01|概念和基本架构
Kafka是一个分布式、多分区、多副本、多生产者、多订阅者基于zookeeper协调的分布式消息系统(日志系统),采用发布-订阅的消息传递模式。对于消息中间件,消息分为推拉两种模式,Kafka只有消息的拉取,没有推送,可以通过轮询实现消息的推送。
1.1|Kafka优势
- 高吞度量:单机每秒处理百万消息量,存储TB级消息也能保持稳定的性能
- 高性能:单节点支持上千客户端,并保证零停机和零数据丢失
- 持久化存储:将消息持久化到磁盘,通过将数据持久化到硬盘以及replication防止数据丢失
- 分布式系统,易于向外拓展
- 客户端状态维护:消息被处理的状态是在Consumer端维护,而不是由Server端维护。当失败时能自动平衡
1.2|基本概念
消息
Kafka的数据单元成为消息,消息有键,键决定了消息将去由不同的分区主题和分区
主题(topic)
每条发布到Kafka集群的消息都有一个类别,这个类别称为Topic,物理上不同的Topic的消息是分开存储的。
分区(partition)
topic可以被分为若干个partition,一个partition就是一个提交日志;
消息以追加的方式写入partition,然后以先入先出的顺序读取;
无法在整个topic范围内保证消息的顺序性(partition数目设置为1可保证顺序性,但会降低性能),但可以保证消息在单个partition内的顺序性;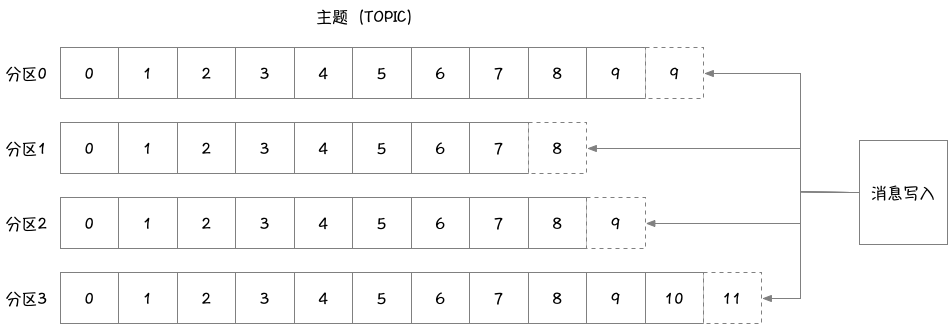
副本(Replicas)
Kafka使用topic来组织数据,每个topic被分为若干个partition,每个partition有多个replicas。replicas保存在broker之上。副本分为leader和follower,生成者和消费者只与leader进行交互,follower不处理来自客户端的请求,它们唯一的任务就是从首领那里复制消息,保持与leader一致的状态。如leader崩溃,则从存活的follower中重新选举一个leader。
分区中的所有副本统称为AR(Assigned Replicas)。
AR = ISR+OSR
ISR:所有与leader副本保持一定程度同步的副本(包括Leader)组成ISR(In-Sync Replicas),消息会先发送到leader副本,然后follower副本才能从leader副本中拉取消息进行同步,同步期间内follower副本相对于leader副本而言会有一定程度(指可以忍受的范围,可以通过参数进行配置)的滞后。
OSR:与leader副本同步滞后过多的副本。在正常情况下所有的follower副本都应该与leader副本保持一定程度的同步,即AR=ISR 而OSR集合为空。
