阅读:2019.8.14
刊物:CVPR
引用:Zhao Q, Sheng T, Wang Y, et al. M2det: A single-shot object detector based on multi-level feature pyramid network[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2019, 33: 9259-9266.
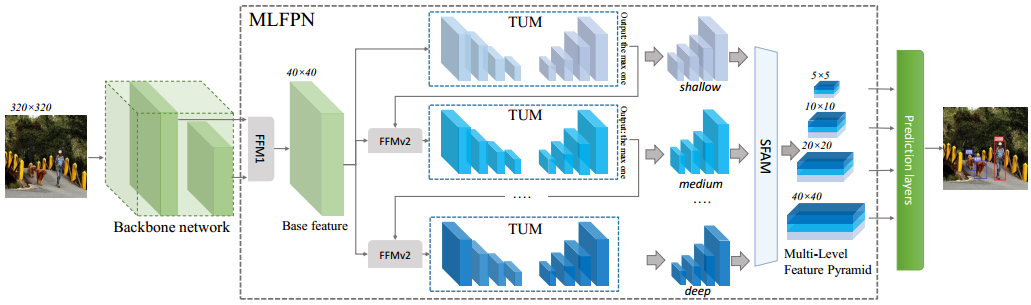
1 M2Det概述
目前有许多的目标检测算法都用到了类似FPN的“特征金字塔”结构,用于增强提取特征的有效性,但是他们都仅是对骨干网络应用了,然而骨干网络通常更适用于分类任务,或者说提取的特征更符合分类任务的需求。
基于上述认识,同时结合实验分析表明“不同尺寸、不同层级的特征具有不同的激活值分布,如图10.2所示”本文作者提出了MLFPN,搭建更有效的特征金字塔,用于提取更符合目标检测任务需求的特征,在backbone network提取的特征基础上(而非直接对backbone network产生特征的过程进行干预),分层级的提取不同的尺寸的特征。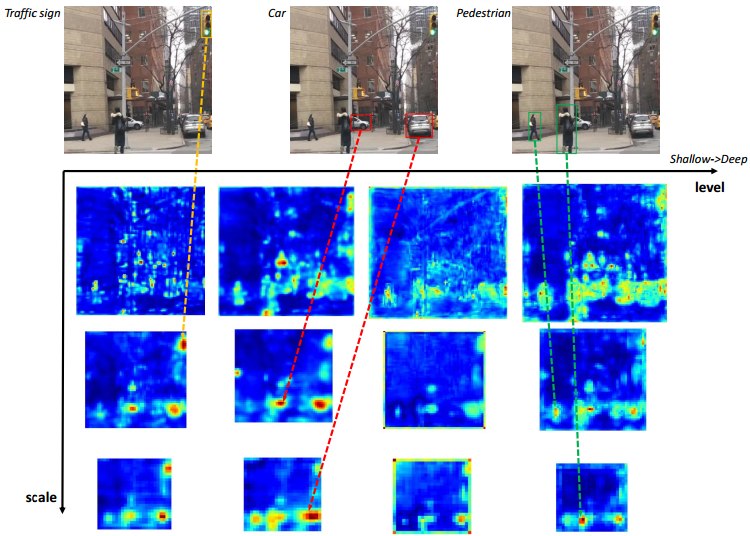
图10.2 不同层级、不同尺寸的特征图
2 M2Det创新点
提出了MLFPN结构:
- 以backbone network提取的特征(base feature)为基础,提取不同层级的特征
- TUM_1时,直接将base feature送入TUM;TUM_2,将TUM_1(Thinned U-shape Modules)的输出(尺寸最大的)与base feature经过FFM V2融合后送入TUM_2;TUM_3时,将TUM_2尺寸最大的输出与base feature经过FFM V2融合后送入TUM_3。
- 将各个TUM的输出统一尺寸后concat起来,构建用于目标检测的金字塔,其中的每个特征图(每个TUM的输出)都包含了多个层级的特征。
3 Introduction
3.1 解决多尺度问题的几种方法
多尺度训练是目标检测中比较常见的方法,目前主要如下几种策略:
- 图像特征金字塔
