概述
阅读 CompletableFuture 源码,真心佩服 Doug Lea 大神。几行代码看似简单,理解却十分困难。 本文源码基于 JDK 1.8。
Future 的局限性在于:
- 无非阻塞结果获取 API。如果任务未完成,调用
get()方法会阻塞线程,没有提供非阻塞获取结果任务的 API。 - 没有异步回调。只能通过不断轮询
isDone()方法或者调用get()方法阻塞线程。 - 不支持链式调用。
CompletableFuture 是 **Doug Lea** 在 1.8 版本提供对 Future 的强有力的扩展 API,与函数式编程相结合可以构建复杂的、高度定制的执行方案(策略):
- 提供阻塞和非阻塞 API 结果获取。
- 提供异步回调策略模型。
- 支持同步、异步任务执行模型。
-
函数式编程
函数式编程(Function Programming)是一种编程范式,它把计算当成是数学函数的求值,从而避免改变状态和使用可变数据。比如指令编程,函数式编程更加强调程序执行的结果而非执行的过程,倡导利用若干简单的执行单元让计算结果不断渐进,逐层推导复杂的运算,而不是设计一个复杂的执行过程。Java 在 JDK8 提供 Lambda 函数式编程,这标示 Java 往函数式编程又迈进了一小步。虽然和其他语言的函数式编程相比有食之无味,弃之可惜的意味,但总算是有这么一个东东存在。如有兴趣,可以看
- 函数式编程—COOLSHELL
- 什么是函数式编程思维?—知乎
函数式接口
Java 8 在java.util.function包下定义了多个函数式接口,详见下表:
| 函数式接口 | 泛型参数 | 接口 | 功能 |
|---|---|---|---|
| Predicate |
T->boolean | boolean test(T) static Predicate static Predicate static Predicate |
断言。判断参数 T 是否符合要求。 |
| Consumer |
T->Void | void accept(T) static Comsumer andThen(Comsumer) |
消费者。消费数据 T,函数没有返回值 |
| Function |
T->R | R apply(T) static Function compse(Function) static Function andThen(Function) static static |
函数。接收一个参数 T 经过运算得到结果 R |
| UnaryOperator |
T->T | Function 子接口,Function 特殊情况。接收一个参数 T 经过运算后得到结果 T。 | |
| BinaryOperator |
(T, T) -> T | static static |
BiFunction 的子接口,是 BiFunction 的特殊情况。接收两个相同的参数类型 T 经过运算后得到结果类型也为 T 的值。 |
| BiConsumer | (T, U)->Void | void apply(T, U) static BiConsumer |
特殊的 Comsumer。 参数为一个二元组。无返回值 |
| BiFunction | (T, U)->R | R apply(T t, U u) static |
特殊的 Function。 参数为一个二元组。返回值为 R |
| BinaryOperator | (T, T) -> T | static static |
BiFunction 子接口,BiFunction 特殊情况。 二元组参数和返回值类型一样,提供两个额外的静态方法 |
| BiPredicate | (T, U)-> boolean | boolean test(T, U) static BiPredicate static BiPredicate static BiPredicate |
特殊的 Predicate。 参数为一个二元组, 返回值为 boolean |
注:前缀
bi为binary,含义是 二元的。在这里表示有两个输入参数。
而我们即将讲解的 CompletableFuture 和上面定义的部分函数式接口密切相关,主要体现在 CompletionStage 接口上。
CompletionStage
Stage 翻译为过程、阶段,比如将 “一个大象放入冰箱” 可以分为三个阶段:
- 打开冰箱门。
- 将大象放入冰箱。
- 关闭冰箱门。
阶段 2 依赖 阶段 1,只有当阶段 1 完成之后才能进行进行阶段 2,而阶段 3 和阶段 2 同理,它是依赖阶段 2 的执行结果。步骤之间的关联关系是可以通过 CompletionStage 描述(上面所述的是基于同步描述的步骤)。
先把官方 CompletionStage 文档翻译一遍。
- 阶段之间具有关联关系。一个阶段的运行可以是依赖某个阶段的执行结果。
- 阶段本身可以同步执行或异步(方法名后缀带有
async关键字)执行。当一个阶段执行之后,会主动触发执行依赖此阶段的其他阶段。它们之间的关联关系是使用在 CompletionFuture 内部类表示,比如 UniApply 内部会持有源对象 A,依赖对象 B、依赖对象 B 执行任务函数 fn 等引用,当源对象 A 所表示的阶段执行完成后,就会触发执行依赖对象 B 的任务函数 fn。类似链式反应会一直递归执行下去。直到得到最后的结果为止。 - 某个已完成的阶段可能会触发其他阶段执行。它们具有前后依赖关系(A 需要 B 的结果,那只能等待 B 执行完才会通知 A 执行)。
- 可能由一个阶段完成之后就触发执行依赖任务。
- 可能由两个阶段都完成之后触发执行依赖任务。
- 可能由两个阶段中的一个完成就可以触发执行依赖任务。
- 阶段的依赖性控制了任务的执行,但不保证任何特定的执行顺序。一个阶段函数定义是通过 Lambda 函数表达式来完成的。支持
Function、Consumer和Runnable(分别调用它们的apply、accept、run方法)。当阶段被设定为异步模式但执行器为空,则会使用FolkJoinPool提供的线程执行异步任务。 - 方法
whenCompelete允许注入一个新的阶段而不管结果如何。方法handle允许对计算结果进一步处理,可能返回新的结果。 - 如果一个阶段的计算出现
Unchecked异常或error,那么所有的依赖此结果的其他阶段任务则会以异常的形式完成(complete exceptionally),并附带CompletionException。如果一个阶段同时依赖另外两个阶段,且另外两个阶段都出现异常,则CompletionException对应其中的某一个。如果一个阶段依赖另外两个阶段中的其中一个,然后他们其中一个抛出异常,那么不能保证被依赖的阶段是正常完成还是异常完成。如果仅whenComplete的阶段抛出异常,那么整体还会返回这个异常。 - 方法
toCompletableFuture通过提供通用的转换类型,可以在此接口的不同实现之间实现互操作性。
计算逻辑
 比如任务 B 需要得到任务 A 的结果才能执行,因此可以采用
比如任务 B 需要得到任务 A 的结果才能执行,因此可以采用 A.a().thenXX() 这种方式得到结果。比如任务 C 需要对任务 A 和任务 B 的结果做聚合,那有 A.a().thenAcceptBoth(B, action) 方式聚合并输出结果。
then 先后关系
