回收算法概述
目前垃圾回收算法主要有两类:
- 引用计数法。比如
Python。 - 可达性分析法(根引用分析法)。将根集合作为起始点,从这些节点开始向下搜索,搜索所走过的路径称为引用链。
垃圾回收算法实现:
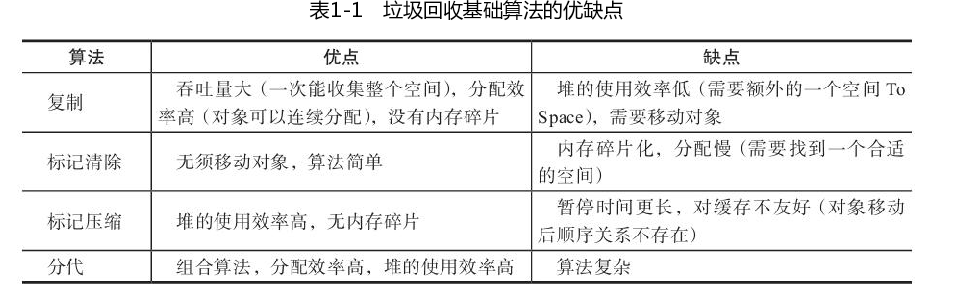
- 复制
- 标记清除(Mark-Sweep)
- 标记压缩(Mark-Compact)
回收方法:
- 串行回收
- 并行回收
- 并发回收
内存管理
- 分代管理:把内存划分成不同的区域进行管理。有些对象存活时间短,有些对象存活时间长。将不同存活时间的对象放在不同区分别管理,这些区可以使用不同的回收算法,从而提升垃圾回收效率。比如内存可分为新生代和老年代,新生代采用复制算法。而老年代采用标记清除算法。
- 非代管理
复制算法
复制算法也分为多种,可以使用两个分区,也可以使用三个分区。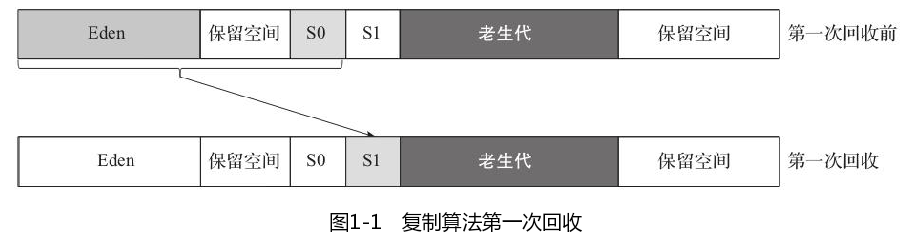
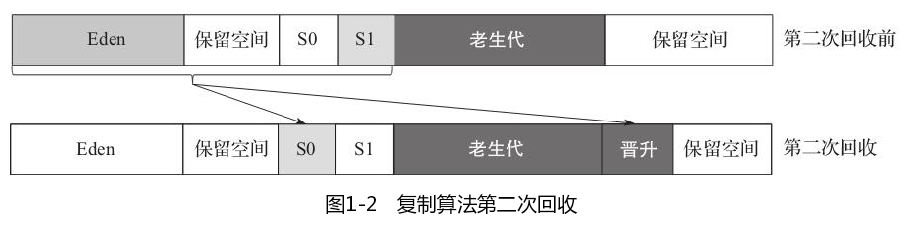
Eden是对象创建的地方,S0和S1是垃圾回收后的目的地。标记清除
从根集合出发,遍历对象,把活跃对象入栈。处理方式可以使用广度优先搜索,也可以使用深度优先搜索(一般使用这种方式以便节约内存)。
标记清除最大的缺点就是使内存碎片化。标记压缩
标记压缩算法是为了解决标记清除算法中使内存碎片化的问题。
JVM 垃圾回收器概述
为了达到最大性能,基于分代管理和回收算法,结合回收的时机,JVM实现垃圾回收器了:
- 串行回收
- 并行回收
- 并发标记回收(CMS)
- 垃圾优先回收(G1)
| 垃圾回收器 | 优点 | 缺点 |
| —- | —- | —- |
| 串行回收 | 单线程方式,编程简单 | STW,无法得用多核优势 |
| 并行回收 | 多线程方式,利用多核优势 | STW, |
| 并发标记回收 |
1. 初始标记(STW,快)
1. 并发标记
1. 重新标记(STW,慢,耗时大)
1. 并发清除
| 通常用于老年代,新生代可采用并行回收 | | G1 回收 |
1. 初始标记(STW)
1. 并发标记
1. 再标记(STW)
1. 并发清除
停顿时间可控,大部分的垃圾收集操作只针对一部分分区,而不是整个堆或整个老年代 | 不适用对停顿时间特别的应用 |
事实上,G1通常的运行状态是:映射G1分区的虚拟内存随着时间的推移在不同的代之间切换。
G1 新第生代:并行收集。采用复制算法。一旦发生一次新第一代回收,整个新第生代都会被回收(Young GC)。
G1 会根据预测时间动态改变新第生代的大小。
从实现角度来看,G1算法是复合算法,吸收了以下算法的优势:
- 列车算法,对内存进行分区。
- CMS,对分区进行并发标记。
-
第二章 G1 的基本概念
JVM 的实现中 GC 更为准确的意思是指内存管理器,它有两个职能,第一是内存的分配管理,第二是垃圾回收。这两者是一个事物的两个方面,每一种垃圾回收策略都和内存的分配策略息息相关,脱离内存的分配去谈垃圾回收是没有任何意义的。
本章是给下面章节作铺垫,包含以下内容: G1 实现中所用的一些基础数据堆分区。
- G1 的停顿预测模型。
- 垃圾回收中使用到的对象头。
- 并发标记中涉及的卡表和位图。
- 垃圾回收过程中涉及的线程、栈帧和句柄。
分区
分区(Heap Region,HR)或堆分区,是 G1 堆和操作系统交互的最小管理单位。可大致分为 4 类:
- 自由分区(Free Heap Region,FHR)
- 又可分为 Eden 和 Survivor
- 新第生代分区(Young Heap Region,YHR)
- 大对象分区(Humongous Heap Region,HHR)
- 又可分为大对象头分区和大对象连续分区。
- 老生代分区(Old Heap Region,OHR)
