阅读:2019.8.7-8.14
期刊:CVPR 2016
引用: A. Shrivastava, A. Gupta, and R. Girshick. Training regionbased object detectors with online hard example mining. In CVPR, 2016
1 OHEM概述
本文主要目的是解决“one-stage”检测算法中正负样本不均衡的问题。
在目标检测中,存在大量的易分类样本,和难分类样本(hard example,具有多样性,高损失的,对分类和检测影响较大的样本),自动的hard example可是的训练更有效。OHEM是一种简单直观的算法,能够抑制易分类样本,筛选出hard example,然后将筛选后的样本送入检测器中,训练检测网络。
1. Boostrapping
Boostrapping的核心思想是逐渐增加检测器分类错误的正样本(难分类样本),去掉易分类样本。该思想是通过迭代交替训练实现:
(1)用样本集更新模型;
(2)固定模型,用模型寻找“false positives”样本,即被分错类的正样本,并将其添加到样本集中。如此迭代进行上述两个步骤。
最终训练集由所有的难分类样本/前景样本、少量易分类样本/背景样本构成。基于DL的目标检测算法都使用SGD训练网络,需要更新迭代数十万次,如果每隔几次就固定模型,将会大大地减慢训练速度,所以Boostrapping无法直接应用于基于DL的检测算法中。
2. OHEM
OHEM的思想来源于“Boostrapping”,OHEM的主要工作是将Boostrapping迭代训练过程融入到深度网络中,构成一个“end-to-end”的单一网络结构,就能够采用“end-to-end”的训练策略了。
OHEM借助2个ROI Network实现迭代交替筛选hard example的过程,2个ROI Network参数共享。一个ROI Network只有前向传播,用于计算损失,选择hard example,并添加到样本集中;一个ROI Network有前向、反向传播,以hard example作为输入,计算损失并向后回传梯度。
3. OHEM的几个优点
(1)使得解决正负样本不均衡问题时,不需要采用设定正负样本比例的方式。在线选择的方式针对性更强。
(2)随着数据集的增大,算法提升更明显(在COCO数据集、Pascal VOC2012上分别实验得到的结果)。
