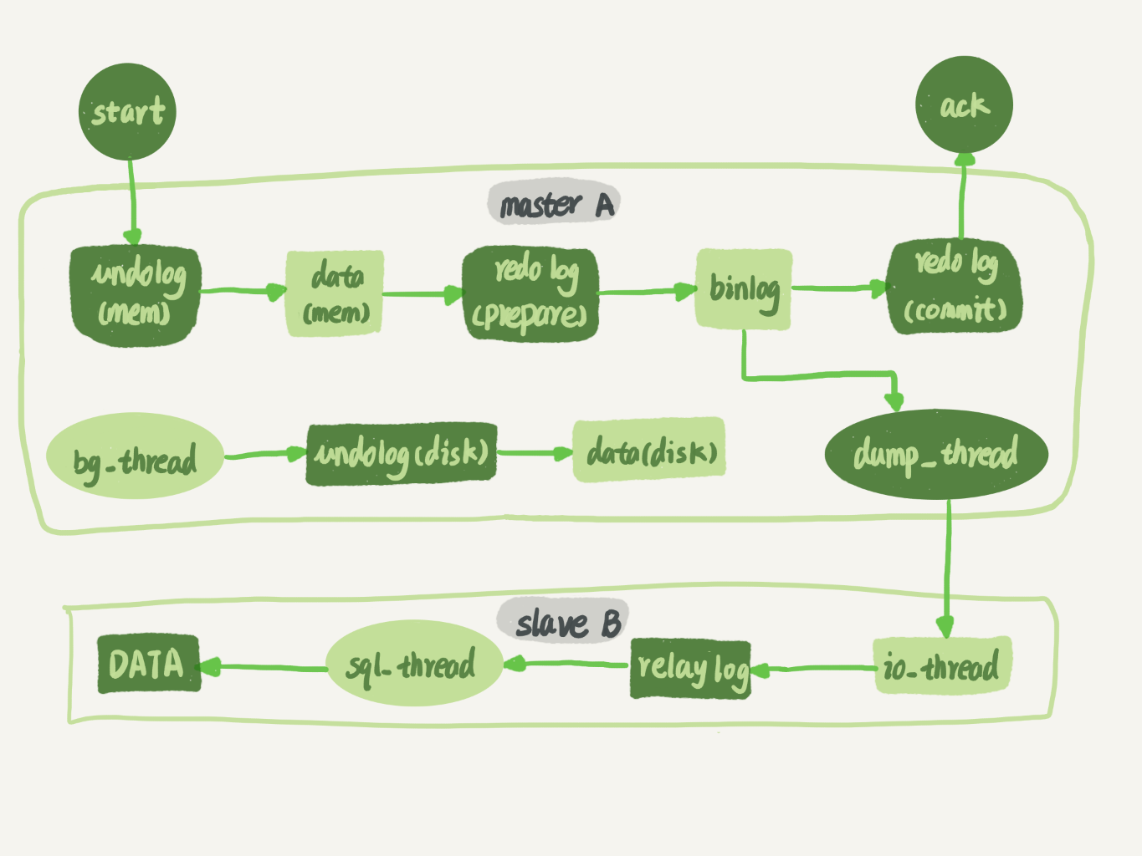
Mysql主备
mysql通过binlog实现主备数据同步。主库接收到客户端请求更新后,执行内部事务的更新逻辑,同时写binlog。备库跟主库之间维持了一个长连接。一个事务日志同步的完成过程如下:
- 在备库上通过change master命令,设置主库的IP、端口、用户名、密码、binlog的文件名和偏移量
- 在备库执行start slave命令,此时本库会启动io_thread个sql_thread两个线程,io_thread负责与主库建立连接
- 主库校验完用户名、密码后,开始按照备库传过来的位置,从本地读取binlog,发送给备库
- 备库B拿到binlog后,写到中转日志(relay log)
- sql_thread读取中转日志,解析出日志里的命令,并执行
GTID
GTID(Global Transaction Identifier),全局事务ID,事务提交时生成,是当前事务的唯一标识。用于主从同步时保证数据的一致性。
GTID工作原理
- master更新数据的时候,会在事务前产生GTID,一同记录到binlog日志中
- slave端的io线程将binlog写入到本地relay log中
