阅读:2019.8.7-8.14
期刊:ICCV 2017
引用:Lin T Y , Goyal P , Girshick R , et al. Focal Loss for Dense Object Detection[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017, PP(99):2999-3007.
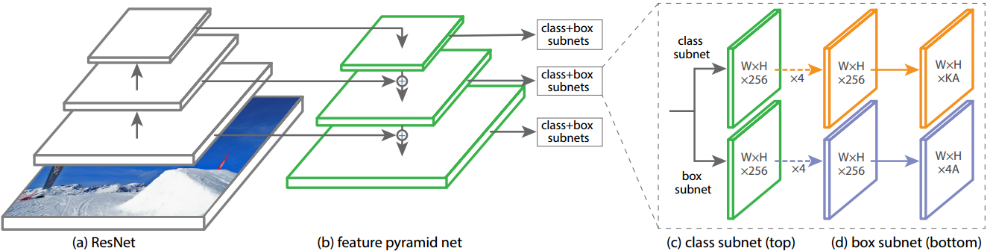
1 RetinaNet概述
本文主要目的是解决“one-stage”检测算法中正负样本不均衡的问题。
1. “two-stage”检测算法的正负样本不均衡问题
“two-stage”检测算法由两个步骤的级联完成检测任务,第一阶段提取候选框,能够初步的将候选框筛选到1~2k个,从而过滤掉大部分的“背景样本”;第二阶段利用“启发式采样(sampling heuristics)”,从第一阶段筛选的框中按“1:3(正样本:负样本)”采样得到第二阶段训练样本,从而保持正负样本的均衡性。这是“two-stage”算法速度慢,但精度高的原因。
2. “one-stage”检测算法的正负样本不均衡问题
“one-stage”检测算法是基于整张图片做检测的,将整张图片分成若干个cell,每个cell生成若干个bbox,则整张图片各个位置都覆盖了不同大小、宽高比(aspect ratio)的bbox(>100k)。负样本占据大部分(1:1000),负样本易于分类,对训练贡献很小,一旦数量过多就会主导训练过程(导致模型退化),会影响网络对正样本的分类性能,从而影响检测精度。此时,虽然也可运用sampling heuristics方法,但效率较低,因为训练仍然由易分类的负样本主导。经典的样本均衡策略:boostrapping、hard example mining等,在这类情况下的效率也较低。这是“one-stage”算法速度快,但精度低的原因。
3. Focal loss
基于上述问题,本文从损失函数的角度着手,提出新的损失函数(Focal loss)用于正负样本均衡方法。在标准交叉熵的基础上添加了“调节因子(modulating factor)”、“权重因子(weighting factor)”和“聚焦参数(focusing factor)”,使得其成为一个动态缩放的交叉熵损失(dynamically scaled cross entropy loss),促使网络训练时自动减小负样本的损失权重,提高正样本的损失权重,更侧重于训练正样本。
4. RetinaNet
为了验证Focal loss的有效性,在FPN基础上提出了RetinaNet单步(one stage)检测算法,其检测、分类两个分支采用相同的主体结构设计,只有输出张量的维度不同,如图7.1所示。
2 RetinaNet创新点
用于二元分类的交叉熵函数(cross entroy,CE)如图7.2所示,Focal loss就是在该函数基础上提出的。CE当样本易于分类时( ),其损失值仍然较高(non-trivial magnitude),如图7.3中蓝色曲线(当
),其损失值仍然较高(non-trivial magnitude),如图7.3中蓝色曲线(当 时,为CE函数的分类性能曲线),如果这类易分类样本占了多数,将会主导训练过程,无法训练正样本的分类。
