这篇文章对拉勾教育课程 Java 并发编程核心 78 讲里面的重要内容做总结归纳。
中断
作者认为,最正确的停止线程的方式是使用中断(interrup)。但有以下局限性:
- Java 的线程中断只会设置中断标志位为 true,仅起到通知线程的作用。并不会直接干预并停止线程。如果线程忽略中断,它仍然会继续执行下去。
所以一般规范编程如下:
public void run() {@Overridepublic void run() {while (!Thread.currentThread().isInterrupted() && ) {}}}
可以看一下 Netty 的EventLoop 对线程中断的响应行为。
sleep 期间能否感受中断
public class TestSleepInterrupt {
public static void main(String[] args) throws Exception{
Thread t1 = new Thread(() -> {
try {
while (true) {
Thread.sleep(1000);
}
} catch (InterruptedException e) {
e.printStackTrace();
}
});
t1.start();
t1.interrupt();
t1.join();
}
}
// OUTPUT
java.lang.InterruptedException: sleep interrupted
at java.lang.Thread.sleep(Native Method)
at concurrent.future.interrupt.TestSleepInterrupt.lambda$main$0(TestSleepInterrupt.java:8)
at java.lang.Thread.run(Thread.java:748)
总结:
- 使用
try/cache或在方法签名中声明throw InterruptedException。这样中断可以层层传递,根据不同业务对中断进行处理。 -
编程注意
当我们使用标志位控制线程的停止时,需要认真考虑阻塞情况下的影响。存在当我们设置标志值后,由于线程处于休眠状态未能及时响应,可能会对业务逻辑产生干扰,导致业务出错。
线程状态
共有 6 种状态
New(新创建)
- Runnable(可运行)
- Blocked(被阻塞)
- Waiting(等待)
- Timed Waiting(计时等待)
- Terminated(被终止)
这在 Thread.State 内部定义。
Runnable
Runnable 包含两种细分状态:Running 和 Ready。
- Running 表示线程正在执行。
- Ready 表示正在等待分配 CPU 资源。
阻塞状态
阻塞状态包含:Timed Waiting、Waiting 和 Blocked。Blocked
Thread state for a thread blocked waiting for a monitor lock. A thread in the blocked state is waiting for a monitor lock to enter a synchronized block/method or reenter a synchronized block/method after calling Object.wait.
线程阻塞等待一个监视器锁(monitor lock)。从 Runnable 状态到 Blocked 状态。
当处于 Blocked 状态的线程抢到 monitor 锁后,就会从 Blocked 状态回到 Runnable 状态。
Blocked 仅仅针对 Synchronized monitor 锁。
Waiting
Thread state for a waiting thread. A thread is in the waiting state due to calling one of the following methods:
Object.waitwith no timeout- T
hread.joinwith no timeoutLockSupport.parkA thread in the waiting state is waiting for another thread to perform a particular action. For example, a thread that has called Object.wait() on an object is waiting for another thread to call Object.notify() or Object.notifyAll() on that object. A thread that has called Thread.join() is waiting for a specified thread to terminate.
从 Runnable 状态进入 Waiting 状态有三种可能:
Object.wait()Thread.join()LockSupport.park()
线程处于等待状态,它等待的是其他线程执行一个特定的行为。比如一个线程执行 Object.wait 使得线程处于等待状态,而另一个线程需要调用 Object.notify() 或 Object.notifyAll() 方法才能重新让线程处于 Running 状态。
Timed Waiting
Thread state for a waiting thread with a specified waiting time. A thread is in the timed waiting state due to calling one of the following methods with a specified positive waiting time:
- Thread.sleep
- Object.wait with timeout
- Thread.join with timeout
- LockSupport.parkNanos
- LockSupport.parkUntil
带有超时时限的等待。前面讲解的 Waiting 可能会一直处于等待,它需要外部条件触发才能被唤醒。而带有超时情况的等待可以设定等待时长,如果等待条件满足或超过等待时长都会使得线程重新回到 Running 状态。
Terminated
Thread state for a terminated thread. The thread has completed execution.
- run() 方法执行完毕,线程正常退出。
出现一个没有捕获的异常,终止 run() 方法执行,最终导致意外终止。
线程状态流转图

当调用Object.notify()或Object.notifyAll()方法后,它不会立即进入 Running 状态,而是直接进入 Blocked 状态。这是因为唤醒 Waiting(包含 Timed Waiting)线程必须首先持有该 monitor 锁。被唤醒的线程此刻还拿不到该锁,就会进入 Blocked 状态,直到执行了Object.notify/Object.nofityAll方法的唤醒线程执行完毕并释放 monitor 锁,才会轮到被唤醒线程去抢夺这把锁。如果能抢到,就会从 Blocked 状态回到 Running 状态。
当然,还是存在部分条件能从 Waiting(包含 Timed Waiting)直接到 Running 状态的。超时时间到
- join 的线程结束
- 线程被中断
- LockSupport.unpark()
状态小结
- 线程状态单向转换。比如线程从 New 状态是不可以直接进入 Blocked 状态的,它需要先经历 Runnable 状态。
线程生命周期不可逆:一旦进入 Runnable 状态就不能回到 New 状态;一旦被终止就不可能再有任何状态的变化。所以一个线程只能有一次 New 和 Terminated 状态,只有处于中间状态才可以相互转换。
wait/nofity/notifyAll
问题:
为什么 wait 方法必须在 synchronized 保护的同步代码中使用?
- 为什么 wait/notify/notifyAll 被定义在 Object 类中,而 sleep 定义在 Thread 类中?
- wait/notify 和 sleep 方法的异同?
为什么 wait 方法必须在 synchronized 保护的同步代码中使用?
