概述
本章是非常重要的一个章节,因为理解不同的 I/O 模型的局限性和优势能帮助我们更好的了解和学习网络编程。
Linux I/O 模型
下图包含 Linux 经典的 5 种 I/O 模型,我们需要清楚的知道一个输入操作通常包含两个的阶段:
- 等待数据准备好。
- 从内核向进程复制数据。
譬如对于一个套接字的输入操作,有以下描述:
- 第一步通常涉及等待数据从网络中到达,当所等待分组到达时,它被复制到内核中的某个缓冲区。
- 第二步就是把数据从内核缓冲区中复制到应用进程缓冲区。
可以笼统地概述网络编程本质是面向缓冲区编程(说法并非绝对正确)。
阻塞式 I/O 模型
阻塞式 I/O 是最流行的 I/O 模型,由于它的可预测性使得编程简单。
默认情况下,所有套接字都是阻塞的。
以数据报为例,它的阻塞式模型如下:
注意,上面的图示是针对UDP而言,对于TCP来说,诸如套接字低水位标记(low-water mark)等额外变量开始起作用,导致这个概念变得复杂。
进程调用 recvfrom,其系统调用直到数据报到达且被复制到应用进程的缓冲区中或发生错误才返回。最常见的错误是系统调用被信号中断。
模型说明
阻塞式 I/O 是最常见的一种模型,也是最简单的模型。因为他的执行流程是从上往下顺序执行,因此具有可预测性,易于编程。此时进程处于 waiting 状态,CPU 处理其他进程。直到数据准备好并将数据从内核复制到用户空间后,进程才会被唤醒。对于 CPU 而言并没有浪费 CPU 性能,但从进程角度看,一个进程只能等待I/O结束,降低进程的使用效率。