2 OHEM创新点
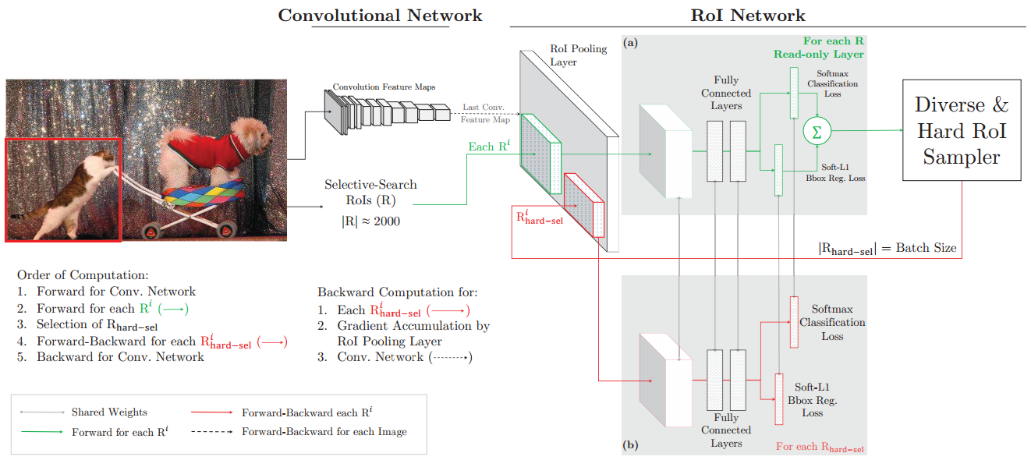
Fast R-CNN主要由的Convolution Network和RoI Network(候选区域提取)两部分构成。Convolution Network由多个卷积层、池化层构成,RoI Network由多个RoI Pooling、FC层构成。如图8.2所示。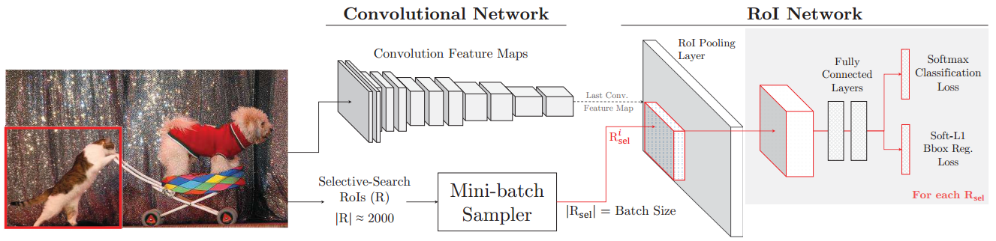
图8.2 Fast R-CNN结构
1. Foreground RoIs
与gt_box的IOU >= 0.5的ROI
2. Backgroud RoIs
bg_lo < 与gt_box的IOU < 0.5的ROI
阈值的设置能够“加速模型收敛”和“提升检测准确度”,但会忽略出现的少、但重要的、难分辨的背景。本文的算法去除了bg_lo的设置。
3. Balancing fg-bg RoIs
为了解决正负样本不均衡问题,在每个mini-batch中,对正负样本进行随机采样,达到“1:3”的比率。“1:3”的设置极大提升了Fast R-CNN的性能,增大或缩小这个比例都会使模型性能降低,本文的Fast R-CNN去除了这个比例设置,使用OHEM。
4. 为什么选Fast R-CNN作为验证OHEM的算法
(1)Fast R-CNN的基本框架也被其他检测算法使用
(2)Fast R-CNN能够更新整个网络的参数
(3)Fast R-CNN不使用SVM
4 Our approach
4.1 Online hard example mining
1. OHEM 的执行策略
将OHEM整合到Fast R-CNN网络中后,在SGD的第t次迭代中,OHEM部分的执行策略如下:
(1)将img送入ConvNet,得到特征图
(2)将“特征图”、“select search得到的RoIs”送入RoI Net_1,计算每个RoIs的损失,将loss“从高到低”排序,然后选择前“B/N”个ROIs RoI Net_2,
大部分的“forward computation”通过对featrue map的卷积操作而实现在各个ROIs之间的参数共享,所以,“forward”需要的额外计算相对较小。另外,因仅选择少数ROIs(loss值很高的,前“B/N”个ROIs)通过“bachward pass”来更新模型,所以反向传播的计算量没有以前那么大
