阅读:2022.05.09
刊物:ICIP 2021
引用:Hnewa M, Radha H. Multiscale domain adaptive yolo for cross-domain object detection[C]//2021 IEEE International Conference on Image Processing (ICIP). IEEE, 2021: 3323-3327.
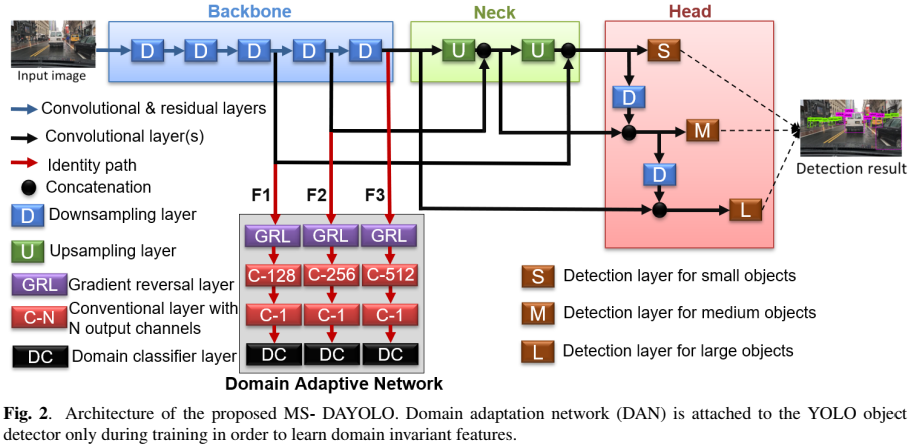
1 概述
本文发表于ICIP2021,篇幅较短(正文4页)。
domain adaption 已经广泛应用于具有domain shift的问题中,并且取得不错的效果。这一点跟恶劣天气的所获得图像所契合,恶劣天气下获得的图像(低质图像)相比于正常天气的图像(高质量图像),其特征分布有一定的偏差,即使增强之后仍然会有一定的差异。因此 domain adaption 正适合用于恶劣天气下的检测、分割任务,用于矫正低质图像和高质量图像之间的分布差异,获取两者之间共有的、不变的的特征分布(domain-invariant features)。
- MSDA-YOLO 框架
基于YOLOv4,在backbone后3个block的输出上加了一个domain adaptive network (DAN)。
- 后3个block的输出是不同的scale,这也是题目中 multiscale 的体现。
- 每个block的输出都将送入 domain classifiers,以引导backbone学习 domain-invariant features。
- 损失函数
detection loss + domain classifier loss
- detection loss:采用YOLO v1的损失
- domain classifier loss:binary cross entropy
- 数据集
训练时,采用source dataset + target dataset
- source dataset: 用于训练YOLO v4部分,有标签
- target dataset: 用于训练DAN部分,通常无标签
- clear —> foggy:
- source dataset: Cityscapes
- target dataset: Foggy Cityscapes training set
- Sunny —> Rainy:
2.1 问题/必要性分析
目前,在普通场景下的检测算法已经有了广泛的研究,但是对于恶劣天气场景,相关的研究仍然不多。这类问题又可以这样描述:
Under a domain shift, when the testing data has a different distribution from the training data distribution, the performance of state-of-the-art object detection methods drop noticeably and sometimes significantly.
即:低质图像的分布/domain 相比较于高质量图像已经发生了偏移(domain-shift),导致将高质量图像训练的检测算法应用于低质图像的性能差(训练、测试数据之间的分布发生了变换)。也可以说是算法的鲁棒性不够,受到了恶劣天气情况的影响,无法提取有效的图像特征。因此需要提高特征的鲁棒性,使其能够不够天气因素的影响,提取图像特征(不管是低质/高质图像,去除天气因素后,他们本质的特征是类似的,这类特征也称为 domain-invariant features)。
在这种情况下,训练数据的domain 称之为 source domain,测试数据的domain 称之为 target domain。
低质图像 = 高质图像 + 天气因素(weather information)

2.2 挑战
lack of annotated target domain data.