时,为CE函数的分类性能曲线),如果这类易分类样本占了多数,将会主导训练过程,无法训练正样本的分类。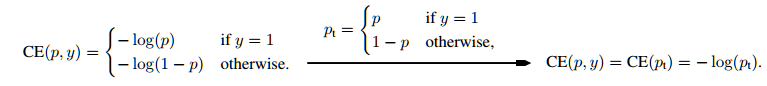
图7.2 交叉熵函数(cross entroy, CE)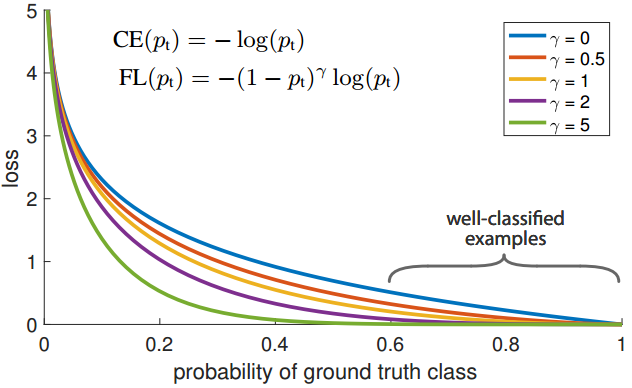
图7.3 不同参数的focal loss分类性能
3.1 Balanced CrossEntropy
解决正负样均衡的常见方法之一时是在CE基础上添加一个权重因子(weighting factor),如公式7.1所示。对于正样本,权重因子为,对于负样本,权重因子为。实际应用中,可以为超参数,也可以由类别的比例倒数决定。 (公式7.1)
(公式7.1)
该方法解决了正负样本的比例失衡问题,但没有区分“易分类样本”和“难分类样本”。
3.2 Focal Loss Definition
“one-stage”检测算法是基于整张图片做检测的,整张图片各个位置都覆盖了不同大小、宽高比(aspect ratio)的bbox(>100k)。负样本占据大部分(1:1000),负样本易于分类,对训练贡献很小,一旦数量过多就会主导训练过程(导致模型退化),影响网络对正样本的分类性能。7.3.1节的方法虽然能够解决正负样本的比例失衡问题,但无法区别“易分类样本”和“难分类样本”。故本文以7.3.1小节的算法为baseline,添加了调节因子“modulating factor ”( )、聚焦参数
)、聚焦参数 (focusing factor),两者以“
(focusing factor),两者以“ ”形式添加到损失函数中。同时,使用sigmoid函数处理
”形式添加到损失函数中。同时,使用sigmoid函数处理 ,增加模型的数值稳定性。
,增加模型的数值稳定性。
1. 调节因子
通过调节因子,降低易分类样本在损失中的权重,增加难分类样本在损失中的权重。
(1)易分类样本的分类概率值比较高( ),
), ,使该样本对损失的贡献较小。
,使该样本对损失的贡献较小。
(2)难分类样本的分类概率值比较低( ),
), ,使该样本对损失的贡献较大。
,使该样本对损失的贡献较大。
2. 聚焦参数
通过调整大小 (本文取
(本文取 ),控制调节因子的对损失函数的影响程度。当时,focal loss相当于普通的CE loss;
),控制调节因子的对损失函数的影响程度。当时,focal loss相当于普通的CE loss; 越大,调节因子对损失函数的影响越大。如图7.4所示,对于一个收敛模型(converged model),
越大,调节因子对损失函数的影响越大。如图7.4所示,对于一个收敛模型(converged model), 的变化对正样本的损失分布影响较小,对负样本的损失分布影响较大,这样促使训练损失中,正样本损失占更大的比例,整个训练过程有利于正样本的分类训练。
的变化对正样本的损失分布影响较小,对负样本的损失分布影响较大,这样促使训练损失中,正样本损失占更大的比例,整个训练过程有利于正样本的分类训练。
如 ,易分类样本(
,易分类样本( )的损失相比于CE,小了100倍;当
)的损失相比于CE,小了100倍;当 ,小1000+倍。难分类样本(
,小1000+倍。难分类样本( ),损失最多小4倍。可见难分类样本的权重相对提升了许多。