非阻塞式 I/O 模型
进程把一个套接字设置成非阻塞是在通知内核: 不要休眠本进程,而是返回一个错误。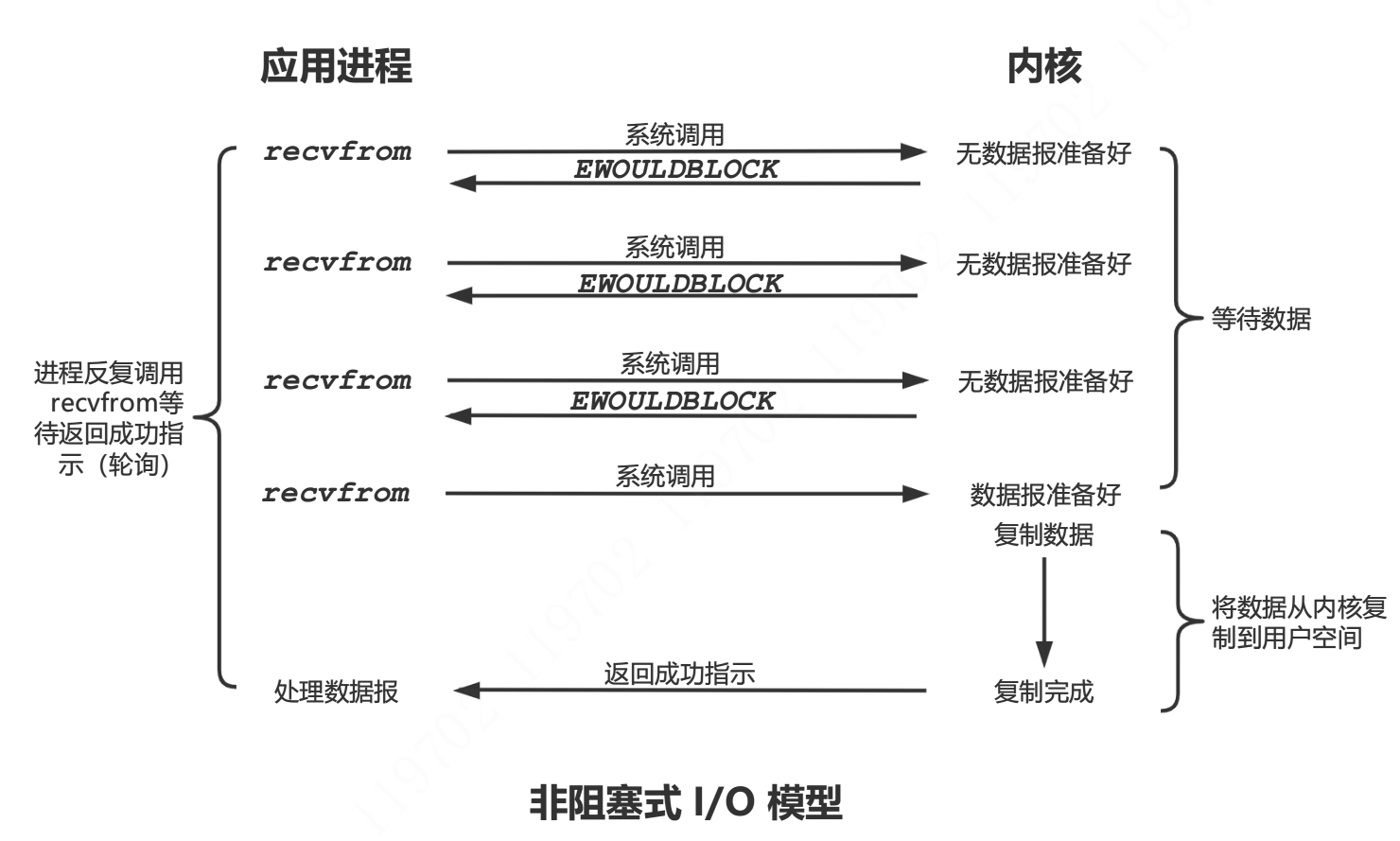
模型说明
前三次调用 recvfrom 时没有数据可返回,因此内核立即返回一个 EWOULDBLOCK 错误,第四次调用 recvfrom 时已有一个数据报准备好,它被复制到应用进程缓冲区(注意,复制数据期间,进程处于阻塞状态)于是 recvfrom 成功返回,进程可以处理数据。
应用进程持续轮询内核,以检查某个操作是否就绪,这样做最大的缺点是耗费大量 CPU 时间,通常是在专门提供某一种功能的系统中才使用。
I/O 复用模型
有了 I/O 复用(I/O multiplexing),我们就可以调用 select 或 poll,阻塞在这两个系统调用中的某一个之上,而非阻塞在真正的 I/O 系统调用上。
模型说明
I/O 复用阻塞于 select 调用,等待数据报套接字变为可读。当 select 返回套接字可读这一条件时,我们调用 recvfrom 把所读数据报复制到应用进程缓冲区。
和阻塞式 I/O 相比,多路复用 I/O 模型似乎并不显得十分明显的优势,因为多路复用 I/O 使用两个系统调用完成相同的功能。但事实上,使用 select 的优势在于我们可以等待多个描述符就绪,即可以使用一个进程管理多个描述符。多路复用解决了阻塞 I/O 和非阻塞 I/O 模型的痛点,是一种非常高效的 I/O 模型。
信号驱动式 I/O
