前言
指针离不开内存,本文建议配合内存管理入门文章一同观看。
由于是入门文章,对本质的理解需要借助C的IO流操作来自动处理数据类型,所以可能涉及一些C的基础内容。但关于指针部分的内容二者完全通用。
指针基础
int i = 1;int *p = NULL;p = &i;
p是个指针,指向了i,我们都知道。那么到底指针是如何工作的?指针有什么用?令人头晕的指针操作到底如何使用如何理解?
下面我们用一种极其简单的描述来重现上面三行代码。
第一行我们在内存里找了一块叫做 i 的空间,让这个空间的值是1。
第二行我们又在空间里找了一块叫做 p 的空间,让这个空间的值是0;
第三行我们干了一件事,我们找到了那个叫做 i 的空间,把它的内存地址放在了叫做p的空间里。
这三个操作如下图所示: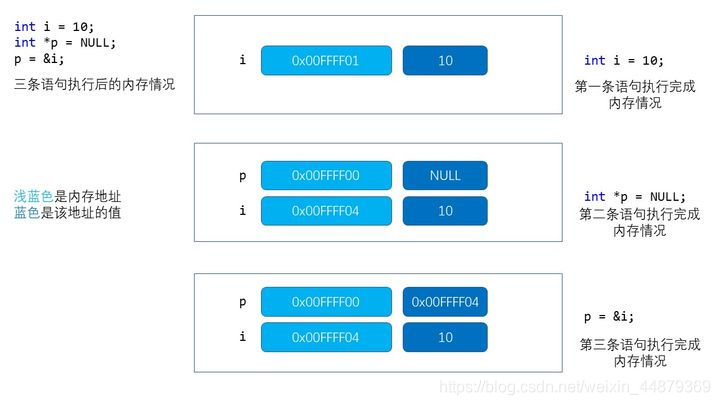
这样我们去查看p的内容时发现了一个地址,我们访问这个地址就发现了一个值,也就是变量i的值。
void PointerBasic(){ //指针的基础int i = 1;int *p;p = NULL;p = &i;/** *p是解指针,p储存了一个变量的地址* *p会把这个地址指向的值解析出来,在解析的过程中* 已经和变量i没什么关系了* &是取地址符,会取一个变量的地址*/cout << "i的值\t" << i << endl;cout << "i的地址\t" << &i << endl;cout << "*p\t" << *p << endl;cout << "p的值\t" << p << endl;cout << "p的地址\t" << &p << endl;cout << "&*p\t" << &*p << endl;//这两个符号会互相抵消}
我们可以通过打印他们的值和地址来观察他们之间的关系。
对于指针来说,指针只是一种普通的变量类型,类似于int,double或者char。
数组内存
int arr[5] = {1,2,3,4,5};
我们定义了一个数组,长度是5,储存了5个值。我们可以通过下标访问数组中的每个值。下面我们看一下这个数组在内存中是如何储存的。
std::cout << arr;
上面这行代码会输出一个地址。这个地址是数组的首地址。
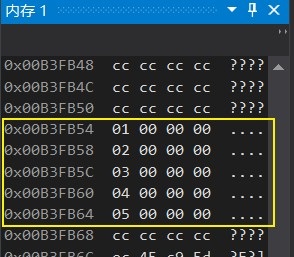
我们发现这个地址储存了1,随后的四个地址便是其他的4个元素。
C/C++使用数组名作为地址,所以在没有方括号的时候arr代表第一个地址。
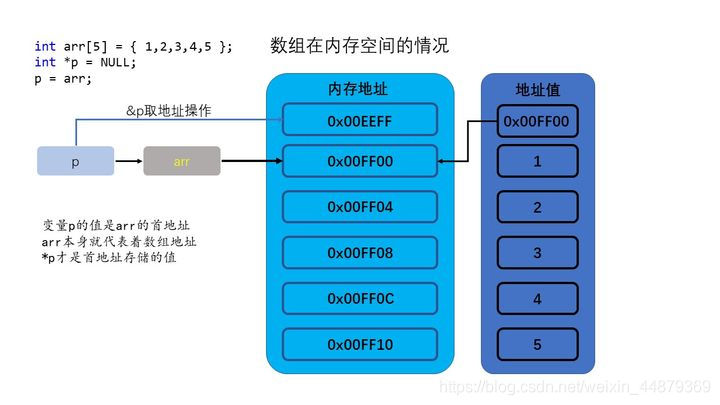
既然他是地址,那么我们就可以通过指针访问。
例如下面这个用C语言指针遍历10个数组元素的示意图。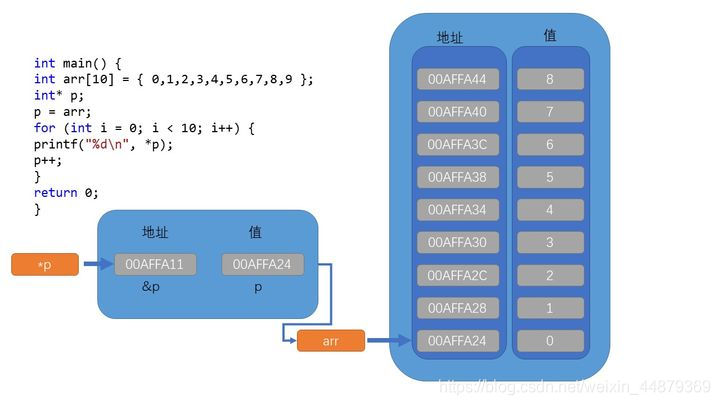
他们之间的关系大致是这个样子的。
指针p加上1会变成什么?
