阅读:2010.8.7-8.14
期刊:CVPR 2017
引用:Redmon J, Farhadi A. YOLO9000: Better, Faster, Stronger[C]// IEEE Conference on Computer Vision & Pattern Recognition. 2017.
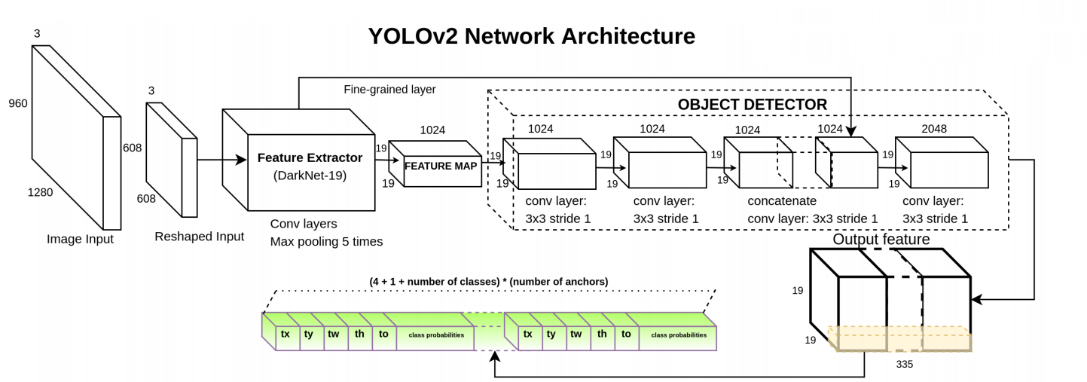
1 YOLO V2概述
本文改进了YOLO V1,提出了YOLO V2;同时提出了YOLO 9000,能够同时检测9418个类别。
1. 改进YOLO V1,提出YOLO V2
(1)为解决YOLO V1的bbox定位不准确,引入anchor box,但又不同于Faster R-CNN的anchor box,首先,本文中的anchor box的宽高由网络学习得到(k-mean聚类),而非手动设置,其次,改“预测anchor box到bbox的偏移量”为“预测bbox的中心坐标”;
(2)为了提升YOLO V1的recall,每个cell生成了更多的bbox(YOLO V1只有2个),且每个bbox都有自己的类别概率,而不是像YOLO V1,每个cell的2个bbox都共用1个分类概率;
(3)为提升YOLO V1对小目标的检测准确率,采用的了特征重排的方法。因为考虑到最终送入检测器的特征图为13x13,对检测小物体而言精度不够,文中参考了SSD中的多尺度特征图的思想,提出了一种新方式来采集不同分辨率的特征图,如图5.1中绿色框中结构。
(4)增加多尺度训练。YOLO V2中只采用了卷积、池化操作,所以可不限定输入的大小,每10个epoch改变一次输入尺寸,以提高网络对多尺度物体的检测性能。
(5)定位策略的改变
YOLO V2与同时期检测算法的性能比较如图5.2所示。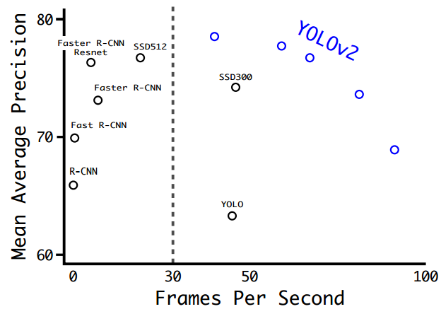
图5.2 YOLO V2与同时期检测算法的性能比较[1]
2. 提出了YOLO 9000
在YOLO V2的基础上提出YOLO 9000,同时提出一种分类、检测联合训练的策略,对于检测数据集,用于学习预测物体的边界框、置信度和物体分类;对于分类数据集,仅用于学习分类,但是其可以大大扩充模型所能检测的物体种类[4]
2 YOLO V2创新点
- 网络自动学习anchor box的宽高。
2. 基于anchor box,预测bbox的中心坐标,而非anchor box与bbox的offset。
3. 提出了一个“特征重排”的方法,来融合不同分辨率的特征。
4. 通过树形结构,整合多个数据集,扩展了目标检测的数据集。
5. 提出一种分类、检测的联合训练策略。3 Better
