机械学习中的分箱处理
在机械学习中,我们经常会对数据进行分箱处理的操作, 也就是 把一段连续的值切分成若干段,每一段的值看成一个分类。这个把连续值转换成离散值的过程,我们叫做分箱处理。
比如,把年龄按15岁划分成一组,0-15岁叫做少年,16-30岁叫做青年,31-45岁叫做壮年。在这个过程中,我们把连续的年龄分成了三个类别,“少年”,“青年”和“壮年”就是各个类别的名称,或者叫做标签。
cut和qcut函数的基本介绍
在pandas中,cut和qcut函数都可以进行分箱处理操作。其中cut函数是按照数据的值进行分割,而qcut函数则是根据数据本身的数量来对数据进行分割。
下面我们举两个简单的例子来说明cut和qcut的用法。
首先我们准备一组连续的数据:
import pandas as pdd = pd.DataFrame([x**2 for x in range(11)],columns=['number'])display(d)

cut:按变量的值进行分割
例子:按照数据值由小到大的顺序将数据分成4份,并且使每组值的范围大致相等。
# cut:按照数据值由小到大的顺序将数据分成4份, 并且使每组值的范围大致相等。d_cut = d.copy()d_cut['cut_group'] =pd.cut(d_cut['number'], 4)d_cut

我们可以看到, 上面的代码把数据按照由小到大的顺序平均切分成了4份, 每份的值的跨度大约是25。
其中, (a1, a2]表示 a < x <= b, 默认情况下, 每个区间包括最大值, 不包括最小值。但是最左边的值, 一般设置成最小值(0)减去最大值(100)的0.1%, 也就是0 - 100*0.1% = -0.1。
我们查看一下上面每个分组里变量的个数。
# 查看每个分组里变量的个数d_cut['cut_group'].value_counts()

可以看到,每个分组里数据的个数并不一样。
如果希望每个分组里的数据个数一样,我们就要用到了qcut方法。
qcut : 按数据的数量进行分割
跟cut()按照变量的值对变量进行分割不同, qcut()是按变量的数量来对变量进行分割,并且尽量保证每个分组里变量的个数相同。
例子:把数据由小到大分成四组,并且让每组数据的数量相同
# 把变量由小到大分成四组,并且让每组变量的数量相同d_qcut = d.copy()d_qcut['qcut_group'] = pd.qcut(d_qcut['number'], 4)d_qcut

# 查看每个分组里变量的个数d_qcut['qcut_group'].value_counts()

从上面的结果我们可以看到,使用qcut()对数据进行分割之后,每个分组里的数据个数都大致相同,但是跟cut()不同的是,每个分组里值的范围并不相同。
cut和qcut函数的拓展用法
上面的内容说明了cut和qcut函数的基本区别,接下来我们来补充一些这两个函数的其它用法。
cut()
例子1:bins参数
按照指定的边界值对变量进行分割
# 使用bins参数, 指定每个分组的边界d_cut_bins = d.copy()d_cut_bins['cut_group'] = pd.cut(d_cut_bins['number'],bins=[0, 10, 50, 100])d_cut_bins

上面的代码里, 我们使用bins参数指定了各个分组的分界点0, 10, 50和100, 最终得到了0-10, 10-50, 50-100三个区间的分组。
例子2 : retbins参数
获取边界值的列表
我们可以通过在cut函数里设置retbins参数, 来获取边界值的列表。当设置了retbins参数之后, cut()方法可以同时返回切分好的分组, 以及各个分组的边界值。
# 通过设置retbins参数获取边界值列表d_cut_retbins = d.copy()d_cut_retbins['cut_group'], bins = pd.cut(d_cut_retbins['number'], 4, retbins=True)display('bins : {}'.format(bins))

例子3 :right参数
设定分组的开闭区间
默认情况下, 每个分组的左边为开区间, 右边为闭区间, 比如上面的(-0.1, 25.0]。而当我们把参数right设置成False, 左右的开闭区间便互相调换了位置, 成了[0.0, 25.0)。
# 通过设定参数right为False, 调换开闭区间的位置。d_cut = d.copy()d_cut['cut_group'] = pd.cut(d_cut['number'], 4, right=False)d_cut
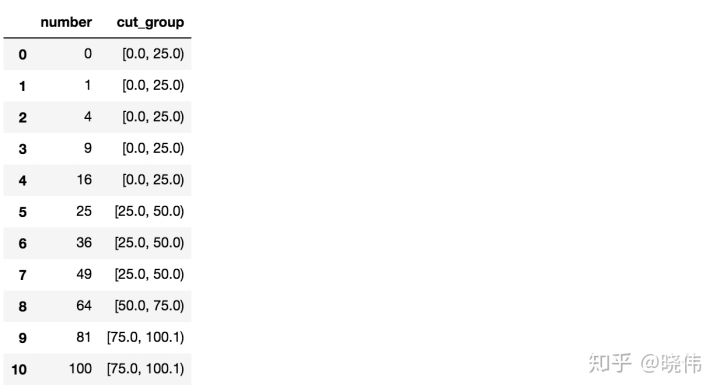
从上面的结果我们可以看到, 原本左开右闭的区间, 变成了左闭右开的区间。
例子4 : labels参数
改变cut_group列里显示的类型标签
到目前为止, 我们cut列中的内容都是以(0.0, 25.0]这样的开闭区间的形式来表示各个分组。 但实际操作中, 我们可能需要更简单的显示方式, 比如1, 2, 3…这样的连续的数字。
上面的想法我们可以通过改变labels的值来实现。默认的情况下, labels=None, 也就是开闭区间的形式; 当我们把labels设置成False的时候, 就可以改成数字的形式了。
# 把cut列的内容由开闭区间的形式改成数字的形式。d_cut = d.copy()d_cut['cut_group'] = pd.cut(d_cut['number'], 4, labels=False)d_cut

我们可以看到, 上面的cut_group的标签由开闭区间改变成了数字。
例子5 : labels参数
自定义cut_group列中的类型标签
通过给labels参数指定一个列表,我们可以把cut_group列中的类型标签自定义成自己想要的内容。
# 把cut_group列中的类型标签自定义为small, medium, large和x-larged_cut = d.copy()d_cut['cut_group'] = pd.cut(d_cut['number'], 4,labels=['small', 'medium', 'large', 'x-large'])d_cut

qcut()
例1:retbins参数
获取分组边界值的列表
跟cut()一样, 我们可以通过在qcut()设置retbins参数, 获取每个分组的边界值列表。
# 获取每个分组的边界值列表d_qcut = d.copy()d_qcut['qcut_group'], bins = pd.qcut(d_qcut['number'], 4, retbins=True)bins

例2:labels参数
自定义分组标签的内容
通过设置labels参数, 我们可以自定义分组标签的内容。
# 自定义分组标签的内容d_qcut = d.copy()d_qcut['qcut_group'] = pd.qcut(d_qcut['number'], 4,labels=['A', 'B', 'C', 'D'])d_qcut

从上面可以看到, 我们通过给labels参数设定自定义的列表, 从而改变了qcut_group中显示的内容。
总结
综上所述, 我们可以看到, cut()和qcut()的主要作用都是对若干连续变量进行分箱操作。但有所不同的是, cut()是按变量的值进行划分, 而qcut()是按照变量的个数进行划分。

若有收获,就点个赞吧
0 人点赞
