1. 如何保证消息不丢失?
就我们市面上常见的消息队列而言,只要配置得当,我们的消息就不会丢。先来看看这个图: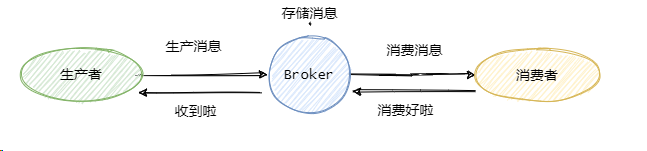
可以看到一共有三个阶段,对应 Kafka 三次消息传递的过程:
- 生产消息(生产者发消息给Kafka Broker)。
- 存储消息(Kafka Broker 消息同步和持久化)。
- 消费消息(Kafka Broker 将消息传递给消费者)。
在这三步中每一步都有可能会丢失消息,下面详细分析为什么会丢消息,如何最大限度避免丢失消息。
1.1 生产消息时丢失
生产者发送消息至 Broker,需要处理 Broker 的响应,不论是同步还是异步发送消息,同步和异步回调都需要做好 try-catch,妥善地处理响应,如果 Broker 返回写入失败等错误消息,需要重试发送。当多次发送失败需要作报警、日志记录等。
1.2 存储消息时丢失
比较常见的一个场景是 Kafka 某个 broker 宕机,然后重新选举 partition 的 leader。如果此时其他的 follower 刚好还有些数据没有同步,而此时 leader 挂了,然后选举某个 follower 成 leader 之后,就会丢失一些数据。
所以存储消息阶段需要在消息刷盘之后再给生产者响应,假设消息写入缓存中就返回响应,那么机器突然断电这消息就没了,而生产者以为已经发送成功了。
如果 Broker 是集群部署,有多副本机制,即消息不仅仅要写入当前 Broker,还需要写入副本机中。那配置成至少写入两台机子后再给生产者响应。这样基本上就能保证存储的可靠了。
一般是要求起码设置如下 4 个参数:
- 给 topic 设置
replication.factor参数:这个值必须大于 1,要求每个 partition 必须有至少 2 个副本。 - 在 Kafka 服务端设置
min.insync.replicas参数:这个值必须大于 1,这个是要求一个 leader 至少感知到有至少一个 follower 还跟自己保持联系,没掉队,这样才能确保 leader 挂了还有一个 follower 吧。 - 在 producer 端设置
acks=all:这个是要求每条数据,必须是写入所有 replica 之后,才能认为是写成功了。 - 在 producer 端设置
retries=MAX(很大很大很大的一个值,无限次重试的意思):这个是要求一旦写入失败,就无限重试,卡在这里了。1.3 消费消息时丢失
唯一可能导致消费者弄丢数据的情况,是你消费到了这个消息,然后消费者那边自动提交了 offset,让 Kafka 以为你已经消费好了这个消息,但其实你才刚准备处理这个消息,你还没处理,你自己就挂了,此时这条消息就丢了。
因为 Kafka 会自动提交 offset,那么只要关闭自动提交offset,在处理完之后自己手动提交 offset,就可以保证数据不会丢。
但需要注意的是,此时还是可能会有重复消费,比如你刚处理完,还没提交 offset,结果自己挂了,此时肯定会重复消费一次,不过此时只要自己保证幂等性就好了。
1.4 小结:保证消息不丢失
可以看出,保证消息的可靠性需要三方配合。
- 生产者需要处理好 Broker 的响应,出错情况下利用重试、报警等手段。
- Broker 需要控制响应的时机,单机情况下是消息刷盘后返回响应。集群多副本情况下,即发送至两个副本及以上的情况下再返回响应。
- 消费者需要在执行完真正的业务逻辑之后再返回响应给 Broker。
但是要注意消息可靠性增强了,性能就下降了,等待消息刷盘、多副本同步后返回都会影响性能。因此还是看业务,例如日志的传输可能丢那么一两条关系不大,因此没必要等消息刷盘再响应。
2. 如何处理消息重复的问题?