CompletableFuture<Void> thenRun(Runnable action)CompletableFuture<Void> thenRunAsync(Runnable action)CompletableFuture<Void> thenRunAsync(Runnable action, Executor executor)<U> CompletableFuture<U> thenApply(Function<? super T,? extends U> fn)<U> CompletableFuture<U> thenApplyAsync(Function<? super T,? extends U> fn)<U> CompletableFuture<U> thenApplyAsync(Function<? super T,? extends U> fn, Executor executor)CompletableFuture<Void> thenAccept(Consumer<? super T> action)CompletableFuture<Void> thenAcceptAsync(Consumer<? super T> action)CompletableFuture<Void> thenAcceptAsync(Consumer<? super T> action, Executor executor)<U> CompletableFuture<U> thenCompose(Function<? super T, ? extends CompletionStage<U>> fn)<U> CompletableFuture<U> thenComposeAsync(Function<? super T, ? extends CompletionStage<U>> fn)<U> CompletableFuture<U> thenComposeAsync(Function<? super T, ? extends CompletionStage<U>> fn, Executor executor)
AND 关系
<U,V> CompletableFuture<V> thenCombine(CompletionStage<? extends U> other, BiFunction<? super T,? super U,? extends V> fn)<U,V> CompletableFuture<V> thenCombineAsync(CompletionStage<? extends U> other, BiFunction<? super T,? super U,? extends V> fn)<U,V> CompletableFuture<V> thenCombineAsync(CompletionStage<? extends U> other, BiFunction<? super T,? super U,? extends V> fn, Executor executor)<U> CompletableFuture<Void> thenAcceptBoth(CompletionStage<? extends U> other, BiConsumer<? super T, ? super U> action)<U> CompletableFuture<Void> thenAcceptBothAsync(CompletionStage<? extends U> other, BiConsumer<? super T, ? super U> action)<U> CompletableFuture<Void> thenAcceptBothAsync( CompletionStage<? extends U> other, BiConsumer<? super T, ? super U> action, Executor executor)CompletableFuture<Void> runAfterBoth(CompletionStage<?> other, Runnable action)CompletableFuture<Void> runAfterBothAsync(CompletionStage<?> other, Runnable action)CompletableFuture<Void> runAfterBothAsync(CompletionStage<?> other, Runnable action, Executor executor)
OR 关系
<U> CompletableFuture<U> applyToEither(CompletionStage<? extends T> other, Function<? super T, U> fn)<U> CompletableFuture<U> applyToEitherAsync(、CompletionStage<? extends T> other, Function<? super T, U> fn)<U> CompletableFuture<U> applyToEitherAsync(CompletionStage<? extends T> other, Function<? super T, U> fn, Executor executor)CompletableFuture<Void> acceptEither(CompletionStage<? extends T> other, Consumer<? super T> action)CompletableFuture<Void> acceptEitherAsync(CompletionStage<? extends T> other, Consumer<? super T> action)CompletableFuture<Void> acceptEitherAsync(CompletionStage<? extends T> other, Consumer<? super T> action, Executor executor)CompletableFuture<Void> runAfterEither(CompletionStage<?> other, Runnable action)CompletableFuture<Void> runAfterEitherAsync(CompletionStage<?> other, Runnable action)CompletableFuture<Void> runAfterEitherAsync(CompletionStage<?> other, Runnable action, Executor executor)
结果处理
CompletableFuture<T> whenComplete(BiConsumer<? super T, ? super Throwable> action)CompletableFuture<T> whenCompleteAsync(BiConsumer<? super T, ? super Throwable> action)CompletableFuture<T> whenCompleteAsync(BiConsumer<? super T, ? super Throwable> action, Executor executor)<U> CompletableFuture<U> handle(BiFunction<? super T, Throwable, ? extends U> fn)<U> CompletableFuture<U> handleAsync(BiFunction<? super T, Throwable, ? extends U> fn)<U> CompletableFuture<U> handleAsync(BiFunction<? super T, Throwable, ? extends U> fn, Executor executor)
