阅读:2018.10.31
期刊:CVPR 2015
引用:K. He, X. Zhang, S. Ren and J. Sun, “Deep Residual Learning for Image Recognition,” 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 770-778, doi: 10.1109/CVPR.2016.90.
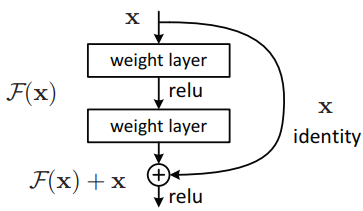
图1‑1 Residual learning, skip connection.
1 概述
重读resnet,有了些新的认识,记录一下。
Residual learning 能够起到作用的根本原因是保持了反向传播中的梯度,即减缓了梯度消失(gradient vanishing)问题,从而使SGD能够持续、有效地优化网络。反向传播的梯度计算如下,当网络layer 越多,相乘的次数越多,中间梯度的值通常是分布在0附近的高斯分布中,那么若干次相乘后,最终的梯度将会非常的小,导致gradient vanishing,使得SGD难以继续训练网络(重点是难以继续优化网络,而非网络潜力有限)
当引入residual learning后,梯度计算如下,第一项等价于上面,即使若干次相乘后梯度很小,但是第二项较大,所以最终的梯度仍然具有较大的值,从而使SGD能够持续、有效地优化网络。
这里要提一下,SGD是要在梯度较大的情况下才能够优化网络。所以如果对优化器进行改进,比如后面的Adam,使其对梯度的要求没那么敏感,获取也能够比较好的解决问题,加速网络收敛。
2 Residual learning
作者认为,理论上deeper network 比 lower network具有更好的能力,至少不会更差,但当时的实验表面,当网络层数上升到一定时,性能反而变差,即当时的技术/硬件无法有效优化那么深的网络,如下图。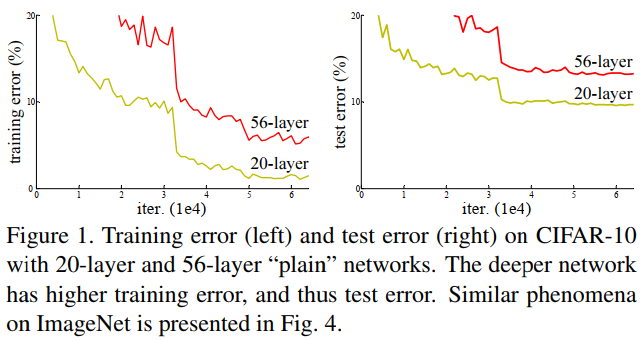
图1‑2 在Cifar10上,56层网络性能弱于20层网络
为什么?
因为额外添加的layer至少能够学习到一个identity mapping,即输入=输出。比如50layers和20layers,31~50layers至少能够学习到identity mapping,所以。但实际上做不到。
因此本文引入了residual leaning。如下,输入为z,我们的目标是学习,浅层学习到了x,此时deeper layers不直接学习,而学习。
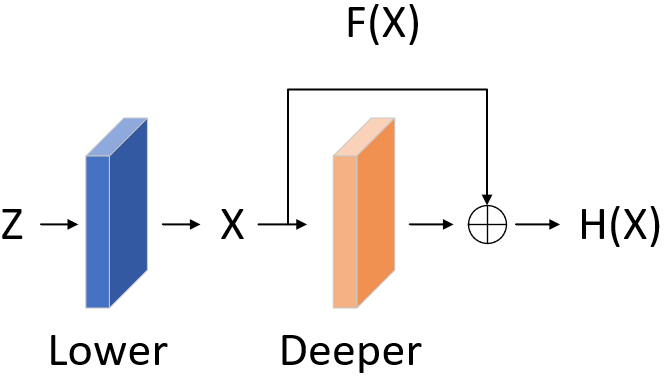
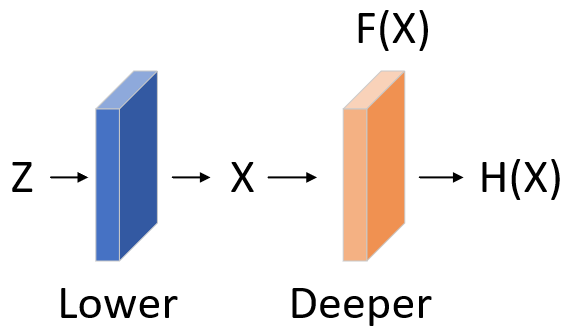
图1‑3 有无residual learning对比
此外,作者认为,优化residual learning 比优化 original mapping 更容易。举个极端的例子,将一个residual learning 优化趋于0,比优化一系列由conv layer构成的非线性映射趋向于0更简单。即利用非线性映射层(conv layers)学习identity learning(x=y),需要优化很多的参数,因此优化难度较大。而利用residual learning直接将输入送到输出,这个操作的复杂度为0。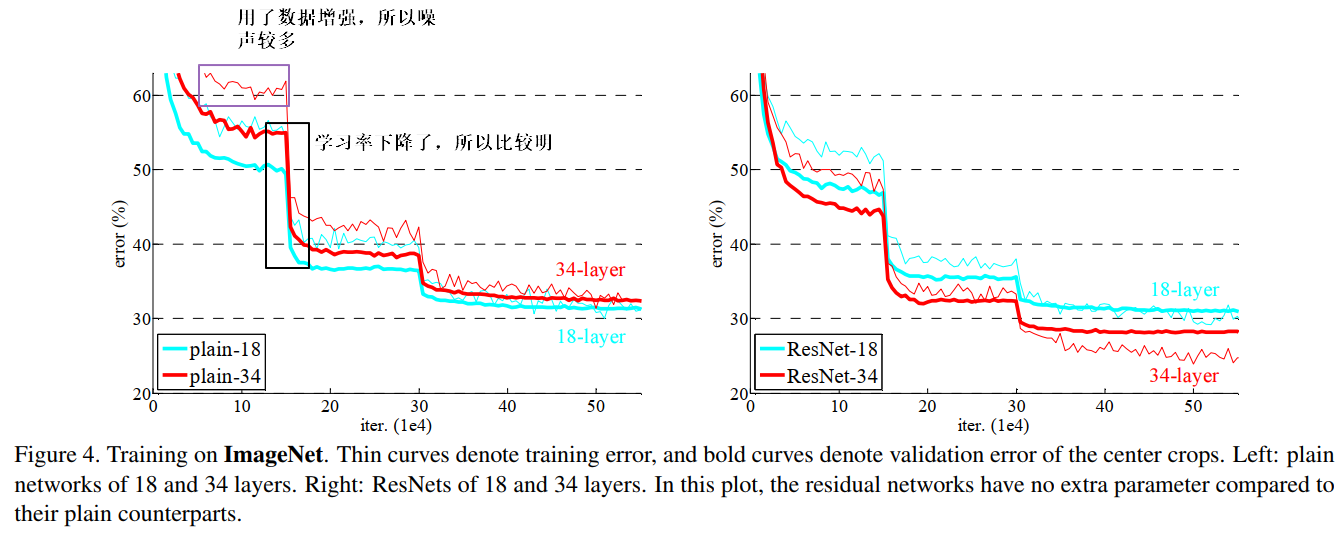
图1‑4 在ImageNet上有无residual learning的对比
.

若有收获,就点个赞吧
0 人点赞