与Fast R-CNN相比,YOLO V1有比较大的定位误差和低的召回率,因此对YOLO V1的改进主要集中在这两方面。不同策略对YOLO V1性能的影响如表5.1所示。
表5.1 不同策略对YOLO V1性能的影响[1]
3.1 Batch Normalization
每个conv层都采用BN,以规范模型,防止过拟合,获得了2%的mAP提升。同时,去掉Dropout层,且不会使模型出现过拟合现象,因为有BN规范模型。
3.2 High Resolution Classifier
YOLO V1的分类训练输入为224x224,检测输入448x448,这要求网络在微调到检测模式时,不仅从分类模式转为目标检测模式,还要调整适应新的输入分辨率。
YOLO V2将分类训练输入提高到448x448,实际输入为416x416,得到13x13(奇数边长,有一个中心cell)的特征图,这促使网络训练时不断调整filter学习适用于高分辨率的输入。该策略提高了4%的mAP。
3.3 Convolutional With Anchor Boxes
1. Faster R-CNN生成anchor box
预测anchor box与bbox之间的偏移量(offset),根据anchor box的坐标和offset,计算得到bbox的坐标。这里用的坐标表示形式都是“中心坐标 + 宽高”。
2. YOLO V1生成anchor box
将输入图片分成7x7的网格,每个cell预测2个bbox,采用全连接(FC)直接预测bbox的坐标,bbox的宽高是相对于整张图片的,由于图片中物体大小不一,所以YOLO V1在训练过程中学习定位不同形状的物体比较困难。
3. YOLO V2生成anchor box
(1)采用卷积来提取特征,另外去除FC,采用卷积预测定位和分类
去除了一个池化层,提高输出特征图的分辨率;
416x416的输入,下采样总步长为32,得到13x13的输出,使得特征图只有一个中心cell(边长为奇数),因为图片中大的物体处于图片中心的位置,所以最好有个中心cell来预测这些大物体,会比周边cell的预测效果更好。
(2)引入anchor box的思想,将“类别预测”与“空间定位”解耦
YOLO V1中,一个cell生成的2个bbox共用一个类别,而在YOLO V2中,每个bbox都进行类别预测。如图5.3所示。
YOLO V1在每张图上生成98(7x7x2)个bbox,而YOLO V2在每张图上生成超过1000(13x14xnum_anchors)个bbox。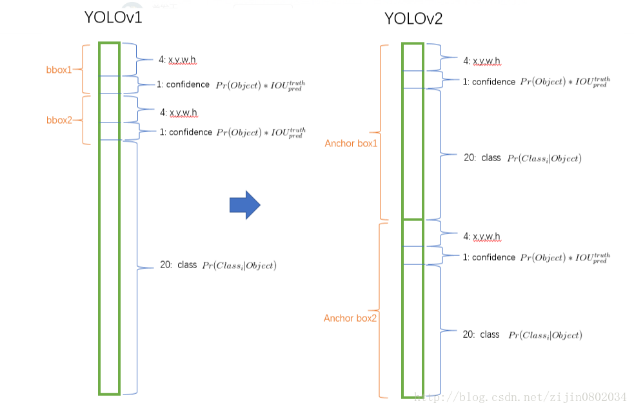
图5.3 YOLO V1与YOLO V2生成的tensor
(3)引入anchor box对性能的影响
YOLO V1的mAP:69.5,recall:81%
