1. Redis 是什么?
Redis 是一个数据库,不过与传统 RDBM 不同,Redis 属于 NoSQL,也就是非关系型数据库,它的存储结构是 Key-Value。Redis 的数据直接存在内存中,读写速度非常快,因此 Redis 被广泛应用于缓存方向。
1.1 为什么要使用缓存?
在我们实际的业务场景中,一定有很多需要做数据缓存的场景,比如售卖商品的页面,包括了许多并发访问量很大的数据,它们可以称作是是“热点”数据,这些数据有一个特点,就是更新频率低,读取频率高,这些数据应该尽量被缓存,从而减少请求打到数据库上的机会,减轻数据库的压力。
1.2 哪类数据适合缓存?
缓存量大但又不常变化的数据,比如详情,评论等。对于那些经常变化的数据,其实并不适合缓存,一方面会增加系统的复杂性(缓存的更新,缓存脏数据),另一方面也给系统带来一定的不稳定性(缓存系统的维护)。
但一些极端情况下,你需要将一些会变动的数据进行缓存,比如想要页面显示准实时的库存数,或者其他一些特殊业务场景。这时候你需要保证缓存不能(一直)有脏数据,这就需要再深入讨论一下。
1.3 缓存的利与弊
我们到底该不该使用缓存的,这其实也是个trade-off(权衡)的问题。
使用缓存的优点:
- 能够缩短服务的响应时间,给用户带来更好的体验。
- 能够增大系统的吞吐量,依然能够提升用户体验。
- 减轻数据库的压力,防止高峰期数据库被压垮,导致整个线上服务BOOM!
使用了缓存,也会引入很多额外的问题:
- 缓存有多种选型,是内存缓存,memcached还是redis,你是否都熟悉,如果不熟悉,无疑增加了维护的难度(本来是个纯洁的数据库系统)。
- 缓存系统也要考虑分布式,比如redis的分布式缓存还会有很多坑,无疑增加了系统的复杂性。
在特殊场景下,如果对缓存的准确性有非常高的要求,就必须考虑缓存和数据库的一致性问题。
2. 本地缓存
缓存的进程和应用进程是同一个,数据的读写都在一个进程内完成,这种方式的优点是没有网络开销,访问速度很快。在单应用不需要集群支持或者集群情况下,且各节点无需互相通知的场景下使用本地缓存较合适。同时,它的缺点也是因为缓存跟应用程序耦合,多个应用程序无法直接共享缓存,而且受 JVM 内存的限制,不适合存放大数据。
2.1 Guava
Guava是Google团队开源的一款 Java 核心增强库,包含集合、并发原语、缓存、IO、反射等工具箱,性能和稳定性上都有保障,应用十分广泛。Guava Cache支持很多特性:
支持最大容量限制
- 支持两种过期删除策略(插入时间和访问时间)
- 支持简单的统计功能
- 基于LRU算法实现
2.2 Caffeine
Caffeine 是基于 Java8 实现的新一代缓存工具,缓存性能接近理论最优。可以看作是 Guava Cache 的增强版,功能上两者类似,不同的是 Caffeine 采用了一种结合 LRU、LFU 优点的算法:W-TinyLFU,在性能上有明显的优越性。
相比 Guava 来说,Caffeine 无论从功能上和性能上都有明显优势。同时两者的 API 类似,使用 Guava 的代码很容易可以切换到 Caffeine,节省迁移成本。需要注意的是,SpringFramework5.0(SpringBoot2.0)同样放弃了 Guava 的本地缓存方案,转而使用 Caffeine。
2.3 Encache
Encache 是一个纯Java的进程内缓存框架,具有快速、精干等特点,是 Hibernate 中默认的 CacheProvider。同 Caffeine 和 Guava 相比,Encache 的功能更加丰富,扩展性更强:
- 支持多种缓存淘汰算法,包括LRU、LFU和FIFO
- 缓存支持堆内存储、堆外存储、磁盘存储(支持持久化)三种
-
2.4 三种缓存框架对比
从易用性角度,Guava、Caffeine 和 Encache 都有十分成熟的接入方案,使用简单。
- 从功能性角度,Guava 和 Caffeine 功能类似,都是只支持堆内缓存,而 Encache 功能更为丰富。
- 从性能上进行比较,Caffeine 遥遥领先、Guava 次之,Encache 最差(下图是三者的性能对比结果)。
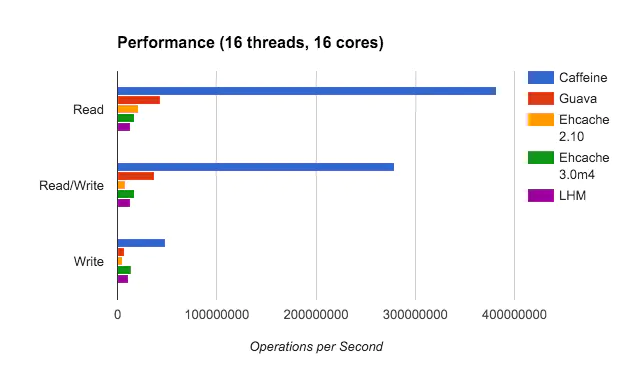
2.5 如何设计一个本地缓存?