2.3 方案:domain adaptation,用于解决domain shift 问题
- 不依赖标注的数据(annotate data)
- 用来自source domain 带标签的数据 和 来自target domain 无标签的数据 训练网络,以获得一个robust object detector。
- 训练策略:通常采用 adversarial training strategy 来训练 domain classifier,该策略使得feature extractor能够学习到 domain invariant features。
- domain classifier:被训练用来区分数据是来自source domain 还是 target domain。
- feature extractor:被训练用于混淆 domain classifier
- 基本检测框架的选择
- faster RCNN:准确率高,但是慢
- YOLO 系列:速度快,但是准确率不是最高
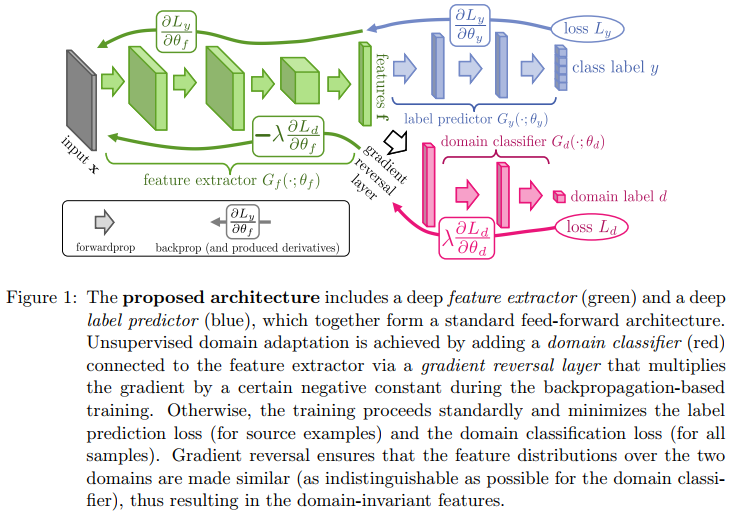
2.4 domain adaptation
Yaroslav Ganin, Evgeniya Ustinova, Hana Ajakan, Pascal Germain, Hugo Larochelle, Franc¸ois Laviolette, Mario Marchand, and Victor Lempitsky, “Domainadversarial training of neural networks,” The Journal of Machine Learning Research, vol. 17, no. 1, pp. 2096–2030, 2016
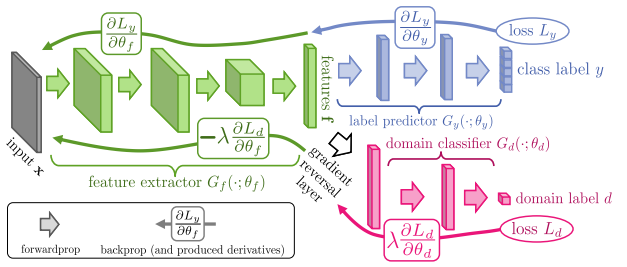
在source domain上训练,同时要求在target domain也能够有不错的性能,在具有不同特征分布的数据集之间找一种合适的“迁移”。如下图,该模型主要包含3个部分,
- 绿色:feature extractor (相当于backdone),得到的特征是共享的,目的是提取出domain-invariant features
- 蓝色:label predictor (相当于detector),对source domain进行相应的任务(分类,定位)
- 粉色:domain classifier,二分类,区分source domain 、target domain
3 MSDA-YOLO
3.1 YOLO v4
主要包括3部分:bakcbone, neck, head
- backbone:darknet53
- neck:特征金字塔
- head: 密集预测
3.2 Domain Adaptive Network for YOLO (DAN)
DAN仅在训练阶段起作用,测试阶段不用,从而不会影响网络的测试速度,可适用于real time的检测。
DAN 通过训练,能够区分 source domain、target domain (二分类)。
DAN作为一个辅助训练分支,用于提升backbone对 domain invariant features的学习。即,backbone提取的特征,应该是难以区分的,即难以区分是属于source domain,还是target domain(提取的特征是source domain 和target domain 共有的),从而提高模型在target domain上的性能。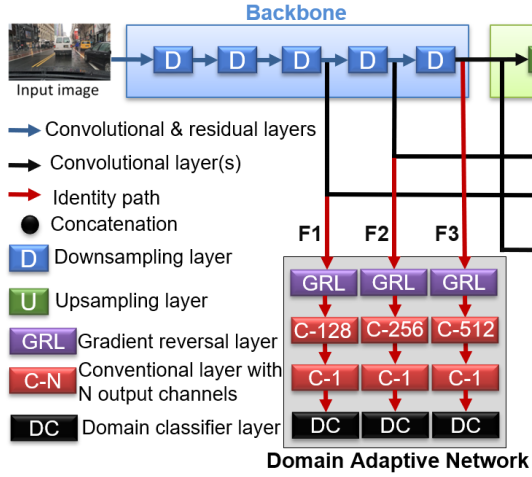
- Input:
采用neck的三个输入,即backbone后3个block的输出(multiscale feature),作为DAN的输入。
- Loss function
采用 binary cross entropy 计算损失: :第 i 张训练图片的 ground truth domain label。
:第 i 张训练图片的 ground truth domain label。 :第 i 张训练图片在特征图位置(x, y)预测的domain class probabilities。
:第 i 张训练图片在特征图位置(x, y)预测的domain class probabilities。