2. OHEM执行策略中存在的问题及其解决方法
下面两个问题导致loss设置翻倍:
(1)位置临近的ROI,即overlap比较高的ROIs,可能具有相近的loss值。
(2)由于分辨率差异,重叠的ROI在feature map可以映射到同一个区域
解决方法:
采用NMS去除近似的RoIs,重复(1)、(2),直到选择了“B/N”个RoIs
(1)计算RoIs的损失,按“从高到低”排序
(2)选择最高的损失值,计算该RoI与其他RoI的IoU,移除IoU大于阈值的RoI(阈值=0.7)
4.2 Implementation details
有两种方法将OHEM整合到Fast R-CNN中。
1. An obvious way
(1)直接修改损失层,去选择“难分类的ROI样本”
(2)计算所有ROI的loss,并对loss进行排列以选择“难分类的ROI样本”
(3)将所有“易分类的ROI样本”的loss置0
缺点:
(1)对所有ROI分配内存
(2)对所有ROI 进行反向传播,即使某些ROI的loss为0
2. A better way
设计两个完全一样的ROI Net,两个网络的参数共享,如图8.3所示:
一个用于计算损失,只进行前向传播。得到RoIs的损失后,按“从高到低”的策略选择hard example
一个有前向、反向传播,以hard example作为输入,计算损失并向后回传梯度。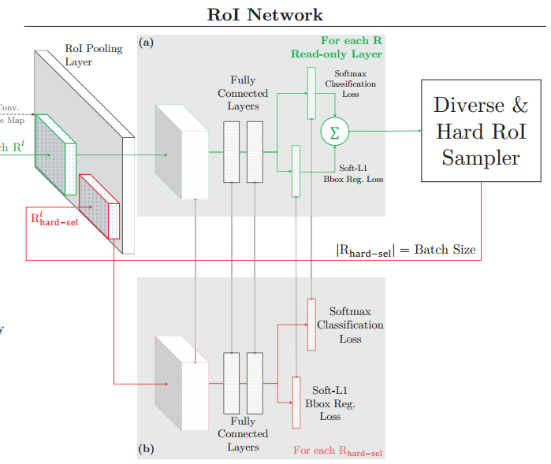
图8.3 RoI Net结构
5 OHEM思维导图
以思维导图的方式,将OHEM各个知识点串联起,有利于构建OHEM的知识树。如图8.4所示。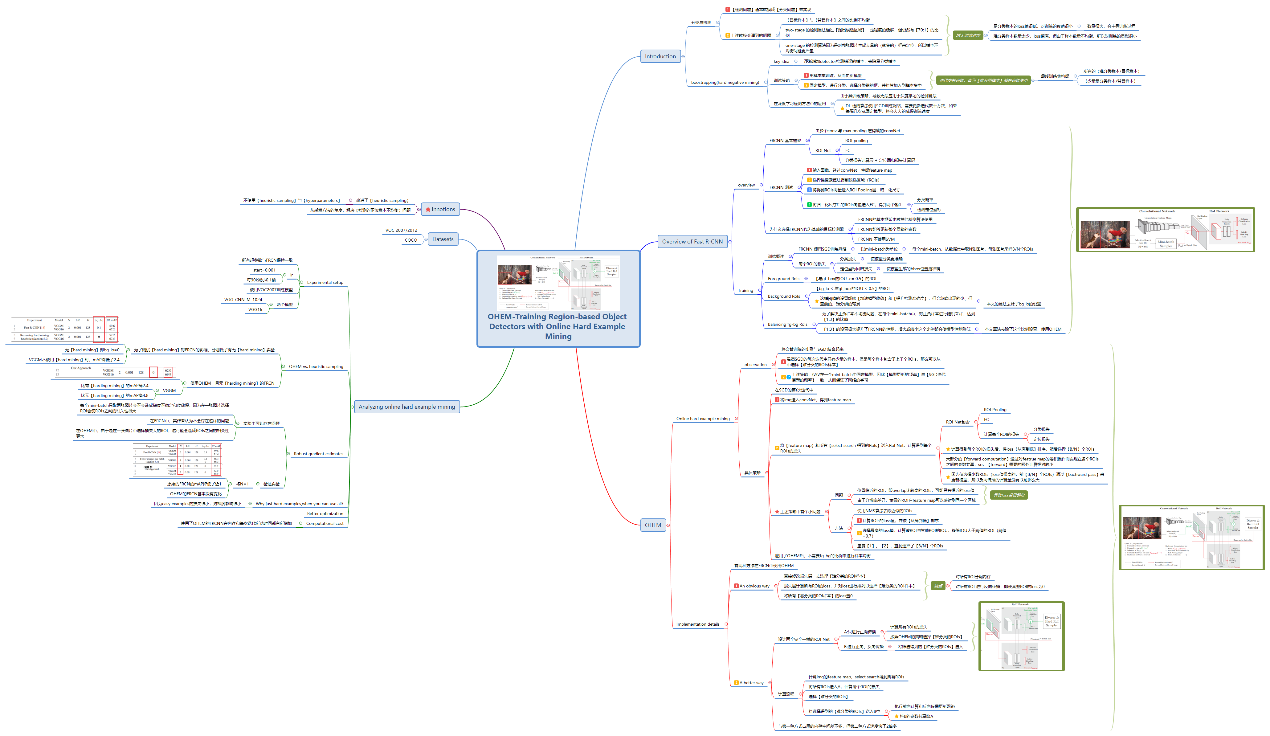
图8.4 OHEM的思维导图
6 未理解的点
(1)如何实现两个ROI Net的参数共享,需要分析源代码。
7 参考文献
[1] A. Shrivastava, A. Gupta, and R. Girshick. Training regionbased object detectors with online hard example mining. In CVPR, 2016
[2] OHEM算法及Caffe代码详解
https://blog.csdn.net/u014380165/article/details/73148073

若有收获,就点个赞吧
0 人点赞