首先,正确使用 wait 的姿势如下源码所示: ```java public String take() throws InterruptedException { synchronized(this) {
} }while (buffer.isEmpty()) { wait(); } return buffer.remove();
synchronized (obj) {
while (
使用 `waiit()` 记住:
1. `wait()` 方法会释放 monitor 锁。所以得先获取到锁才能进行释放操作。因此,需要在被 **Synchronized **保护的同步代码块中使用。
1. 使用 `while` 避免虚假唤醒(spurious weakup)。如果我们不在 `while` 中判断的话,可能会导致空指针等异常。
<a name="YW4NR"></a>
## 为什么 wait/notify/notifyAll 被定义在 Object 类中,而 sleep 定义在 Thread 类中?
主要有**两点**原因:
1. 每个对象都有一把 monitor 锁(在对象头中有一个用来保存锁信息的位置),每个对象都可以进行加锁、解释操作。这个锁是对象级别的,而非线程级别的。`wait/notify/notifyAll` 都是对象锁级别的操作,所以把它们定义在 Object 类中是最合适,因为 Object 类是所有对象的父类。
1. 如果把 `wait/notify/notifyAll` 方法定义在 Thread 类中,会带来很大的局限性,比如一个线程可能持有多把锁,以便实现相互配合的复杂逻辑,假设此时 wait 方法定义在 Thread 类中,如何实现让一个线程持有多把锁呢?又如何明确线程等待的是哪把锁呢?既然我们是让当前线程去等待某个对象的锁,自然应该通过操作对象来实现,而不是操作线程。
<a name="kvTPc"></a>
## wait/notify 和 sleep 方法的异同?
相同点:
1. 都可以让线程**阻塞**。
1. 都可以响应**中断**。
不同点:
1. 从**定义**的角度讲:wait/notify 是 Object 类的方法,而 sleep 是 Thread 类的方法。
1. 从**使用**角度讲:wait 方法必须在 **synchronized** 保护的代码中使用,而 sleep 方法并没有这个要求。
1. 从**锁的释放**角度讲:在同步代码中执行 sleep 方法时,并不会释放 monitor 锁,但执行 wait 方法时会主动释放 monitor 锁。
1. 从**超时时间**角度讲:sleep 方法中会要求必须定义一个时间,时间到期后会主动恢复,而对于没有参数的 wait 方法而言,意味着永久等待,直到被中断或被唤醒才能恢复,它并不会主动恢复。
<a name="j3Lfk"></a>
# 使用 wait/notify/Condition/BlockingQueue
阻塞线程唤醒时机:
1. 消费者看到阻塞队列为空时,开始进入等待。一旦生产者往队列中放入数据,就会通知所有的消费者,唤醒阻塞的消费者线程。
1. 生产者发现队列已经满了,也会被阻塞。一旦消费者获取数据之后就会通知所有正在阻塞的生产者进行生产。
<a name="s6FUV"></a>
# 线程安全
一共有3类线程安全问题:
1. 运行结果错误
1. 发布和初始化导致线程安全问题
1. 活跃性问题:
1. 死锁:两个线程之间相互等待对方持有的资源,但同时又互不相让,都想自己先执行。(两个都比较自私)
1. 活锁:两个线程之间互相谦让。
1. 饥饿:始终得不到自己需要的某些资源。尤其是 CPU 资源。就会导致线程一直不运行而产生问题。
哪些场景需要额外注意线程安全问题:
1. 访问共享变量或资源。
1. 依赖时序的操作。像如果存在则运行代码 A,否则运行代码 B。如果整段逻辑不加锁,则会出现问题。
1. 不同数据之间存在绑定关系。
1. 对方没有声明自己是线程安全的。
多线程带来的性能问题
- 调度开销
- 上下文切换。
- 缓存失效。上下文切换可能使得缓存失效。
- 协作开销。因为线程之间共享数据,为了避免数据错乱,因此可能会禁用编译器和 CPU 的重排序优化。也可能出于同步目的,反复把线程工作内存中修改后的数据写回到主内存中,然后再从主内存 refresh 到其他正在使用该变量的工作内存。
<a name="ttz4f"></a>
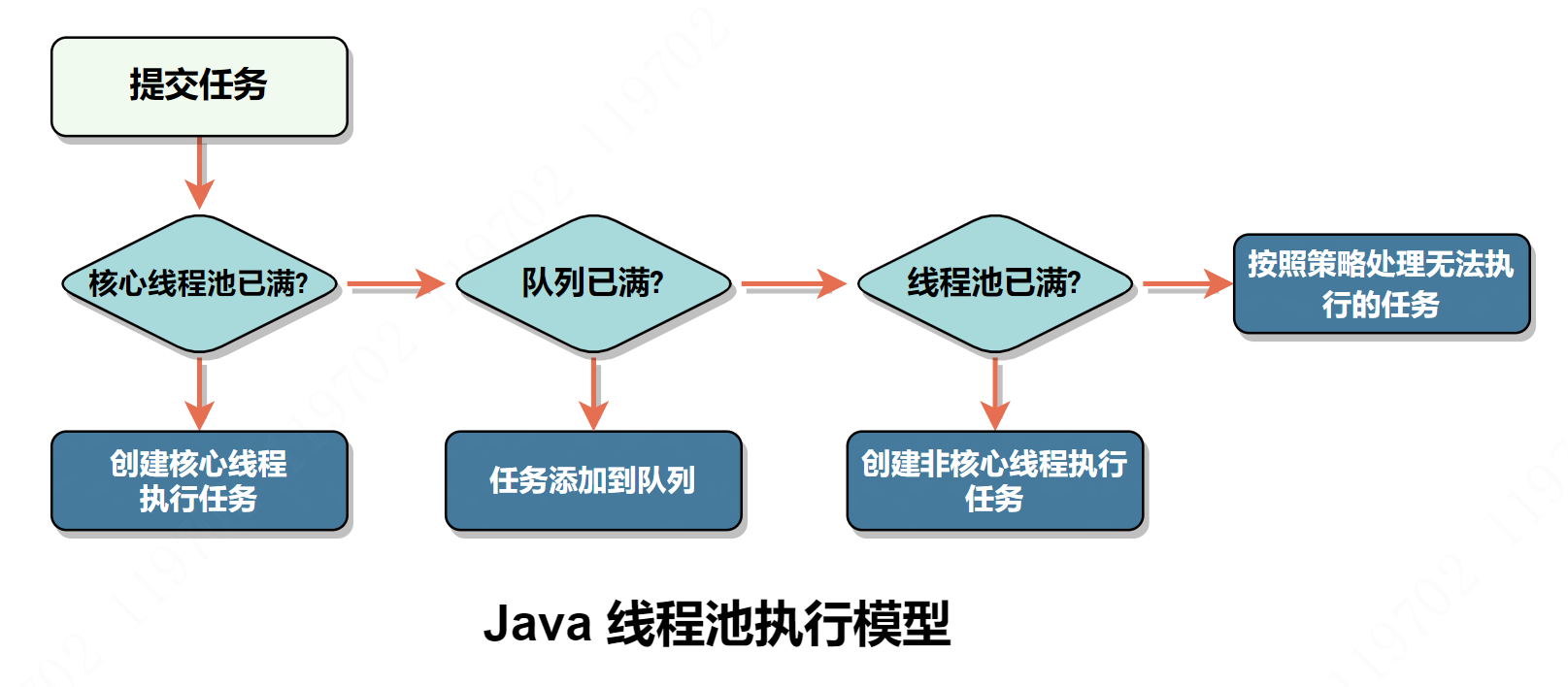
# 线程池
<a name="LHsQf"></a>
## 各种参数含义
| 参数名 | 含义 |
| --- | --- |
| corePoolSize | 核心线程数 |
| maxPoolSize | 最大线程数 |
| keepAliveTime+时间单位 | 空闲线程的存活时间 |