),损失最多小4倍。可见难分类样本的权重相对提升了许多。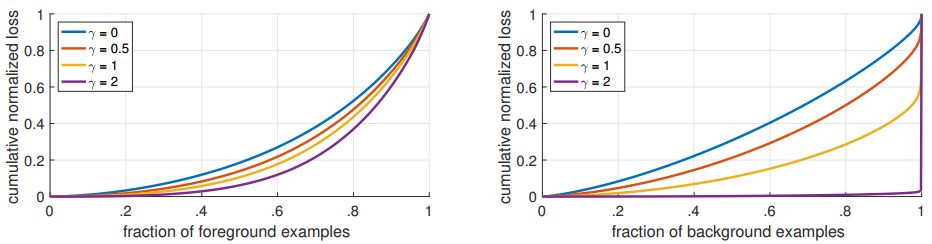
图7.4 不同 对损失值得影响,左图为对正样本的影响,右图为对负样本的
对损失值得影响,左图为对正样本的影响,右图为对负样本的
3. Focal loss的影响
如表7.1所示。
表7.1 Focal loss对样本分布的影响
| Loss量级 | 数量多的类别 | 数量少的类别 |
|---|---|---|
| 易分类样本的loss | 大幅减少 | 稍微减少 |
| 难分类样本的loss | 适当减小 | 几乎保持不变 |
3.3 Class Imbalance and Model Initialization
通常来讲,二分类模型初始化后,预测结果(y=1 or y=-1)的机会是均等的(随机猜想,等概率),即都是0.5的概率。但是在正负样本比例严重不均衡的情况下,这种设定会使占多数的类别能够主导训练走向,并导致早期训练的不稳定性。
故本文提出初始化模型参数的一种方法,使得模型对稀有类别的预测概率变小(如小0.01倍),即在训练开始时,模型为稀有类(正样本)估计Π值,以定义先验,并使模型为稀有类别样本估计的Π值较小,如0.01。通过设置Π,稀有类的概率P值会更小,从而在loss中占更大的权重。
实验表明该方法对CE和focal loss的性能提升都有帮助这是模型初始化的改变,不是损失函数的改变。具体操作参考7.5.6。
3.4 Class Imbalance and Two-stage Detectors
“two-stage”检测算法由两个步骤的级联完成检测任务。
第一阶段提取候选框,能够初步的将候选框筛选到1~2k个,从而过滤掉大部分的“背景样本”;
第二阶段利用“启发式采样(sampling heuristics)”,从第一阶段筛选的框中按“1:3(正样本:负样本)”采样得到第二阶段训练样本,从而保持正负样本的均衡性。
4 RetinaNet Detector
RetinaNet是一个“one-stage”算法,由一个骨干网络(backbone)和两个特定任务子网络(task-specific subnetworks)构成,如图7.1所示。骨干网络对整张图片进行特征提取,第一个子网络负责分类,第二个子网络负责回归定位。
4.1 Feature Pyramid Network Backbone
主要参考了FPN的特征金字塔结构,如图7.5所示。在提升速度,且保持准确率的同时,本文的设计与原始FPN有几点不同:
(1)考虑到计算开销,未使用P2的特征图(采用了P3~P7)。
(2)采用s=2的conv进行下采样,而非池化操作。
(3)为提升对大物体的检测性能,使用P7的特征图。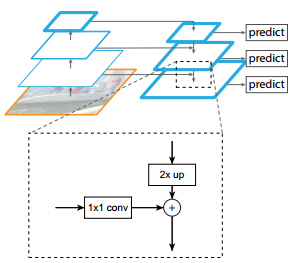
图7.5 FPN特征金字塔结构
4.2 Anchors
(1)FPN的每层都有9种anchor box
3种aspect ratio:{1:2, 1:1, 2:1}
3种scale:{2^0, 2^1/3, 2^2/3}
(2)类别与bbox坐标
长度为k的one-hot表示所属类别,共k类
4维tensor表示bbox的坐标
(3)利用IoU对分类anchor box
IoU >= 0.5 anchor box 为目标框/正样本/前景(foreground)