信号驱动式 I/O 可以让内核在描述符就绪时发送 SIGIO 信号通知进程。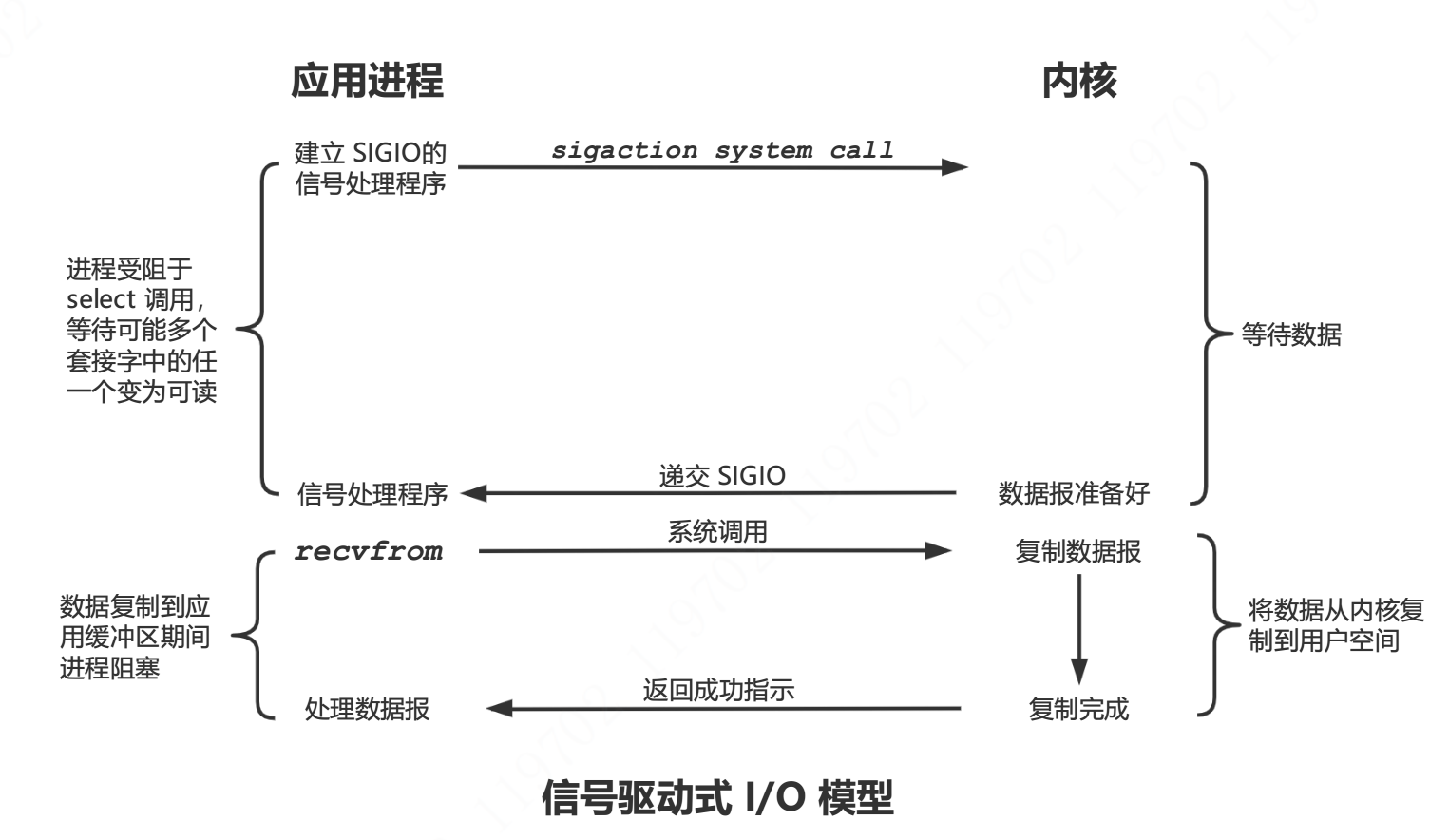
模型说明
信号驱动式 I/O 并不常用,它是一种半异步的 I/O 模型。当数据准备就绪后,内核通过发送一个 SIGIO 信号通知应用进程,应用进程就可以开始读取数据了。因为 recvfrom 还是由应用进程调用,所以是一个半异步模型。
异步 I/O
异步 I/O(asynchronous I/O)由 POSIX 规范定义。相关函数工作机制是:
- 告知内核启动某个操作。
- 让内核在整个操作(包括将数据从内核复制到进程缓冲区)完成后通知进程。
异步 I/O 和信号驱动式 I/O 的主要区别在于: 信号驱动式 I/O 是由内核通知进程何时可以启动一个 I/O 操作,而异步 I/O 模型是由内核通知进程 I/O 操作何时完成。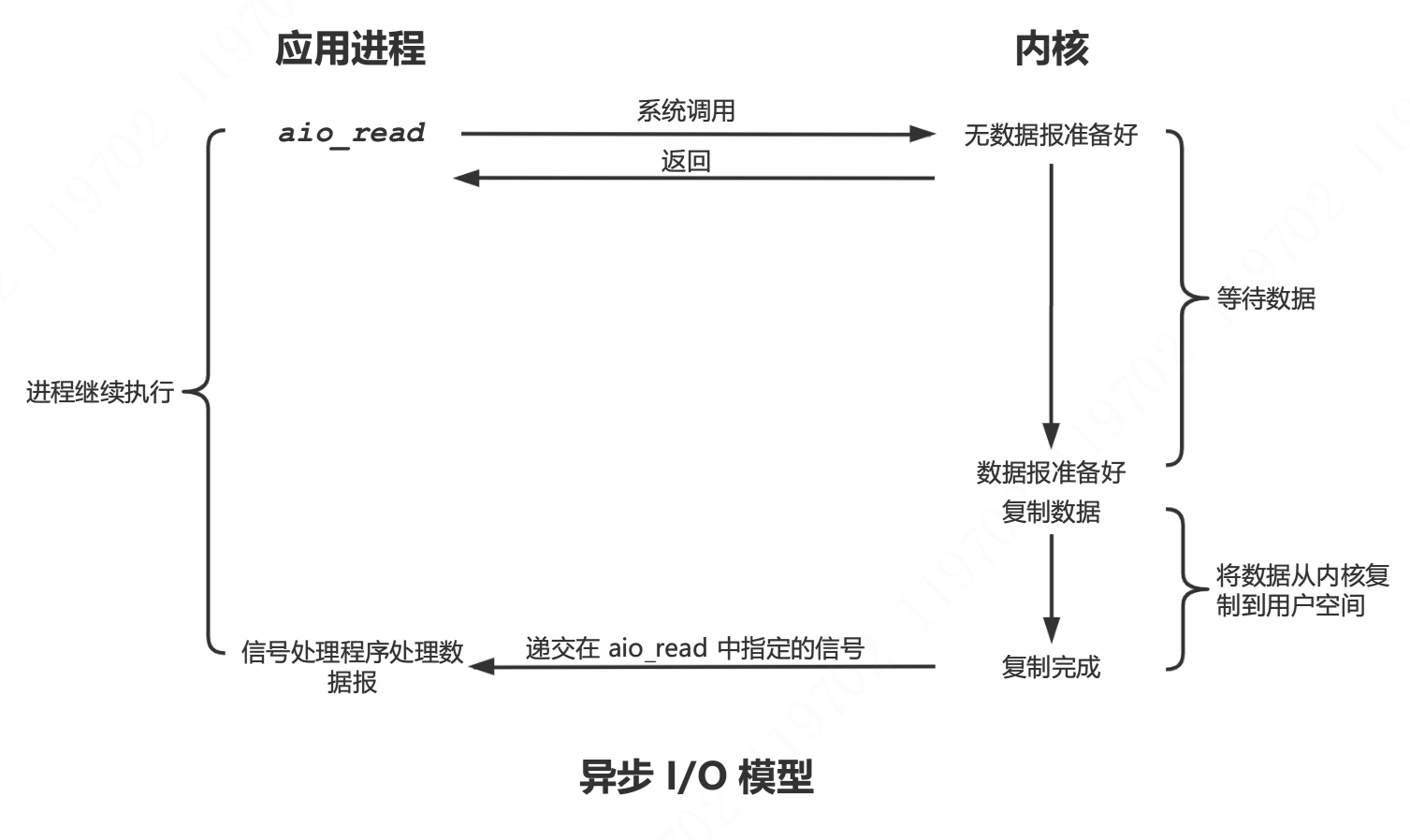
模型说明
进程调用 aio_read函数,向内核传递描述符、缓冲区指针、缓冲区大小和文件偏移,并告知内核当整个操作完成时如何通知进程。该系统调用立即返回,并且等待 I/O 完成期间,进程不会被阻塞。
5种 I/O 模型比较
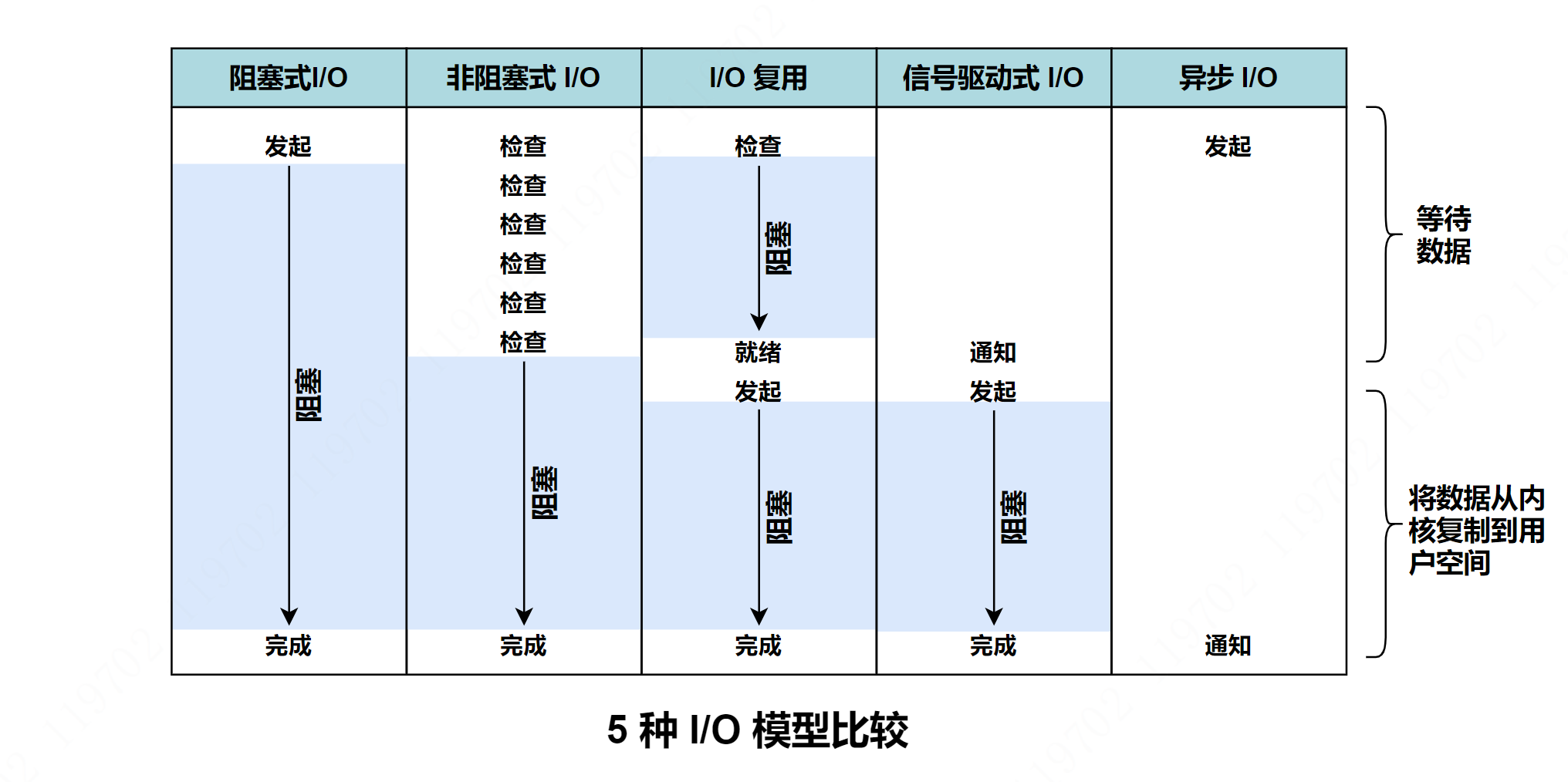
比较结果
- 前 4 种模型的第二阶段是一样的(在数据从内核复制到进程缓冲区期间,进程阻塞于 recvfrom 系统调用),第一阶段存在明显区别。
- 异步 I/O 模型在第一、二阶段都要处理,与其他 4 种模型都不相同。
同步IO/异步IO
