阅读:2022.05.07
刊物:T-PAMI
引用:S. -C. Huang, T. -H. Le and D. -W. Jaw, “DSNet: Joint Semantic Learning for Object Detection in Inclement Weather Conditions,” in IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 43, no. 8, pp. 2623-2633, 1 Aug. 2021, doi: 10.1109/TPAMI.2020.2977911.
1 概述
说来也是巧合,没看到这个论文前,我也有类似的想法。
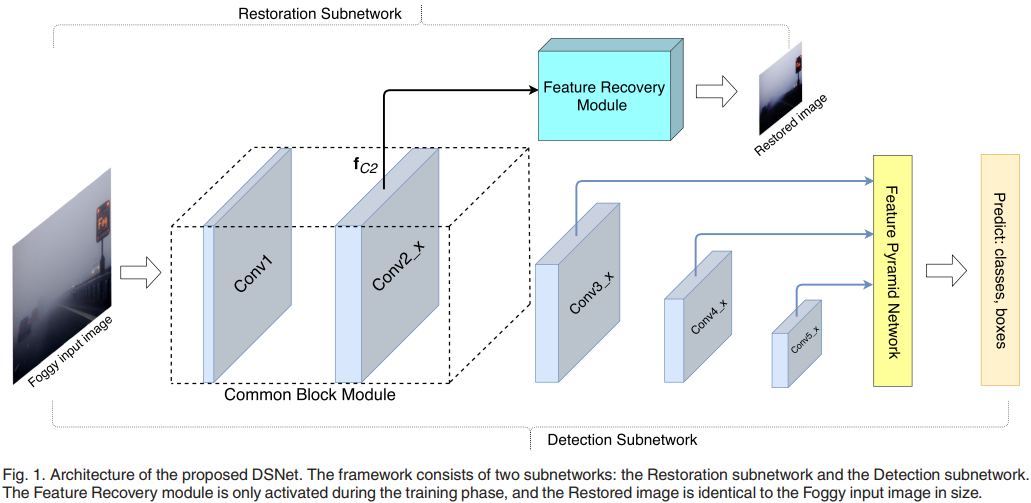
- DSNet 框架
- DSNet在RetinaNet的基础上,引入了一个 restoration subnet 用于生成 clean image,其特征提取部分与RetinaNet的前两个block共用,该部分受到3种任务的学习(visibility enhancement, object classification, object localization)
- 我的认识:通过重构clean image,迫使 conv1,conv2在学习捕获用于目标检测的图像特征外,也能够学习用重构图像细节的信息
- 目标检测:侧重学习high-level feature、语义特征,更抽象的特征
- 图像重构:侧重学习low-level feature、细节纹理信息
- 文中描述:通过采用联合优化的策略,visibility enhancement 能够共享restoration subnet 从模糊输入图像中生成的干净特征以增强可见性,以在检测子网络中学习更好的对象分类和对象定位
- 我的认识:通过重构clean image,迫使 conv1,conv2在学习捕获用于目标检测的图像特征外,也能够学习用重构图像细节的信息
- DSNet在RetinaNet的基础上,引入了一个 restoration subnet 用于生成 clean image,其特征提取部分与RetinaNet的前两个block共用,该部分受到3种任务的学习(visibility enhancement, object classification, object localization)
- 损失函数
- Detection subnetwork:常用的检测函数