改变输入图像的尺寸(如图10.3所示),这种方法会增加算法对内存的需求,提高计算复杂度,因此现在用的不多。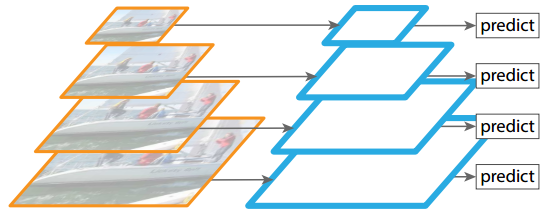
图10.3 图像特征金字塔
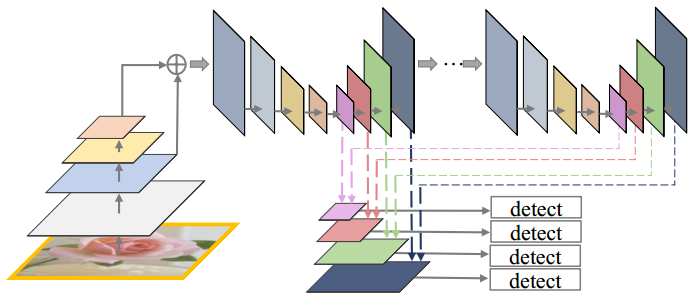
- Pyramidal feature hierarchy
特征金字塔。将各层特征图直接送入检测器中进行目标检测,不会产生额外的计算量,如图10.4所示。
深度网络逐层提取特征时,产生多尺度的子特征图,这些子特征图构成一个“特征金字塔”。这种因网络层次而产生的具有不同空间分辨率的特征图,由于处在不同深度,从而引起了较大的语义间隔。高分辨率的特征图具有低级特征,较弱的语义信息,这些损害了目标检测的表征能力(representational capacity)。
部分的算法采用该方法,如SSD。但文中认为,SSD没有提取足够低层次的特征,SSD最底层特征为VGG的conv4_3,FPN的实验表明,低层次特征有利于检测小目标。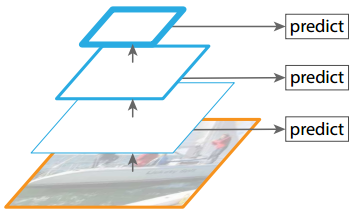
图10.4 Pyramidal feature hierarchy
- Feature Pyramid Networks
比较经典的就是FPN中提出的特征金字塔,不需要更多的内存,也不会增加计算复杂度,能够很简便的嵌入到已有的目标检测算法中。结构如图10.5所示。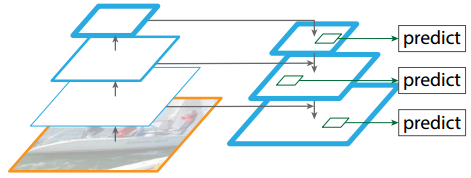
图10.5 Feature Pyramid Networks
3.2 已有多尺度方法的不足
利用FPN改进目标检测算法框架已经获得了比较好的效果,但仍然具有一定的局限性,一方面,因为他们都是根据backbone network固有的多尺度金字塔结构来构建特征金字塔,而backbone network通常是基于分类任务设计的结构,因此获得的特征图的表征性并不一定适用于目标检测任务。另一方面,特征金字塔中的每个特征图(用于检测特定大小范围内的对象)主要或仅仅由单层构造而成,即它主要只包含单层信息。