- Gradient Reversal Layer (GRL)
用于实现2个不同的优化策略 (bidirectional operator,矛盾的操作 ),类似GAN的操作(min, max)
- 为什么需要GRL?
- 蓝色部分的目的是最小化分类、定位误差,粉色部分的目的是最小化二分类误差
- 绿色部分提取的特征,同时给蓝色、粉色部分处理,则该部分学习特征时有两个目标:
- 最小化目标检测损失(分类、定位)
- 最大化二分类误差(对抗紫色部分),这个就需要GRL实现。Domain adapation的目的就时要让那个绿色部分难以区分source domain和target domain,即学习 domain-invariant features。
- 为什么不直接在 domain classification loss 前直接加 “-”
 ?
?
如下图,很明显,RGL是介于绿色、粉色之间的,对于绿色部分的梯度是 negative,对于粉色部分的梯度是positive。如果直接改成 ,则粉色部分的梯度也是 negative。
,则粉色部分的梯度也是 negative。
- feed-forward direction
相当于一个判别操作,这导致了在 DAN 中执行局部反向传播时最小化分类错误的标准目标
- backpropagation
- 在绿色部分,相当于一个 negative factor,此时在,它会导致二进制分类误差最大化; 这种最大化促进了骨干网生成域不变特征。
- 在蓝色部分,还是正常的梯度传播,优化domain classifier 最小化二分类损失
GRL code
class GRL(torch.autograd.Function):def __init__(self, lambda):super(GRL, self).__init__()self.lambda = lambdadef forward(self, x):return x.view_as(x)def backward(self, grad_output):grad_input = grad_output.clone()return grad_input * (-self.lambda)def set_lambda(self, lambda):self.lambda = lambda
References
Cityscapes:
Marius Cordts, Mohamed Omran, Sebastian Ramos, Timo Rehfeld, Markus Enzweiler, Rodrigo Benenson,
Uwe Franke, Stefan Roth, and Bernt Schiele, “The cityscapes dataset for semantic urban scene understanding,” in Proc. CVPR, 2016, pp. 3213–3223Foggy Cityscapes
Christos Sakaridis, Dengxin Dai, and Luc Van Gool, “Semantic foggy scene understanding with synthetic
data,” International Journal of Computer Vision, vol. 126, no. 9, pp. 973–992, 2018BDD100K
Fisher Yu, Wenqi Xian, Yingying Chen, Fangchen Liu, Mike Liao, Vashisht Madhavan, and Trevor Darrell, “Bdd100k: A diverse driving video database with scalable annotation tooling,” arXiv preprint
arXiv:1805.04687, 2018INIT
Zhiqiang Shen, Mingyang Huang, Jianping Shi, Xiangyang Xue, and Thomas Huang, “Towards instancelevel image-to-image translation,” in Proc. CVPR, 2019.

若有收获,就点个赞吧
0 人点赞