同步 IO
导致请求进程阻塞,直到 I/O 操作完成。本次调用过程的参与者都处于一个状态同步的过程。异步 IO
不导致请求进程阻塞。调用方发出请求后立即返回,而结果会在未来某个时刻被接收方主动推送(通知或回调)。阻塞 IO/非阻塞 IO
阻塞 I/O
进程在发起了一个系统调用后,由于该系统调用的操作不能立即完成,需要等待一段时间,于是内核将进程挂起为等待(waiting)状态,以确保它不会被调度执行,占用 CPU 资源。非阻塞 I/O
非阻塞 I/O 其实可以被异步 I/O 替换,但它们还是有以下区别:
- 非阻塞式 I/O 系统调用操作立即返回,返回的内容是当前时刻已准备好的数据。结果可能完整也可能不完整。
- 异步 I/O 系统调用操作立即返回,但结果必须是完整的。对这个结果的处理可以延迟在未来的某个时间点执行。
- 非阻塞式 I/O 和 异步 I/O 都属于非阻塞式行为,它的们差异仅仅是返回的结果的方式和内容不同。
阻塞和非阻塞描述的本质是进程的某个操作是否会使得进程转变为等待(waiting)状态。
但为什么经常和 I/O 放在一起讨论呢?这是因为阻塞这个词是与系统调用紧密联系的,因为要让一个进程进入等待状态,有两种方式:
- 进程主动调用 wait() 或 sleep() 等方法将自己挂起。
- 通过系统调用让自己陷入内核态,而系统调用因为涉及到了 I/O 操作,不能立即完成,于是内核就会先将该进程置为等待状态,待进程所请求的 I/O 操作完成后,内核再将进程的状态更改为 ready。
内核执行 I/O 相关的系统调用时,比如从硬盘中读取数据简单划分以下步骤:
- 内核发起一个读硬盘的请求,通过总线向硬盘设备发出读请求。
- 硬盘收到读请求,把数据拷贝到硬盘相应的缓冲区中,并发出中断信号。
- CPU 响应此中断信号,把硬盘缓冲区中的数据拷贝到内核缓冲区中。
通常,与底层硬盘的交互都是非阻塞的,但提供的接口却是阻塞,这是因为阻塞式调用可以让应用级代码更加容易。
总结
- 阻塞/非阻塞、同步/异步的概念的讨论需要确认上下文的语境:
- 在进程通信层面,阻塞/非阻塞、同步/异步基本是同义词,但需要区分所讨论的对象是发送方还是接收方。
- 发送方阻塞/非阻塞(同步/异步)和接收方的阻塞/非阻塞(同步/异步)是互不影响的。
- 在 I/O 系统调用层面,非阻塞 I/O 系统调用和异步 I/O 系统调用是有区别的,主要区别是: 返回结果的方式和内容。
- 非阻塞式系统调用的存在可以说用来实现线程级的 I/O 并发,与通过多进程实现的 I/O 并发相比可以减少内存消耗和进程切换的开销。
- 从 Linux 接口的角度讲,阻塞和非阻塞都是同步 I/O,因为它们都需要调用方把数据在内核空间和用户空间来回移动(读/写操作),从这个角度看是同步的。只有使用了特殊的 API (比如 IOCP)才是异步 I/O。阻塞与非阻塞的区别其实是影响调用接口的结果(在特定条件下是否提前返回结果),而不是调用方式。
简言之, 对于一个应用层级的IO接口,调用该接口时,如果数据尚未准备好,不管是返回错误值,还是最终触发回调函数,只要能立刻返回, 我们就能称这个接口是非阻塞的,相反,如果在数据尚未准备好时,调用该接口的线程/进程被挂起, 进入等待状态,那我们就可以称这个接口是阻塞的