0 <= IoU < 0.4 anchor box 为背景框
0.4 <= IOU < 0.5 anchor box 丢弃,不用于下一步预测
4.3 Classification Subnet
该分类分支对特征金字塔生成所有的anchor box进行分类,所有分类分支的参数都共享。
(1)输出
每个cell生成A(9)个anchor box,K个类别,特征图为WxH,则总的输出为WxHxKA,由3x3conv + sigmoid计算得到。
(2)结构设计
4个3x3 conv,通道数为C(C=256),激活函数为ReLU,如图7.6红框部分所示。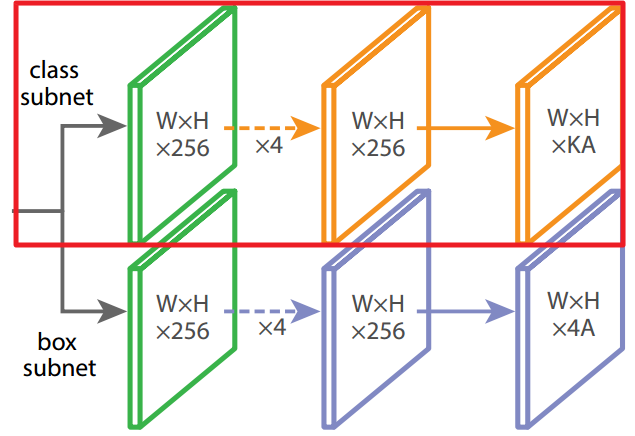
图7.6 RefinaNet分类分支
4.4 Box Regression Subnet
该分类分支对特征金字塔生成所有的anchor box进行回归定位,所有分类分支的参数都共享。与分类分支具有一样的隐藏层设计,但是参数不共享。将分类与回归定位分布用两个分支完成,实现了分类、回归定位的解耦。如图7.6所示。
4.5 Initialization
(1)采用ResNet-50-FPN、ResNet-101-FPN作为骨干网络。在ImageNet上进行分类预训练。
(2)从ImageNet预训练得到的basenet不做调整,新加入的卷积层权重初始化为的高斯分布,偏置项置0。
(3)分类网络的最后一个卷积层,将偏置项置为,为超参数,每个anchor被分类为前景的概率,文中=0.01。
4.6 Optimization
RefinaNet的优化策略如表7.2所示。
表7.2 RefinaNet的优化策略
| Optimizer | SGD |
|---|---|
| Minibatch | 16 |
| Iterations | 90k |
| Initial learning rate | 0.01,在60k时除以10;在80k时再除以10 |
| Date augmentation | 水平翻转(horizontal image flipping) |
| Loss | Focal loss用于分类,smooth L1 loss用回归定位 |
5 RefinaNet思维导图
以思维导图的方式,将RefinaNet各个知识点串联起,有利于构建RefinaNet的知识树。如图7.6所示。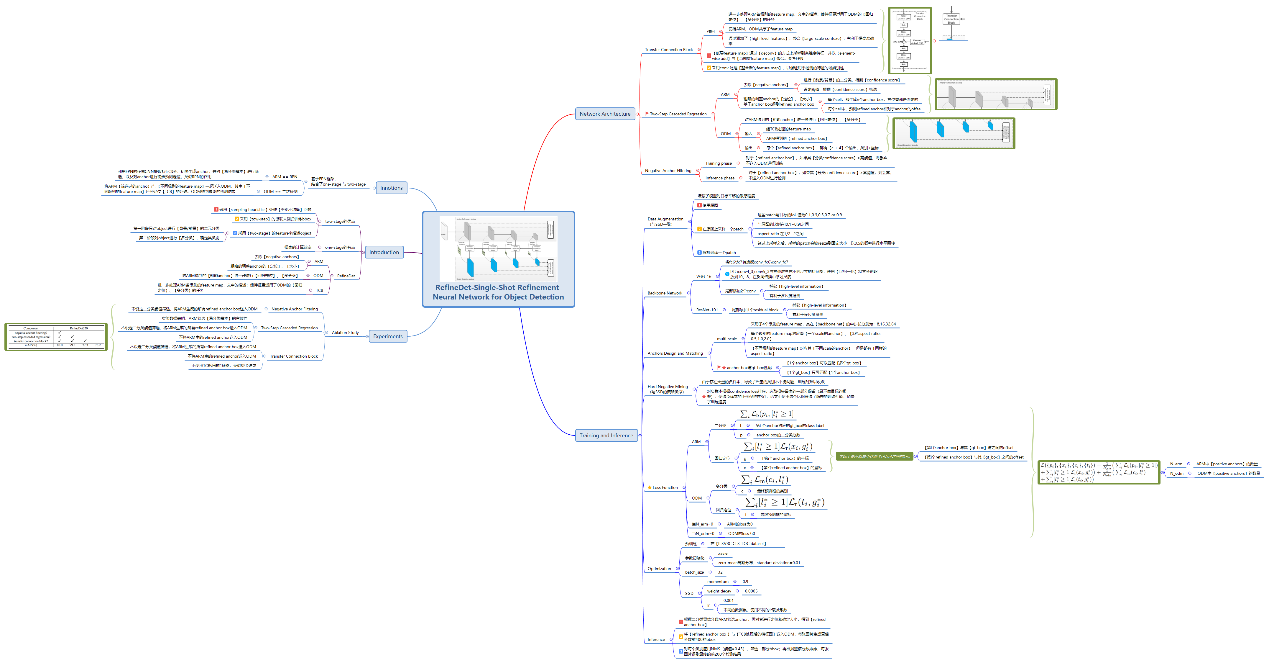
图7.6 RefinaNet思维导图
6 未理解的点
(1)7.3.3小节,不了解是怎么对“难分类样本”添加一个先验值的,是怎么确定其为“难分类样本”的。
(2)7.5节的内容待深入理解。
7 参考文献
[1] Lin T Y , Goyal P , Girshick R , et al. Focal Loss for Dense Object Detection[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017, PP(99):2999-3007.
[2] Focal Loss论文阅读 - Focal Loss for Dense Object Detection
https://xmfbit.github.io/2017/08/14/focal-loss-paper/

若有收获,就点个赞吧
0 人点赞
