阅读:2019.7.22-7.31
期刊:CVPR 2016
引用:Redmon J , Divvala S , Girshick R , et al. You Only Look Once: Unified, Real-Time Object Detection[J]. arXiv preprint arXiv:1506.02640,2015.
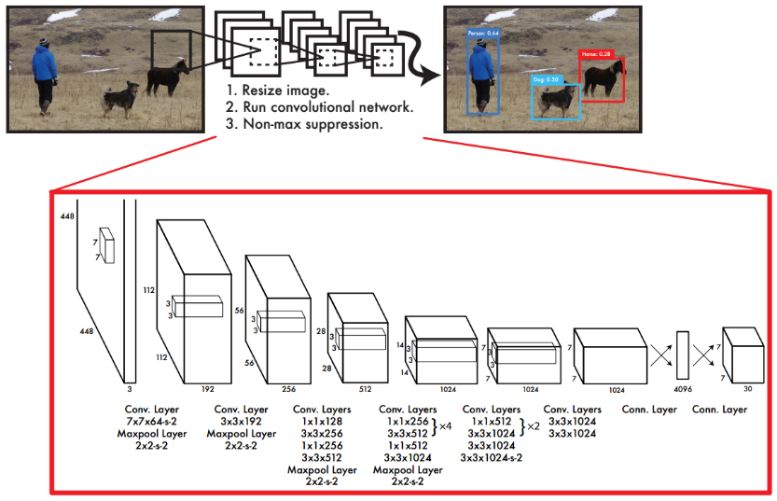
1 YOLO V1概述
YOLO V1顾名思义,是YOLO系列的第一个版本。不同于Faster R-CNN的“RPN+RCNN”的两阶段搭配完成检测任务,YOLO V1将整个目标检测任务看作成回归问题,仅由一个“端对端(end-to-end)”网络生成“边界框(bounding box,bbox)”和“分类任务”,直接在整张图片的特征图上生成预测框而不是基于候选区域,从而实现了端对端地训练整个网络,简化了训练。几种目标检测算法的检测流程如图4.2所示,YOLO V1结构如图4.1所示。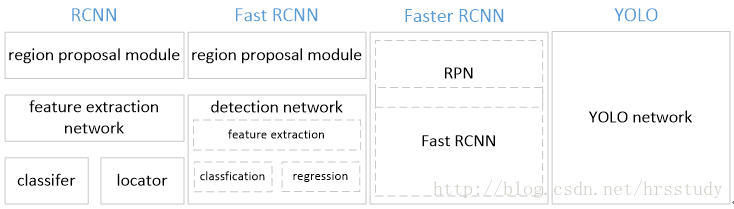
图4.2 几种目标检测算法的检测流程比较
YOLO V1的一个突出特点是检测速度很快(45fps,简化版本155fps),且能够保持较高的平均准确率,获得当时实时检测算法的最佳成绩(如图4.3所示),比同时期的Faster R-CNN快的多(5fps)、YOLO V1是基于整张图片做检测,所以能够很好地利用上下文信息。从而避免在背景上预测出错误的物体信息。
但相对于Faster R-CNN,YOLO V1的bbox定位不准确、小目标检测效果不好、bbox大小与物体大小匹配的不够好,尤其是密集的小物体,这是由于它没有基于候选区域、每个cell只生成2个框,且是只有一个类别。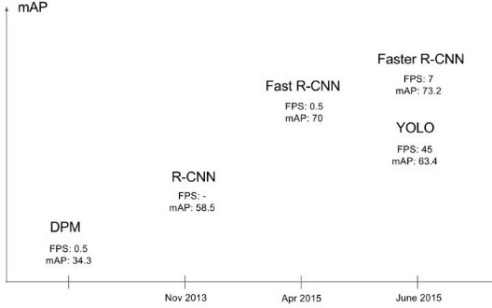
图4.3 YOLO V1与同时期检测算法的比较[2]
2 YOLO V1创新点
1. 将目标检测转化成一个回归问题
YOLO V1是一个“end-to-end”的网络,能够进行“end-to-end”训练,相比FasterR-CNN,简化了训练;测试速度非常快,能够达到“实时检测(real-time detection)”的效果,同时拥有高的“average precision”。
2. 基于整张图片做目标检测
直接在整张图片的特征图上生成预测框、分类,因可对整张图片的上下文信息进行编码,使得网络对整张图片的特征具有全局感知/推理,有利于检测图片中的对象,故背景错误较少。而Fast R-CNN/Faster R-CNN是基于候选区域的,没有整合上下文信息和全局感知,所以产生了很多的背景错误。
