索引定义:是存储引擎用于快速查找记录的一种数据结构。需要额外开辟空间和数据维护工作。
- 索引是物理数据页存储,在数据文件中(InnoDB,ibd文件),利用数据页(page存储)
- 索引可以加快数据查询速度,但是同时也会降低增删改操作速度,索引维护需要代价
本质:通过不断地缩小想要获取数据地范围来筛选出最终想要地结果,同时把随机地事件变成顺序地事件。
在Mysql中,索引是在存储引擎层实现的,所有并没有统一的索引标准,即不同存储引擎的索引的工作方式并不一样。由于InnoDB在Mysql中使用最为广泛,以下说明皆以InnoDB为例。
01|InnoDB索引模型
InnoDB使用了B+树索引模型,所有数据都是存储在B+树中。表都是根据主键顺序以索引的形式存放。每个表实质上就是多个B+树(一个主键索引树和多个非主键索引树),主键索引树的叶子节点为具体的数据行,非主键索引树的叶子节点为主键索引,如图: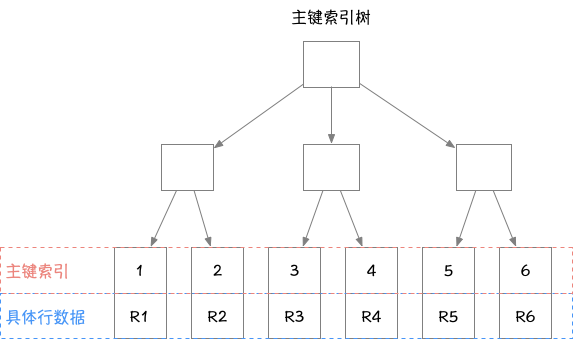
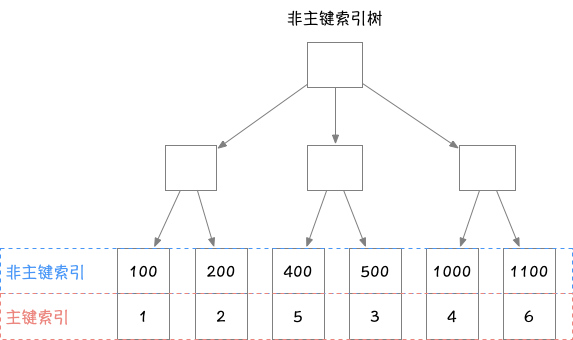
由图可以看出主键索引的叶子节点存的是整行数据,主键索引也被称为聚簇索引;非主键索引的叶子节点内容是主键的值,非主键索引也被称为二级索引。当一个查询语句以主键的方式进行查询时,则只需要搜索主键索引树即可,而使用普通索引进行查询时,需要先搜索普通索引树得到主键索引,然后再根据主键在主键索引树上定位具体的行记录数据,这个过程称为回表。
02|常用索引
- 普通索引:加速查找
- 唯一索引
- 主键索引:加速查找+约束(不为空、不能重复)
- 唯一索引:加速查找+约束(不能重复)
- 联合索引
- 联合普通索引
- 联合主键索引
- 联合唯一索引
03|索引性能分析
Mysql提供了EXPLAIN命令对SELECT语句进行分析,并输出SELECT执行地详细信息
id: 1select_type: SIMPLEtable: userpartitions: NULLtype: rangepossible_keys: PRIMARYkey: PRIMARYkey_len: 4ref: NULLrows: 1filtered: 100.00Extra: Using where
- select_type:表示查询的类型,常用值如下:
- SIMPLE:表示当前查询不包含子查询或union
- PRIMARY:表示此查询是最外层的查询
- UNION:表示此查询是UNION的第二个或后续的查询
- DEPENDENT UNION:UNION中的第二个或后续的查询语句使用了外面查询结果
- UNIONT RESULT:UNION的结果
- SUBQUERY:SELECT子查询语句
- DEPENDENT SUBQUERY:SELECT子查询语句依赖外层查询的结果
- type:表示存储引擎查询数据时采用的方式,通过该属性可以判断出查询是全表扫描还是基于索引的部分扫描,常用属性值如下,从上至下效率依次增强
- ALL:全表扫描
- index:基于索引的全表扫描
- range:基于索引的范围查询
- ref:基于非唯一索引进行单值查询
- eq_ref:一般出现在多表join查询,表示前面表的每个记录都只能匹配后面表的一行结果
- const:基于主键或唯一索引做等值查询
- NULL:不用访问表
- possible_keys:查询时能够使用到的索引,并不一定会真正使用