| ThreadFactory | 线程工厂、用来创建新线程 |
| workQueue | 用于存放任务的队列 |
| Handler | 处理被拒绝的任务 |
<a name="I8kun"></a>
## 线程池拒绝策略
```java
newThreadPoolExecutor(5, 10, 5, TimeUnit.SECONDS, new LinkedBlockingQueue<>(),
new ThreadPoolExecutor.DiscardOldestPolicy());
线程池会在以下两种情况下会拒绝新提交的任务。
- 当我们调用 shutdown 等方法关闭线程池后,即便此时可能线程池内部依然有没执行完的任务正在执行,但是由于线程池已经关闭,此时如果再向线程池内提交任务,就会遭到拒绝。
- 线程池没有能力继续处理新提交的任务,也就是工作已经非常饱和的时候。

- DiscardOldestPolicy:如果线程池没被关闭且没有能力执行,则会丢弃任务队列中的头结点,通常是存活时间最长的任务,这种策略与第二种不同之处在于它丢弃的不是最新提交的,而是队列中存活时间最长的,这样就可以腾出空间给新提交的任务,但同理它也存在一定的数据丢失风险。
- DiscardPolicy:当新任务被提交后直接被丢弃掉,也不会给你任何的通知,相对而言存在一定的风险,因为我们提交的时候根本不知道这个任务会被丢弃,可能造成数据丢失。
- AbortPolicy:会直接抛出一个类型为 RejectedExecutionException 的 RuntimeException,让你感知到任务被拒绝了,于是你便可以根据业务逻辑选择重试或者放弃提交等策略。
CallerRunsPolicy:如果线程池没有执行执行,则把这个任务交给提交者线程执行,即谁提交谁执行。有两点好处:
FixedThreadPool
- CachedThreadPool
- ScheduledThreadPool
- SingleThreadExecutor
- SingleThreadScheduledExecutor
- ForkJoinPool
| 线程类型 | 特点 | 缺点 |
| —- | —- | —- |
| FixedThreadPool | ① 核心线程数和最大线程数一样
② 初始阶段线程数从0开始增长 | ① 线程池无法弹性伸缩 | | CachedThreadPool | ① 线程数无限增大
② 队列长度为0
③ 可回收闲置线程 | ① 由于没有限定线程数,会有资源耗尽风险 | | ScheduledThreadPool | ① 定时或周期性执行任务
② 相关 API 分析见下 | | | SingleThreadExecutor | ① 只有一个核心线程,是 FixedThreadPool 的特殊情况
② 非常适用于所有任务都需要按提交顺序依次执行的场景 | ① 只有一个线程,性能容易出现瓶颈 | | SingleThreadScheduledExecutor | ① ScheduledThreadPool 的特例 | | | ForkJoinPool | ① 解析见下 | |
SingleThreadScheduledExecutor
ScheduledExecutorService service = Executors.newScheduledThreadPool(10);
// #1 10S 后执行一次任务
schedule(Runnable command, long delay, TimeUnit unit);
service.schedule(new Task(), 10, TimeUnit.SECONDS);
// #2 第一次任务执行在10S后,后续固定每10S执行一次任务
scheduleAtFixedRate(Runnable command, long initialDelay, long period, TimeUnit unit);
service.scheduleAtFixedRate(new Task(), 10, 10, TimeUnit.SECONDS);
// #3
scheduleWithFixedDelay(Runnable command, long initialDelay, long delay, TimeUnit unit);
service.scheduleWithFixedDelay(new Task(), 10, 10, TimeUnit.SECONDS);
#1指延迟指定时间后执行一次任务。#2指以固定频率执行任务。initialDelay:初始(第一次)延迟时间。period:周期,即第一次延迟后每次延迟多长时间执行一次任务。忽略前序任务延迟,时间到了就会执行。#3与#2类似,也是周期执行任务,区别在于对周期的定义。#2忽略前序任务的延迟,时间到了就会执行新的任务,而#3则会以及前序任务执行完后的时间开始计算接下来执行时间。ForkJoinPool