水平触发和边缘触发
在非阻塞 I/O 中,有两种模式对已准备好的 fd 进程操作,分别是:水平触发(LT)和边缘触发(ET)。
区别
在 LT 模式中,只要某个 fd 还有数据没有读完,那么下次轮询还会被选出。而在 ET 模式下,只有 fd 状态发生改变后,该 fd 才会两次被选出,因此,在 ET 模式下,必须处理完本次轮询出的 fd 中的所有数据,每次都需要读到 Socket 返回 EWOULDBLOCK 为止,否则该 fd 将不会在下次轮询中被选出,此 Socket 作废。
在Netty中,NioChannel体系是水平触发,EpollChannel体系是边缘触发。在使用 Java NIO 编程时,在没有数据可以写的时候就取消写事件,在有数据可写的时候再注册写事件。
Reactor 设计模式
引用 Wiki 定义:
The reactor design pattern is an event handling pattern for handling service requests delivered concurrently to a service handler by one or more inputs. The service handler then demultiplexes the incoming requests and dispatches them synchronously to the associated request handlers. Reactor 设计模式是一个事件处理模式,用于处理由一个或多个输入并发交付给服务处理程序的服务请求。然后,服务处理程序将传入的请求解复用,并将它们同步地分派给关联的请求处理程序。