YOLO V2的mAP:69.2,recall:88%
3.4 Dimension Clusters
改手动设置aspect ratio,到以聚类方式学习得到aspect ratio。
YOLO V2引入了anchor box的思想,但与Faster R-CNN的anchor box先手动设置box的维度(aspect ratio,宽高比),再通过网络回归学习得到bbox的具体宽高,YOLO V2采用k-mean聚类的方式,由网络学习为bbox提供宽高的“先验”(而非人工),促使网络更容易学习预测合适宽高的bbox。在YOLO V2中,k-mean聚类的中心个数即“aspect ratio”的个数,也即anchor box 的个数。
1. k-mean距离的计算
YOLO V2通过k-mean聚类的方法获得先验框(即anchor box),为了得到一个好的anchor box宽高先验,以获得较好的IoU分数,且与获取结果的好坏与anchor box的大小无关。因此,文中并没由采用“Euclidean distance”,因为其会使k-mean的聚类效果受anchor box大小的影响,即“大的anchor box”比“小的anchor box”产生更多的误差。文中采取的距离计算如公式5.1所示。
 (公式5.1)
(公式5.1)
2. anchor box个数的选择
不断实验,对多个值进行实验,通过权衡“模型复杂度”和“recall”,设定k=5,如图5.4 a)所示。由聚类生成的anchor box比人工设计具有更少短、宽的,更多高、瘦的框,如图5.4 b)所示。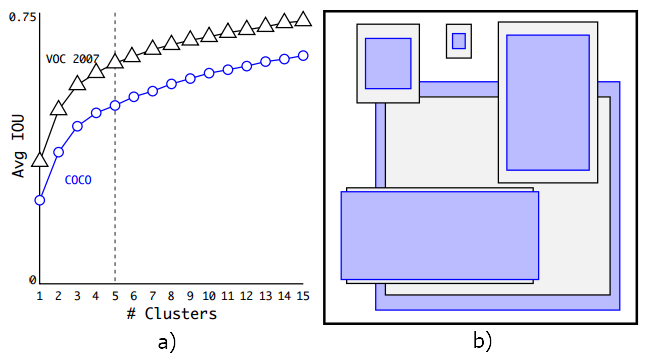
图5.4 聚类中心个数选择与生成的宽高示意图[1]
使用聚类方法生成“prior aspect ratio”,当聚类中心为5,即“prior aspect ratio”的个数为5时,AVG IOU与Faster R-CNN的9个“aspect ratio”效果相当,当聚类中心为9时,得到的AVG IOU比Faster R-CNN的9个“aspect ratio”更高(如表5.2所示),表明以聚类的方式提出“prior aspect ratio”,进而得到“anchor box”,能够以更好的表示方式(better representation)与模型结合,使bbox的定位回归任务更容易学习。
表5.2 聚类的anchor box与手动设置的anchor box的AVG IOU比较[1]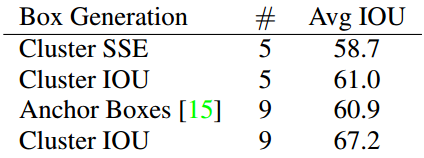
3.5 Direct location prediction
解决Faster R-CNN的anchor box稳定的问题。