在 JDK 7 引入,具有以下特点
将任务可以分解成多个子任务。利用 CPU 的多核优势。
- 内部结果不同。之前线程池共用一个队列,但 ForkJoinPool 线程池中的每个线程都有自己独立的任务队列。

ForkJoinPool 线程池可以有多种方法实现任务的分裂和汇总。
双端队列 deque 特点:
- 线程获取任务逻辑是后进先出()Last In First Out,LIFO)
- 线程进行任务窃取(Work-Stealing)对其他线程的 deque 操作是是先进先出(FIFO) 。
ForkJoinPool 非常适合用于递归的场景,例如树的遍历、最优路径搜索等场景。
线程池中常见的阻塞队列
- LinkedBlockingQueue
- SynchronousQueue
- DelayedWorkQueue
线程池与阻塞队列关系
| FixedThreadPool | LinkedBlockingQueue | | | —- | —- | —- | | SingleThreadExecutor | LinkedBlockingQueue | | | CachedThreadPool | SynchronousQueue | 线程数量无限制,所以不需要存储任务的任务队列,因此使用 SynchronousQueue 仅仅是加锁的作用 | | ScheduledThreadPool | DelayedWorkQueue | 可延迟执行任务。DelayedWorkQueue 内部按延迟时间长短对任务进行排序,采用堆数据结构。 | | SingleThreadScheduledExecutor | DelayedWodkQueue | |
如何确定合适的线程数量
目的:充分并合理利用 CPU 和内存资源,从而最大限度地提高程序的性能。我们应根据任务类型的不同选择对应的策略。
任务类型:
- CPU 密集型任务。比如加密、解密、压缩、计算等需要耗费 CPU 资源。最佳的线程数为 CPU 核心数的 1~2倍。设置过多反而适得其返。
- 耗时 IO 型任务。比如查询数据库、文件读写、网络通信等任务。这种任务并不会特别消耗 CPU 资源,但 IO 非常耗时,总体占用比较多的时间。对于这种任务最大线程数一般会大于 CPU 核心数很多倍。如果设置过少的线程数可能会导致 CPU 资源浪费。
《Java并发编程实战》的作者 Brain Goetz 推荐的计算方法:
线程数 = CPU 核心数 *(1+平均等待时间/平均工作时间)
如何定制线程
- 核心线程数
- 阻塞队列
- 线程工厂
-
如何正确关闭线程池
shutdown():可以安全关闭一个线程池。调用此方法之后并不是立刻被关闭,因为内部有正在执行的任务或队列中有大量等待被执行的任务。此方法会在执行完正在执行的任务和队列中等待任务后才彻底关闭。新提交的任务会被拒绝处理器执行。
- isShutdown():true 并不表示线程池已彻底关闭,即线程池可能依然有线程正在执行任务。
- isTerminated():可以检测线程是否真正被终结。同时也表示线程池中的所有任务都已经执行完毕。
- awaitTermination():判断线程池状态。
- 等待期间(包括进入等待状态之前)线程池已关闭并且所有已提交的任务(包括正在执行的和队列中等待的)都执行完毕,相当于线程池已经“终结”了,方法便会返回 true;
- 等待超时时间到后,第一种线程池“终结”的情况始终未发生,方法返回 false;
- 等待期间线程被中断,方法会抛出 InterruptedException 异常。
shutdownNow():首先会给所有线程池中的线程发送中断信号,然后将任务队列中正在等待的所有任务转换到一个 List 中并返回,我们可以通过返回的 List 进行补救操作。
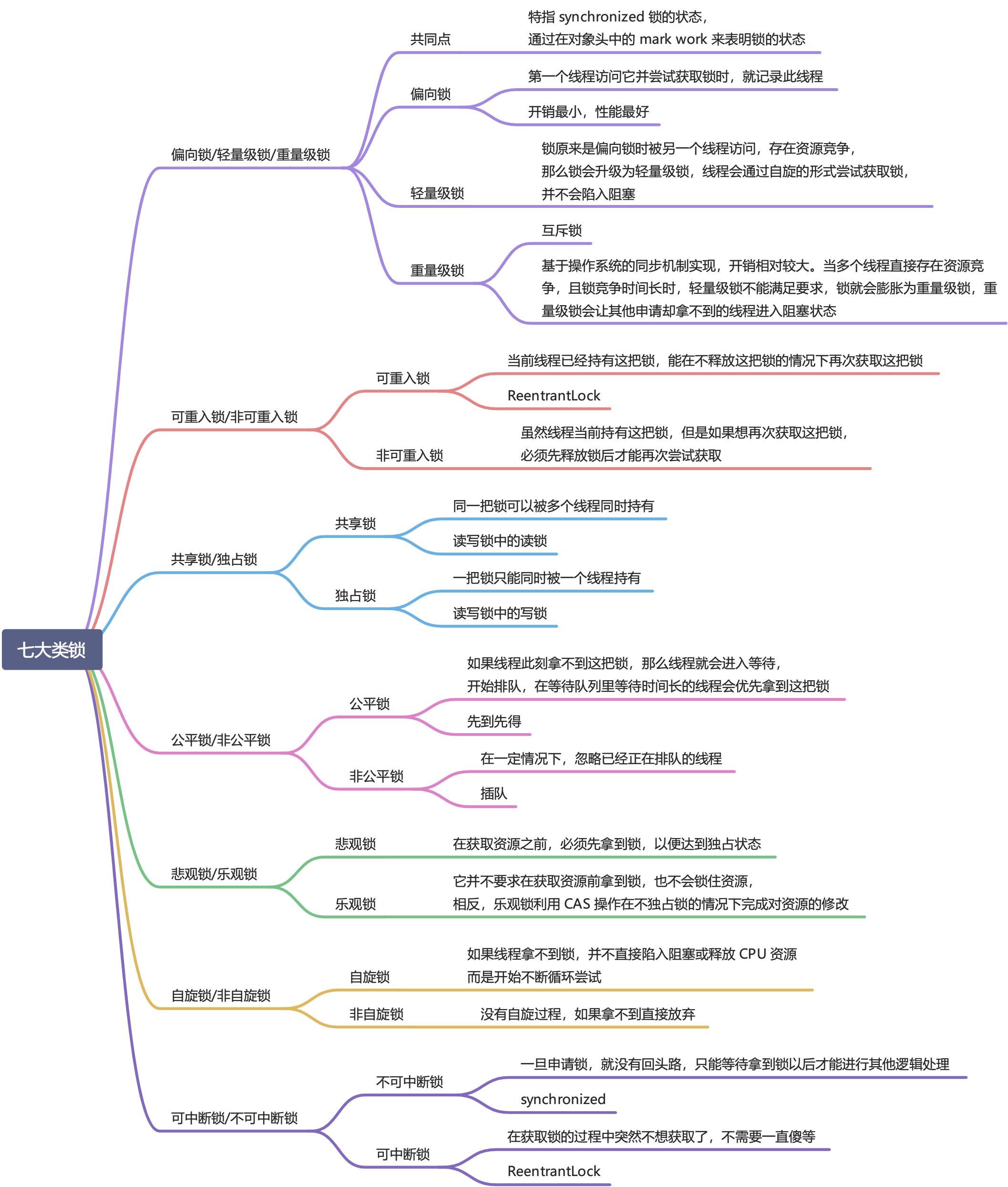
锁的七大种类
偏向锁/轻量级锁/重量级锁
- 可重入锁/非可重入锁
- 共享锁/独占锁
- 公平锁/非公平锁
- 悲观锁/乐观锁
- 自旋锁/非自旋锁
-
悲观锁/乐观锁
分类角度:是从能否锁住资源的角度进行分类。
悲观锁认为这个资源会被多个线程竞争,所以为了保证结果安全,每次对数据修改时都需要上锁。
乐观锁认为这个资源在自己操作时不会有其他线程参数争抢,所以不会锁住被操作的对象。同时在更新之前比较数据是否被其他线程修改过,如果没有修改则说明大概率是自己在操作,那么就可以正常更新自己的数据。如果发现数据不一致,说明其他线程在这段时间内修改过,说明迟了一步,应该放弃修改。可以选择抛出异常或重试。使用 CAS 会引发 ABA 问题。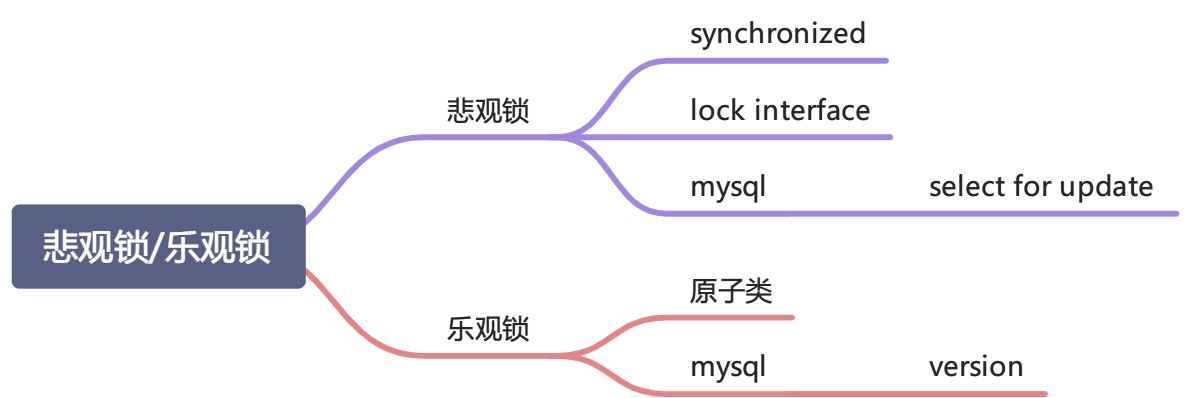
既然悲观锁开销大,那么就应该多使用乐观锁?