为了解决副本同步滞后性的问题,HW是High Watermark的缩写,俗称高水位,它表示了一个特定消息的偏移量,消费者只能拉取到这个消息之前的消息。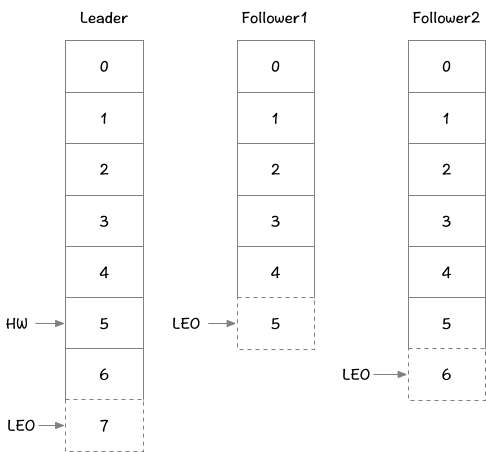
LEO是Log Eed Offset的缩写,它表示了当前日志文件中的下一条待写入消息的offset。
偏移量(Offset)
生产者offset
消息写入时,每个partition都有一个offset,这个offset就是生产者的offset,同时也是这个分区最新最大的offset。
消费者offset
消费者的offset与消费组有关,针对每个组中的消费中会记录不同的offset,消费者从头部开始进行消息的读取,并依次记录消费的位置。
生产者和消费者
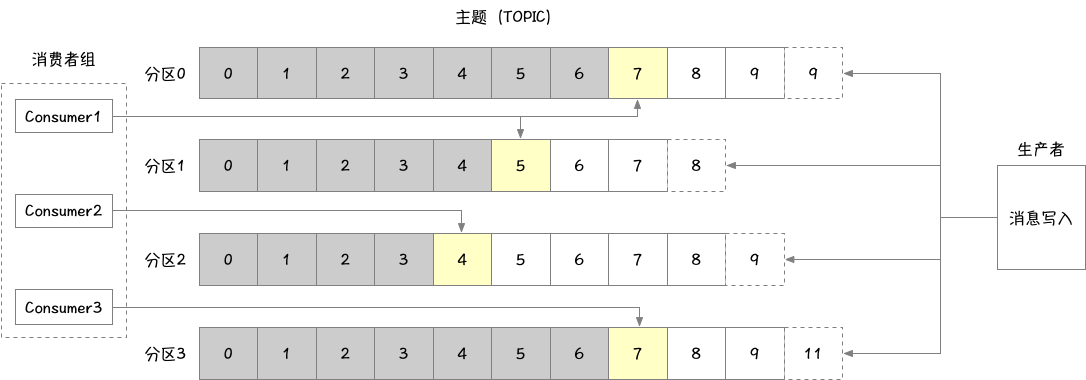
生产者创建消息,消费者消费消息,一个消息被发布到一个指定的主题上时,生产者将通过以下策略将消息发布到对应的分区上:
- 直接指定消息的分区
- 根据消息的key散列取模得出分区
- 轮询指定分区
消费者可以订阅一个或多个主题,并按照消息的生成顺序进行读取,消费者通过检查消息的偏移量来区分已经读取过的消息,偏移量是另一种元数据,它是一个不断递增的整数值,在创建消息时,kafka会把它添加到消息里。在给定的分区中,每个消息的偏移量都是唯一的。消费者把每个分区最后读取的消息偏移量保存在zookeeper或kafka上,如果消费者关闭或重启,它的读取状态不会丢失。消费者是消费组的一部分。组群保证组内每个分区只能被一个消费者使用。如果一个消费者失效,消费组内的其他消费者可以接管失效消费者的工作,再平衡,重新进行分区分配
broker和集群
一个独立的Kafka服务器称为broker。broker接收来自生产者的消息,为消息设置偏移量,并提交消息到磁盘保存。broker为消费者提供服务,为读取分区的请求作出响应,返回已经提交到磁盘上的消息。单个broker可以轻松处理数千个分区以及每秒百万级的消息量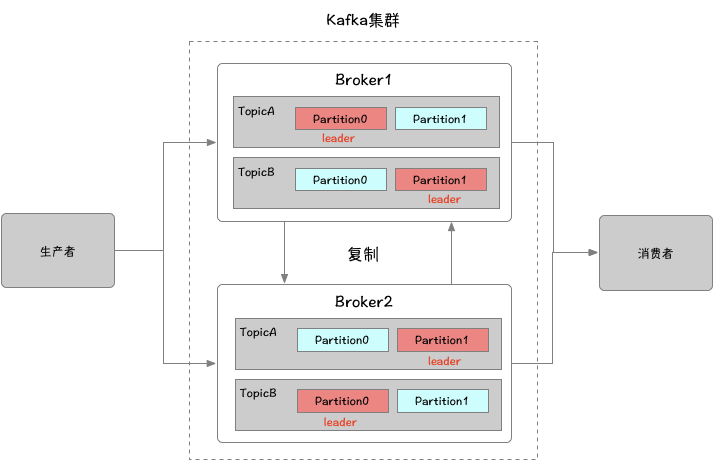
如果某topic的partition数量和broker的数量一致,那么每个broker都存储了一个该topic的partition;如果某topic的partition数量为N,broker的数量为N+M,则其中有N个broker会存储该topic的partition,剩余的M个broker则不存储
1.3|核心API
- Producer API:允许应用程序将数据流发布到一个或多个Kafka主题