2.1 产生重复消息的两种场景
先说结论:无法保证消息不重复。
有两种场景会产生重复消息:
- 一般情况下,为了保证消息不丢失,生产者需要等待 Broker 的响应。但是如果 Broker 已经将消息写入了,而生产者由于网络原因没有收到响应,然后生产者又重新将消息发送了一次,此时消息就重复了。
- 再看消费者消费的时候,假设我们消费者拿到消息消费了,业务逻辑已经走完了,事务提交了,此时需要更新 Consumer offset 的时候这个消费者挂了,然后另一个消费者顶上。此时 Consumer offset 还没更新,于是又拿到刚才那条消息,业务又被执行了一遍,于是消息又被重复处理了。
可以看到正常业务而言消息重复是不可避免的,因此我们只能从另一个角度来解决重复消息的问题。
关键点就是幂等。既然我们不能防止重复消息的产生,那么我们只能在业务上处理重复消息所带来的影响。
2.2 幂等处理重复消息
幂等是数学上的概念,我们就理解为同样的参数多次调用同一个接口和一次调用这个接口产生的结果是一致的。
一般有以下几个套路,不过真正应用到实际中还是得看具体业务细节:
- 比如你拿个数据要写库,你先根据主键查一下,如果这数据都有了,你就别插入了,update 一下好吧。
- 比如你是写 Redis,那没问题了,反正每次都是 set,天然幂等性。
- 比如你不是上面两个场景,那做的稍微复杂一点,你需要让生产者发送每条数据的时候,里面加一个全局唯一的 id,类似订单 id 之类的东西,然后你这里消费到了之后,先根据这个 id 去比如 Redis 里查一下,之前消费过吗?如果没有消费过,你就处理,然后这个 id 写 Redis。如果消费过了,那你就别处理了,保证别重复处理相同的消息即可。
- 比如基于数据库的唯一键来保证重复数据不会重复插入多条。因为有唯一键约束了,重复数据插入只会报错,不会导致数据库中出现脏数据。
3. 如何保证消息的有序性?
有序性分为全局有序和部分有序。3.1 全局有序
如果要保证消息的全局有序,首先只能由一个生产者往 Topic 发送消息,并且一个 Topic 内部只能有一个队列(分区)。消费者也必须是单线程消费这个队列,这样的消息就是全局有序的。
不过一般情况下我们都不需要全局有序,即使是同步 MySQL Binlog 也只需要保证单表消息有序即可。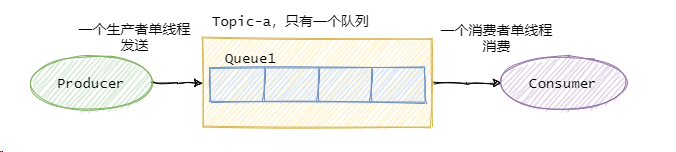
3.2 部分有序
因此绝大部分的有序需求是部分有序,部分有序我们就可以将 Topic 内部划分成我们需要的队列数,把消息通过特定的策略发往固定的队列中,然后每个队列对应一个单线程处理的消费者。这样即完成了部分有序的需求,又可以通过队列数量的并发来提高消息处理效率。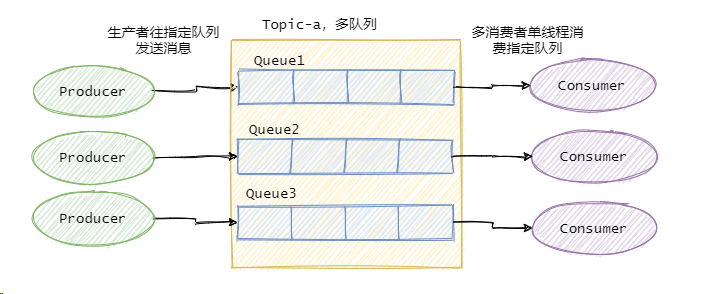
图中有多个生产者,一个生产者也可以,只要同类消息发往指定的队列即可。
4. 如何处理消息堆积?
消息的堆积往往是因为生产者的生产速度与消费者的消费速度不匹配。有可能是因为消息消费失败反复重试造成的,也有可能就是消费者消费能力弱,渐渐地消息就积压了。
因此我们需要先定位消费慢的原因,如果是 bug 则处理 bug ,如果是因为本身消费能力较弱,我们可以优化下消费逻辑,比如之前是一条一条消息消费处理的,这次我们批量处理,比如数据库的插入,一条一条插和批量插效率是不一样的。
假如逻辑我们已经都优化了,但还是慢,那就得考虑水平扩容了,增加 Topic 的队列数和消费者数量,注意队列数一定要增加,不然新增加的消费者是没东西消费的。
参考

若有收获,就点个赞吧
0 人点赞