3. 学习目标的一般化表征(generalizable representations)
YOLO V1能够学到的特征具有很高的通用性,使得YOLO V1不仅在自然图像上的检测性能较好,在艺术品上的检测性能也不错,比DPM、R-CNN都要好的多。
3 Unified Detection
3.1 生成bbox的规则
YOLO V1基于整张图片的特征图进行目标检测,将特征图分成“SS”的网格(如图4.4所示),如果一个物体的中心点在某个cell中,那么这个cell就用来对该物体进行检测。每个cell都生成“B个bbox”、“B个bbox的置信度”和“分类概率(C个类别)”,一张特征图生成“SS(B5 + C)”大小的tensor。
1. 每个cell预测“bbox”和“confidence score”
“confidence score”表示cell中是否含有物体的概率,其由公式4.1计算。可知,当cell没有物体时,该项为0,否则,为bbox和gtbox的IoU。 为cell是否有物体,有则为1,否则为0。
为cell是否有物体,有则为1,否则为0。
(公式4.1)
2. 每个bbox的预测包含5个值:x, y, w, h, confidence
(x,y)为bbox的中心坐标,也即bbox中心cell的中心坐标;w, h为bbox的宽高;confidence为bbox与gtbox之间的IOU。
3. 每个cell只预测一个类别的bbox的conditional class probability
每个cell都预测其bbox属于某类别的概率 ,所有bbox只属于某一个类别,即每个cell只预测一个类别的bbox。测试阶段,将条件类概率与单个框的confidence相乘,如公式4.2所示。表示每个bbox的特定类别的confidence,该特定类别出现在bbox中的概率和bbox与该类对象的拟合程度(class-specific confidence score),最后根据这个,设定阈值,采用NMS筛选。
,所有bbox只属于某一个类别,即每个cell只预测一个类别的bbox。测试阶段,将条件类概率与单个框的confidence相乘,如公式4.2所示。表示每个bbox的特定类别的confidence,该特定类别出现在bbox中的概率和bbox与该类对象的拟合程度(class-specific confidence score),最后根据这个,设定阈值,采用NMS筛选。
(公式4.2)
Note:
conditional class probability是针对每个cell的
confidence是针对每个bbox的
在PASCAL VOC数据集中,S=7, B=2, C=20,最终预测的tesor为7x7(2x5 + 20)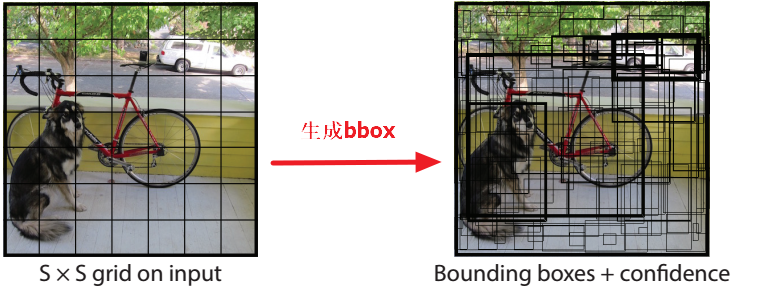
