEntropy(node.ClassCount, nums.Count);Object[] check = ifEnd(node, totalShang, isUsed);if ((bool)check[0]){node = (Node)check[1];return node;}#region 变量声明SplitInfo info = new SplitInfo();//int[] isUsed = node.getUsed(); //连续变量or离散变量//List<int> nums = node.getNum(); //样本的标号int RowCount = nums.Count; //样本总数double jubuMax = 0; //局部最大熵#endregionfor (int i = 0; i < isUsed.Length - 1; i++){if (isUsed[i] == 1){continue;}#region 离散变量if (type[i] == 0){int[] allFeatureCount = new int[0]; //所有类别的数量double[][] allCount = new double[allNum[i]][];for (int j = 0; j < allCount.Length; j++){allCount[j] = new double[classCount];}int[] countAllFeature = new int[allNum[i]];List<int>[] temp = new List<int>[allNum[i]];for (int j = 0; j < temp.Length; j++){temp[j] = new List<int>();}for (int j = 0; j < nums.Count; j++){int index = Convert.ToInt32(allData[nums[j]][i]);temp[index - 1].Add(nums[j]);countAllFeature[index - 1]++;allCount[index - 1][Convert.ToInt32(allData[nums[j]][lieshu - 1]) - 1]++;}double allShang = 0;for (int j = 0; j < allCount.Length; j++){allShang = allShang + CalEntropy(allCount[j], countAllFeature[j]) * countAllFeature[j] / RowCount;}allShang = (totalShang - allShang);if (allShang > jubuMax){info.features=new List<String>();info.type=0;info.temp=(temp);info.splitIndex=(i);info.class_Count=(allCount);jubuMax = allShang;allFeatureCount = countAllFeature;}}#endregion#region 连续变量else{double[] leftCount = new double[classCount]; //做节点各个类别的数量double[] rightCount = new double[classCount]; //右节点各个类别的数量double[] values = new double[nums.Count];List<String> List_Feature = new List<string>();for (int j = 0; j < values.Length; j++){values[j] = allData[nums[j]][i];}QSort(values, nums, 0, nums.Count - 1);int eachNum = nums.Count / 5;double lianxuMax = 0; //连续型属性的最大熵int index = 1;double[][] counts = new double[5][];List<int>[] temp = new List<int>[5];for (int j = 0; j < 5; j++){counts[j] = new double[classCount];temp[j] = new List<int>();}for (int j = 0; j < nums.Count - 1; j++){if (j >= index * eachNum&&index<5){List_Feature.Add(allData[nums[j]][i]+"");lianxuMax += eachNum*CalEntropy(counts[index - 1], eachNum)/RowCount;index++;}temp[index-1].Add(nums[j]);counts[index - 1][Convert.ToInt32(allData[nums[j]][lieshu - 1])-1]++;}lianxuMax += ((eachNum + nums.Count % 5)*CalEntropy(counts[index - 1], eachNum + nums.Count % 5) / RowCount);lianxuMax = totalShang - lianxuMax;if (lianxuMax > jubuMax){info.splitIndex=(i);info.features=(List_Feature);info.type=(1);jubuMax = lianxuMax;info.temp=(temp);info.class_Count=(counts);}}#endregion}#region 如何找不到最佳的分裂属性,则设为叶节点if (info.splitIndex == -1){double[] finalCount = node.ClassCount;double max = finalCount[0];int result = 1;for (int i = 1; i < finalCount.Length; i++){if (finalCount[i] > max){max = finalCount[i];result = (i + 1);}}node.feature_Type=("result");node.features=(new List<String> { "" + result });return node;}#endregionint deep = node.deep;#region 分裂node.SplitFeature=("" + info.splitIndex);List<Node> childNode = new List<Node>();int[] used = new int[isUsed.Length];for (int i = 0; i < used.Length; i++){used[i] = isUsed[i];}if (info.type == 0){used[info.splitIndex] = 1;node.feature_Type=("离散");}else{used[info.splitIndex] = 0;node.feature_Type=("连续");}int sumLeaf = 0;int sumWrong = 0;List<int>[] rowIndex = info.temp;List<String> features = info.features;for (int j = 0; j < rowIndex.Length; j++){if (rowIndex[j].Count == 0){continue;}if (info.type == 0)features.Add(""+(j+1));Node node1 = new Node();//node1.setNum(info.getTemp()[j]);node1.setClassCount(info.class_Count[j]);//node1.setUsed(used);node1.deep=(deep + 1);node1.rowCount = info.temp[j].Count;node1 = findBestSplit(node1, info.splitIndex,info.temp[j], used);childNode.Add(node1);}node.features=(features);node.childNodes=(childNode);#endregionreturn node;}catch (Exception e){Console.WriteLine(e.StackTrace);return node;}}/// <summary>/// 计算熵/// </summary>/// <param name="counts"></param>/// <param name="countAll"></param>/// <returns></returns>public static double CalEntropy(double[] counts, int countAll){try{double allShang = 0;for (int i = 0; i < counts.Length; i++){if (counts[i] == 0){continue;}double rate = counts[i] / countAll;allShang = allShang + rate * Math.Log(rate, 2);}return -allShang;}catch (Exception e){return 0;}}#endregion
(注:上述代码只是ID3的核心代码,数据预处理的代码并没有给出,只要将预处理后的数据输入到主方法findBestSplit中,就可以得到最终的结果)
总结
<br />ID3是基本的决策树构建算法,作为决策树经典的构建算法,其具有结构简单、清晰易懂的特点。虽然ID3比较灵活方便,但是有以下几个缺点:<br /> (1)采用信息增益进行分裂,分裂的精确度可能没有采用信息增益率进行分裂高<br /> (2)不能处理连续型数据,只能通过离散化将连续性数据转化为离散型数据<br /> (3)不能处理缺省值<br /> (4)没有对决策树进行剪枝处理,很可能会出现过拟合的问题

若有收获,就点个赞吧
0 人点赞