- sql线程从relay log中读取GTID,设置gtid_next的值为该gtid,然后对比slave端的binlog是否有记录
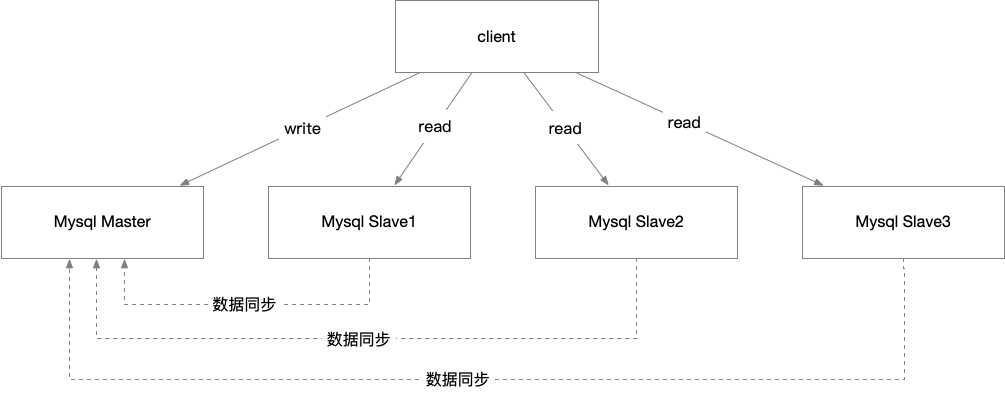
将主库和从库的数据库连接信息放在客户端的连接层,由客户端主动做负载均衡。客户端直连方案,整体架构简单,排查问题方便,但客户端需要了解后端部署细节,当出现主备切换,库迁移等操作时,客户端会感知到并需要调整数据连接信息
中间件读写分离
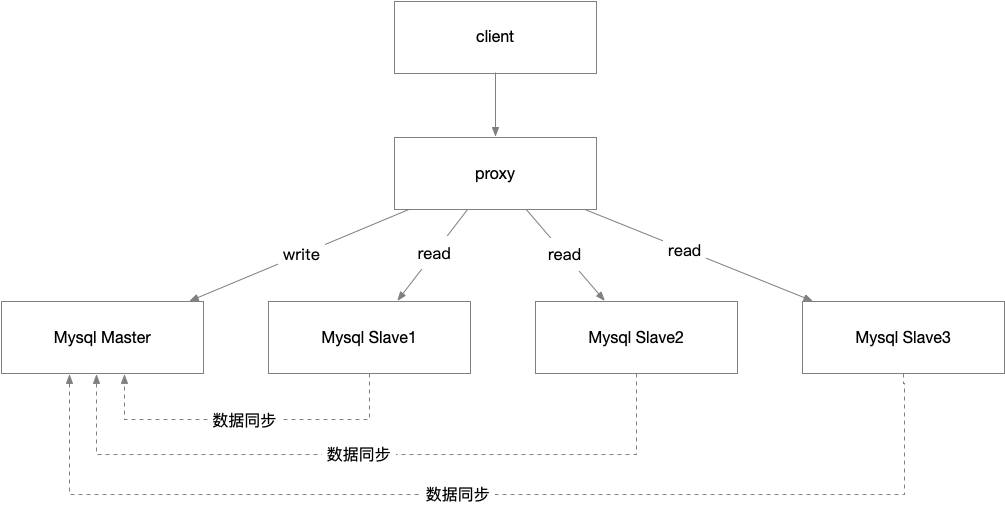
客户端不用关注后端部署细节,性能稍逊与客户端直连,架构相对复杂,proxy层也需要高可用架构
MHA集群
MHA(Master High Availability)是一套比较成熟的MySQL高可用方案,也是一款优秀的故障切换和主从提升的高可用软件。在MySQL故障切换过程中,MHA能做到在30秒之内自动完成数据库的故障切换,并在切换过程中,MHA能在最大程度上保证数据的一致性,以达到高可用的目的。要搭建MHA,要求一个复制集群中必须最少有三台数据库服务器。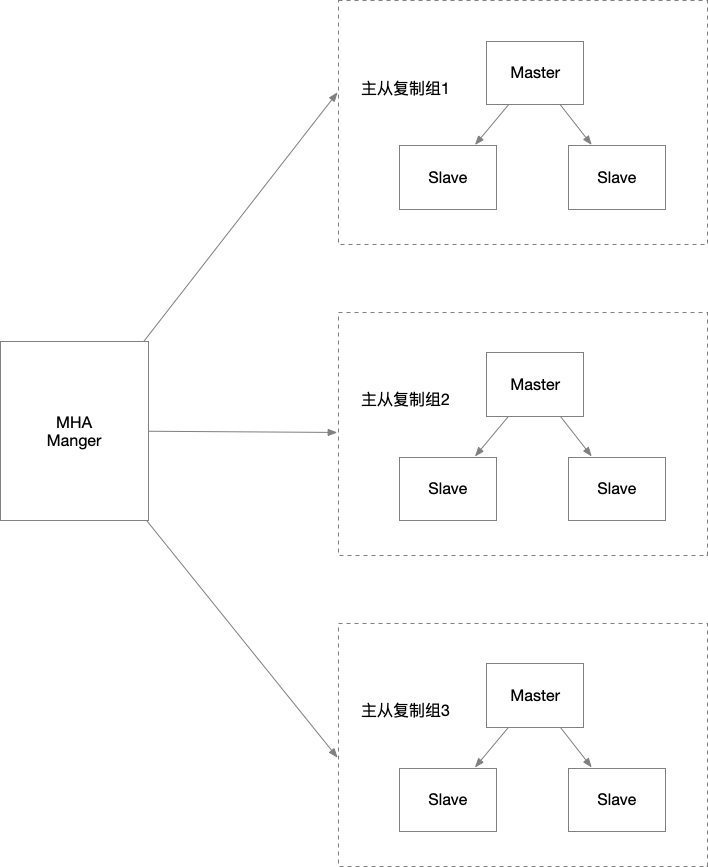
