1. 熔断&降级&限流&隔离
面对高并发的流量,我们通常会使用四种方式(熔断&降级&限流&隔离)来防止瞬时大流量对系统的冲击。
1.1 什么是熔断?

关键字:断路保护。比如 A 服务调用 B 服务,由于网络问题或 B 服务宕机了或 B 服务的处理时间长,导致请求的时间超长,如果在一定时间内多次出现这种情况,就可以直接将 B 断路了(A 不再请求B)。而调用 B 服务的请求直接返回降级数据,不必等待 B 服务的执行。因此 B 服务的问题,不会级联影响到 A 服务。
1.2 什么是降级?
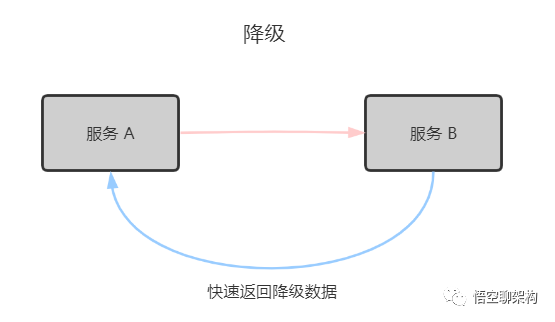
关键字:返回降级数据。网站处于流量高峰期,服务器压力剧增,根据当前业务情况及流量,对一些服务和页面进行有策略的降级(停止服务,所有的调用直接返回降级数据)。以此缓解服务器资源的压力,保证核心业务的正常运行,保持了客户和大部分客户得到正确的响应。降级数据可以简单理解为快速返回了一个 false,前端页面告诉用户『服务器当前正忙,请稍后再试』。
1.3 什么是限流?

对请求的流量进行控制, 只放行部分请求,使服务能够承担不超过自己能力的流量压力。
1.4 什么是隔离?
每个服务看作一个独立运行的系统,即使某一个系统有问题,也不会影响其他服务。
Hystrix 和 Sentinel https://mp.weixin.qq.com/s/7M65kzwFhxzbw50ULQXeaw
2. 什么是负载均衡?
负载均衡其实就是任务的分发,使得任务能按照你的预想分配到各个计算单元上,它能提高服务对外的性能,避免单点失效场景。负载均衡常见的有:软件负载均衡、硬件负载均衡、DNS负载均衡。
2.1 软件负载均衡
软件负载均衡是最常见的,大小公司都需要用到它。 软件负载均衡是通过负载均衡功能的软件来实现负载均衡,常见的软件有 LVS、Nginx、HAProxy。软件负载负载均衡又分四层和七层负载均衡,四层负载均衡就是在网络层利用IP地址端口进行请求的转发,基本上就是起个转发分配作用。而七层负载均衡就是可以根据访问用户的 HTTP 请求头、URL 信息将请求转发到特定的主机。
2.2 硬件负载均衡
硬件负载均衡就是用一个硬件一个基础网络设备,类似我们的交换机啊这样的硬件,来实现负载均衡。常见的硬件有F5、A10。
优点:
- 功能强大,支持全局负载均衡提供全面的复杂均衡算法。
- 性能强悍,支持百万以上的并发。
- 提供安全功能,例如防火墙,防DDos攻击等。
2.3 DNS 负载均衡
这个负载均衡时通过DNS来的,因为DNS解析同一个域名可以返回不同的ip。所以例如哈尔滨的人访问百度就返回距离他近的那个机房的IP,海南的人访问百度就返回距离他近的那个机房的IP。所以主要是用来实现地理级别的负载均衡。
优点:
- 简单,交给DNS服务器处理咱们都不用干活。
- 因为是就近访问可以减少响应的时间,提升访问速度。
缺点:
- DNS有缓存而且缓存时间较长,所以当机房迁移等需要修改DNS配置的时候,用户可能还会访问之前的IP,导致访问失败。
- 扩展能力差,因为运营商管理控制的,由不得我们定制或者扩展。
- 比较笨,不能区分服务器之间的差异,也不能反映服务器的当前运行状态。
DNS负载均衡是地理级别的,硬件负载均衡对应的是集群级别的,软件负载均衡对应的是机器级别的,一般小公司使用软件负载均衡就足够了。
2.4 一致性哈希算法实现负载均衡
2.4.1 一致性哈希算法的具体做法
正是由于普通哈希算法实现的缓存负载均衡存在扩展能力和容错能力差问题,所以我们引入一致性哈希算法。一句话概括一致性哈希:就是普通取模哈希算法的改良版,哈希函数计算方法不变,只不过是通过构建环状的 Hash 空间代替普通的线性 Hash 空间。具体做法如下:
- 首先,选择一个足够大的 Hash 空间(一般是 0 ~ 2^32)构成一个哈希环。
- 然后,对于缓存集群内的每个存储服务器节点计算 Hash 值,可以用服务器的 IP 或 主机名计算得到哈希值,计算得到的哈希值就是服务节点在 Hash 环上的位置。
- 最后,对每个需要存储的数据 key 同样也计算一次哈希值,计算之后的哈希也映射到环上,数据存储的位置是沿顺时针的方向找到的环上的第一个节点。