这个回答是片面的,需要根据实际情况选择合适的锁。
悲观锁开销固定。乐观锁大部分情况下性能优于悲观锁,但是某些极端情况会导致资源消耗过高。
- 悲观锁适用场景
- 并发写入多、临界区代码复杂、竞争激烈等场景
- 乐观锁适用场景
- 如果该 monitor 的计数为 0,则线程获得该 monitor 并将其计数设置为 1。然后,该线程就是这个 monitor 的所有者。
- 如果线程已经拥有了这个 monitor ,则它将重新进入,并且累加计数(可重入)。
- 如果其他线程已经拥有了这个 monitor,那个这个线程就会被阻塞,直到这个 monitor 的计数变成为 0,代表这个 monitor 已经被释放了,于是当前这个线程就会再次尝试获取这个 monitor。
monitorexit:monitorexit 的作用是将 monitor 的计数器减 1,直到减为 0 为止。代表这个 monitor 已经被释放了,已经没有任何线程拥有它了,也就代表着解锁,所以,其他正在等待这个 monitor 的线程,此时便可以再次尝试获取这个 monitor 的所有权。
同步方法
被 synchronized 关键字标识的同步方法不同在于:这个方法会有一个 ACC_SYNCHRONIZED 的 flag 修改符用来标识它是同步方法。
public synchronized void synMethod();
descriptor: ()V
flags: ACC_PUBLIC, ACC_SYNCHRONIZED
Code:
stack=0, locals=1, args_size=1
0: return
LineNumberTable:
line 16: 0
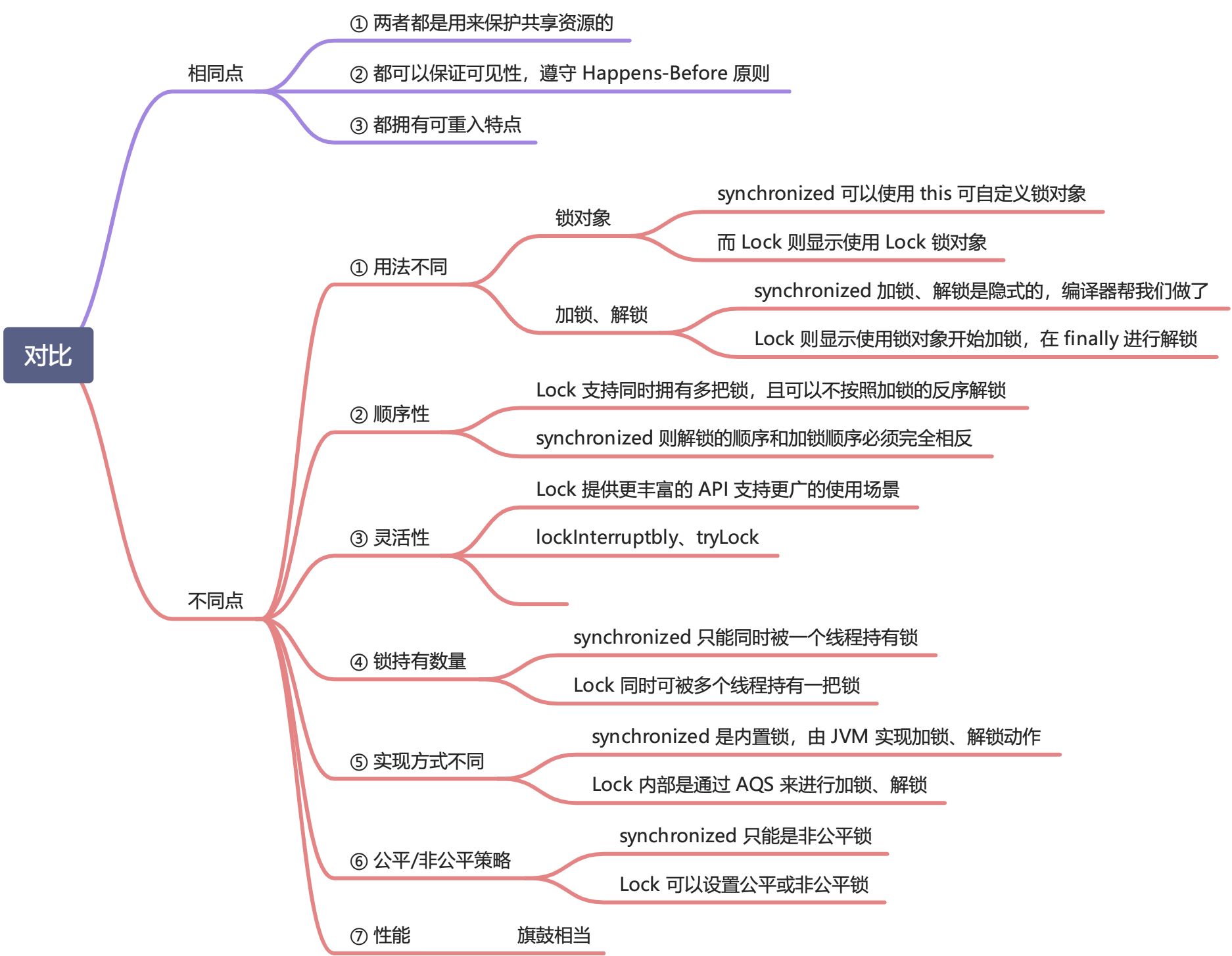
如何选择
- 尽量使用
java.util.concurrent包下的工具类完成你的需求。 - 能有
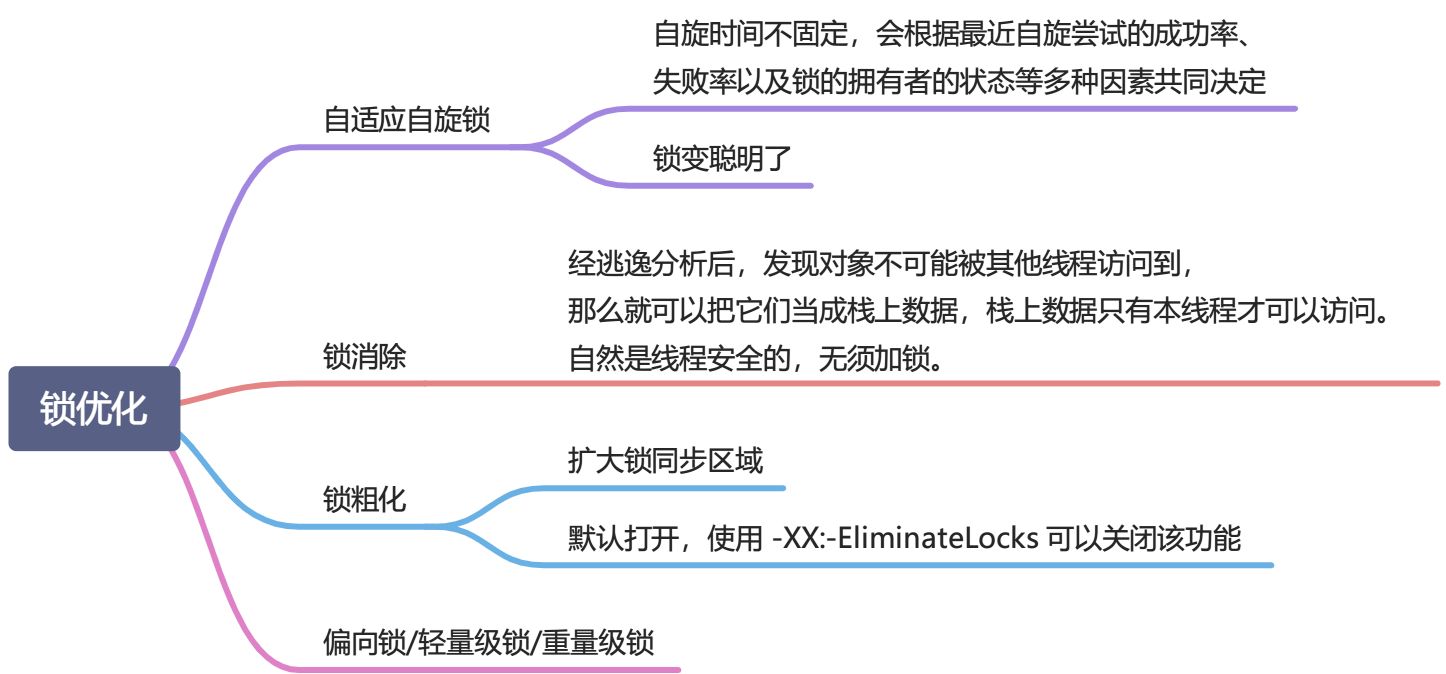
synchronized就用它,优点是对他编写代码的数量,减少出错的概率。而且 JDK6 对synchronized性能进行大量优化,比如自适应自旋、锁消除、锁粗化、锁升级(偏向锁->轻量级锁->重量级锁)。 - 如果特别需要 Lock 的特殊功能,比如尝试获取锁、可中断、超时功能等,才使用 Lock。
Lock

Lock 最常见的实现类是ReentrantLock。
// java.util.concurrent.locks.Lock
/**
* 和 synchronized 相比,Lock接口能提供更广泛、更灵活、更强大的功能。
* ① 可以具有完全不同的属性,可支持多个关联的 Condition 对象。
* ② 锁是一种用于控制共享资源的工具。通常,锁提供对共享资源的独占访问(互斥):一镒
* 只能有一个线程可以获取该锁,对共享资源的所有访问都需要首先获取该锁。但是,某些锁
* 可以允许并发访问共享资源,比如 ReadWriteLock的读锁。
* ③ Lock 接口的实现类允许在不同范围内获取和释放锁,并允许以任意顺序获取和释放锁。
* ④ 通常使用 Lock 接口编程模型:
* Lock l = ...;
* l.lock();
* try {
* // access the resource protected by this lock
* } finally {
* l.unlock();
* }
*/
public interface Lock {
/**
* 获取锁
*
* ① 如果锁被其他线程占用,则线程状态变更为 「waiting」,线程处于休眠状态。
* ② Lock的解锁动作应该包含在finally语句块内,因为抛出异常时JVM不会主动释放锁,需要用户手动实现。
* ③ 由于 lock() 方法是不可被中断的,因此一旦陷入死锁,lock() 就会陷入永久等待。
* 所以一般使用tryLock()等其他高级方法代替lock()
*/
void lock();
/**
* 尝试获取锁,这个操作是可中断的。
* ① 如果锁可用,立即返回。
* ② 如果锁不可用,则
* <1> 线程一直等待(休眠)直到锁可用为止
* <2> 线程被中断
*
* @throws InterruptedException
*/
void lockInterruptibly() throws InterruptedException;
/**
* 尝试获取锁
*
* ① 如果当前锁 可用, 获取锁后并立即返回 true。
* ② 如果当前锁不可用,则立即返回 false。
* ③ 典型用法是
* Lock lock = ...;
* if (lock.tryLock()) {
* try {
* // manipulate protected state
* } finally {
* lock.unlock();
* }
* } else {
* // 执行额外事情,比如过一段时间重试或跳过
* }}
*
*
* @return {@code true} 成功获得锁
* {@code false} 未能获得锁
*/
boolean tryLock();
/**
* 在指定的等待时间范围内成功获得锁并返回true。
*
* ① 和 tryLock() 方法差不多,也能解决死锁问题。
* ② 附带超时时间就不需要轮询多次了,相当于 Thread.sleep(),避免线程永久等待。
* ③ 在等待期间可随时中断线程。