HR 的大小直接影响分配和垃圾回收效率。
- 过大,一个 HR 可存放多个对象,但是回收耗时。
- 过小,一个 HR 可容纳较少对象,虽然回收耗时变小。
为了达到分配效率和回收效率的平衡,HR 有一个上限值和下限值。
- 上限值:
32MB。 - 下限值:
1MB。
默认情况下,整个堆空间分为 2048 个 HR(根据最小堆分区大小计算得出),HR 大小可由以下方式确定:
- 可以通过参数
G1HeapRegionSize来指定大小,这个参数的默认值为 0。 - 启发式推断。即在不指定 HR 大小时,由 G1 启发式地推断 HR 大小。
按照默认值计算,G1 可以管理的最大内存为 2048×32MB=64GB。假设设置 xms=32G,xmx=128G,则每个堆分区的大小为 32M,分区个数动态变化范围从 1024 到 4096 个。G1 中大对象不使用新生代空间,直接进入老年代,那么多大的对象能称为大对象?简单来说是 region_size 的一半。
如果 G1 是启发式推断新生代的大小,那么当新生代变化时该如何实现?简单地说,使用一个分区列表,扩张时如果有空闲的分区列表则可以直接把空闲分区加入到新生代分区列表中,如果没有的话则分配新的分区然后把它加入到新生代分区列表中。G1 有一个线程专门抽样处理预测新生代列表的长度应该多大,并动态调整。
另外还有一个问题,就是分配新的分区时,何时扩展?一次扩展多少内存?G1 是自适应扩展内存空间的。参数 -XX:GCTimeRatio 表示 GC 与应用的耗费时间比,G1 中默认为 9,计算方式为_gc_overhead_perc=100.0×(1.0/(1.0+GCTimeRatio)),即 G1 GC 时间与应用时间占比不超过 10% 时不需要动态扩展,当 GC 时间超过这个阈值的 10%,可以动态扩展。扩展时有一个参数 G1ExpandByPercentOfAvailable(默认值是 20)来控制一次扩展的比例,即每次都至少从未提交的内存中申请 20%,有下限要求(一次申请的内存不能少于 1M,最多是当前已分配的一倍)。
G1 停顿预测模型
G1 是一个响应时间优先的 GC 算法,用户可以设定整个 GC 过程的期望停顿时间,由参数 MaxGCPauseMills控制,默认值:200ms。G1 根据停顿预测模型统计计算历史数据来预测本次收集需要选择的堆分区数量(即选择收集哪些内存空间),从而尽量满足用户设定的目标停顿时间。
G1 的预测逻辑是基于衰减平均值和衰减标准差。
卡表和位图
卡表(CardTable)是 CMS 中最常见的概念之一,G1 中不仅保留,还引入了 RSet。GC 最早引入卡表的目的是为了对内存的引用关系做标记,从而根据引用关系快速遍历活跃对象。
512 字节粒度的卡表。
使用 BitMap 可以描述一个分区对另一个分区的引用情况。
对象头
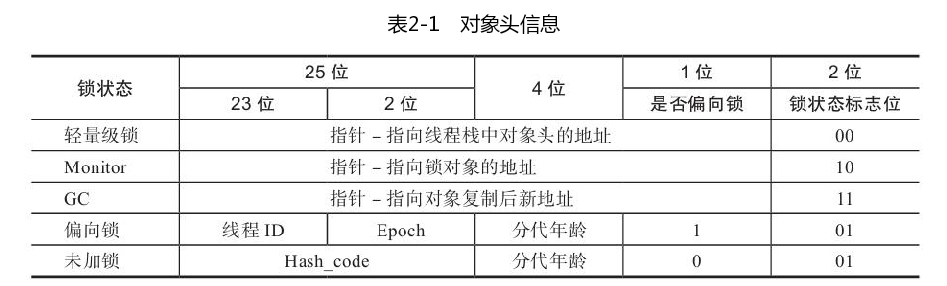
当对象被设置为 marked(11) 时,表示被引用的对象已经被标记且被复制了,当遍历其它引用对象时,发现被引用对象已经完成标记,则不再需要复制对象,直接完成对象引用更新即可。
元数据信息
在垃圾回收时如何区别一个立即数和指针地址? 实际上垃圾回收器不能区别,但是为了准确地回收垃圾,一个简单的办法是先将地址强转成 OOP 结构,再判定这个 OOP 是否含有 KClass 指针,如果有的话即认为是一个指针。如果是 NULL 则认为是一个立即数。但这会有一个误判,所以 JVM 维护了一个全局的 OOpMap,用于标记栈里面的数是立即数还是值。每一个 InstanceKlass 都维护了一个 Map(OopMapBlock)用于标记 Java 类里面的字段到底是 OOP 还是 int 这样的立即数类型。
内存分配和管理