1. Faster R-CNN的定位策略
预测anchor box与bbox之间的偏移量(offset),根据anchor box的坐标和offset计算得到bbox的中心坐标,如图5.5所示,计算如公式5.2所示,t_x,t_y为offset;(x_a, y_a, w_a, h_a)为anchor box的坐标。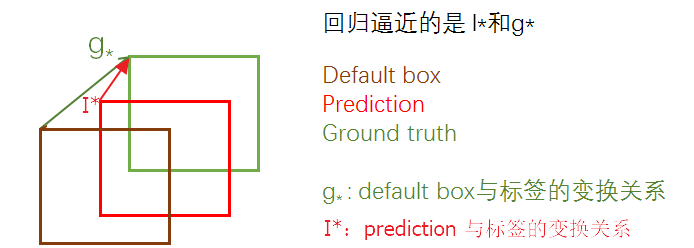
图5.5 Faster R-CNN的定位策略 (公式5.2)
(公式5.2)
该方法的缺点也比较明显,公式5.2没有任何约束条件,如当t_x =1 时,bbox将向右偏移anchor box的一个宽度距离;当t_x = -1 时,bbox将向左偏移anchor box的一个宽度距离。
导致每个位置预测的bbox可以落在图片的任何位置(当距离gt_box很远时,回归定位的难度会很大,计算量也很大),导致模型不稳定,训练时需要较长时间来回归定位,获得较为准确的offset,以生成位置更精确的bbox。
2. YOLO V2的定位策略
(1)定位策略
不同于Faster R-CNN预测anchor box与bbox之间的offset,YOLO V2预测“bbox的中心”与“anchor box中心点所在cell的左上角位置”的offset,且采用sigmoid处理offset,使其取值在[0, 1]之间,从而将bbox的中心点约束在距离当前cell中的一个cell的范围内(如图5.6所示),从而使每个anchor只负责预测周围正负一个cell以内的bbox,有利于模型稳定性。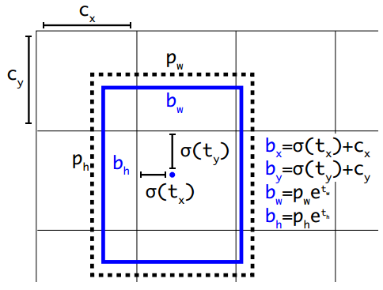
图5.6 YOLO V2的bbox定位策略和大小计算[1]
(2)计算公式
如公式5.3所示。
 (公式5.3)
(公式5.3)
c_x,c_y:anchor box中心cell的左上角坐标;t_x,t_y:“box的中心点”对于“anchor box中心cell的左上角”offset;t_w,t_h:bbox的宽高偏移量;p_w,p_y:anchor box的宽高。
(3)将bbox映射到原图上
根据公式5.4,得到bbox相对于特征图的位置和大小(W,H为特征图的宽高),将其乘以图片的宽度、高度,得到bbox在原图上的位置和大小。
 (公式5.4)
(公式5.4)
3. Faster R-CNN与YOLO V2定位策略的比较
Faster R-CNN通过预测anchor box与bbox间的坐标偏移量,对bbox进行定位(此时坐标表示形式为:中心坐标+宽高)。YOLO V2通过预测“anchor box中心cell左上角”与“bbox中心”的偏移量(且利用sigmoid将偏移量规范到[0, 1]区间),对bbox进行定位。如图5.7所示。