通常来说,在深层次的高级别(high-level)特征更有利于分类任务,而浅层次的低级别(low-level)特征更有利于目标定位回归任务。另外,低级特征更适用于内容简单的对象,而高级特征更适用于内容复杂的对象。实际上,大小相近的两个对象,可能具有完全不同的内容。
4 MLFPN
为了构建一个更高效的特征金字塔结构用于不同尺度的目标检测任务,同时避免10.3.2小节提出的不足。文章提出了下述解决方案:
- 利用backbone network提取特征,融合不同层级的特征,最终得到一个基础特征(base feature);
- 将base feature送入Thinned U-Shape Modules(TUM) 和 Feature Fusion Modules(FFM),以提取更具有表征性(representative)、多级别、多尺度的特征。其中U-shape结构中的decoder部分共享相同的深度。
- 将不同TUM得到特征图的相应层级(尺寸相同)的特征融合到一起,即最终金字塔的每个level上的特征是由几个TUM相应level上的特征构成的,如特征金字塔的A leve,由不同TUM输出金塔中的A level组成的,如图10.6所示。将这么一个特征金字塔送入检测器中检测。
5 M2Det
5.1 Multi-level Feature Pyramid Network
MLFPN由三个模块组成:Feature Fusion Module(FFM)、Thinned U-shape Module(TUM)、Scale-wise Feature Aggregation Module(SFAM)。如图10.7所示。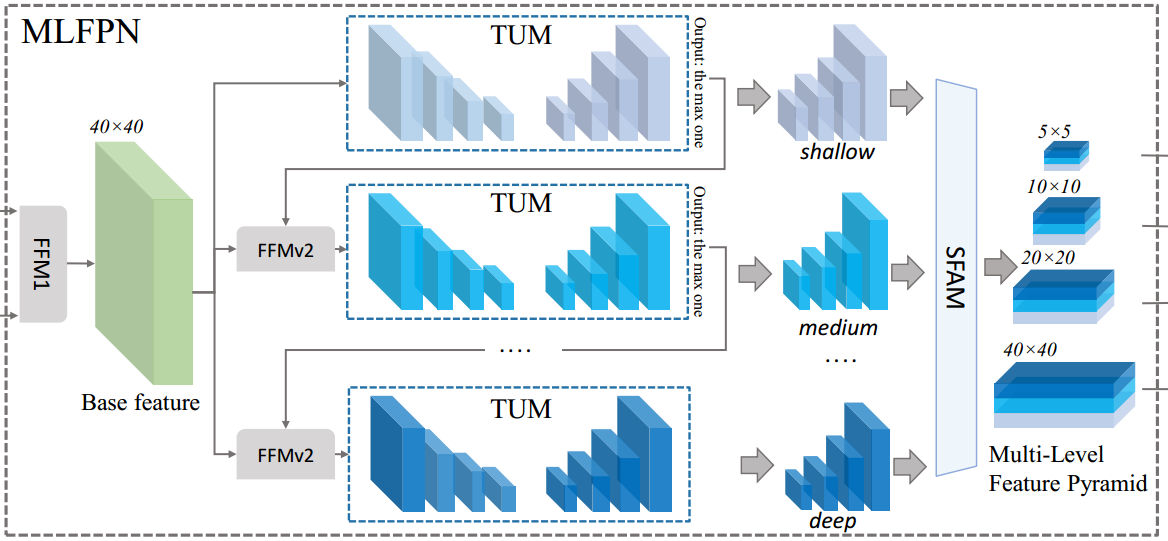
图10.7 MLFPN
1. FFMs
用于融合不同的特征,是构建特征金字塔的重要部分。使用1x1conv压缩输入特征的特征通道数,将不同特征的通道数归一化到同一数量。再利用concat方式融合特征。
a. FFMv1
用于融合backbone network提取的不同层级的特征,得到具有丰富语义信息的base feature。其融合了两个不同尺度的特征,对较深(尺度较小)的采用上采样操作,改变其尺寸,然后对两个特征进行concat操作。FFMv1结构如图10.8所示。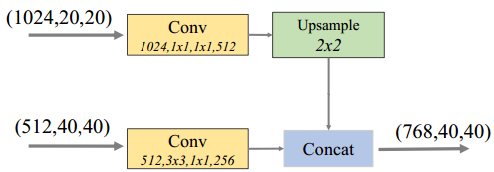