2.4.2 一致性哈希算法的优点
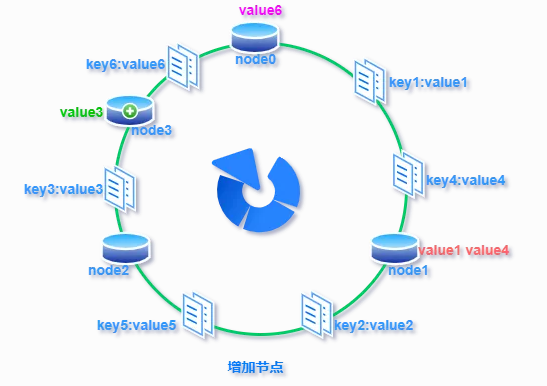
- 扩展能力提升:如下图所示,当缓存服务集群要新增一个节点node3时,受影响的只有 key3 对应的数据 value3,此时只需把 value3 由原来的节点 node0 迁移到新增节点 node3 即可,其余节点存储的数据保持不动。
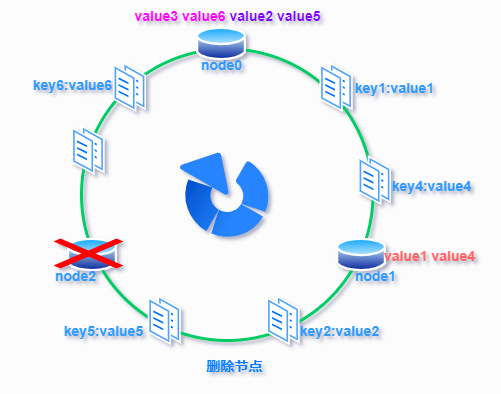
- 容错能力提升:普通哈希算法当某一服务节点宕机下线,也会导致原来哈希映射的大面积失效,失效的映射触发数据迁移影响缓存服务性能,容错能力不足。一起来看下一致性哈希是如何提升容错能力的。如下图所示,假设 node2 节点宕机下线,则原来存储于 node2 的数据 value2 和 value5 ,只需按顺时针方向选择新的存储节点 node0 存放即可,不会对其他节点数据产生影响。一致性哈希能把节点宕机造成的影响控制在顺时针相邻节点之间,避免对整个集群造成影响。
2.4.3 一致性哈希算法的缺点
上面展示了一致性哈希如何解决普通哈希的扩展和容错问题,原理比较简单,在理想情况下可以良好运行,但在实际使用中还有一些实际问题需要考虑,下面具体分析。
数据倾斜:试想一下若缓存集群内的服务节点比较少,就像我们例子中的三个节点,而哈希环的空间又有很大(一般是 0 ~ 2^32),这会导致什么问题呢?可能的一种情况是,较少的服务节点哈希值聚集在一起,比如 node0 、node1、node2 聚集在一起,缓存数据的 key 哈希都映射到 node2 的顺时针方向,数据按顺时针寻找存储节点就导致全都存储到 node0 上去,给单个节点很大的压力!这种情况称为数据倾斜。
节点雪崩:数据倾斜和节点宕机都可能会导致缓存雪崩。拿前面数据倾斜的示例来说,数据倾斜导致所有缓存数据都打到 node0 上面,有可能会导致 node0 不堪重负被压垮了,node0 宕机,数据又都打到 node1 上面把 node1 也打垮了,node1 也被打趴传递给 node2,这时候故障就像像雪崩时滚雪球一样越滚越大。总之,连锁反应导致的整个缓存集群不可用,就称为节点雪崩。
2.4.4 如何解决一致性哈希算法的缺点?
利用虚拟节点优化一致性哈希算法:那该如何解决上述两个棘手的问题呢?可以通过「虚拟节点」的方式解决。所谓虚拟节点,就是对原来单一的物理节点在哈希环上设置几个虚拟节点。打到虚拟节点上的数据实际上也是映射到分身对应的物理节点上,这样一个物理节点可以通过虚拟节点的方式均匀分散在哈希环的各个部分,解决了数据倾斜问题。由于虚拟节点分散在哈希环各个部分,当某个节点宕机下线,他所存储的数据会被均匀分配给其他各个节点,避免对单一节点突发压力导致的节点雪崩问题。

若有收获,就点个赞吧
0 人点赞
