1. 为什么 Redis 可以这么快
- 完全基于内存,绝大部分请求是纯粹的内存操作,执行效率高。
- 数据结构简单,对数据操作简单,存储结构是键值对(类似于 HashMap)。
- 采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗 CPU,不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗。
- 使用多路 I/O 复用模型,非阻塞 I/O。
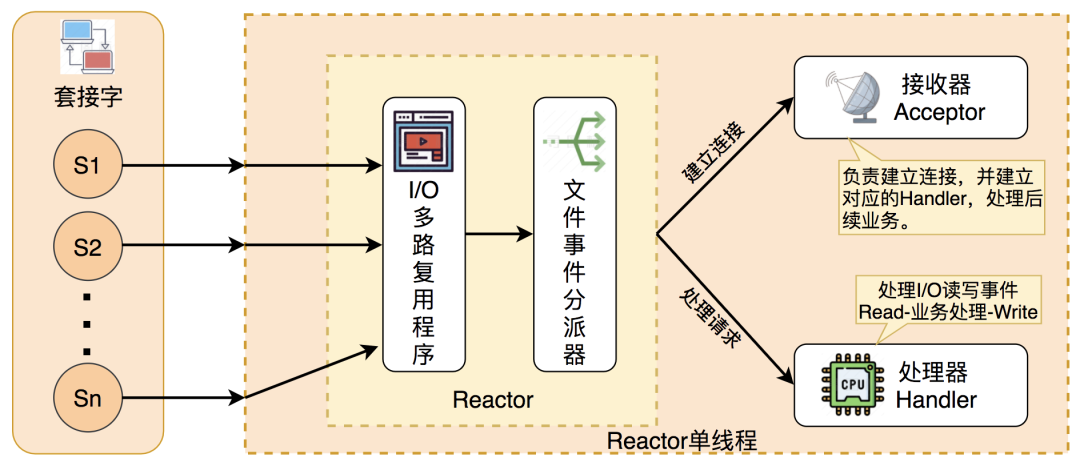
Redis 是单线程 Reactor 模型,通过高效的 IO 复用以及内存处理实现高性能。如果是6.0之前我会毫不犹豫说是单线程,6.0之后,我还是会说单线程,但会补充一句,IO 解包通过多线程进行了优化,而处理逻辑,还是单线程。另外,如果考虑到 RDB 的 Fork,一些定时任务的处理,那么 Redis 也可以说多进程,这没有问题。但是 Redis 对数据的处理,至始至终,都是单线程。
注:Redis 6.0 之后的版本开始选择性地使用多线程模型。这里的多线程功能,主要用于提高解包的效率。和传统的 Multi Reactor 多线程模型不同,Redis 的多线程只负责处理网络 IO 的解包和协议转换,一方面是因为 Redis 的单线程处理足够快,另一方面也是为了兼容性做考虑。因为读写网络的 Read/Write 系统调用在 Redis 执行期间占用了大部分 CPU 时间,把网络读写做成多线程的方式对性能会有很大提升。
Redis 的多线程部分只是用来处理网络数据的读写和协议解析,执行命令仍然是单线程。 之所以这么设计是不想 Redis 因为多线程而变得复杂,需要去控制 key、lua、事务、LPUSH/LPOP 等等的并发问题。
3. 如果数据太大,Redis 存不下怎么办?
可以使用集群模式。也就是将数据分片,不同的 Key 根据 Hash 路由到不同的节点。集群索引是通过一致性 Hash 算法来完成,这种算法可以解决服务器数量发生改变时,所有的服务器缓存在同一时间失效的问题。
同时,基于 Gossip 协议,集群状态变化时,如新节点加入、节点宕机、Slave 提升为新 Master,这些变化都能传播到整个集群的所有节点并达成一致。
关于一致性哈希可参考:
https://www.yuque.com/codershenghai/javalearning/qkz5ik#d8Eol
参考

若有收获,就点个赞吧
0 人点赞