我们知道p只是一个值,这个值是个地址,地址也是数,比如0x00加上1就变成了0x01。
但是指针的特殊之处在于,指针是int类型的话,那么他认为一个单位就是一个int的单位,即四个字节,就会把值加上4。如下图: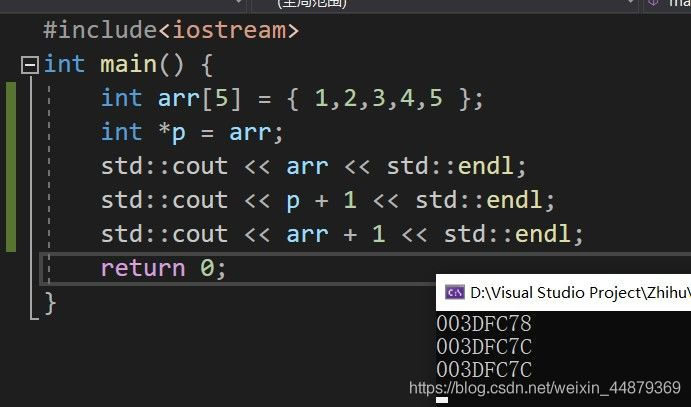
对于int类型的指针来说,4个字节才是1个单位。
指针的指针
看下面这段令人迷惑的代码:
int i = 10;int *ptr = &i;int **pptr = &ptr;//this is a double pointerint ***ppptr = &pptr;//this is a triple pointerint ****pppptr = &ppptr;//please don't do this.cout << ***ppptr;
两个*的指针就是双重指针,是指向指针的指针。
一个指针的本质既然是储存地址的变量,那么这个变量本身一定是有个地址的。
再拿一个指针指向这个地址。那么这个指针就称作指针的指针。
只不过指针的指针只能指向指针,不能指向值。例如三重指针只能指向二重指针,不能跨层次指向。
如果你有兴趣,可以试一试这道题: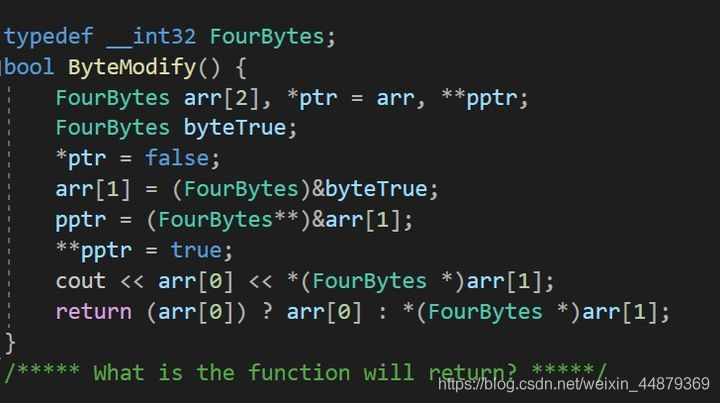
组类型
数组、字符串等我们能看到有中括号的地方大多数都有组的概念。把一系列相同的东西组合在一起就是组。
例如数组,就是数字的组合。
指针的组合,就可以称为指针组,也就是C/C++的指针数组。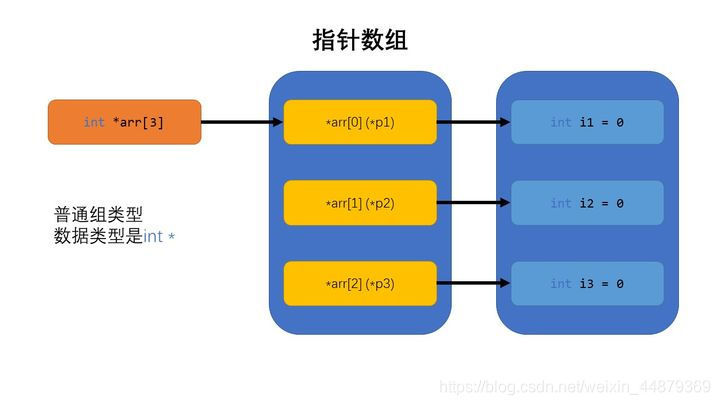
他们和数组的区别是,数组储存数,而他们储存指针。
对组来说:
组里面是数就是数组。
是字符型就是字符数组,也叫字符串。
组里面是指针就是指针数组。
组里面可以是任何东西,浮点型、对象、结构体甚至函数。
int i1, i2, i3;i1 = i2 = i3 = 0;int *p1 = &i1, *p2 = &i2, *p3 = &i3;int *arr[3] = { p1,p2,p3 }; //指针数组就是存指针的数组//更适合理解成普通指针,但是写成 int* 类型的arr[3]//储存的元素也是(int*)类型cout << "arr\t" << arr << endl;cout << "arr[0]\t" << arr[0] << endl;cout << "&arr[0]\t" << &arr[0] << endl;cout << "*arr[0]\t" << *arr[0] << endl;cout << "&arr\t" << &arr << endl;cout << "&arr[0]\t" << &arr[0] << endl;cout << "arr+1\t" << arr + 1 << endl;cout << "*arr+1\t" << *arr + 1 << endl;cout << "*(arr+1)" << *(arr + 1) << endl;cout << "&arr+1\t" << &arr + 1 << endl;
观察这段代码的输出,我们可以一窥运算符之间的关系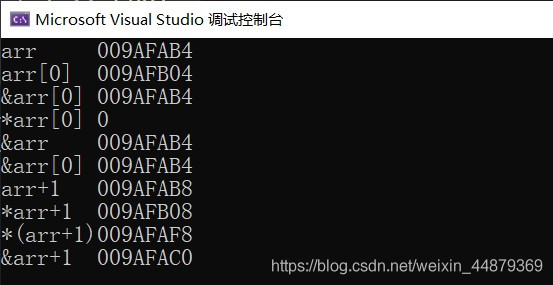
二维数组
我们在讨论计算机中的维度时指的是离散的维度。
例如二维数组可以理解成特殊的一维数组,这个一维数组的每个元素都是一个组合。

那么我们就可以定义一个储存组的指针。
int(*p)[3];//指向的类型是一个组类型,一个组是一个单位。这个单位的大小是3//二维数组的本质便是一维数组的特殊情况,只是一维数组的每个元素都是一个组int arr[2][3] = { {1,2,3},{4,5,6} };p = arr;
加括号是调整优先级,区别于数组指针。他的本质还是*p,只不过他需要接收一个长度是3的数组类型。
cout << "*p\t" << *p << endl;cout << "*p[0]\t" << *p[0] << endl;cout << "*p[0]+1\t" << *p[0] + 1 << endl; //编号为0的组加上一个元素// cout << "*(p[0]+1)\t" << *(p[0] + 1) << endl;//It was the samecout << "*p[1]\t" << *p[1] << endl;cout << "*p[1]+1\t" << *p[1]+1 << endl;cout << "*p+1\t" << *p + 1 << endl;cout << "*(p+1)\t" << *(p + 1) << endl;cout << "&p\t" << &p << endl;cout << "p\t" << p << endl;cout << "arr\t" << arr << endl;cout << "&arr\t" << &arr << endl;