图4.4 YOLO V1生成预测框示意图
3.2 Network Design
使用全卷积(Full convolution)网络作为特征提取器,采用全连接(Full connection)网络预测bbox的坐标和分类概率。在PASCAL VOC数据集上训练和测试。
YOLO V1的网络设计受到了GoogLeNet的启发,拥有24个卷积层+2个FC层,在3x3 conv后加1x1 conv。如图4.1所示。另外,还设计一个简化版“Fast YOLO”,更少的卷积层(9层)和更少的卷积核,所有的训练、测试的超参数与YOLO V1保持一致。
网络最终的输出为7x7x30的tensor。
3.3 Training
1. 预训练
将网络放到ImageNet中做分类训练(输入为224x224),以初始化参数。但并不是与图4.1完全一致的结构,而是由“前20个conv + 1个average pooling + 1个FC”构成的网络。最终将前20个conv得到的参数用来初始化检测网络中的前20个conv。
2. 检测训练
在预训练获得的前20个conv基础上,添加随机初始化的4个conv、2个FC。同时,由于检测需要“细粒度(fine-grained)”的特征信息(视觉信息),故将网络的输入从224x224调整到448x448。中间层使用“leaky rectified linear( LReLU)”(如公式4.3,图4.5所示),最后一层使用线性激活函数。 (公式4.3)
(公式4.3)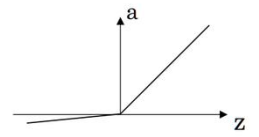
图4.5 LReLU函数图像
3. 检测的输出
检测的输入为每个cell预测的bbox的坐标和bbox的分类概率:7x7(2x5 + 20),7x7是特征图大小;2x5表示2个bbox,每个bbox预测5个值:坐标(x,y,w,h)和confidence;20为类别的个数。如图4.6所示。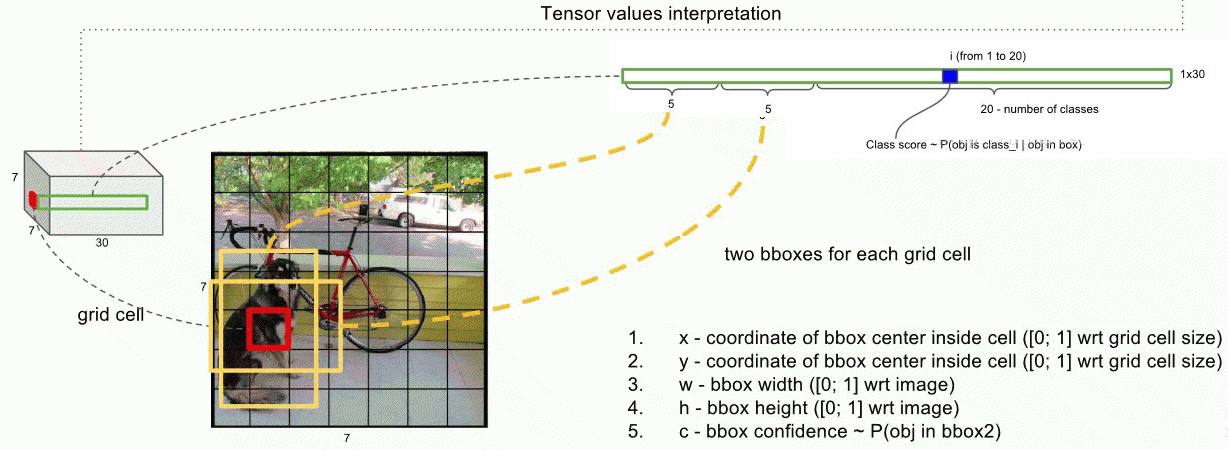
图4.6 每个cell的检测输入示意图[4]
文中将bbox的坐标归一化到[0,1]的范围。bbox宽高采用图片的宽高进行归一化处理,中心坐标(x, y)是基于中间cell的左上角的偏移量(offset),因此也在[0, 1]之间。
4. gt_box与bbox之间的匹配