图10.8 FFMv1结构
b. FFMv2
用于融合base feature和TUM的最大输出(有多个不同尺寸的输出,与最大尺寸的特征融合),这两个特征图的尺寸是相同的。将融合后的特征送入下一个TUM模块。FFMv2结构如图10.9所示。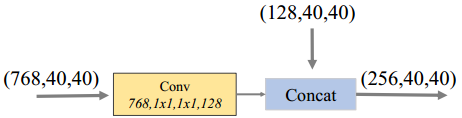
图 10.9 FFMv2结构
2. TUMs
TUM,每个TUM生成一组多尺度特征,交替的利用FFMv2融合base feature,作为下一个TUM的输入。第一个TUM的输入只有base feature。
TUM的结构如图10.10所示,采用了简化版本的U-shape结构:Encoder中,每层卷积模块仅使用conv 3x3,s=2的卷积操作,兼顾卷积和下采样操作,所以计算量相对较小。Decoder中,每层卷积模块使用conv 3x3 ,s=1的卷积操作。Encoder、Decoder相应特征图融合时,先利用upsample操作对decoder相应输出层进行上采样操作,再将其与Encoder相应层输出以逐像素相加的方式融合。
多个TUM堆叠,浅层的TUM主要用于提取浅层特征,中间TUM主要用于提取中间层特征,后面的TUM主要用于提取深层特征。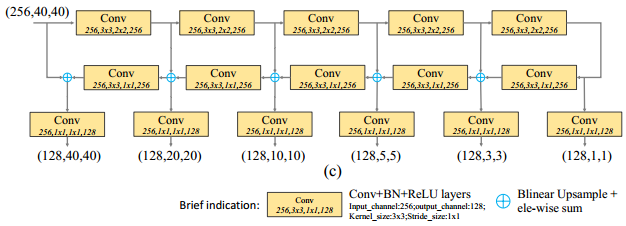
图10.10 TUMs结构
3. SFAM
1)将不同TUM输出中的相同尺寸的特征图以concat的方式组合在一起,结合自适应注意力机制(adaptive attention mechanism)将特征聚合到多层级特征金字塔中。
2)引入对通道显示建模的模块,通过对通道间的依赖关系和重要性进行建模,对带有重要特征信息的通道给予更大的权重。论文中采用的是SE模块。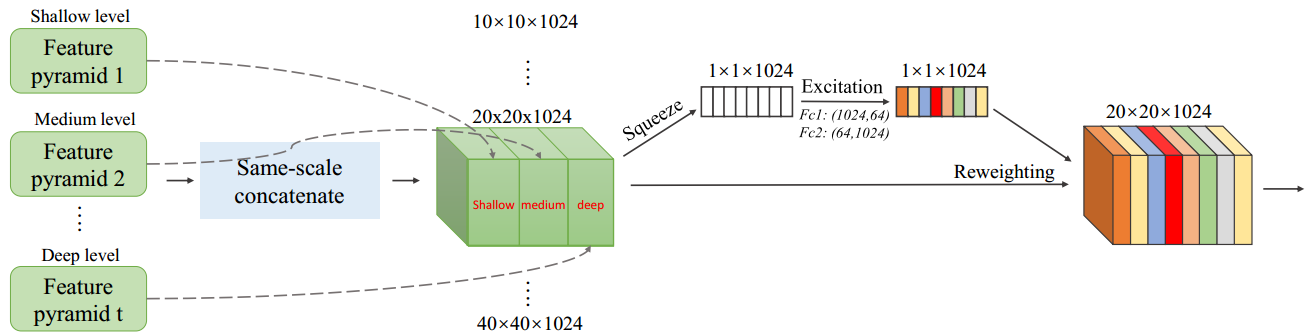
图10.11 SFAM结构
5.2 Network Configurations
- 采用了2种backbone network:残差网络、VGG网络。在ImageNet2012上进行预训练。
- 所有的MLFPN默认包含了8个TUM,每个TUM有5个striding-Conv和5个上采样操作,TUM中的每个尺寸的特征图的通道数为256.