MHA由两部分组成:MHA Manager(管理节点)和MHA Node(数据节点)。MHA Manager可以单独部署在一台独立的机器上管理多个master-slave集群,也可以部署在一台slave节点上。负责检测master是否宕机、控制故障转移、检查Mysql复制状态等。MHA Node运行在每台Mysql服务器上,不管是Master角色,还是Slave角色,都称为Node,是被监控管理的对象节点,负责保存和复制master的二进制日志,识别差异的中继日志事件并将其差异的事件应用于其他的slave。
MHA Manager会定时探测集群中的master节点,当master出现故障时,它可以自动将最新数据的slave提升为新的master,然后将所有其他的slave重新指向新的master,整个故障转移过程对应用程序完全透明。
MHA故障处理机制:
- 把宕机master的binlog保存下来
- 根据binlog位置点找到最新的slave
- 用最新slave的relay log修复其他的slave
- 将保存下来的binlog在最新的slave上恢复
- 将最新的slave提升为master
- 将其他slave重新指向新提升的master,并开启主从复制
MHA优点:
- 自动故障转移快
- 主库崩溃不存在数据一致性问题
- 性能优秀,支持半同步复制和异步复制
- 一个Manager监控节点可以监控多个集群

若有收获,就点个赞吧
0 人点赞