从上面可以看出,Reactor 设计模型包含以下几部分:
- 事件源(Resource):任何能够为系统提供输入或消耗系统输出的资源。
- 同步事件分离(Synchronous Event Demultiplexer):使用事件循环对所有资源进行阻塞。当可以在资源上开始同步操作而不阻塞时,解复用器(demultiplexer)将资源发送给调度器。
- 分发(Dispatcher):处理注册和取消注册。将资源从解复用器分配给相关的请求处理程序。
- 处理请求(Request Handler):一个应用程序定义的请求处理程序及其相关资源。
Reactor 设计模型是一种典型的事件驱动的编程模型,以 I/O 多路复用为基础。
关于如何使用 Java NIO 实现 Reactor 设计模式可以通过阅读 Doug Lea 的 Scalable Io In Java。
单 Reactor 单线程模型
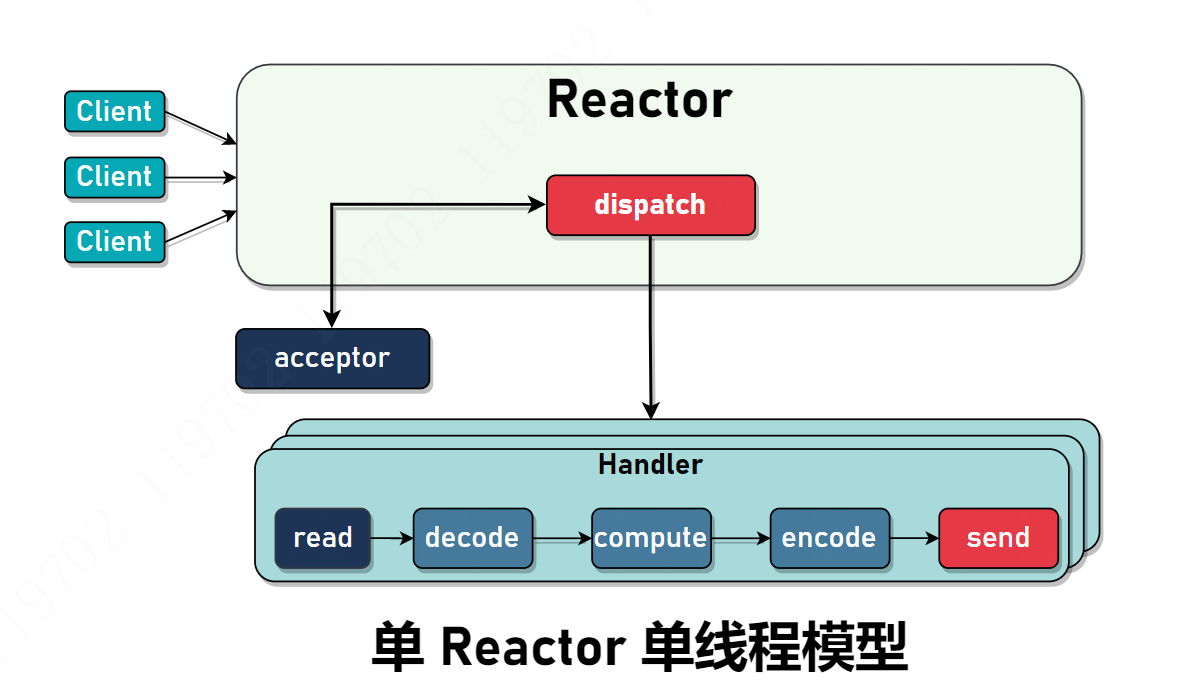
一个线程执行所有逻辑,包括通道注册、建立连接、解码、计算、编码、发送等一系列逻辑。在 Doug Lea 的 Scalable Io In Java 中实现逻辑总结如下:
- acceptor 专门负责处理 OP_ACCEPT 事件,一旦连接建立,acceptor 为此连接创建新的 Handler 对象,后续相关 I/O 操作由此 Handler 负责。