3. 分布式缓存
分布式缓存的应用进程和缓存进程通常分布在不同的服务器上,不同进程之间通过 RPC 或 HTTP 的方式通信,多个应用可直接共享缓存。
- 优点:是缓存和应用服务解耦,支持大数据量的存储。
-
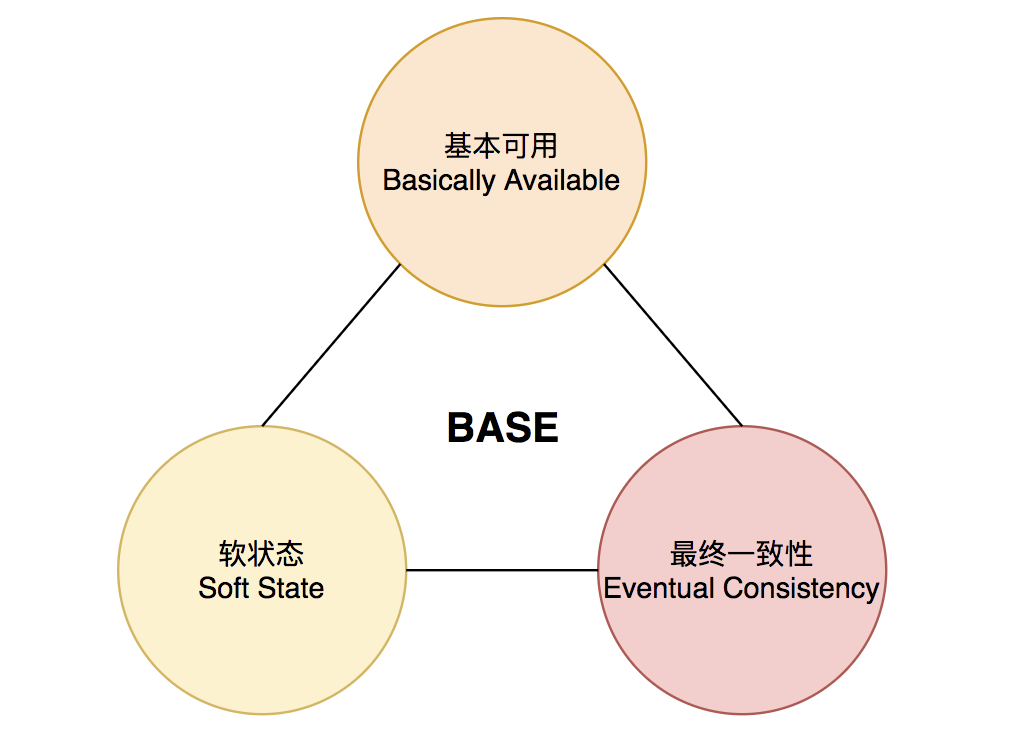
4. BASE 理论是什么?
可以说 BASE 理论是 CAP 中一致性的妥协。和传统事务的 ACID 截然不同,BASE 不追求强一致性,而是允许数据在一段时间内是不一致的,但最终达到一致状态,从而获得更高的可用性和性能。
5. Redis 过期策略
Redis 使用 定期删除 + 懒惰删除 删除过期的 Key。
定期删除:定期删除的原理是,Redis 会将所有设置了过期时间的 Key 放入一个字典中,然后每隔一段时间从字典中随机一些 Key 检查过期时间并删除已过期的 Key。Redis 默认每秒进行 10 次过期扫描:
- 从过期字典中选取 20 个随机 key。
- 删除这 20 个key中已过期的。
- 如果超过 25% 的 key 过期,则重复第一步。
- 懒惰删除:定期删除可能会导致很多过期 Key 到了时间并没有被删除掉。所以就有了懒惰删除。所谓懒惰删除就是在客户端访问该 Key 的时候,Redis 会对 Key 的过期时间进行检查,如果过期了就立即删除。这种方法看似完美,在访问的时候检查 Key 的过期时间,不需要占用太多额外的 CPU 资源。但是如果一个 Key 已经过期了并且长时间没有被访问,那么这个 Key 就会一直停留在内存中造成内存资源的消耗。
还有一种定时删除的方法,不过 Redis 没有采用。定时删除是指在设置键的过期时间的同时,创建一个定时器,让定时器在键过期时执行对键的删除操作。
但是仅仅通过设置过期时间还是有问题的。我们想一下:如果定期删除漏掉了很多过期 key,然后你也没及时去查,也就没走惰性删除,此时会怎么样?如果大量过期 key 堆积在内存里,导致 Redis 内存慢慢耗尽了。怎么解决这个问题呢?答案是使用 Redis 内存淘汰机制。
6. Redis 内存淘汰机制
举个例子:假设 MySQL 里有 2000w 数据,Redis 中只存 20w 的数据,如何保证 Redis 中的数据一定是热点数据?答案是使用 Redis 的内存淘汰机制。Redis 用的是近似 LRU 算法,LRU 算法需要一个双向链表来记录数据的最近被访问顺序,但是出于节省内存的考虑,Redis 的 LRU 算法并非完整的实现。Redis 通过对少量键进行取样,然后和目前维持的淘汰池综合比较,回收其中的最久未被访问的键。通过调整每次回收时的采样数量 maxmemory-samples,可以实现调整算法的精度。
Redis 提供 6种数据淘汰策略:
- volatile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
- volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
- volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
- allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key(这个是最常用的)
- allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰
- no-eviction:禁止驱逐数据,也就是说当内存不足以容纳新写入数据时,新写入操作会报错。这个应该没人使用吧!