一个cell可以预测B个bbox,在训练阶段,每个gt_box只有一个bbox来预测(一对一)。将与gt_box具有最大IOU的bbox用来预测该gt_box,文中称这种匹配方式为bouding box predictor的specialization(专职化)。每个predictor对特定的gt_box(sizes, aspect ratios, or classes of object)会预测的越来越好,改善整体的召回率。IOU最大的bbox偏移会更小,可以更快地学习到正确位置[2]。
5. 训练流程
(1)将图片resize到448x448,图片分割得到7x7网格
(2)CNN网络提取特征、FC预测分类和定位
大致的训练流程如图9所示。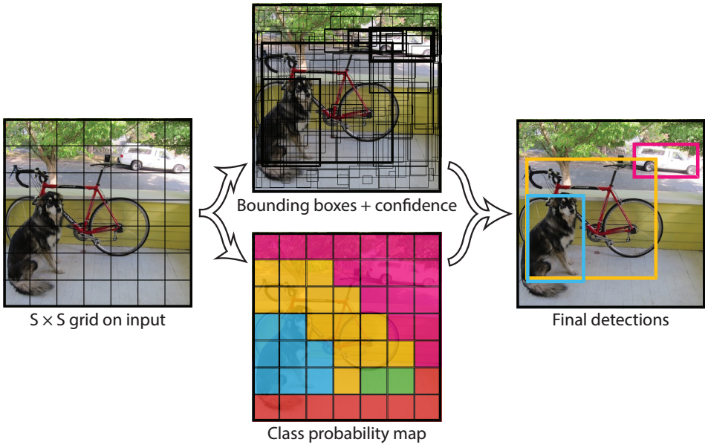
图9 YOLO V1训练流程[1]
3.4 Loss function
因为检测输出包含三个方面:bbox坐标(定位)、bbox的confidence和bbox的分类概率,所以损失函数也由这三部分构成(如图4.7所示),为三部分的“sum-squared error”。其中定位误差是相对于整张图片的坐标误差。文中提到如果只是简单的“sum-squard error”则会有下述问题:
(1)定位损失(8维)与分类损失(20维)具有相同的权重是不合理的
(2)如果一个cell中没有object(多数cell是没有object的),则该cell生成的bbox的confidence=0;相对于有object的cell,这种处理会“压制渐变(overpowering the gradient)”,使得模型不稳定,甚至导致在训练早期发散。
文中给的解决方法:
(1)增加定位损失的权重,给更大的权重,在PASCAL VOC中训练时,取5,即
(2)降低没有object的cell的confidence loss的权重,给更小的权重,在PASCAL VOC中训练时,取5,即
(3)有object的cell的confidence loss和classification loss权重为1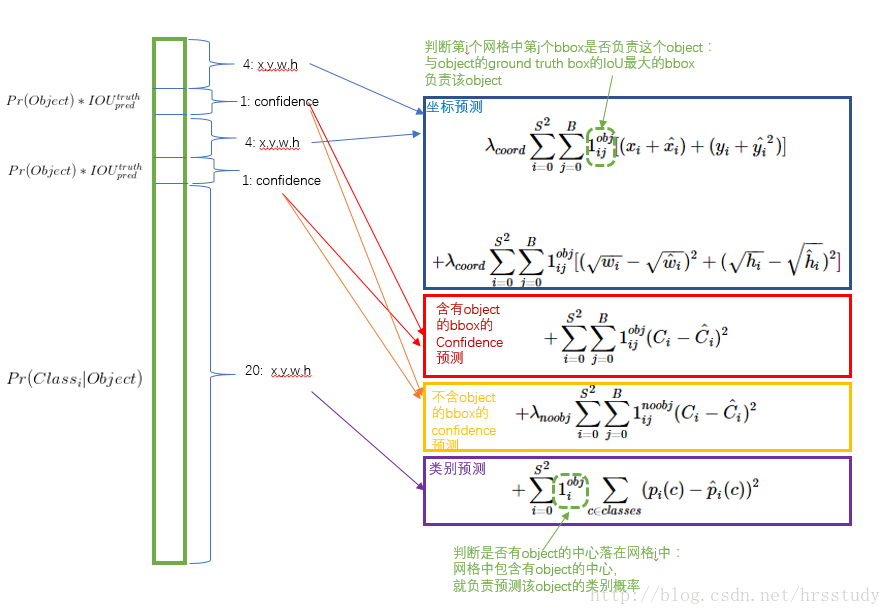
图4.7 YOLO V1损失函数[1][3]
计算定位误差时,相对于预测大的bbox时出现一点偏差,还能接受,预测小的bbox出现一点偏差,是不能接受的,bbox越小,偏差影响越大。在“sum-quare error”中,对不同大小的bbox的同样偏差的loss是一样的,这就影响小目标的检测精度。为此,文中提出的方法是,将宽高取平方根后送入计算,而不是直接送入,这样能够相对减小偏差的影响。当小的bbox发生较小的偏差a(x轴的差值),会产生比大的box发生a偏差更大的损失值(y轴的差值),如图4.8中,绿色范围比红色范围更大。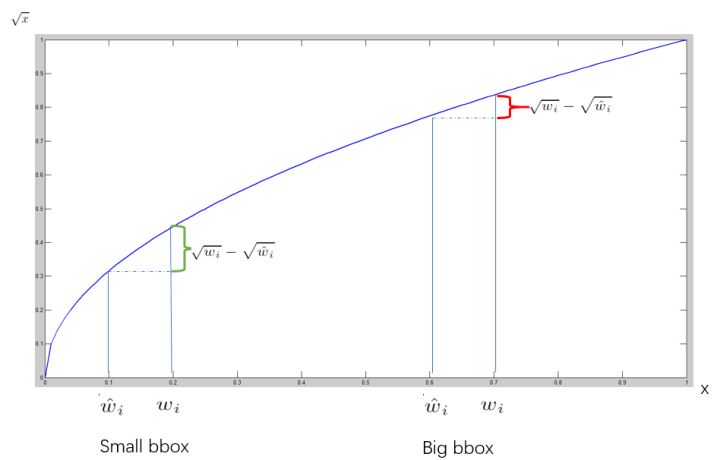
图4.8 YOLO V1损失分析[2]
3.5 Inference