- Main 线程在 while 循环中不断调用 Selector#select() 轮询新的 I/O 事件并交给 dispatch,它仅仅是调用 Handler#run() 方法执行相关逻辑。
单 Reactor 单线程模型有一个致命的缺点,就是所有的操作(包含 I/O 事件处理和编解码等)都在 Main 线程中完成,如果其中某一步骤耗时严重,这会严重影响整体性能。
单 Reactor 多线程模型
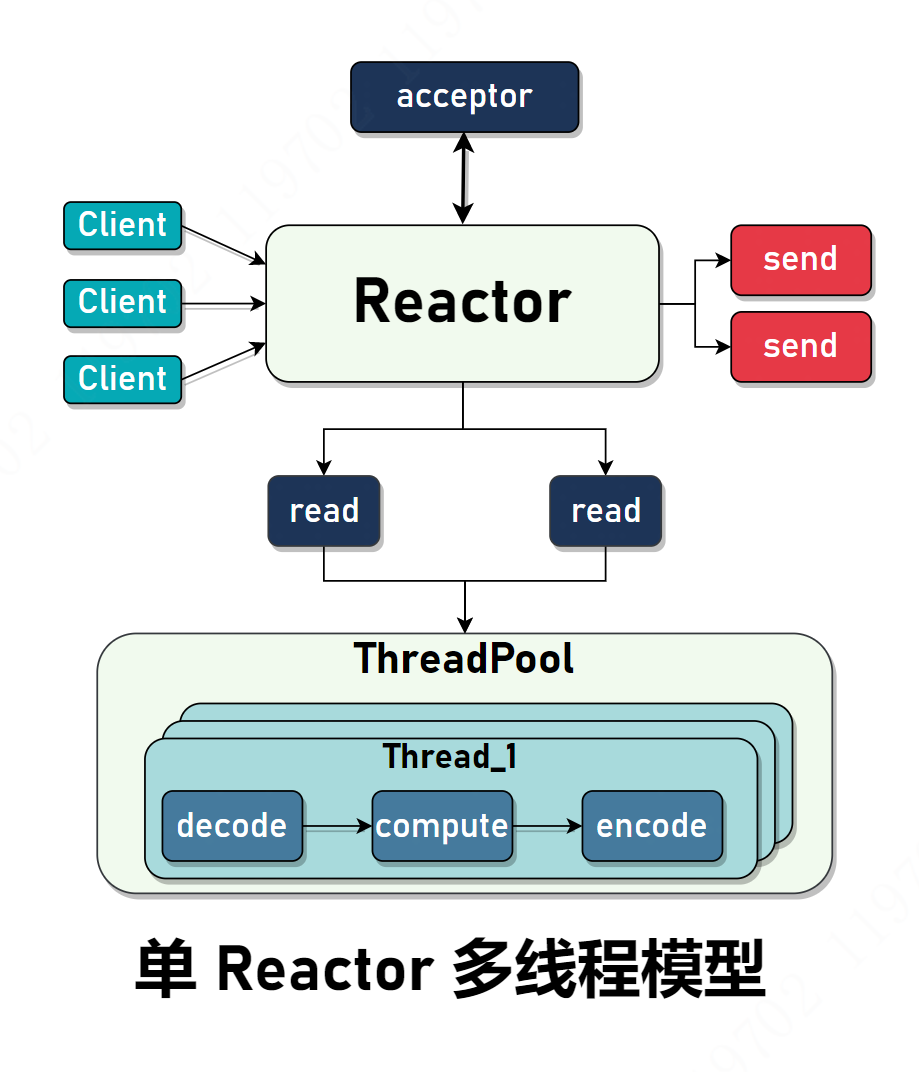
单 Reactor 多线程模型正是解决单线程模型的痛点,把解码、计算、编码等耗时的严重的操作和 acceptor 分开,并使用线程池提升性能。连接的建立、读取、发送等 I/O 操作还是在 Reactor 线程中完成。
主从 Reactor 模型
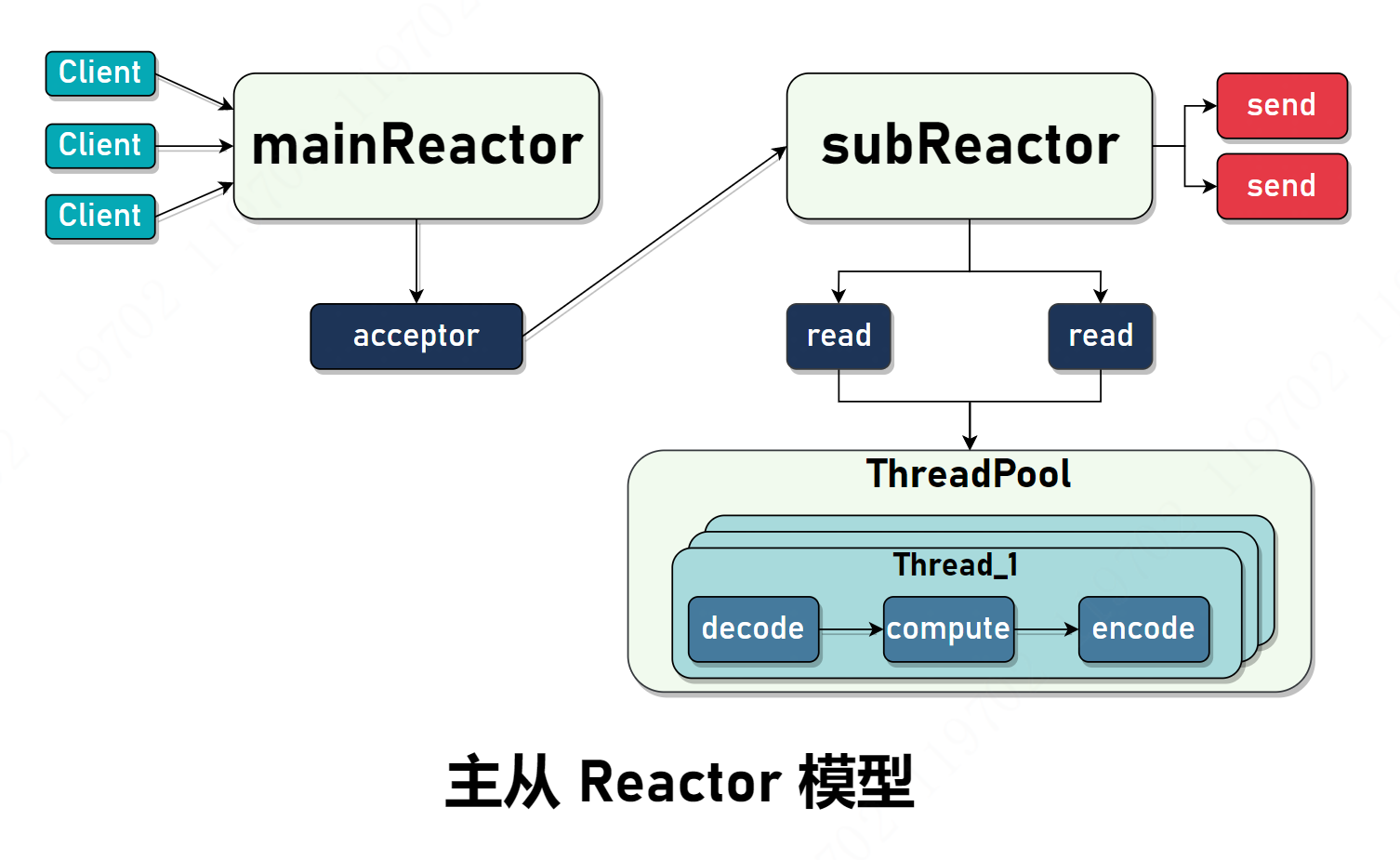
当连接过多时,如果只有一个线程处理建立通道连接、读取、发送等 I/O 事件的话,也会存在性能瓶颈,建立通道连接使用一个单独的线程运行,称为 mainReactor,一旦连接建立,向 subReactor 注册,后续只由 subReactor 管理。
参考
https://juejin.cn/post/6844904161725661197
https://www.jb51.net/article/162885.htm
关于非阻塞I/O、多路复用、epoll的杂谈

若有收获,就点个赞吧
0 人点赞