- Consumer API:允许应用程序订阅一个或多个主题并处理其生成的数据流
- Streams API:允许应用程序充当流处理器,使用一个或多个主题的输入流,并生成一个或多个输出主题的输出流,从而有效地将输入流装转换为输出流。
- Connector API:允许构建和运行将Kafka主题连接到现有应用程序或数据系统的可重用生成者或使用者。
02|Kafka高级特性
2.1|生产者
消息发送流程分析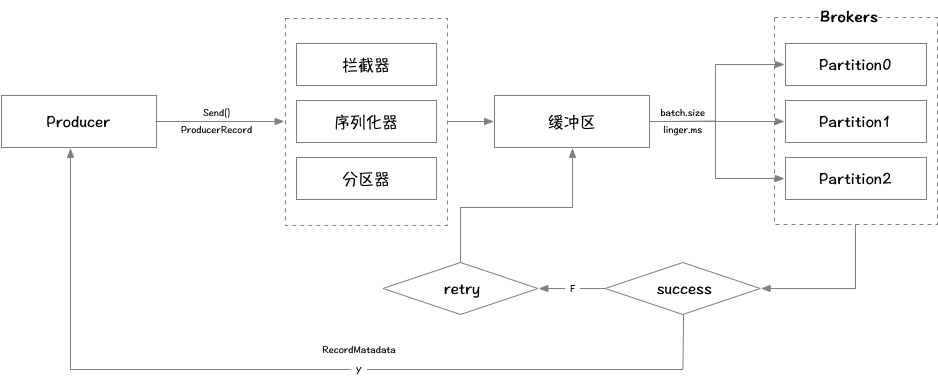
生产消息时,内部其实是异步流程,生产的消息先经过拦截器->序列化器->分区器,然后将消息缓存在缓冲区,当缓冲区数据大小达到batch.size或者linger.ms达到上限,才将缓冲区中的消息批量发送到broker的指定分区,落盘到broker成功之后,返回生产者元数据给生产者。
生产者相关参数配置
| 属性 | 说明 |
|---|---|
| bootstrap.servers | broker地址列表 |
| key.serializer | 指定key的序列化器 |
| value.serializer | 指定value的序列化器 |
| acks | acks=0 :生产者不等待broker的任何消息确认。只要将消息放到了socket的缓冲区,就认为消息已发送。不能保证服务器是否收到该消息, retries 设置也不起作用,因为客户端不关心消息是否发送失败。客户端收到的消息偏移量永远是-1。 acks=1 :leader将记录写到它本地日志,就响应客户端确认消息,而不等待follower副本的确认。如果leader确认了消息就宕机,则可能会丢失消息,因为follower副本可能还没来得及同步该消息。 acks=all :leader等待所有同步的副本确认该消息。保证了只要有一个同步副本存在,消息就不会丢失。这是最强的可用性保证。等价于acks=-1。acks默认值为1 |
| compression.type | 生产者生成数据的压缩格式。默认是none(没有压缩)。允许的值: none , gzip , snappy 和lz4 。 |
| retries | 重试次数 |
2.2|消费者
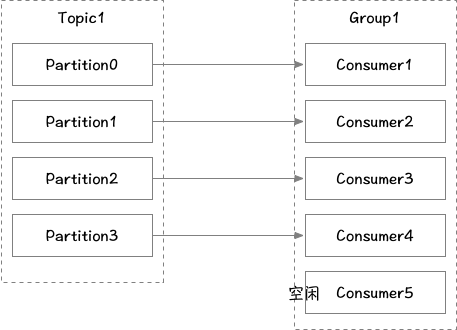
消费者从订阅的主题消费消息,多个从同一主题消费的消费者可以加入到一个消费组中,组中的消费者共享group_id。消费组能均衡地给消费者分配分区,每个分区在消费组中同时只能有一个消费者进行消费。当消费者数量大于分区数时则会有消费者空转空闲。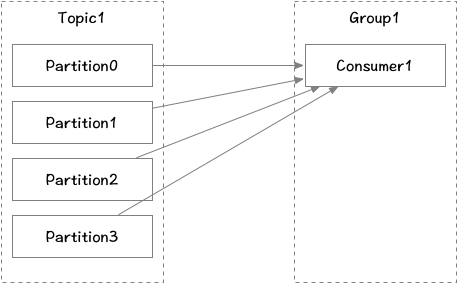