可以通过上述代码观察规律。
清楚了这个概念后我们就可以进行套娃
int(*p)[2][3];int arr[1][2][3] = {{{1,2,3}, {4,5,6}}};p = arr;
除特殊算法和需求,否则维度尽量控制在三层以内。超过三层请使用更合适的数据结构。
函数名作地址
假设我们有一个函数
int func(int a,int b){return a+b;}
这个简单的加和函数的函数名func代表着这个函数的地址,和字符串、数组一样属于首地址。
那么我们就可以用指针来接收它。
int (*p)(int, int);//int是指针类型,(*p)属于函数名,(int,int)是参数列表p = func;//函数名可以在内存中也代表地址,同数组的头地址一样。//将代表同样函数的指针接收函数名地址//注意参数列表的一致性,否则会发生重载或非法访问int i = (*p)(1, 2);//整体会作为一个函数储存在接收变量中。
这样我们就可以通过指针直接调用函数进行操作。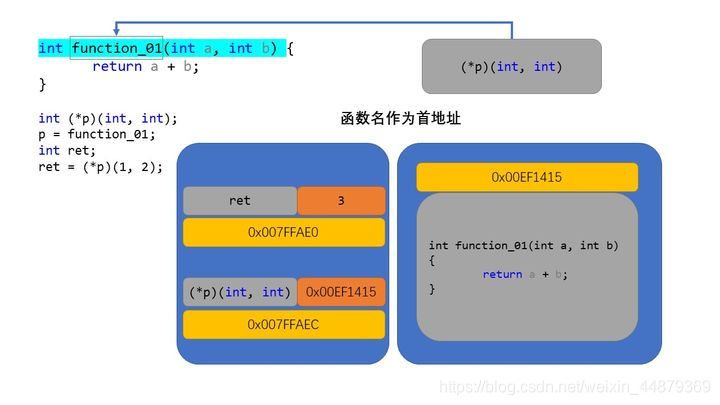
结构体同理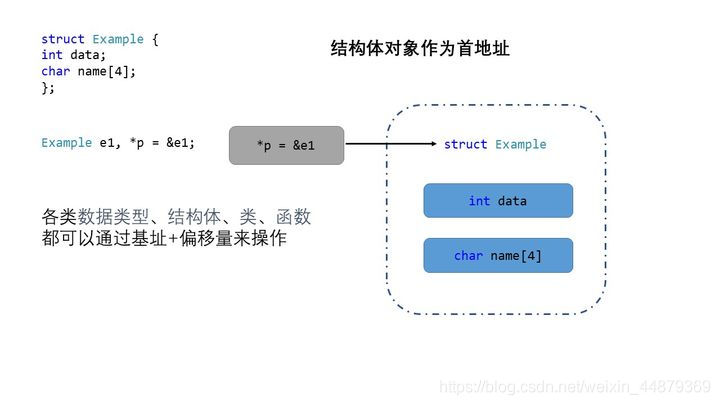
结构体、类、自定义数据结构都可以进行类似操作。这属于基址+偏移的操作概念。可以阅读内存管理来清楚内存是如何通过指针操作的。
那么既然函数名是首地址,我们可不可以把一堆函数做成组和然后用组合指针去接收他们?
当然可以。
int f1(int a) {return a;}int f2(int b) {return b;}
实现起来是这样的
int (*pf[2])(int);//同数组一样,函数名能表示头地址,那么也可以做成组pf[0] = f1;pf[1] = f2;i = (*pf)(5);j = (*pf)(2);cout << i << j << endl;
这样是完全合法的,在早期没有重载和面向对象等概念时可以通过这种方法快速访问一些同类函数。而且可以封装成二维函数数组、多维函数数组等等复杂概念。
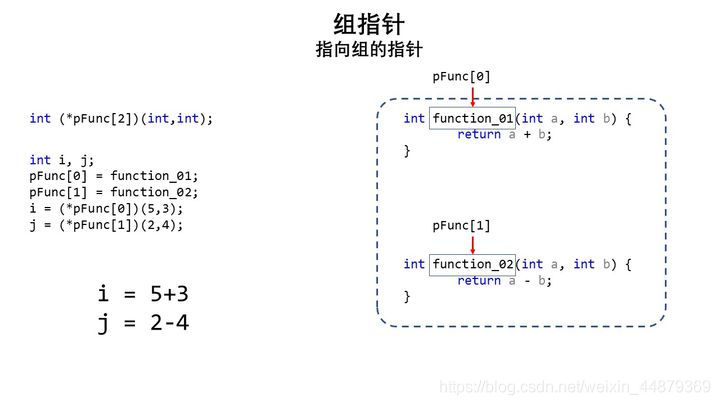
组的概念相当广泛且灵活,但是不合规的访问很容易造成冲突和未知错误,也请仔细斟酌不同运算符之间的优先级和本质。

若有收获,就点个赞吧
0 人点赞