JVM 通过系统调用函数 mmap 进行内存申请,glibc 提供我们常用的内存管理函数(malloc/free/realloc/memcopy),为什么 JVM 不直接用呢? 因为 GC 算法实现了一套自己的管理方式,所以再基于 malloc/free 这类的 API 实现效率肯定不高。mmap 必须以 PAGE_SIZE 为单位进行映射,而内存也只能以页为单位进行映射,若要映射非 PAGE_SIZE 整数倍的地址范围,要先进行内存对齐,强行以 PAGE_SIZE 的倍数大小进行映射。
JVM 中常见的对象类型有以下 6 种:
- ResourceObj:线程有一个资源空间。目的是对 JVM 的其它功能支持,如 CFG、在C1/C2优化时可能需要访问这些运行时信息。
- StackObj:栈对象。声明的对象使用栈管理。对象分配在线程栈中,或者使用自定义的栈窗口进行管理。
- ValueObj:值对象。该对象在堆对象需要进行嵌套时使用。简单地说就是对象分配的位置和宿主对象是一样的。
- AllStatic:静态对象,全局唯一。
- MetaspaceObj:元对象。
- CHeapObj:堆空间对象。由 new/delete/free/malloc 管理。包含内容很多,比如 Java 对象、InstanceOop。
线程
线程是程序执行的基本单元。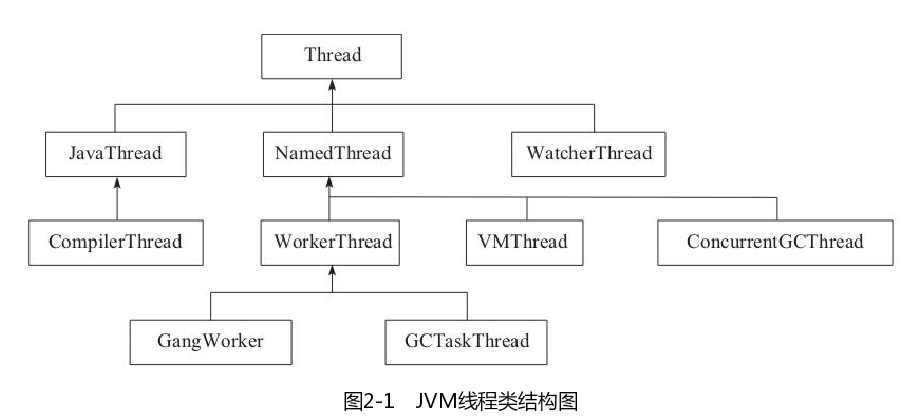
- JavaThread:要执行 java 代码的线程。对一般的 java 线程,都是调用 java.lang.thread 中的 start 方法,这个方法通过 JNI 调用创建 JavaThread 对象,完成真正的线程创建。
- CompilerThread:执行 JIT 的线程。
- WatcherThread:执行周期性任务。JVM 里面有很多周期性任务,例如内存管理中对小对象使用 ChunkPool,而这种需要周期性的清理动作 ChunkPoll Cleaner。JVM 中内存抽样任务 MemProfilerTask 等都是周期性任务。
- NameThread:是 JVM 内存使用的。
- VMThread:JVM 执行 GC 的同步线程,这个是 JVM 最关键的线程之一。主要是用于处理垃圾回收。所以的垃圾回收操作都是从 VMThread 触发的,如果是多线程回收,则启动多个线程,如果是单线程回收,则使用 VMThread 进行。VMThread 提供一个队列,任何要执行 GC 的操作都实现 VM_GC_Operation,然后放入到这个队列中,VMThread 的 run 方法不断轮询这个队列。当这个队列有内容时它就开始尝试进入安全点,然后执行相应的 GC 任务,完成 GC 任务后会退出安全点。
- ConcurrentGCThread:并发执行 GC 任务的线程。比如 G1 中的 ConcurrentMark Thread 和 ConcurrentG1RefineThread 分别处理并发标记和并发 Refine。
- WorkerThread:工作线程,可认为是线程池。线程池里面的线程为了执行任务,也就是做 GC 工作的地方。VMThread 会触发这些任务的调度执行。
从线程的实现角度看,JVM 中的每一个线程都对应一个操作系统线程。JVM 为了提供统一的处理,设计了 JVM 线程状态:
enum ThreadStatus {NEW = 0,RUNNABLE = JVMTI_THREAD_STATE_ALIVE + // runnable / runningJVMTI_THREAD_STATE_RUNNABLE,SLEEPING = JVMTI_THREAD_STATE_ALIVE + // Thread.sleep()JVMTI_THREAD_STATE_WAITING +JVMTI_THREAD_STATE_WAITING_WITH_TIMEOUT +JVMTI_THREAD_STATE_SLEEPING,IN_OBJECT_WAIT = JVMTI_THREAD_STATE_ALIVE + // Object.wait()JVMTI_THREAD_STATE_WAITING +JVMTI_THREAD_STATE_WAITING_INDEFINITELY +JVMTI_THREAD_STATE_IN_OBJECT_WAIT,IN_OBJECT_WAIT_TIMED = JVMTI_THREAD_STATE_ALIVE + // Object.wait(long)JVMTI_THREAD_STATE_WAITING +JVMTI_THREAD_STATE_WAITING_WITH_TIMEOUT +JVMTI_THREAD_STATE_IN_OBJECT_WAIT,PARKED = JVMTI_THREAD_STATE_ALIVE + // LockSupport.park()JVMTI_THREAD_STATE_WAITING +JVMTI_THREAD_STATE_WAITING_INDEFINITELY +JVMTI_THREAD_STATE_PARKED,PARKED_TIMED = JVMTI_THREAD_STATE_ALIVE + // LockSupport.park(long)JVMTI_THREAD_STATE_WAITING +JVMTI_THREAD_STATE_WAITING_WITH_TIMEOUT +JVMTI_THREAD_STATE_PARKED,BLOCKED_ON_MONITOR_ENTER = JVMTI_THREAD_STATE_ALIVE + // (re-)entering a synchronization blockJVMTI_THREAD_STATE_BLOCKED_ON_MONITOR_ENTER,TERMINATED = JVMTI_THREAD_STATE_TERMINATED};
JVM 可以运行在不同的操作系统之上,所以它也统一定义了操作系统线程的状态,
enum ThreadState {ALLOCATED, // Memory has been allocated but not initializedINITIALIZED, // The thread has been initialized but yet startedRUNNABLE, // Has been started and is runnable, but not necessarily runningMONITOR_WAIT, // Waiting on a contended monitor lockCONDVAR_WAIT, // Waiting on a condition variableOBJECT_WAIT, // Waiting on an Object.wait() callBREAKPOINTED, // Suspended at breakpointSLEEPING, // Thread.sleep()ZOMBIE // All done, but not reclaimed yet};
这里定义不同的线程有两个目的:
- 统一管理。
- 根据状态可以做一些同步处理。
当线程创建时,它的状态为 NEW,当执行时转变为 RUNNABLE。在 Linux 上创建线程后,虽然设置成 NEW,但是 Linux 的线程创建完之后就可以执行,所以为了让线程只有在执行 Java 代码的 start 之后开始执行,当线程初始化后,通过等待一个信号将线程暂停。