图5.7 Faster R-CNN与YOLO V2定位策略的比较
3.6 Fine-Grained Features
为了整合不同大小特征图的信息,提升YOLO V2对小物体和多尺度的检测性能。文中提出了passthrough layer,以获取浅层的、较高分辨率特征图的信息(如图5.8所示),操作如下。
(1)将一个特征图(26x26x512)按列隔行采样,得到4个维度相同的新的特征图(13x13x512)。
(2)将4个feature map 通过concat拼接起来(13x13x2048),得到高分辨率的“子feature map”。
(3)将拼接好的高分辨率的“子feature map”以类似resnet跳跃结构的方式(element-wise add)拼接,相当于特征融合,有利于检测小目标。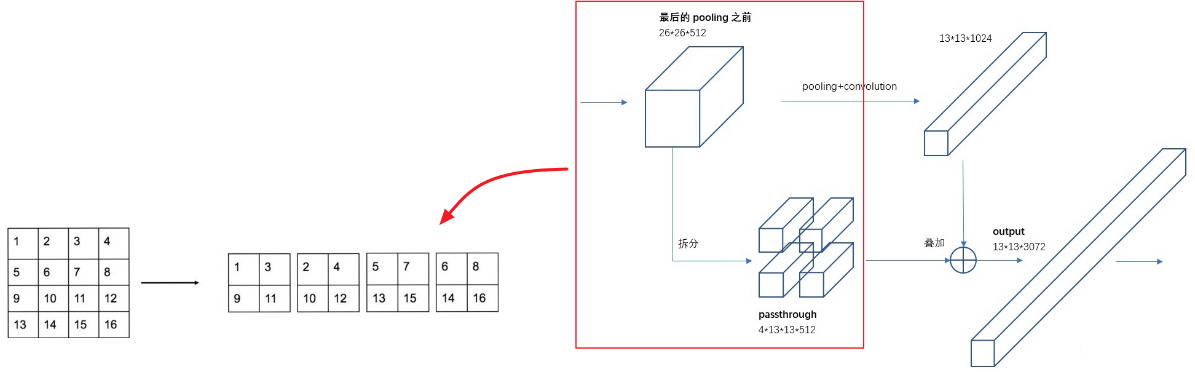
图5.8 passthrough layer结构
3.7 Multi-Scale Training
因为YOLO V2中只采用卷积、池化操作,所以网络不限定输入尺寸。
为提高YOLO V2对多尺度物体检测、不同分辨率图像的检测能力,YOLO V2中,每10个epoch随机改变一次输入分辨率,因YOLO V2的下采样总步长为32,故输入分辨率主要由一系列32倍数值组成:{320, 352,…,608},最小为32x32,最大为608x608。如图5.9所示。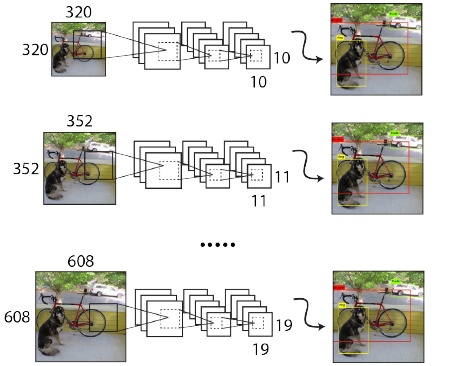
图5.9 多尺度训练
检测低分辨率图片时(288x288),YOLO V2检测速度有90FPS,同时mAP能够与Fast R-CNN接近。检测高分辨率图片时,YOLO V2在VOC 2007上仍能获得78.6mAP,比同时期的“real-time”目标检测算法都高。如表5.3所示。
表5.3 不同目标检测算法的比较(PASCAL VOC 2007)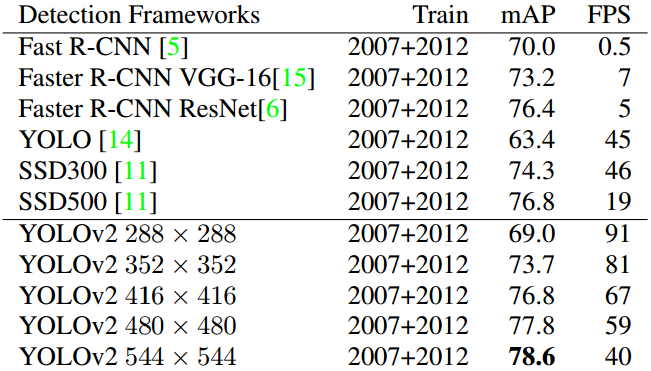
3.8 Loss function
由分类损失(classification loss)、置信度损失(confidence loss)/有无object的损失和定位损失(coordinate loss)三部分构成,如图5.10所示。
(1)confidence loss
confidenceloss = object_loss + no_objcet_loss,如公式5.5所示。
(公式5.5)
YOLO V2在每张图片上生成845(13x13x5)个anchor box。在没有与gt_box匹配的anchor box中,与gt_box的max IoU小于0.6时,anchor box内无预测对象,此时计算“no_objcet_loss”;与gt_box匹配的anchor box,则计算“object_loss”。