测试时,在PASCAL上,每张图片生成98(7x7x2)个bbox、每个bbox的分类概率。
1. 计算class-specific confidence score
分类概率乘以confidence,得到每个bbox特定类别的confidence(class-specific confidence score),如图4.10所示。用于进行NMS筛选。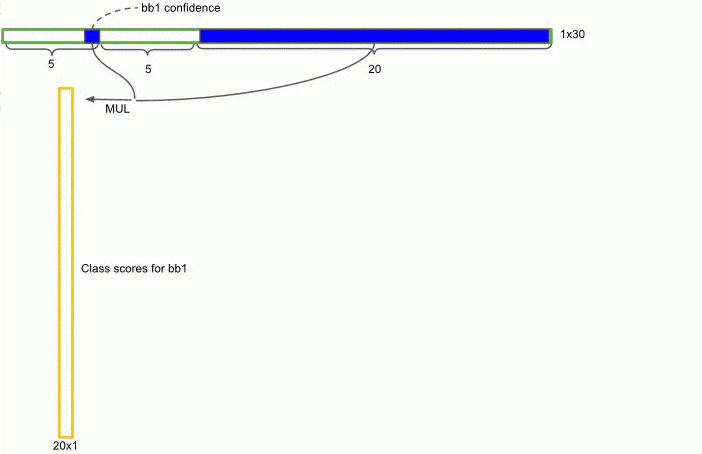
图4.10 计算class-specific confidence score[4]
2. NMS筛选
在计算每个bbox的class-specific confidence score后,设置阈值,筛选掉得分低的bbox;对保留下的bbox进行NMS处理,得到最终的检测结果。
(1)将一张图片预测的98个bbox按class-specific confidence score,从高到低排序。
(2)计算最高得分的bbox与其他bbox的IoU,如果IoU>0.5,那么就将低分bbox的class-specific confidence score置0,如图4.11所示。
(3)将指针移向剩下bbox中得分最高的bbox,继续步骤(2),直到完成所有的bbox。
图4.11 YOLO V1中的NMS筛选[4]
3. 获取Object Detect结果
如图4.12所示。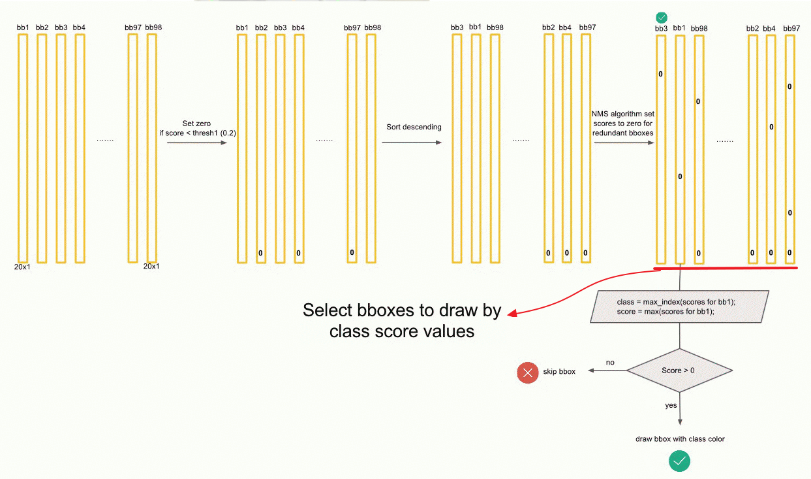
图4.12 YOLO V1生成bbox[4]
图4.13 YOLO V1生成bbox[4]
4 未理解的点
(1)为什么YOLO V1基于整张图做检测,它的背景错误比基于候选区域的小,怎么理解整合了整张图的上下文信息,从而减少了背景错误?
(2)怎么确定一个cell是一个物体的中心?
(3)正负样本是怎么分配的?
5 参考文献
[1] Redmon J , Divvala S , Girshick R , et al. You Only Look Once: Unified, Real-Time Object Detection[J]. arXiv preprint arXiv:1506.02640 2015.
[2] 【深度学习YOLO V1】深刻解读YOLO V1(图解)
https://blog.csdn.net/c20081052/article/details/80236015
[3] YOLOv1论文理解
https://blog.csdn.net/hrsstudy/article/details/70305791
[4] https://deepsystems.ai/reviews

若有收获,就点个赞吧
0 人点赞

{kind=link}
{kind=link}