* ④ 此时锁处于不可用状态,线程会休眠直到以下三种情况之一发生:
* <1> 锁被当前线程得到。
* <2> 其他线程中断当前线程。
* <3> 经过指定的等待时间。
* ⑤ {@link InterruptedException} 异常
* <1> 线程的中断标志位被设置
* <2> 在获取锁的过程中线程被中断
* ⑥ 注意事项:
* <1> 并非所有Lock的实现类都能提供中断获取锁的实现,需要仔细阅读文档说明。
* <2> 中断正在尝试获取锁是一个非常昂贵的操作。但更愿意使用中断而非超时。
*
* @param time 获取锁最长等待时间
* @param unit 时间单位
* @return 成功获取锁则返回false,如果在超时则返回false
* @throws InterruptedException 此操作是可中断的
*/
boolean tryLock(long time, TimeUnit unit) throws InterruptedException;
/**
* 释放线程持有的锁
*
* 释放锁应该有严格限制,需要线程持有锁才能释放锁,
* 如果违背规则则指出非受检异常
*/
void unlock();
/**
* 返回一个新的绑定 {@code Lock} 的 {@link Condition} 实例对象
*
* 有以下条件注意:
* <1> 在等待该条件之前,该锁必须由当前线程持有。
* <2> 调用 Condition.await() 会在等待之前自动释放该锁,并在等待返回之前重新获取该锁。
*/
Condition newCondition();
}
公平锁/非公平锁
| 锁的类型 | 优势 | 劣势 |
|---|---|---|
| 公平锁 | 各线程公平竞争,总有机会执行(排队) | 相对非公平锁更慢,吞吐量更小 |
| 不公平锁 | 相对公平锁更快,吞吐量更高 | 存在线程饥饿问题 |
AQS 源码分析公平和非公平锁是如何实现的。主要是 Sync 类。
公平锁
/**
* 公平获取锁
*
*/
protected final boolean tryAcquire(int acquires) {
final Thread current = Thread.currentThread();
// #1 获取共享状态
int c = getState();
if (c == 0) {
if (!hasQueuedPredecessors() && // 判断是否有比当前线程等待更久的准备获取锁的线程
compareAndSetState(0, acquires)) { // 更新原子状态
// 当前线程获取锁
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) { // 线程重入
int nextc = c + acquires;
if (nextc < 0)
throw new Error("Maximum lock count exceeded");
// 更新原子值
setState(nextc);
return true;
}
return false;
}
/**
* 判断是否有比当前线程等待更久的准备获取锁的线程,和下面代码等价
* getFirstQueuedThread() != Thread.currentThread() && hasQueuedThreads()
*
* 实现细节:
* ① 首先获取尾结果,因为尾结点存在则头结点必然存在,如果顺序相反则会导致空指针异常
* ②
*/
public final boolean hasQueuedPredecessors() {
// The correctness of this depends on head being initialized
// before tail and on head.next being accurate if the current
// thread is first in queue.
Node t = tail; // Read fields in reverse initialization order
Node h = head;
Node s;
return h != t &&
((s = h.next) == null || s.thread != Thread.currentThread());
}
非公平锁
// java.util.concurrent.locks.ReentrantLock.Sync#nonfairTryAcquire
/**
* 非公平锁获取锁
* 和公平获取锁区别在于公平锁需要调用 hasQueuedPredecessors() 方法
* 而非公平锁不需要判断,则先尝试获取,尝试失败则去排队
*/
final boolean nonfairTryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {
if (compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0) // overflow
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}
注意:针对
tryLock()方法,它不遵守设定的公平原则。一旦有线程释放了锁,那么这个正在tryLock的线程能获取到锁,即便设置为 公平锁模式。