在YOLO V1中,object_loss : no_object_loss = 1 : 0.5
在YOLO V2中,object_loss : no_object_loss = 5 : 1
(2)classification loss
采用均方误差公式计算,如公式5.6所示。
(公式5.6)
(3)coordinate loss
计算如公式5.7所示。
与YOLO V1的不同:
a) YOLO V1是计算相对于整张图片的坐标误差,预测输出为(x,y,w,h),与gtbox的(x,y,w,h)计算误差。YOLO V2是计算“gt_box到anchor box中心cell左上角的offset”与“bbox到anchor box中心cell左上角的offset”之间的误差。
b) 与YOLO V1对w,h取根号求误差不同,YOLO V2是对长宽的缩放因子取log。
c) YOLO V1的修正系数为5,YOLO V2的为1
与YOLO V1的相同:对于一样的误差值,降低对大物体误差的惩罚,加大对小物体误差的惩罚。
(公式5.7)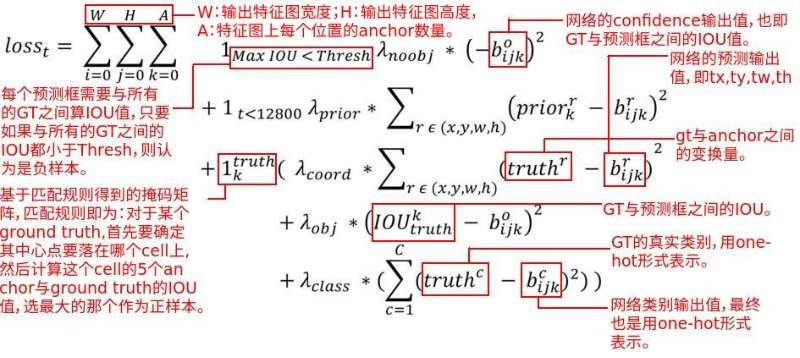
图5.10 YOLO V2损失函数
4 Faster
YOLO V2提出了新的骨干网络“Darknet-19”,在ImageNet分类任务中,训练参数量减少,同时保持很好的性能。VGG-16、YOLO V1 darknet、YOLO V2 Darknet-19三者比较如表5.4所示。
表5.4 VGG-16、YOLO V1 darknet、YOLO V2 Darknet-19三者比较
| 网络 | 参数量 | Top-1准确率 | Top-5准确率 |
|---|---|---|---|
| VGG-16 | 30.69billion | 90.0% | |
| YOLO V1 darknet | 8.52billion | 88.0% | |
| YOLO V2 Darknet-19 | 5.58billion | 72.9% | 91.2% |
4.1 Darknet-19
共10个conv层,使用大量的小核卷积(3x3)提取特征,在两层3x3conv之间,使用1x1conv 压缩特征;5个max pooling 层,下采样的同时,通道数翻倍。具体结构设计如表5.5所示。
表5.5 Darknet-19结构设计[1]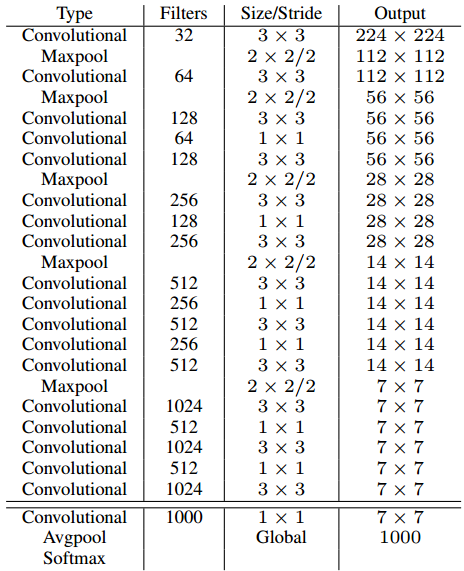
4.2 Training for classification