- 输入尺寸有三种:320、512、800。
- 在检测阶段,我们向6个金字塔特征的每一个添加2个卷积层,以分别实现定位回归、分类。6个特征图生成的预测框的宽高比范围遵循SSD的设置。
- 当输入为800x800,除保持最大特征图的最小尺寸,在金字塔特征图中的每个像素点生成具有3中宽高比的6个anchors。然后,使用概率得分0.05作为阈值来过滤掉大多数得分较低的anchor。最后使用带有线性核(linear kernel)的soft-NMS来过滤bbox,得到最终的检测结果。
6 Experiment
6.1 Ablation study
基础算法结构是原始的SSD,输入为320x320,backbone network为VGG-16。消融实验数据如图10.12所示。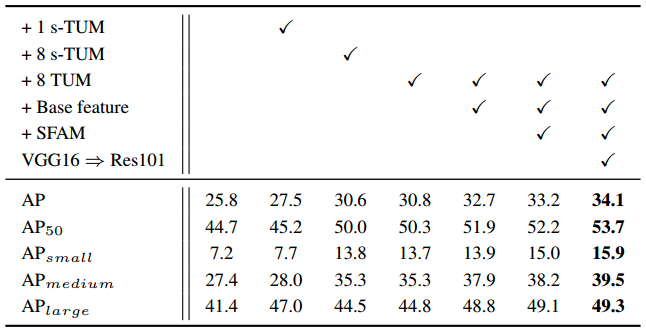
图10.12
- TUM
与DSSD类似,对baseline detector增加一系列的deconv layers,AP从25.8提高到27.5。
将一系列的deconv layers用1个TUM模块替代,AP从27.5提升到30.6,有了3.1幅度的提升。
最后,用多组TUM替代原有的一个TUM,获得了30.8的AP。
- Base feature
按照之前的设计,backbone network提取的特征只使用了一次,另外,后续TUM的通道数受限于第一个TUM,如果直接增加第一个TUM的通道数,那么会增加整个TUMs模块的参数量,如果通道数太少,则TUM提取特征的表征性不够。因此文中提出了FFMv1模块用于融合basebone network提取的特征,得到base feature。通过concat的方式将base feature与每个TUM的输出组合后送入下一个TUM,在不增加参数量的前提下,向TUM输入信息添加了低层次的信息,丰富了TUM的输入信息。增加base feature后,AP从30.8增加到了32.7。
- SFAM
添加SFAM后,AP从30.8增加到33.2。
- Backbone feature
将backbone network从VGG-16换成Res101后,AP从33.2提高到34.1。
6.2 Varitants of MLFPN
将backbone network固定为VGG-16,输入图像大小固定为320x320,然后调整TUM的数量和每个TUM的内部通道的数量。TUM的参数设计如图10.13所示。
可见,当固定通道数为256时,增加TUMs的个数,AP会随之上升,但Params也有了大幅增加。与增加通道数相比,增加TUM能够获得更大的AP提高,但两者在参数量的增加上是差不多的。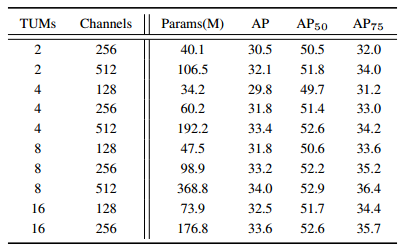
图10.13 TUM不同参数设计
6.3 Speed
batch size设置为1,将1000张图片的CNN处理时间和NMS筛选时间加起来后,除以1000,得到单个图像的检测时间(inference time)。具体来说,将简化版的VGG-16(去除FC层)嵌入到M2Det中,M2Det共三个版本:
- 输入为320x320,检测速度最快的版本
- 输入为512x512,标准版本
- 输入为800x800,准确率最高的版本
M2Det得益于one-stage检测框架和MLFPN获得了更好的速度和准确率。对比如图10.14所示。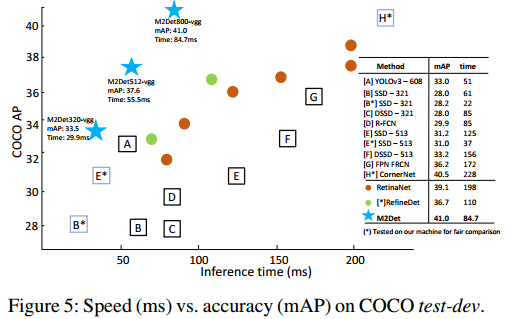
图10.14 检测速度-准确率对比图
6.4 Discussion
作者认为M2Det的检测准确率的提升主要是因为MLFPN结构。
一方面,将backbone network提取的multi-level特征融合,作为base feature,将其作为TUM模块和FFM模块输入的一部分,以提取更具表征性的特征,TUM是在backbone network之外的提出结构,结构更深,因此能够提取到更具表征性的特征,使其对于检测任务而言更具有代表性,更适用于检测任务。
另一方面,每个TUM提取得到的多尺度特征金字塔都会经SFAM整合,得到最终的多尺度金字塔。值得注意的是,在每个scale,都使用multi-level的特征用于检测,这能够提升网络对复杂对象的检测,更好地处理对象实例之间的外观复杂变化。

若有收获,就点个赞吧
0 人点赞
