1. 项目回顾
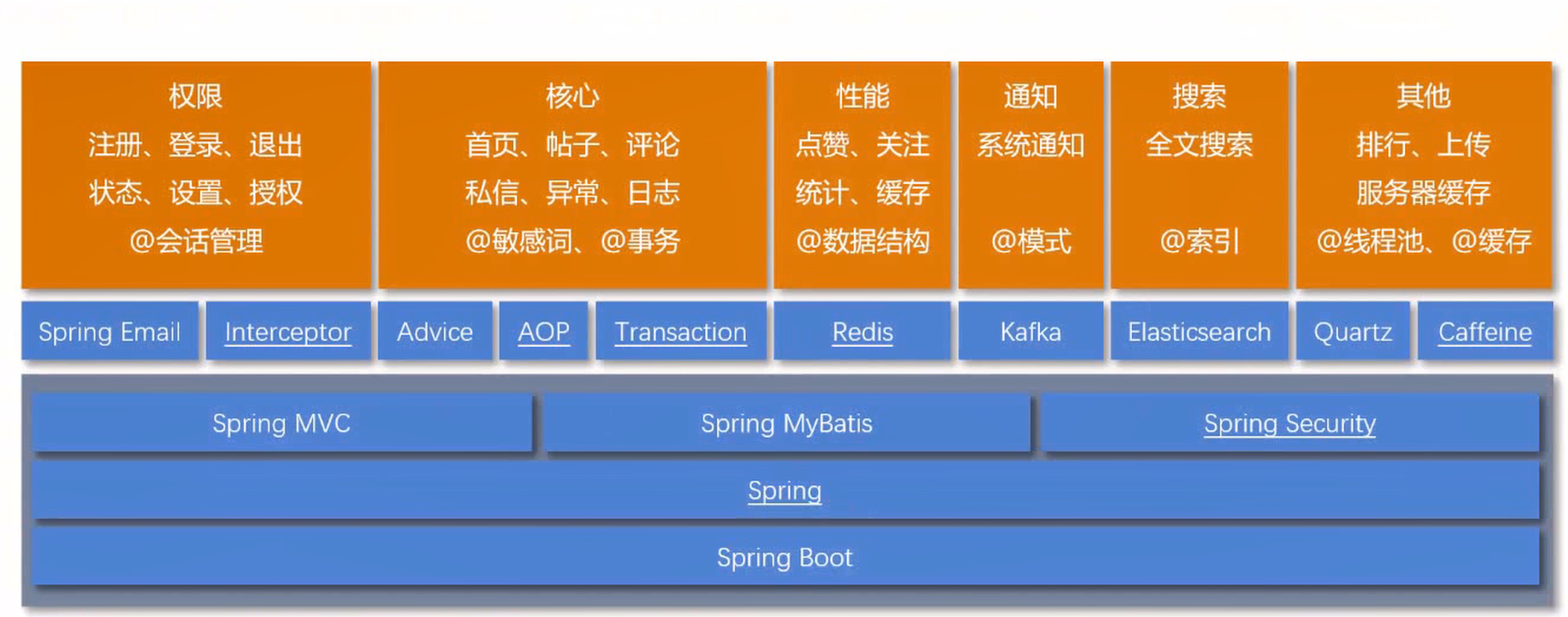
- Spring MVC 解决了前后端请求和交互的问题,Spring MyBatis 访问数据库,Spring Security 用于管理系统安全层面的内容,这三个项目构建在 Spring 之上,由 Spring 进行整合。
- 需要长期连续的交互,就必须要有会话管理,复习的时候看看 Cookie、Session 各自能发挥什么样的作用,区别是什么。后期用 Redis 取代了 session,是因为考虑到了分布式部署的问题。
- 使用 Advice 控制器通知统一处理了异常,使用 Spring AOP 实现了记录业务层日志的功能,使用 Trie 树实现了敏感词的过滤,使用 Spring 对事务进行管理。
- 使用 Redis 实现点赞、关注,以及统计网站的UV、DAU,同时部分模块用 Redis 做了缓存。需要关注 Redis 的数据结构。
- 使用 Kafka 实现了系统通知,Kafka 框架使用比较简单,要明白后面的原理,如生产者消费者模式。
- 使用 Elasticsearch 实现了搜索功能,Elasticsearch 的使用也比较简单。在复习的时候要关注它的数据结构,Elasticsearch 在存数据的时候是以索引来存的,重点要关注索引的结构。
- 使用 Caffeine 做本地缓存,进一步提高了网站的性能,由于是本地缓存,因此在分布式部署时有一定的局限性,所以需要 Redis 配合。
2. 整个项目在真实的环境下到底是怎么部署的
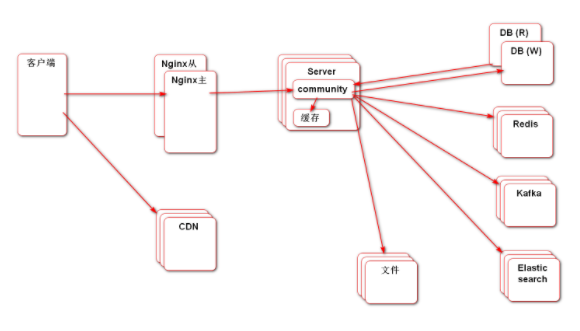
数据库服务器一般两台即可,用于读写分离。如果数据库也用多台服务器部署,那么就需要处理分布式事务,这是非常麻烦的,在实现了二级缓存的情况下,访问数据库的几率已经大大减少,因此两台数据库一般就够用了。3. 项目的难点痛点是什么?你们怎么解决的?
- 难点: 敏感词的过滤
- 为什么要使用 Trie 树? 过滤敏感词可以直接使用API替换字符串,但是这样效率很低,因此采用前缀树(Trie树)过滤敏感词。Trie 树的查找效率高,但是消耗内存大,应用于字符串检索、词频统计、字符串排序等。