异常处理
CompletableFuture<T> exceptionally(Function<Throwable, ? extends T> fn)
CompletableFuture<T> exceptionallyAsync(Function<Throwable, ? extends T> fn)
CompletableFuture<T> exceptionallyAsync(Function<Throwable, ? extends T> fn, Executor executor)
入参
从上面的接口定义中,我们不难发现,CompletionStage 所定义的接口入参是 Lambda 函数接口,主要有以下几类:
- Runnable
- Function
- Consumer
- Supplier
- BiConsumer
可以从接口名称看出到底应该选择哪种类型 Lambda 函数接口,比如 thenAccept 表示接受数据,但不会返回任何有意义的结果,因此,使用 Consumer 类型的 Lambda 函数接口。再比如 thenApply 表示应用数据,它会返回有意义的结果,因此,使用 Function 类型的 Lambda 函数接口。
CompletableFuture
CompletableFuture 是这篇文章的主角,前面讲了这么多就是给它做铺垫。前面讲到关于 Lambda 函数接口以及 CompletionStage 接口的定义以及类型,CompletableFuture 是 CompletionStage 的实现类,同时也实现 Future,这样具有获取结果、取消任务等能力。层次结果描述如下: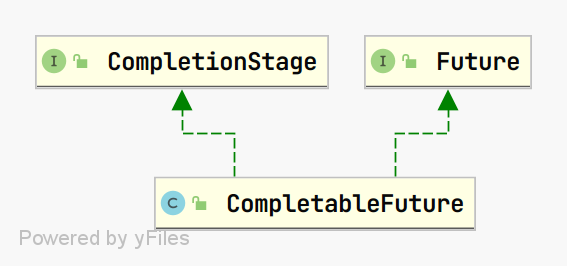
部分 API 使用
关于 API 的使用,请看 CompletableFuture 20 个使用示例
AltResult
这个类用途是作为 CompletableFuture 结果返回:
- 结果为 null 时返回此对象。
- 出现异常时返回此对象。
源码定义非常简单:
// java.util.concurrent.CompletableFuture.AltResult
static final class AltResult {
final Throwable ex; // null only for NIL
AltResult(Throwable x) { this.ex = x; }
}
static final AltResult NIL = new AltResult(null);
Completion
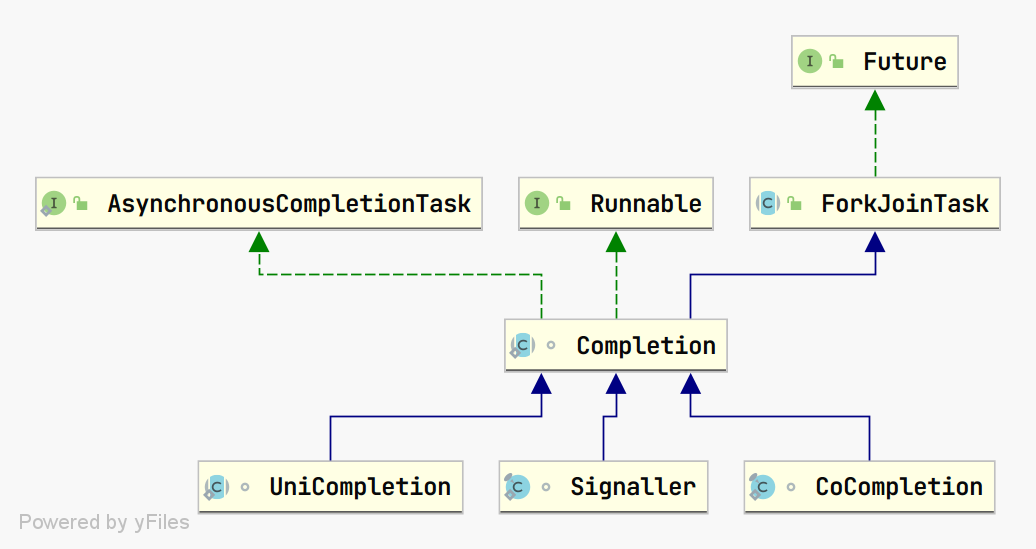
Completion 是 CompletableFuture 的内部抽象类,层次关系如上图所示:
- AsynchronousCompletionTask 是一个标记接口,用来方便 DEBUG。
- 继承
ForkJoinTask抽象类,主要是在异步执行任务时,如果用户没有指定 Executor,内部会默认使用 ForkJoinPool 执行。而 ForkJoinPool 执行的基本是将任务封装为 ForkJoinTask 对象。 - 继承 Runnable。如果用户指定 Executor,则会调用
Runnable#run方法执行任务。
Completion 所继承的接口和抽象类主要是为了执行异步任务封装的。但 Completion 抽象类还定义了两个非常重要的抽象方法:
CompletableFuture tryFire(int mode)是一个非常重要的方法。具体子类有不同的实现,但是逻辑相似:它会尝试异步或同步触发任务执行,如果执行成功,则触发后置任务执行并返回后置依赖任务的 CompletableFuture 对象,否则返回 null。boolean isLive()方法判断当前 Completion 是否仍然可触发(triggerable)。特定子类有不同的实现。
Completion 内部属性只有一个带 volatile 关键字的 Completion next,它是通过单向链表构成 Treiber 并发栈,用来保存依赖当前任务的其他任务对象。即任务 B 需要任务 A 的执行结果,但此时任务 A 并没有执行完,所以会把任务 B 相关的信息封装为 Completion 子类实例并放入任务 A 的并发栈中,待 A 执行完成后会触发栈内相关的任务执行。
// java.util.concurrent.CompletableFuture.Completion
abstract static class Completion extends ForkJoinTask<Void>
implements Runnable, AsynchronousCompletionTask {
// 指向下一个Completion,构成单向链表
volatile Completion next; // Treiber stack link
/**
* Performs completion action if triggered, returning a
* dependent that may need propagation, if one exists.
*
* ① 执行任务函数
* ② 返回依赖当前任务的后置任务(使用CompletableFuture表示)
*
* @param mode SYNC, ASYNC, or NESTED
*/
abstract CompletableFuture<?> tryFire(int mode);
/**
* true:当前「Completion」仍是「可触发的(triggerable)」,
* 此方法用于清理任务栈时使用
*/
abstract boolean isLive();
/**
* 实现「Runnable」方法,
*/
public final void run() {
tryFire(ASYNC);
}
/**
* 实现「java.util.concurrent.ForkJoinTask#exec」接口
* 有一个返回值且一直为true
*/
public final boolean exec() {
tryFire(ASYNC);
return true;
}
public final Void getRawResult() {
return null;
}
public final void setRawResult(Void v) {}
}
Completion 有三个子类,分别是 UniCompletion、CoCompletion 和 Signaller。层次关系图如下: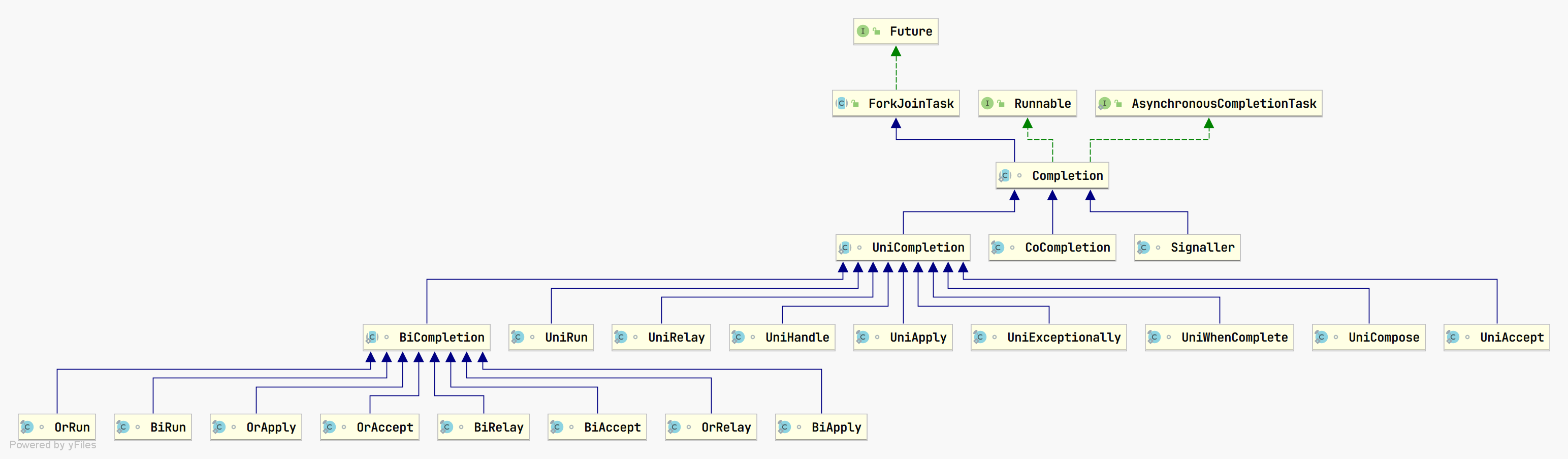
CoCompletion
CoCompletion 是 BiCompletion 的代理,内部持有一个 BiCompletion,相关方法都会委托 BiCompletion 实现。
Signaller
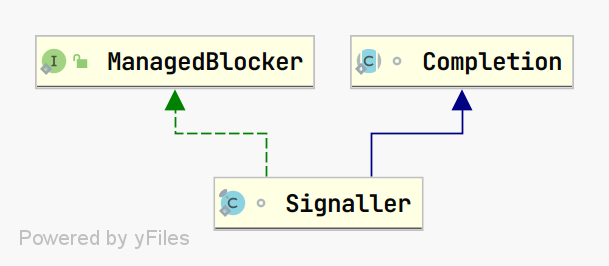
从上图的层次关系可以看出,Signaller 继承 Completion 抽象类的同时也实现了 ManagedBlocker 接口(该接口来源于 ForkJoinPool,定义阻塞相关的 API)。从名称也可以看出,它是一个信号员,配合 CompletableFuture#get 或 CompletableFuture#join 使用。当主线程调用这两种方法时,如果任务还没有执行完毕,它有做以下几件事情:
- 先自旋一定次数(默认值:256),每次自旋都会尝试获取结果。如果此时还不能获得结果,则创建新的 Signaller 对象包装结果获取线程并加入任务 CompletableFuture 的并发栈中。
- 调用
ForkJoinPool#managedBlock(ManagedBlocker)静态方法阻塞结果获取线程。
比如线程 B 需要获取线程 A 的任务结果(异步任务执行)此时线程 A 在一定时间内还没有结果产生,线程 A 则出于不浪费资源的目的,先不断自旋并判断线程 A 的结果是否存在,如果超出自旋次数结果还没有的话,那就使用 Signaller 对象包装线程 A 并添加线程 B 的任务 CompletableFuture 并发栈中,等到线程 B 的任务完成后,会遍历栈并回调相关方法,而 Signaller 的任务就是唤醒线程 A 表示结果已经有了,你可以执行后续任务。这一般是针对并发的情况才会这样做。
相关源码解释如下:
// java.util.concurrent.CompletableFuture.Signaller
static final class Signaller extends Completion
implements ForkJoinPool.ManagedBlocker {
long nanos; // 超时时间
final long deadline; // 如果nanos!=0,则deadline也为非0的数
volatile int interruptControl; // > 0: 可中断的, < 0: 已中断
volatile Thread thread; // 待通知线程
Signaller(boolean interruptible, long nanos, long deadline) {
this.thread = Thread.currentThread();
this.interruptControl = interruptible ? 1 : 0;
this.nanos = nanos;
this.deadline = deadline;
}
/**
* 如果线程不为空,则解除线程阻塞并唤醒线程
*/
final CompletableFuture<?> tryFire(int ignore) {
Thread w; // no need to atomically claim
if ((w = thread) != null) {
thread = null;
// 解除阻塞,唤醒线程
LockSupport.unpark(w);
}
return null;
}
/**
* 判断线程「thread」是否可被释放。返回true表示阻塞线程是否必要的。
*/
public boolean isReleasable() {
if (thread == null)
return true;
if (Thread.interrupted()) {
int i = interruptControl;
interruptControl = -1;
if (i > 0)
return true;
}
if (deadline != 0L &&
(nanos <= 0L || (nanos = deadline - System.nanoTime()) <= 0L)) {
thread = null;
return true;
}
return false;
}
/**
* 阻塞线程
*/
public boolean block() {
if (isReleasable())
return true;
else if (deadline == 0L)
LockSupport.park(this);
else if (nanos > 0L)
LockSupport.parkNanos(this, nanos);
return isReleasable();
}
final boolean isLive() { return thread != null; }
}
Signaller 做了以下工作:
- 解除线程阻塞。
- 根据是否设定超时时间阻塞线程。
UniCompletion
UniCompletion 也一个非常重要的内部抽象类,前缀 Uni- 我的理解表示单独的,从源码来看表示一对一关系。即任务 B (成员变量: dep)依赖任务 A (成员变量:src)。当然,这并不能说明任务 A 只有任务 B 这么一个依赖者,而是说明任务 B 只依赖任务 A 。
相关源码解释如下:
// java.util.concurrent.CompletableFuture.UniCompletion
abstract static class UniCompletion<T,V> extends Completion {
Executor executor; // 当前任务所需的执行器
CompletableFuture<V> dep; // 依赖者
CompletableFuture<T> src; // 依赖任务
UniCompletion(Executor executor, CompletableFuture<V> dep,
CompletableFuture<T> src) {
this.executor = executor;
this.dep = dep;
this.src = src;
}
/**
* true 表示行动(action)可以被执行。只有在已知可触发的情况下才能调用此方法。
* 使用FJ标志位确保只有一个线程声明所有权利。
* 如果同步调用,则以任务启动(随后会调用 tryFire() 方法执行)
* 如果异步调用,则通过调用执行器执行,并返回false
*/
final boolean claim() {
Executor e = executor;
// 设置标志位为1,在图搜索时用于判断当前节点是否已经被访问过
if (compareAndSetForkJoinTaskTag((short)0, (short)1)) {
if (e == null)
return true;
executor = null; // disable
// 异步执行
e.execute(this);
}
return false;
}
final boolean isLive() {
return dep != null;
}
}
UniCompletion 内部维护三个变量,分别是依赖任务 src、依赖者 dep 和 依赖者任务执行器 executor。依赖者 dep 需要等待所依赖的任务 src 执行完成后才能被触发执行。
方法 claim() 表示尝试对此 Task “宣誓主权”:
- 使用 CAS 设置相关标志位,防止任务重复执行。设置成功且没有执行器,直接返回 true。
- 设置失败且有执行器,则调用
Executor#execute(Runnable)执行,并返回 false。

UniCompletion 也有多个实现子类,如上图所示。除了抽象类 BiCompletion 外,其他子类都会实现 tryFire 抽象方法。它的大致逻辑是相似的:
- 尝试触发后置任务 dep 执行。内部会判断前置(依赖)任务 src 是否有返回结果,如果没有,则返回 false。否则返回 true。
- 若返回 false,则 tryFire 结果返回 null。若返回 true,则调用后置方法的
CompletableFuture#postFire触发后置方法的依赖。这是不是有点递归的味道呢?