- Restortation subnetwork:常采用MSE损失

- 数据集
2 值得借鉴
- multi-mask learning
多任务的说法可以借鉴:
- visibility enhancement
- object classification
- object localization
- 问题的分析
- 结合现实场景(自动驾驶)来描述
- 已有的目标检测方法能够有效的应用于高质量的图像,但是对于 inclement weather conditions (fog, low-light)场景下的性能较差,而这些场景是车辆驾驶中最常见的。
- 原因:被捕获的物体和相机之间的特定光谱被悬浮的微小水滴、冰晶、灰尘和其他颗粒吸收和散射,从而降低了从这些图像中提取的用于物体目的的特征 检测。(The reason for this is that the specific light spectra between the specific light spectra between the objects being captured and the camera are absorbed and scattered by suspended tiny water droplets, ice crystals, dust, and other particles, which degrade the features extracted from these images for the purpose of object detection. )
- 已有的解决方案:图像预处理+目标检测
- 引入去雾、照度增强算法来预处理(preprocess step)图像,该类与处理算法有利于有助于人类对图像质量的视觉感知以及许多必须在不同天气条件下运行的系统,例如交通监控系统、智能车辆和户外物体识别系统。
- 预处理后的图像送入目标检测中并不一定会增强性能。
- 加入预处理操作后,该类检测算法的速度较慢。
- 用了别人的算法,怎么在文章中写的不是那么简单的挪用,参考3.1。
- 如何将简单的算法描述清楚,且显得不那么单调,浅薄。
3 DSNet
为提升目标检测算法在 inclement weather 中的性能,DSNet利用三个学习联合学习来实现:visibility enhancement, object classification, object localization。DSNet主要由两个自网络组成:restoration subnet, detection subnet。
- detection subnet:实际上是RetinaNet,用于目标检测、定位,前两个conv block与restoration subnet共享,称之为common block (CB)。
restoration subnet:用于还原一张清晰的图像,但是其目的并不是生成清晰的图像,而是促使CB 学习到clean features。其与detection subnet共享CB,利用CB提取图像特征,送入feature recovery (FR) 中生成图像。
3.1 Detection subnetwork
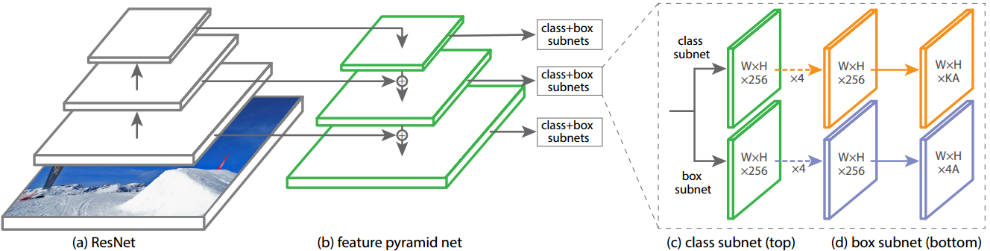
DSNet的主体结构是RetinaNet,详细介绍看RetinaNet的笔记。
RetinaNet3.2 Restoration subnetwork
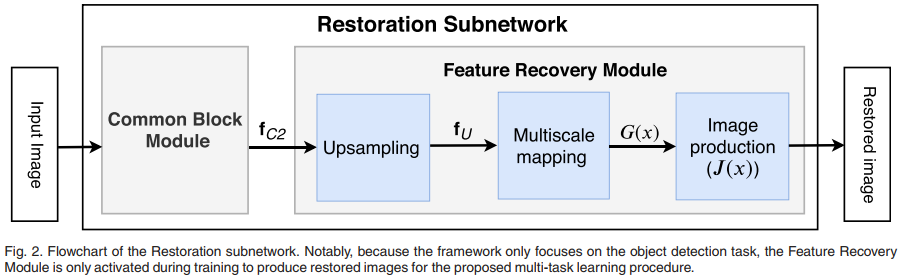
Restoration subnetwork 用于生成clean feature,并将其分享给detection subnetwork,以提高模型在恶劣天气下的检测性能。
Restoration subnetwork
Restoration subnetwork 基于大气散射模型生成干净的图像: : foggy image;
: foggy image; : clean image
: clean image : global atmospheric light;
: global atmospheric light; :medium transmission map;
:medium transmission map; :大气散射系数;
:大气散射系数; :scence depth
:scence depth
如果直接采用上述公式计算干净的图像,需要更多的步骤、且增加了算法的复杂度。受启发于AODNet,restoration subnet将 合并成一个
合并成一个 ,利用FR模块来学习
,利用FR模块来学习 ,则上述式子可改写为:
,则上述式子可改写为:
3.2.1 CB
CB没有单独设计,而是直接采用detection subnetwork 的前10层conv layer。C1,C2捕获的是浅层特征,包含大量的空间信息,有利于重构图像。
3.2.2 FR
由于有雾气,CB从输入图像中捕获的特征是退化的,从而导致了模型性能较差。FR 利用该类特征重构干净图像,从而还原该类特征所包含的信息。FR包含3部分:upsampling submodule, multiscale mapping (MM) submodule, image production (IP) submodule.
upsampling submodule
CB输出特征的尺寸是输入图像1/4,通过上采样还原尺寸。
首先采用 1*1 conv 调整通道数,再用 bilinear interpolation 完成上采样。
- MM
用于提取多尺度特征,4个分支:
- 1个11 conv;1个33 conv;1个77 conv;1个55 conv
- 通道数均为4
- 融合各个特征后利用一个3*3 conv 学习

- IP
实现下面的式子,得到输出图像
4 Dataset
4.1 Train set
本文提出了一个FOD (fog object detection) 数据集
已有的数据集
RTTS,hazzy images,常用于测试
- 4322 张自然的hazy images】
- 5个类别:bus, bicycle, car, motorbike, person
B. Li et al., “Benchmarking single-image dehazing and beyond,” IEEE Trans. Image Process., vol. 28, no. 1, pp. 492–505, Jan. 2018.
Li:rainy images,
- 2000 images
- 5个类别:bus, bicycle, car, motorbike, person
- 带bounding boxes label
S. Li et al., “Single image deraining: A comprehensive benchmark analysis,” in Proc. IEEE Conf. Compute. Vis. Pattern Recognit., 2019, pp. 3838–3847.
Foggy Cityscapess-refined dataset
- 550 images (498 for training, 52 for testing)
C. Sakaridis, D. Dai, and L. V. Gool, “Semantic foggy scene understanding with synthetic data,” Int. J. Comput. Vis., vol. 126, no. 9, pp. 973–992, 2018.
- 550 images (498 for training, 52 for testing)
FOD
- 从 Foggy Cityscapes dataset 中选取图片,并标记2个类(car, person)
- 从3个版本的 Foggy Cityscapes dataset 中选择6000张图像,3个版本即有不同程度雾气的图像
- heavy fog (0.02), medium fog (0.01), light fog (0.005)
- 共 119, 979 个标注实例,其中60,279 个人,59,700辆车

FOD 数据集
4.2 Test set
在FOD、foggy driving dataset(真实数据集)两个数据集上测试

若有收获,就点个赞吧
0 人点赞