ReadWriteLock 获取锁规则
- 如果有一个线程已经占用了读锁,则此时其他线程如果要申请读锁,可以申请成功。
- 如果有一个线程已经占用了读锁,则此时其他线程如果要申请写锁,则申请写锁的线程会一直等待释放读锁,因为读写不能同时操作。
- 如果有一个线程已经占用了写锁,则此时其他线程如果申请写锁或者读锁,都必须等待之前的线程释放写锁,同样也因为读写不能同时,并且两个线程不应该同时写。
读读共享,读写互斥。 要么是一个或多个线程同时持有读锁,要么是一个线程有写锁。不会存在既有线程持有读锁,也有线程持有写锁。
public class ReadWriteLockDemo {
private static final ReentrantReadWriteLock reentrantReadWriteLock = new ReentrantReadWriteLock(false);
private static final ReentrantReadWriteLock.ReadLock readLock = reentrantReadWriteLock.readLock();
private static final ReentrantReadWriteLock.WriteLock writeLock = reentrantReadWriteLock.writeLock();
private static void read() {
readLock.lock();
try {
System.out.println(Thread.currentThread().getName() + "得到读锁,正在读取");
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
System.out.println(Thread.currentThread().getName() + "释放读锁");
readLock.unlock();
}
}
private static void write() {
writeLock.lock();
try {
System.out.println(Thread.currentThread().getName() + "得到写锁,正在写入");
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
System.out.println(Thread.currentThread().getName() + "释放写锁");
writeLock.unlock();
}
}
public static void main(String[] args) throws InterruptedException {
new Thread(() -> read()).start();
new Thread(() -> read()).start();
new Thread(() -> write()).start();
new Thread(() -> write()).start();
}
}
// OUTPUT
Thread-0得到读锁,正在读取
Thread-1得到读锁,正在读取
Thread-1释放读锁
Thread-0释放读锁
Thread-2得到写锁,正在写入
Thread-2释放写锁
Thread-3得到写锁,正在写入
Thread-3释放写锁
ReentrantLock 适用于一般场合,ReadWriteLock 适用于读多写少的情况。合理使用可以进一步提高并发效率。
读写锁升降级
// 非公平读写锁,默认方式
ReentrantReadWriteLock reentrantReadWriteLock = new ReentrantReadWriteLock(false);
// 公平读写锁
ReentrantReadWriteLock reentrantReadWriteLock = new ReentrantReadWriteLock(true);
在获取读锁之前,线程会检查 readerShouldBlock() 方法,同样,在获取写锁之前,线程会检查 writerShouldBlock() 方法,来决定是否需要插队或者是去排队。
公平读写锁
final boolean writerShouldBlock() {
return hasQueuedPredecessors();
}
final boolean readerShouldBlock() {
return hasQueuedPredecessors();
}
上述代码表明只要等待队列中有线程在等待,即 hasQueuedPredecessors() 返回 true,那么读操作和写操作都会被阻塞,即一律不允许插队。
非公平读写锁
final boolean writerShouldBlock() {
return false; // writers can always barge
}
final boolean readerShouldBlock() {
return apparentlyFirstQueuedIsExclusive();
}
writeShouldBlock() 方法始终返回 false,对于想获得写锁而言,该线程是随时可以插队的。
但是对于读锁则不一样了:线程1、2 都持有读锁,线程 3 想要写入,所以线程 3 进入等待队列中。此时线程 4 突然跑来想要插队获取读锁。面对这种情况有两种应对策略:
- 允许插队。看似效率增加,但会导致一个严重的问题:如果读线程不断增加,则想要得到读锁的线程可能处于饥饿状态。
- 不允许插队。也是非公平读写锁采取的策略。乖乖让线程 4 去排队。
锁的升降级
读写锁支持锁的降级,不支持升级。只能从写锁降级为读锁,不能从读锁升级为写锁。
为什么不支持锁的升级?我们知道读写锁的特点是如果线程都申请读锁,是可以多个线程同时持有的,可是如果是写锁,只能有一个线程持有,并且不可能存在读锁和写锁同时持有的情况。
正是因为不可能有读锁和写锁同时持有的情况,所以升级写锁的过程中,需要等到所有的读锁都释放,此时才能进行升级。
假设有 A,B 和 C 三个线程,它们都已持有读锁。假设线程 A 尝试从读锁升级到写锁。那么它必须等待 B 和 C 释放掉已经获取到的读锁。如果随着时间推移,B 和 C 逐渐释放了它们的读锁,此时线程 A 确实是可以成功升级并获取写锁。
但是我们考虑一种特殊情况。假设线程 A 和 B 都想升级到写锁,那么对于线程 A 而言,它需要等待其他所有线程,包括线程 B 在内释放读锁。而线程 B 也需要等待所有的线程,包括线程 A 释放读锁。这就是一种非常典型的死锁的情况。谁都愿不愿意率先释放掉自己手中的锁。
但是读写锁的升级并不是不可能的,也有可以实现的方案,如果我们保证每次只有一个线程可以升级,那么就可以保证线程安全。只不过最常见的 ReentrantReadWriteLock 对此并不支持。
降级锁是在持有写锁的情况下获取读锁然后释放写锁,读操作不会存在线程不安全问题,但是写操作存在,所以在写锁中获取读锁肯定是线程安全的,是允许的。我有一个问题,如果在锁降级之前,已经有新的线程在等待写锁,这里的降级应该也是能成功的,而且读锁插队了,要不然死锁了。如果在锁降级的过程中,已经有多个线程在等待读写锁,而且写锁的申请发生在读锁之前,这个时候应该还有只有发生锁降级的线程持有读锁吧,这样做的话还有一个好处,减少了两次线程切换。锁不能升级的原因:多个线程同时发生锁升级的时候,会发生死锁,因为发生锁升级的线程会等待其它线程释放读锁,我感觉可以在我感觉可以在这里加一个标志变量或者 trylock 来解决。
自旋锁

前提知识点:上下文切换、线程阻塞和唤醒等开销很大。
因此,为了减少这一部分开销,尽量在不进行上面的情况下获取锁。底层使用 Compare And Swap,CAS 的思想。
缺点:在极端的情况下可能会做大量的无用的尝试,白白浪费 CPU 资源。
适用场景:适用于并发度不是特别高的场景。以及临界区比较短小的情况。临界区短小是指使用共享资源非常短暂。
锁优化
ConcurrentHashMap
JDK 7

- 在 ConcurrentHashMap 内部进行了 Segment 分段,Segment 继承了 ReentrantLock,可以理解为一把锁,各个 Segment 之间都是相互独立上锁的,互不影响。
每个 Segment 的底层数据结构与 HashMap 类似,仍然是数组和链表组成的拉链法结构。默认有 0~15 共 16 个 Segment,所以最多可以同时支持 16 个线程并发操作(操作分别分布在不同的 Segment 上)。16 这个默认值可以在初始化的时候设置为其他值,但是一旦确认初始化以后,是不可以扩容的。
JDK 8

元素小于等于 8 采用拉链法,大于 8 转换为红黑树结构。
- 红黑树特点:
- 每个节点要么是红色,要么是黑色,但根节点永远是黑色。
- 红色节点不能连续,即红色节点的子和父都不能是红色。
- 从任一节点到每个叶子节点的路径都包含相同数量的黑色节点。
- 对 BST(Binary Search Tree)的一种平衡策略。会自动平衡。

为什么 Map 桶中超过 8 个才转为红黑树?
单个 TreeNode 需要占用的空间大约是普通 Node 的两倍,所以只有当包含足够多的 Nodes 时才会转成 TreeNodes,而是否足够多就是由 TREEIFY_THRESHOLD 的值决定的。而当桶中节点数由于移除或者 resize 变少后,又会变回普通的链表的形式,以便节省空间。
如果 hashCode 分布良好,也就是 hash 计算的结果离散好的话,那么红黑树这种形式是很少会被用到的,因为各个值都均匀分布,很少出现链表很长的情况。在理想情况下,链表长度符合泊松分布,各个长度的命中概率依次递减,当长度为 8 的时候,概率仅为 0.00000006。这是一个小于千万分之一的概率,通常我们的 Map 里面是不会存储这么多的数据的,所以通常情况下,并不会发生从链表向红黑树的转换。
事实上,链表长度超过 8 就转为红黑树的设计,更多的是为了防止用户自己实现了不好的哈希算法时导致链表过长,从而导致查询效率低,而此时转为红黑树更多的是一种保底策略,用来保证极端情况下查询的效率。
通常如果 hash 算法正常的话,那么链表的长度也不会很长,那么红黑树也不会带来明显的查询时间上的优势,反而会增加空间负担。所以通常情况下,并没有必要转为红黑树,所以就选择了概率非常小,小于千万分之一概率,也就是长度为 8 的概率,把长度 8 作为转化的默认阈值。
所以如果平时开发中发现 HashMap 或是 ConcurrentHashMap 内部出现了红黑树的结构,这个时候往往就说明我们的哈希算法出了问题,需要留意是不是我们实现了效果不好的 hashCode 方法,并对此进行改进,以便减少冲突。

若有收获,就点个赞吧
0 人点赞