还记得我们之前提到的函数式接口么? 有 Function、Runnable、BiFunction、BiConsumer、Consumer 等,它们是和 UniCompletion 对应的:
| 函数式接口 | 实现类类型 | 描述 |
|---|---|---|
| Runnable | UniRun | 内部维护一个 Runnable 的引用,会回调该对象的 run 方法 |
| Function | UniApply | 传入一个参数,得到一个结果。 结果类型为泛型 V |
| Function | UniExceptionally | 传入一个参数,得到一个结果。 入参参数类型为 Throwable 的子类 |
| Function | UniCompose | 传入一个参数,得到一个结果。 结果参数类型为 CompletionStage 或子类类型 |
| BiFunction | UniHandle | BiFunction 是特殊的 Function 传入两个参数(第二个参数是 Throwable 的子类),得到一个结果 |
| Consumer | UniAccept | 传入一个参数,不会返回任何结果 |
| BiConsumer | UniWhenComplete | 传入两个参数,不会返回任何结果 |
从上表可以看出,UniCompletion 针对不同类型的函数式接口提供对应的实现类。Uni- 的实现类表示只有一个入参的意思。
BiCompletion
BiCompletion 带有 Bi- 前缀的抽象类,表示有两个入参。源码如下:
// java.util.concurrent.CompletableFuture.BiCompletion
abstract static class BiCompletion<T,U,V> extends UniCompletion<T,V> {
CompletableFuture<U> snd; // second source for action
BiCompletion(Executor executor, CompletableFuture<V> dep,
CompletableFuture<T> src, CompletableFuture<U> snd) {
super(executor, dep, src); this.snd = snd;
}
}
变量 CompletableFuture 存储第二个依赖任务的结果对象。
该抽象类的层次接口如下图所示:
其实类型是和 UniCompletion 大致相同,只不过增加了额外的 OR 语义:之一。两个依赖任务其中一个完成就可以进行下面操作了。而其他没有带 Or- 前缀的就是 AND 语义:两者都。具体详见源码。
Treiber stack 无锁并发栈
前面大致讲了 CompletableFuture 和内部类的层次结构,了解相关类的设计思想。接下来所讲解的是一种数据结果:无锁并发栈。这在 java.util.concurrent 非常常见。
CompletableFuture 内部的 Completion 使用单向链表实现栈的效果,支持并发操作。具有以下特点:
- 栈顶元素是链表头部,栈底是链表尾部。
- 通过 CAS 对链表的头部进行增、删操作以达到入栈/出栈的目的。
源码解析如下:
static final int SYNC = 0; // 同步
static final int ASYNC = 1; // 异步
static final int NESTED = -1; // 内嵌
// java.util.concurrent.CompletableFuture.Completion
abstract static class Completion extends ForkJoinTask<Void>
implements Runnable, AsynchronousCompletionTask {
// 指向下一个Completion,构成单向链表
volatile Completion next; // Treiber stack link
/**
* Performs completion action if triggered, returning a
* dependent that may need propagation, if one exists.
*
* 尝试传播,
*
* @param mode SYNC, ASYNC, or NESTED
*/
abstract CompletableFuture<?> tryFire(int mode);
/**
* true:当前「Completion」仍是「可触发的(triggerable)」,
* 此方法用于清理任务栈时使用
*/
abstract boolean isLive();
/**
* 实现「Runnable」方法,
*/
public final void run() {
tryFire(ASYNC);
}
/**
* 实现「java.util.concurrent.ForkJoinTask#exec」接口
* 有一个返回值且一直为true
*/
public final boolean exec() {
tryFire(ASYNC);
return true;
}
public final Void getRawResult() {
return null;
}
public final void setRawResult(Void v) {}
}
/**
* 无脑更新当前链表的头结果为对象c,直到成功
*/
final void pushStack(Completion c) {
do {} while (!tryPushStack(c));
}
// java.util.concurrent.CompletableFuture#tryPushStack
/**
* 如果成功将 Completion c 入栈,则返回true
* lazySetNext底层是调用UNSAFE的putOrderedObject方法实现,
* 这个方法是对其他线程延迟可见,因为后面compareAndSwapObject方法设置成功了
* c自然对其他线程立即可见。因此,这是缩小临界值以提升性能
* 换名话说,lazySetNext方法调用完成后,引用关系只在工作内存更新,并没有立即同步到主内存。
* 因为这是没有必要的,当 compareAndSwapObject 调用成功后一起进行内存更新也不迟。
* 此方法可能会调用失败,所以名字以try开头
*/
final boolean tryPushStack(Completion c) {
// #1 获取栈对象
Completion h = stack;
// #2 先将旧的头结点添加到对象c.next
lazySetNext(c, h);
// #3 通过CAS设置「stack」的引用为c,有可能设置失败
return UNSAFE.compareAndSwapObject(this, STACK, h, c);
}
/**
* 修改对象c中偏移量为NEXT的值为对象next的引用
* @param c
* @param next
*/
static void lazySetNext(Completion c, Completion next) {
// 对其他线程延迟可见
UNSAFE.putOrderedObject(c, NEXT, next);
}
/**
* 「CAS」如果与期望值相等,则将对应属性更新为目标值
* @param o 目标对象
* @param offset 偏移量
* @param expected 期望值
* @param x 目标值
* @return
*/
public final native boolean compareAndSwapObject(Object o,
long offset,
Object expected,
Object x);
Java 内存模型
A memory model describes, given a program and an execution trace of that program, whether the execution trace is a legal execution of the program. Java’s memory model works by examining each read in an execution trace and checking that the write observed by that read is valid.