- key:查询是真正使用到的索引
- rows:查询优化器根据统计信息估算查询到结果需要扫描的行记录数
- key_len:表示查询使用了索引的字节数量,可以判断是否全部使用了组合索引,key_len的计算规则如下:
- 字符串类型:字符串长度跟字符集有关:latin=1、gbk=2、utf8=3、utf8mb4=4。
- char(n):n*字符集长度
- varchar(n):n*字符集长度+2字节
- 数值类型
- TINYINT:1个字节
- SMALLINT:2个字节
- MEDIUMINT:3个字节
- INT、FLOAT:4个字节
- BIGINT、DOUBLE:8个字节
- 时间类型
- DATE:3个字节
- TIMESTAMP:4个字节
- DATETIME:8个字节
- 字段属性:NULL属性占用1个字节,如果一个字段设置了NOT NULL,则没有此项
- 字符串类型:字符串长度跟字符集有关:latin=1、gbk=2、utf8=3、utf8mb4=4。
- Extra:额外提示信息
- Using where:表示查询需要通过索引回表查询数据
- Using index:表示查询需要通过索引并且索引就能满足所需数据,不需要回表
- Using filesort:查询结果需要额外排序
- Using temporary:查询需要用到临时表
04|最左前缀原则
Mysql建立联合索引时会遵守最左前缀匹配规则,即最左优先,在检索数据时从联合索引的最左边开始匹配。如建立复合索引(a,b,c),当查询使用索引(a)、(a,b)、(a,b,c)时索引生效,其他情况下索引不生效。
05|普通索引和唯一索引
查询过程
- 普通索引:当查到满足条件的第一个记录后,需要查找下一个记录,直到碰到第一个不满足条件的记录
- 唯一索引:由于索引定义了唯一性,当查到第一个满足条件的记录后,就会停止进行检索
由于InnoDB的数据是按 数据页为单位进行读写的,所以,当需要读一条记录时,并不是将这个记录本身从磁盘读出来,而是以页为单位,将其整体读入内存。在InnoDB中,每个数据页的大小默认就是16KB。所以唯一索引和普通索引不同带来的查询性能差距微乎其微。
更新过程
在说明两种索引类型在更新过程中的性能对比需要先介绍以下change buffer
change buffer
当需要更新一个数据页时,如果数据页在内存中就直接更新内存,而如果这个数据还没有在内存中,则在不影响数据一致性的前提下,InnoDB会将这些更新操作缓存在change buffer中,这样就不需要在磁盘中读入这个数据页了。在下次查询需要访问这个数据页的时候,将数据页读入内存,然后执行change buffer中与这个页有关的操作。change buffer同时也会被写入到磁盘上,避免异常情况下数据丢失。将change buffer中的操作应用到原数据页得到最新结果的过程称为merge,除了访问这个数据页会触发merge外,系统有后台线程也会定期merge,在数据库正常关闭的过程中,也会执行merge操作。可见使用change buffer能够减少磁盘IO,能够显著提升性能。
对于唯一索引来说,所有的更新操作都要先判断这个操作是否违反唯一性约束,执行更新操作之前必须将数据页从磁盘读入内存才能进行判断。因此,唯一索引的更新不能使用change buffer,实际上也只有普通索引可以使用。

若有收获,就点个赞吧
0 人点赞