// Wait until child thread is either initialized or aborted{Monitor* sync_with_child = osthread->startThread_lock();MutexLockerEx ml(sync_with_child, Mutex::_no_safepoint_check_flag);while ((state = osthread->get_state()) == ALLOCATED) {sync_with_child->wait(Mutex::_no_safepoint_check_flag);}}
在调用 start() 方法时,发送通知事件,让线程真正运行起来。
栈帧
JVM 设计了 java 栈帧,这是垃圾回收中的最重要的根。在 JavaThread 中定义了 JavaFrameAnchor,这个结构保存的是最后一个栈帧的 sp、fp。每一个 JavaThread 都有一个 javaFrameAnchor,通过这两个值可以构造栈帧结构,并且栈帧内容,能够遍历整个 JavaThread 运行时的所有调用链。
我们将 Java 的栈帧作为根来遍历堆,对对象进行标记并收集垃圾。
句柄
日志解读
通过 -XX:+Print CommandLineFlags 让 JVM 打印出那些已经被用户或 JVM 设置守的详细的 XX 参数的名称和值。
参数介绍和优化
- 参数
G1HeapRegionSize指定堆大小。分区大小可以指定,也可以不指定。不指定时,由内存管理器启发式推断分区大小。 xms/xmx指定堆空间的最小值/最大值。一定要正确设置 xms/xmx,否则将使用默认配置,将影响分区大小推断。- 在非 G1 的内存管理器中,为了防止新第生代因为内存不断地重新分配导致性能变低,通常设置 Xmn 或者 NewRatio。但是 G1 不要设置 MaxNewSize、NewSize、Xmn 和 NewRatio。原因有两点:
- G1 对内存的管理是不连续的。所以即便重新分配一个堆分区代价不高。
- G1 的目标满足垃圾收集停顿。这需要 G1 根据停顿时间动态调整收集的分区,如果设置了固定的分区数,即 G1 不能调整新生代的大小,那么 G1 可能不能满足停顿时间的要求。
GCTimeRatio指 GC 与应用程序之间的时间占比,默认是 9。表示 GC 与应用程序时间占比为 10%。增大该值将减少 GC 占用时间,带来的后果就是动态扩展内存更容易发生。- 根据业务请求变化的情况,设置合适的扩展
G1ExpandByPercentOfAvailable速率。 - JVM 在对新第生代内存分配管理时,还有一个参数就是保留内存
G1ReservePercent,默认值是 10。即在初始化,或者内存扩展/收缩的时候会计算更新有多少个分区是保留的,在新生代分区初始化时,在空闲列表中保留一定比例的分区不使用,那么在对象晋升的时候就可以使用了,所以能有效地减少晋升失败的概率。这个值最大不超过 50%。保留过多会导致新生代可用空间少,过少可能会增加新生代晋升失败,这将会导致更复杂的串行回收。 G1NewSizePercent是一个实验参数,需要使用-XX:+UnlockExperimentalVMOptions才能改变选项。这个值在大内存时需要减少。比如 32GB 可以设置-XX:G1NewSizePercent=3,这样 Eden 至少保留大约 1GB 的空间,从而保证收集效率。MaxGCPauseMills指期望时间。系统配置和业务动态调整。G1 在垃圾收集时一定会收集新生代,所以需要配合新生代大小的设置来确定。如果该值太小,连新生代都不能收集完成,则没有任何意义,每次除了新生代之外只能多收集一个额外的老年代分区。GCPauseIntervalMillisGC指 GC 间隔时间,默认值为 0。GC 启发式推断为 MaxGCPauseMillis + 1。G1ConfidencePercent指 GC 预测置信度。该值越小说明基于过去历史数据的预测越准确。反之该值越大,说明波动越大,越不准确,需要加上衰减方差来补偿。

若有收获,就点个赞吧
0 人点赞