给定一个程序和该程序的一串执行轨迹,内存模型描述了该执行轨迹是否是该程序 的一次合法执行。对于 Java,内存模型检查执行轨迹中的每次读操作,然后根据特 定规则,检验该读操作观察到的写是否合法。
首先,回顾一个 JVM 的内存模型:
- 所有的变量都存储在主内存(Main Memory)。
- 每条线程拥有自己的工作内存(Work Memory),工作内存保存了被该线程使用的变量的主内存副本。
- 线程对变量的所有操作(读取、赋值)都必须在自己所属的工作内存中进行,而不能直接读写主内存中的数据。
线程之间不能直接进行数据交换,必须通过主内存完成线程间变量值的传递。
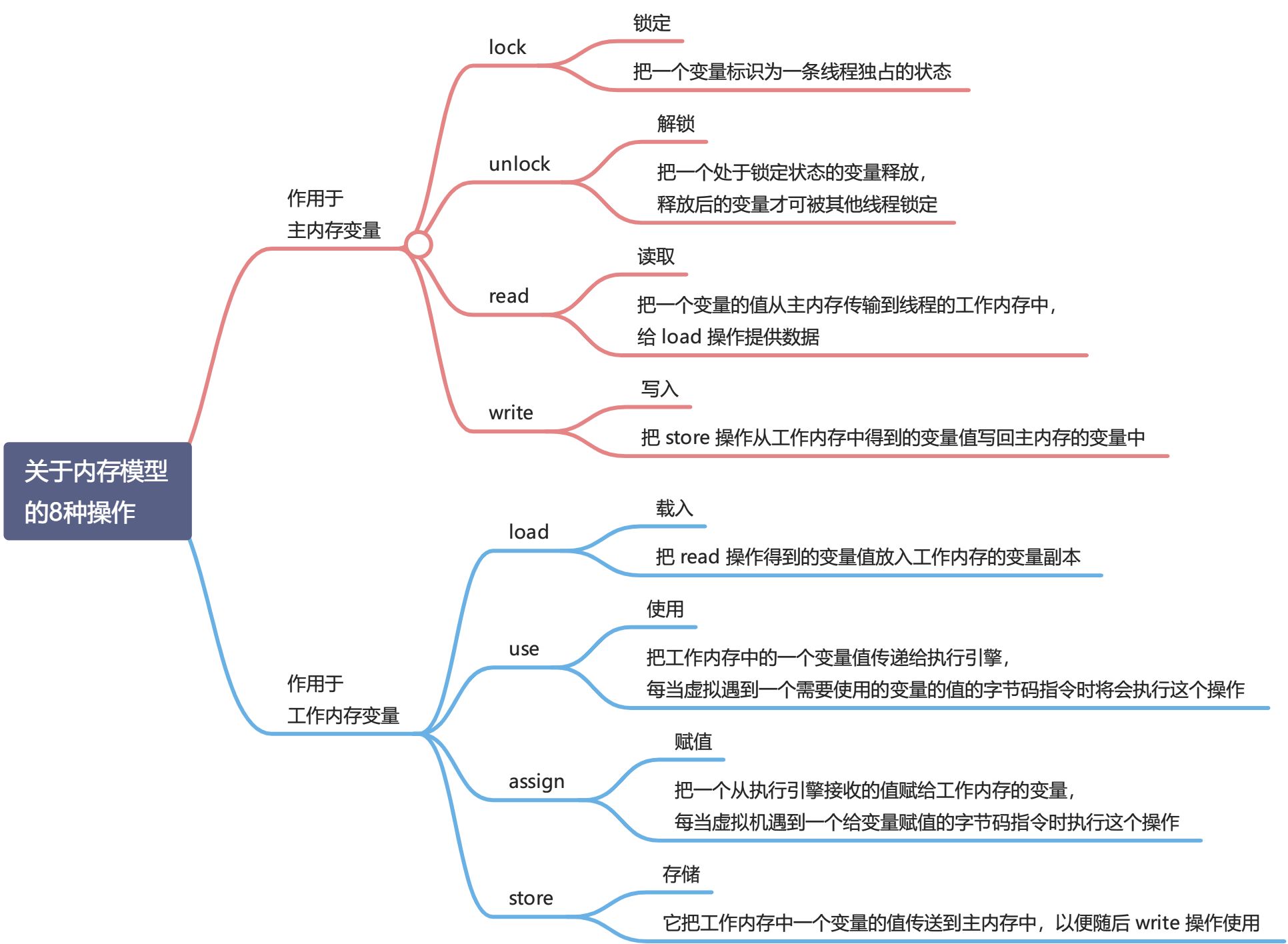 有几条规则值得注意一下:
有几条规则值得注意一下:一个变量在同一时刻只允许一条线程对其进行
lock操作。- 如果对一个变量执行
lock操作,那将会清空工作内存中此变量的值。在执行引擎使用这个变量前,需要重新对执行load或assign以初始化变量的值。 - 对一个变量执行
unlock操作之前,必须先把此变量同步回主内存中。
当一个变量被定义成 volatile 之后,它将具备两项特性:
- 保证此变量对所有线程的可见性。新值对其他线程来说是立即得知的。
- 禁止指令重排序优化。指令排序时不能把后面的指令重排主观到内存屏障之前的位置,只有一个处理器访问内存时,并不需要内存屏障,但如果有两个或更多处理器访问同一块内存且需要进行内存同步的话,就需要靠内存屏障来保障一致性了。
volatile 底层实现是通过 lock 关键字完成。
lock 的作用是将本处理器的缓存写入内存,写入动作会触发别的处理器或别的内核无效化(Invalidate)其缓存,相当于对缓存中的变量做了一次 store 和 write 操作。这样就能保证其他处理器立即可见。
- 每当线程使用变量之前都必须先从主内存获取该变量的最新值(进行一次刷新动作)。use 需要和 load、read 关联。
- 每当线程修改变量后都必须立刻写回主内存中,保证其他线程可以看到线程对变量的修改。assign 需要和 store、write 关联。
JMM 采取保守策略实现 volatile 禁止指令重排:
- 在每个 volatile 写操作的前面插入一个 StoreStore 屏障 。
- 在每个 volatile 写操作的后面插入一个 StoreLoad 屏障 。
- 在每个 volatile 读操作的后面插入一个 LoadLoad 屏障 。
- 在每个 volatile 读操作的后面插入一个 LoadStore 屏障。
内存屏障
内存屏障将前面 8 个指令精简为 4个,详情如下:
| 屏障类型 | 指令示例 | 说明 |
|---|---|---|
| LoadLoad | Load1;LoadLoad;Load2 | 该屏障确保Load1数据的装载先于Load2及其后所有装载指令的的操作 |
| StoreStore | Store1;StoreStore;Store2 | 该屏障确保Store1立刻刷新数据到内存(使其对其他处理器可见)的操作先于Store2及其后所有存储指令的操作 |
| LoadStore | Load1;LoadStore;Store2 | 确保Load1的数据装载先于Store2及其后所有的存储指令刷新数据到内存的操作 |
| StoreLoad | Store1;StoreLoad;Load2 | 该屏障确保Store1立刻刷新数据到内存的操作先于Load2及其后所有装载装载指令的操作。它会使该屏障之前的所有内存访问指令(存储指令和访问指令)完成之后,才执行该屏障之后的内存访问指令 |
 和
和  ,以及共享变量
,以及共享变量  ,出现下面情况:
,出现下面情况:- 线程
 在时刻
在时刻  对变量
对变量  有个写操作。
有个写操作。 - 线程
 在时刻
在时刻  对变量
对变量  有个读操作。
有个读操作。 - 且读写操作没有被同步排序。
当上述情况发生时,称之为存在数据争用(data race)。当代码出现数据争用时,
Happens-Before
要想保证线程  在时刻
在时刻  对变量
对变量  操作的结果被线程
操作的结果被线程  看到,那么这两个存在冲突访问(conflicting access)动作必须被 Happens-Before 关系排序。如果两个动作之间缺乏 Happens-Before 关系,那么 JVM 可以对它们任意地重排序。
看到,那么这两个存在冲突访问(conflicting access)动作必须被 Happens-Before 关系排序。如果两个动作之间缺乏 Happens-Before 关系,那么 JVM 可以对它们任意地重排序。
Happens-Before 顺序包括:
- 某个线程中的每个动作都 happens-before 该线程中该动作后面的动作。
- 某个管程上的 unlock 动作 happens-before 同一个管程上后续的 lock 动作。
- 对某个 volatile 字段的写操作 happens-before 每个后续对该 volatile 字段的读操作。
- 在某个线程对象上调用 start() 方法 happens-before 该启动了的线程中的任意动作。
- 某个线程中的所有动作 happens-before 任意其它线程成功从该线程对象上的 join() 中返回。
- 如果某个动作 a happens-before 动作 b,且 b happens-before 动作 c,则有 a happens-before c.