(1)输入为224x224,在ImageNet上预训练DarkNet-19,共训练160epoch。
采用SGD优化,lr=0.1;polynomial rate decay=4;weight decay=0.0005;momentum=0.9;采用标准的数据增强技巧:随机剪切、旋转、色调、饱和度、曝光变化。
(2)输入为448x448,在ImageNet上finetune DarkNet-19,训练10个eopch。
初始lr = 0.001
4.3 Training for detection
修改Darknet-19用于检测,如图5.11所示。主要修改有:
(1)移除最后一个卷积层、global avg pooling、softmax
(2)添加3个“3x3x1024”
(3)添加passthrough层
(4)最后采用1x1 conv预测分类和定位,输出张量的维度为:num_anchors x (5 + num_classes),VOC的类别为125,COCO的类别为425。
图5.11 Darknet-19的检测结构[4]
5 Stronger
在YOLO V2的基础上提出YOLO 9000。主要贡献是提出了一种分类、检测联合训练的策略,检测数据集比分类数据集的数量少很多,如果能够将分类和检测联合训练,将大大扩充训练数据集。在YOLO V2中,定位、分类是分别进行的,所以YOLO V2能够实现在分类、检测数据集上的联合训练。对于检测数据集,用于学习预测物体的边界框、置信度和物体分类;对于分类数据集,仅用于学习分类,但是其可以大大扩充模型所能检测的物体种类[4]。
通过联合训练策略,YOLO 9000可快速检测出超过9000个类别的物体,总体mAP值为19.7%。
5.1 Hierachical classification
(1)目的
将ImageNet 与 COCO 两个数据集整合到一起。因为ImageNet 与 COCO 的类别并不是完全互斥的,所以可行。
(2)方法
a) 根据类别之间的从属关系建立一种树结构WordTree如图5.11所示。
b) 构建WordTree的策略
添加节点时,尽可能少的增加树的高度
如果一个concept到root有多条path,则选择更短的path
c) 计算概率
WordTree中的根节点为“physical object”,每个节点的子节点都属于同一子类,可对他们进行softmax处理(如图5.12所示),在计算得到某个类别的预测概率时(如公式5.8所示),需要找到其所在的位置,遍历这个path,然后计算各个节点上的概率之积(如公式5.9所示)。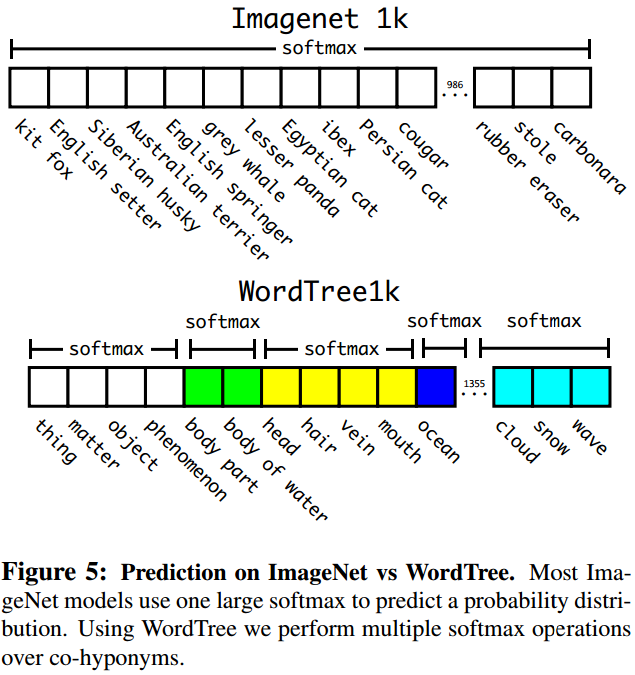
图5.12 ImageNet与WordTree分类的比较[1] (公式5.8)