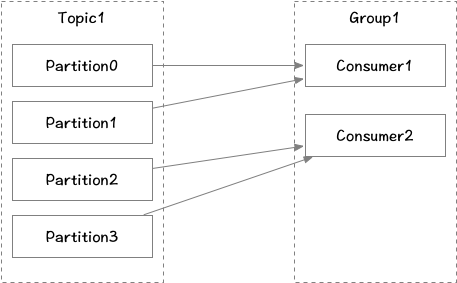
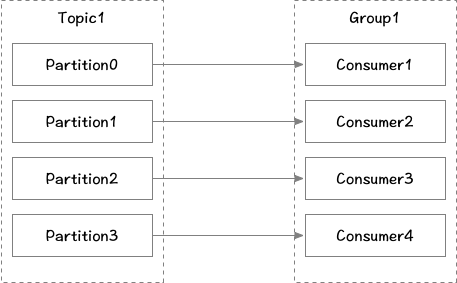
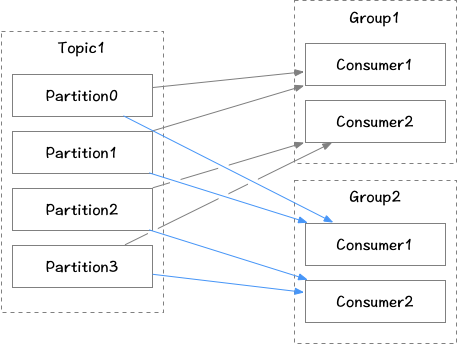
不同的消费组之间消费消息offset互不影响,都可以正常消费主题下的所有消息
Consumer和Broker之间通过心跳机制来进行检测,当某个消费者下线时,Broker会触发rebalance机制,重新给消费组中的消费者分配分区。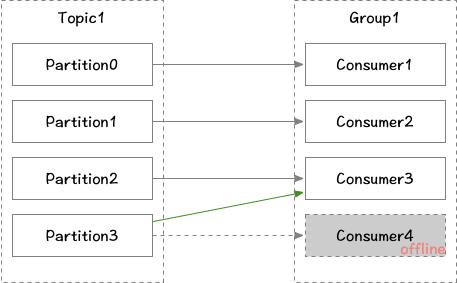
提交(Commit)与位移(offset)
Consumer在消费消息时需要向Kafka回报自己的offset数据,需要为分配给它的每个分区提交各自的位移数据。当Consumer调用poll()拉取消息时,该方法会返回没有被消费的消息,当消息从Broker返回消费者时,broker并不跟踪这些消息是否被消费者接收到,Kafka让消费者自身来管理消费的位移,并向消费者提供更新位移的接口,这种更新位移的方式称为提交(commit)。位移提交分为自动提交和手动提交,手动提交又分为同步提交和异步提交。
- 自动提交
应用本身不需要显示操作,需将enable.auto.commit设置为true,那么消费者会在poll方法调用后每隔一定时间(由auto.commit.interval.ms指定)提交一次位移。在该模式下,如果在提交之前发生的rebalance,则次期间的这部分消息将会被重复消费。
- 手动同步提交
为了减少消息重复消费,可选择手动同步提交,需设置enable.auto.commit为false,应用通过调用commitSync()来主动提交位移,该方法会提交poll返回的最后位移,此种方式至多会导致当前poll的消息会被重复消费。但此种方式会阻塞当前线程,直到返回提交响应,如提交失败会进行重试直到成功或者最后抛出异常。
- 手动异步提交
该方式下,提交不会阻塞当前线程,但该种方式如提交失败,不会进行重试,同样可能导致消息的重复消费,可通过异步回调的方式来进行提交确认。
rebalance再均衡
rebalance是一个协议,它规定了如何让消费者组下的所有消费者来分配topic中的每一个分区。rebalance的触发条件主要有以下三个:
- 消费者组内成员发生变更,这个变更包括了增加和减少消费者,消费者宕机或者退出消费组
- 主题的分区数发生变更,kafka目前只支持增加分区,当分区数增加时会触发rebalance
- 订阅的topic发生变化,当消费者组使用正则表达式订阅主题,而恰好又新建了对应的主题

若有收获,就点个赞吧
0 人点赞