有了以上知识的铺垫,我们再看 tryPushStack 这个方法:
final boolean tryPushStack(Completion c) {
// #1 获取栈对象
Completion h = stack;
// #2 先将旧的头结点添加到对象c.next
lazySetNext(c, h);
// #3 通过CAS设置「stack」的引用为c,有可能设置失败
return UNSAFE.compareAndSwapObject(this, STACK, h, c);
}
其实使用 volatile 变量也挺消耗 CPU 的,因为它需要在工作内存和主内存进行同步。而步骤 2 方法能降低延迟:实现非阻塞写入。因为它能使用 storestore 屏障,而不是全屏障(Full Barrier)storeload。因此,能提升部分性能。
源码解析
说实话,我并未能完全理解 CompletableFuture 源码,我只能是通过网上博客和不断 DEBUG 找到某一条线索,也仅仅是一条,如果 Doug Lea 大神在我旁边一行行指导我该多好呀! CompletableFuture 可算做一个小的异步任务执行框架,适用于大多数的场景,所以有些语言文字描述不清楚或不准确,请大家多多包含和理解。
接下来,我们会通过一个异步任务尝试理解 CompletableFuture 内部执行流程。
Demo
public static void nest2() throws Exception {
CompletableFuture<String> s0 = CompletableFuture.supplyAsync(() -> {
sleep(3); // #1
return "s0->";
});
CompletableFuture<String> s1 = s0.thenApply(s -> s + "s1->");
CompletableFuture<String> s2 = s0.thenApply(s -> s + "s2->");
CompletableFuture<String> s3 = s1.thenApply(s -> s + "s3");
CompletableFuture<String> s4 = s2.thenApply(s -> s + "s4");
CompletableFuture<String> s5 = s1.thenApply(s -> s + "s5");
System.out.println("S5: " + s3.get());
System.out.println("S5: " + s5.get());
System.out.println("S4: " + s4.get());
}
// OUTPUT
// S5: s0->s1->s3
// S5: s0->s1->s5
// S4: s0->s2->s4
这个示例比较简单,其实就是一个字符串拼接。任务拆分步骤如下图所示,一对比就很清楚了。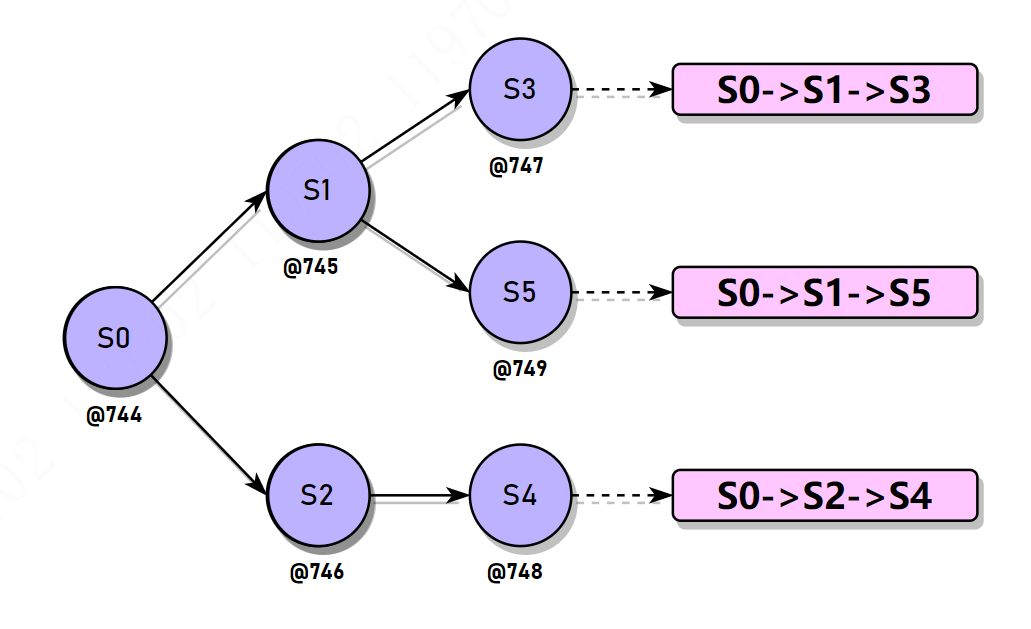
图 1
在 #1 这一步让线程休眠 3S 目的是主线程调用 CompletableFuture#get 方法时异步任务还未执行完成,这样就能更好的 DEBUG。如下图所示:
图 2
任务 S0~S5 的状态和依赖数清晰可见,此刻它们都还未完成,因为 #1 存在的关系,所以后续的依赖任务都得等待 S0 完成之后才能被触发执行。
执行流程概述
程序从上向下执行,通过不同的语义组成不同的逻辑。图 1 展示所构建的任务依赖图,S0 存在两个依赖任务,分别是 S1 和 S2,从图 2 的 DEBUG 中也能看出 2 dependents 信息。S1 也有两个依赖任务,分别是 S3 和 S4。S2 只有一个依赖任务 S4。当我们调用 s3.get() 方法后(主线程 main 调用,简称 ),由于 S0 是异步任务且线程处于休眠状态,所以此刻暂时无法得到结果,线程  会在
会在 for 循环中不断判断 S3 结果是否为空。为了性能,它会尝试一定次数,默认是 512。当超出默认的自旋次数后,如果还不能得到结果,则会创建一个 Signaller 对象压入 S3 对象的栈中,随后线程  阻塞。Signaller 也可以看成是一个唤醒任务,它依赖 S3 任务的完成。当 S3 任务完成会依次弹出自己栈中的任务,当遇到 Signaller 任务时,就会唤醒线程
阻塞。Signaller 也可以看成是一个唤醒任务,它依赖 S3 任务的完成。当 S3 任务完成会依次弹出自己栈中的任务,当遇到 Signaller 任务时,就会唤醒线程  ,这样就能得到结果啦。
,这样就能得到结果啦。
其实,看我的描述看起来并不复杂,任务之间的依赖关系确定他们的执行顺序。Doug Lea 使用并发栈保存将要被触发执行的依赖任务,比如对 S0 来说,它有两个依赖任务 S1 和 S2,它会把 S1 和 S2 使用特定的 Completion 抽象类的实例对象包装然后放入自己的栈中,等到任务执行完成后,依次出栈并触发依赖任务的执行。
对 Demo 示例而言,它的执行顺序示意图如下所示:
左上角表示执行顺序,@744、@746 等是和图 2 一一对应的。下面通过解读源码配合上面的图对 CompletableFuture 做一个简单的描述。
首先,我们通过 supplyAsync() 创建一个异步任务,这个任务会让线程休眠 3S 的时候,然后返回一个 S0-> 字符串。
CompletableFuture<String> s0 = CompletableFuture.supplyAsync(() -> {
sleep(3); // #1
return "s0->";
});
supplyAsync() 方法会创建一个AsyncSupply 实例,然后调用 Executor#execute 异步执行。这里涉及到一个 Executor 对象,如果用户没有指定 Executor 对象,则 CompletableFuture 默认使用 ForkJoinPool.commonPool() 返回的 Executor 执行任务。相关源码如下:
// java.util.concurrent.CompletableFuture#asyncSupplyStage
/**
* 异步执行任务
* @param e 异步执行器
* @param f 任务处理函数f
*/