(公式5.8) (公式5.9)
(公式5.9)
5.1.1 Dataset combination with WordTree
以Hierarchical classification方法组合ImageNet 与 COCO 两个数据集,如图5.13所示。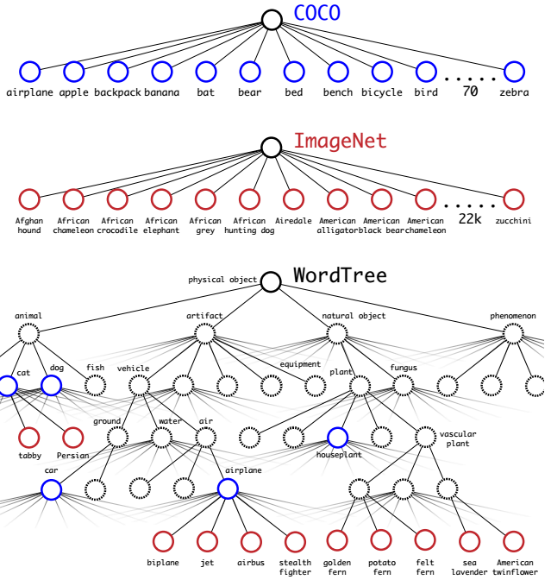
图5.13 将COCO、ImageNet根据类别从属关系构建WordTree[1]
5.1.2 Joint classification and detection
训练时,如果是检测数据集中的样本,则按照YOLO V2的损失计算误差;如果是分类数据集中的样本,只计算分类误差。
预测时,YOLO V2给出的置信度为Pr(physical object),同时给出边界框位置以及一个树状概率图。在这个概率图中找到概率最高的路径,当达到某一个阈值时停止,用当前节点表示预测的类别[4]。
6 YOLO V2思维导图
以思维导图的方式,将YOLO V2各个知识点串联起,有利于构建YOLO V2的知识树。如图5.14所示。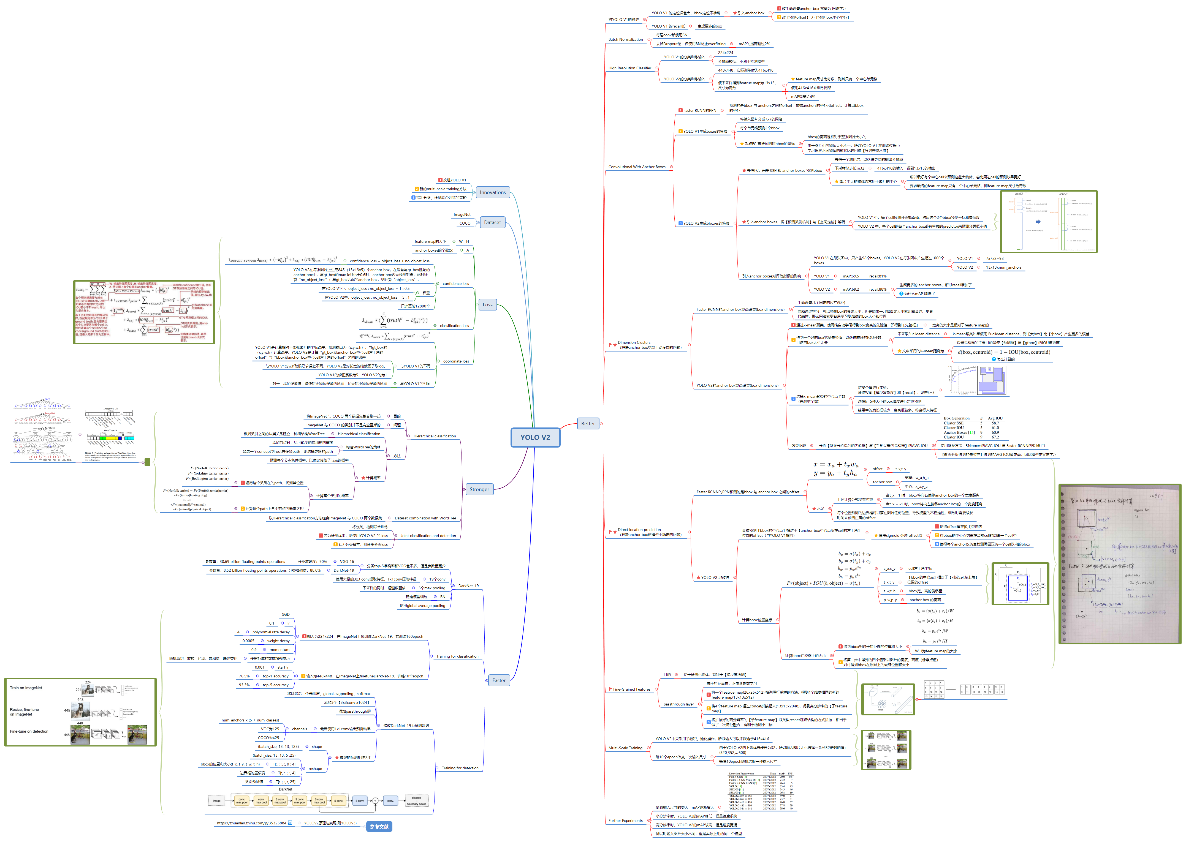
图5.14 YOLO V2思维导图
7 未理解的点
(1)5.5.3小节中,怎么区别检测样本、分类样本。
(2)5.3.8小节中,关于YOLO V2损失函数的分析,还没有理解透彻。
(3)正负样本分配策略是怎么?
8 参考文献
[1] Redmon J, Farhadi A. YOLO9000: Better, Faster, Stronger[C]// IEEE Conference on Computer Vision & Pattern Recognition. 2017.
[2] YOLOv2 and Hierarchical Soft-Max Tree for US Traffic Sign Detection System
https://riss.ri.cmu.edu/wp-content/uploads/2017/09/2017-RISS-poster-NGUYEN-Dat.pdf
[3] 对YOLO V2的改进
https://www.researchgate.net/figure/YOLOv2-architecture-YOLOv2-architecture-is-modified-with-our-new-assisted-excitation_fig3_333609719
[4] YOLOv2原理与实现(附YOLOv3)
https://zhuanlan.zhihu.com/p/35325884

若有收获,就点个赞吧
0 人点赞

{kind=link}
{kind=link}
{kind=link}