- Trie 树的数据结构? Trie 树可以使用 HashMap 实现,因为一个节点的子节点个数未知,而 HashMap 可以动态扩展,而且可以在 O(1) 的时间复杂度内判断某个子节点是否存在。首先定义 Trie 树的节点,节点的结构为 HashMap,key 为字符串中的字符,value 为这个节点的子节点。在实现敏感词过滤前,首先需要初始化 Trie 树,将所有敏感词插入到 Trie 树中。
- 具体怎么初始化 Trie 树的呢? 将每个词语的每个字符一个个地添加到 Trie 树中,树中的每个节点代表一个字。
- 怎么实现敏感词过滤呢? 将待过滤文本与 Trie 树中的节点一个个地进行比较。使用三个指针,其中一个指针指向 Trie 树,另外两个指针指向待过滤文本的起始位置和结束位置。首先 p1 指针指向 root,指针 p2 和 p3 指向字符串中的第一个字符。算法从字符 a 开始,检测有没有以 a 作为前缀的敏感词,在这里就直接判断 root 中有没有 a 这个子节点即可。没有的话将 p2 和 p3 同时右移,而如果存在以 a 作为前缀的敏感词,那么就只右移 p3 继续判断 p2 和 p3 之间的这个字符串是否是敏感词。如果在字符串中找到敏感词,那么可以用其他字符串如 * 代替。接下来不断循环直到整个字符串遍历完成就可以了。
- https://www.jianshu.com/p/9919244dd7ad
4. 介绍一下 Caffeine
Caffeine 是目前很优秀的一种本地缓存,本地缓存是直接从本地内存中读取,相比于 Redis 这种分布式缓存,本地缓存是直接从内存中读取,没有网络开销。在数据量小的场景下,本地缓存比远程缓存更合适。
Caffeine 是基于 JAVA 8 的高性能缓存库。并且在 spring5 (springboot 2.x) 后,spring 官方放弃了 Guava,而使用了性能更优秀的 Caffeine 作为默认缓存组件。(使用 CAS 来保证线程安全)
5. 项目中遇到过什么印象比较深的Bug?
Elasticsearch 和 Redis 底层用的都是 netty 的服务,会冲突,需要手动配置。
6. 你是根据哪些指标进行针对性优化的?
qps(query per second),使用本地缓存 Caffeine 进行优化。
7. 如果让你对这个项目再进行优化, 可以优化哪一部分?
可以讲讲二级缓存,及将热门帖子列表的一级缓存是 Caffeine,二级缓存是分布式的 Redis,最后才是数据库。

若有收获,就点个赞吧
0 人点赞