4.0版本后增加以下两种:
- volatile-lfu:从已设置过期时间的数据集(server.db[i].expires)中挑选最不经常使用的数据淘汰
allkeys-lfu:当内存不足以容纳新写入数据时,在键空间中,移除最不经常使用的key
1. Redis 一般有哪些使用场景?
1.1 Redis 适合的场景
缓存:减轻 MySQL 的查询压力,提升系统性能。
- 排行榜:利用 Redis 的 SortSet(有序集合)实现。
- 计算器:利用 Redis 中原子性的自增操作,我们可以统计类似用户点赞数、用户访问数等。这类操作如果用 MySQL,频繁的读写会带来相当大的压力。
- 好友关系:利用集合的一些命令,比如求交集、并集、差集等。可以方便解决一些共同好友、共同爱好之类的功能。
- 消息队列:除了 Redis 自身的发布/订阅模式,我们也可以利用 List 来实现一个队列机制,比如:到货通知、邮件发送之类的需求,不需要高可靠,但是会带来非常大的 DB 压力,完全可以用 List 来完成异步解耦。
Session 共享:Session 是保存在服务器的文件中,如果是集群服务,同一个用户过来可能落在不同机器上,这就会导致用户频繁登陆;采用 Redis 保存 Session 后,无论用户落在那台机器上都能够获取到对应的 Session 信息。
1.2 Redis 不适合的场景
数据量太大、数据访问频率非常低的业务都不适合使用 Redis。因为数据太大会增加成本,访问频率太低,保存在内存中纯属浪费。
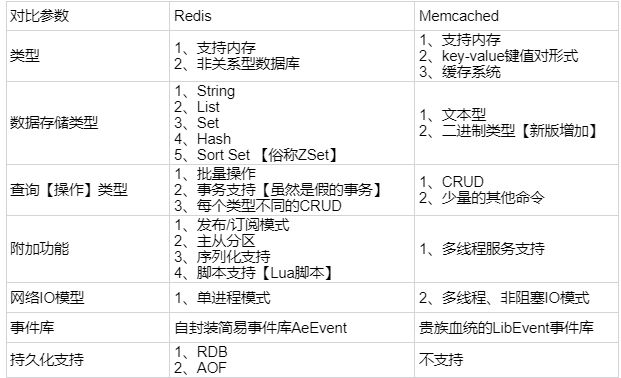
5. Redis 和 Memcache 的区别
Redis 支持更丰富的数据类型(支持更复杂的应用场景):Redis 不仅仅支持简单的 k/v 类型的数据,同时还提供 list,set,zset,hash 等数据结构的存储。Memcache 只支持简单的 k/v 类型数据。
- Redis 支持数据的持久化:Redis 可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用,而 Memecache 把数据全部存在内存之中。
- 集群模式:Redis 天然支持集群功能,可以实现主动复制、读写分离。Redis 官方也提供了 sentinel 集群管理工具,能够实现主从服务监控,故障自动转移,这一切对于客户端都是透明的,无需程序改动,也无需人工介入。而 Memcache 要想要实现高可用,需要进行二次开发,例如客户端的双读双写,或者服务端的集群同步。
- Redis 可以存储的内容更大,Memcache 的 value 存储最大为1M。
- 内存分配机制:Memcache 使用预分配内存池的方式管理内存,能够省去内存分配时间。
Redis 则是临时申请空间,可能导致碎片。
从这一点上看,mc 会更快一些。 - 虚拟内存使用:Memcache 把所有的数据存储在物理内存里。
Redis 有自己的 VM 机制,理论上能够存储比物理内存更多的数据,当数据超量时,会引发 swap,把冷数据刷到磁盘上。
从这一点上看,数据量大时,mc 会更快一些。 - 网络模型:Memcache 和 Redis 都使用非阻塞 IO 复用模型。但由于 Redis 还提供一些非KV存储之外的排序,聚合功能,在执行这些功能时,复杂的 CPU 计算,会阻塞整个 IO 调度。从这一点上看,由于 Redis 提供的功能较多,mc 会更快一些。
- 线程模型:Memcache 使用多线程,主线程监听,worker 子线程接受请求,执行读写,在这个过程中可能存在锁冲突。而 Redis 使用单线程,虽无锁冲突,但难以利用多核的特性提升整体吞吐量。
从这一点上看,mc 会快一些。
参考

若有收获,就点个赞吧
0 人点赞
