CAP定理
一个分布式系统不可能同时满足一致性(C:Consistency)、可用性(A:Availability)和分区容错性(P:Partition tolerance)这三个基本需求,最对只能同时满足其中的两个
| 选项 | 描述 |
|---|---|
| C(一致性) | 分布式环境中,数据在多个副本之间能够保持一致的特性。 |
| A(可用性) | 系统提供的服务必须一直处于可用的状态,每次请求都能获取到非错的响应,但不保证获取的数据为最新数据。 |
| P(分区容错性) | 系统在遇到任何网络分区故障的时候,仍然能够对外提供满足一致性和可用性的服务,除非整个网络环境都发生了故障 |
Base理论
全称:Basically Available(基本可用)、Soft state(软状态)、Eventually consistent(最终一致性)三个短语的缩写。
核心思想:既是无法做到强一致性(Strong consistency),但每个应用都可以根据自身的业务特点,采用适当的方式来使系统达到最终一致性(Eventual consistency)
Basically Available(基本可用)
当分布式系统在出现不可预知故障时,允许损失部分“可用性”
- 响应时间的损失:允许一定的响应延迟
- 功能损失:服务降级
Soft state(软状态)
允许系统中的数据存在中间状态,并认为该状态不影响系统的整体可用性,即允许系统在多个不同节点的数据副本之间进行数据同步的过程中存在延迟Eventually consistent(最终一致性)
最终一致性强调的是系统中所有的数据副本,在经过一段时间的同步后,最终能够达到一个一致的状态。因此最终一致性的本质是需要系统保证最终数据能够达到一致,而不需要实时保证系统数据的强一致性
一致性算法
Paxos
Paxos算法的目的是解决分布式系统下一致性的问题,即一个分布式系统中的各个进程如何就某个值(决议)达成一致。Paxos算法运行在允许宕机故障的异步系统中,不要求可靠的消息传递,可容忍消息丢失、延迟、乱序以及重复。它利用大多数 (Majority) 机制保证了2F+1的容错能力,即2F+1个节点的系统最多允许F个节点同时出现故障。
一个或多个提议进程 (Proposer) 可以发起提案 (Proposal),Paxos算法使所有提案中的某一个提案,在所有进程中达成一致。系统中的多数派同时认可该提案,即达成了一致。最多只针对一个确定的提案达成一致。
Paxos中有一个很重要的概念叫提案(Proposal)。最终要达成一致的Value就在提案里。
Paxos将系统中的角色分为提议者 (Proposer),决策者 (Acceptor),和最终决策学习者 (Learner):
- Proposer: 提出提案 (Proposal)。Proposal信息包括提案编号 (Proposal ID) 和提议的值 (Value)。
- Acceptor:参与决策,回应Proposers的提案。收到Proposal后可以接受提案,若Proposal获得多数Acceptors的接受,则称该Proposal被批准。
Learner:不参与决策,从Proposers/Acceptors学习最新达成一致的提案(Value)。
约束
P1:一个Acceptor必须接受它收到的第一个提案
- P2:如果某个value为v的提案被选定了,那么每个编号更高的被选定提案的value必须也是v
- P2a:如果某个value为v的提案被选定了,那么每个编号更高的被Acceptor接受的提案的value必须也是v
- P2b:如果某个value为v的提案被选定了,那某个之后任何Proposer提出的编号更高的提案的value必须也是v
P2c:对于任意的Mn和Vn,如果提案【Mn,Vn】被提出,那么肯定存在一个由半数以上的Acceptor组成的集合S,满足以下两个条件中的任意一个:
- Proposer选择一个新的提案编号N,然后向某个Acceptor集合(半数以上)发送请求,要求该集合中的每个Acceptor做出如下响应(response)
- a)向Proposer承诺保证不再接受任何编号小于N的提案
- b)如果Acceptor已经接受过提案,那么就向Proposer反馈已经接受过的编号小于N的,但为最大编号的提案的值
- Proposer选择一个新的提案编号N,然后向某个Acceptor集合(半数以上)发送请求,要求该集合中的每个Acceptor做出如下响应(response)
- 如果Proposer收到了半数以上的Acceptor的响应,那么它就可以生成编号为N,Value为V的提案[N,V]。这里的V是所有的响应中编号最大的提案的Value。如果所有的响应中都没有提案,那么此时V就可以由Proposer自己选择。生成提案后,Proposer将该提案发送给半数以上的Acceptor集合,并期望这些Acceptor能接受该提案。我们称该请求为Accept请求。
Acceptor接受提案
一个Acceptor可能会收到来自Proposer的两种请求,分别是Prepare请求和Accept请求,对这两类请求做出响应的条件分别如下:
- Prepare请求:Acceptor可以在任何时候响应一个Prepare请求
- Accept请求:在不违背Acceptor现有承诺的前提下,可以任意响应Accept请求
Learner选定Value
- 方案一:Acceptor接受了一个提案,就将该提案发送给所有的Learner
- 优点:Learner能快速获取被选定的value
- 缺点:通信的次数为(M*N)
- 方案二:Acceptor接受了一个提案,就将该提案发送给主Learner,主Learner再通知其他Learner
- 优点:通信的次数减少(M+N-1)
- 缺点:单点问题(主Leader可能出现故障)
- 方案三:Acceptor接受了一个提案,就将该提案发送给一个Learner集合,Learner集合再通知其他Learner
- 优点:集合中Learner个数越多,可靠性越好
- 缺点:网络通信复杂度越高
Raft
Raft是一种共识算法,旨在替代Paxos。 它通过逻辑分离比Paxos更容易理解,但它也被正式证明是安全的,并提供了一些额外的功能。Raft提供了一种在计算系统集群中分布状态机的通用方法,确保集群中的每个节点都同意一系列相同的状态转换。
Raft算法分为两个阶段:
- 1)选举过程:选举中Leader
-
角色
在Raft中,任何时候一个服务器都可以扮演如下角色
Leader(领导者):接受客户端请求,并向Follower同步请求日志,当日志同步到大多数节点上后告诉Follower提交日志
- Candidate(候选者):Leader选举过程中的临时角色。
Follower(跟随者):接受并持久化Leader同步的日志,在Leader告之日志可以提交之后,提交日志。
选举过程
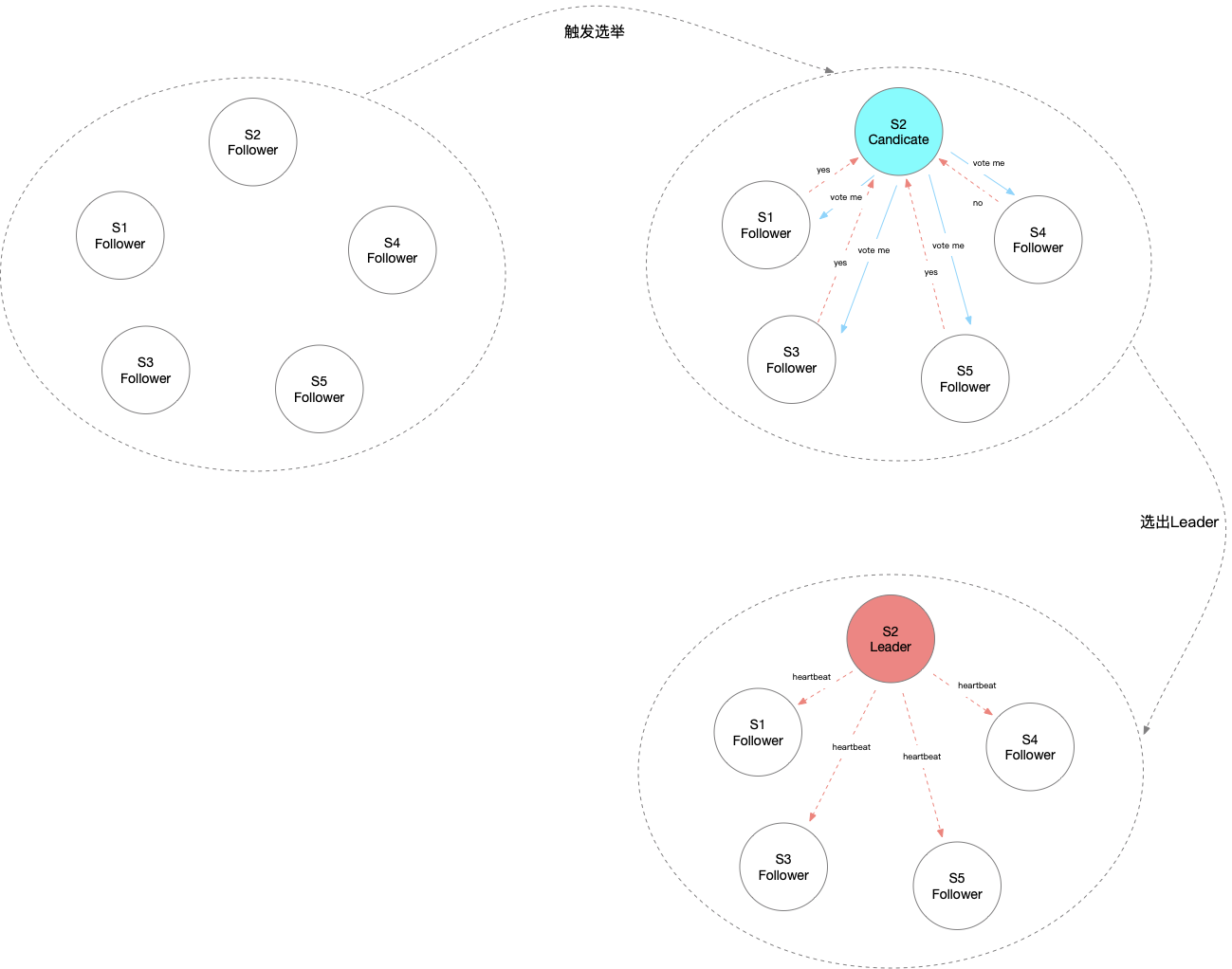
Raft使用心跳机制来触发选举。当Server启动时,初始状态都是follower,每个Server都有一个定时器并设置有超时时间,如果某Server超时时间之外没有收到任何来自Leader或者Candidate的消息,则认为超时,触发选举。日志复制流程
- 客户端的每个请求都包含被复制状态机执行的指令
- Leader把这个指令作为一条新的日志条目添加日志中,然后并行发起RPC给其他服务器,让让他们复制这条消息
- 跟随者响应ACK,如果跟随者宕机或者运行缓慢或则丢包,Leader会不断重试,直到所有的follower最终都复制来所有的日志条目
- 通知所有的follower提交日志,同时领导人提交这条日志到自己的状态机中,并返回给客户端

若有收获,就点个赞吧
0 人点赞