static <U> CompletableFuture<U> asyncSupplyStage(Executor e,
Supplier<U> f) {
if (f == null) throw new NullPointerException();
// #1 创建一个新的「CompletableFuture」对象用来存储当前任务函数f的处理结果以及相关流程信息
CompletableFuture<U> d = new CompletableFuture<U>();
// #2 使用「AsyncSupply」封装结果收集器和任务处理函数
// 随后调用 execute() 方法执行
e.execute(new AsyncSupply<U>(d, f));
// #3 返回CompletableFuture对象,可以从这个对象获取本次任务函数f的处理结果
return d;
}
// 判断是否使用公用的 Executor 执行任务
private static final Executor asyncPool = useCommonPool ?
ForkJoinPool.commonPool() : new ThreadPerTaskExecutor();
前面我们并没有介绍 AsyncSupply 这个类。其实,理解它也十分简单:
// java.util.concurrent.CompletableFuture.AsyncSupply
/**
* 这里一个包装类,对异步任务进行包装。
* 一个异步任务是由「CompletableFuture」和「Suppiler」函数两部分构成的。
* 调用 run() 方法能执行函数fn并得到结果更新到「CompletableFuture」对象中,
* 然后调用 postComplete() 方法触发等到当前任务执行完后的所有后置任务的行。
*/
static final class AsyncSupply<T> extends ForkJoinTask<Void>
implements Runnable, AsynchronousCompletionTask {
CompletableFuture<T> dep; // 依赖任务
Supplier<T> fn; // 任务函数,是一个函数式接口,
// 它会返回一个 T 类型的对象。简单理解为生产者
/**
* 创建一个「AsyncSupply」对象,该对象包含一个功能函数fn
* 和任务执行结果CompletableFuture对象
* @param dep
* @param fn
*/
AsyncSupply(CompletableFuture<T> dep, Supplier<T> fn) {
this.dep = dep;
this.fn = fn;
}
public final Void getRawResult() {
return null;
}
public final void setRawResult(Void v) {}
public final boolean exec() {
run();
return true;
}
// 核心方法
public void run() {
CompletableFuture<T> d;
Supplier<T> f;
if ((d = dep) != null && (f = fn) != null) {
dep = null;
fn = null;
// 判断当前节点任务是否已经有结果
if (d.result == null) {
try {
// 调用 Supplier#get() 方法获取结果
d.completeValue(f.get());
} catch (Throwable ex) {
// 出现异常,包装异常
d.completeThrowable(ex);
}
}
// 触发执行本次任务的后置任务
d.postComplete();
}
}
}
其实内部也十分简单,核心方法为 run() 方法,主要流程也是我们前面所讲过的。最终还是调用 Supplier#get 获取结果并将结果赋值给 CompletableFuture 对象。这样,后续依赖 S0 的任务就可以通过 CompletableFuture 对象判断并获取结果了。
CompletableFuture<String> s1 = s0.thenApply(s -> s + "s1->");
then 表示然后的意思,顾名思义就是任务 S1 需要在任务 S0 执行完之后执行,因为 S1 需要 S0 的结果,因此,对应的函数式接口应该为 Function。CompletableFuture 内部维护一个并发栈,就是用来存储这些依赖任务的。
// java.util.concurrent.CompletableFuture#thenApply
public <U> CompletableFuture<U> thenApply(Function<? super T,? extends U> fn) {
// 注意,这里第一个参数为null,
// 表示相对于任务this来说新任务同步执行。任务间产生依赖关系
return uniApplyStage(null, fn);
}
uniApplyStage
// java.util.concurrent.CompletableFuture#uniApplyStage
/**
* ① 尝试执行任务,如果所依赖的任务执行完成,这此任务会被执行
* ② 如果所依赖的任务没有执行完成,则会包装 UniApply 对象放入所依赖任务的栈中,
* 等待弹出并回调相关方法
* ③ 返回的CompletableFuture对象表示新任务
*/
private <V> CompletableFuture<V> uniApplyStage(
Executor e,
Function<? super T,? extends V> f) {
if (f == null) throw new NullPointerException();
// #1 创建一个新的CompletableFuture用来包装当前的任务
CompletableFuture<V> d = new CompletableFuture<V>();
// #2 如果所依赖的任务执行完成,则当前任务也可以接着执行
// 否则会包装为一个「UniApply」对象并放入所依赖的任务栈中
// ① 如果e!=null,说明任务d需要异步执行,因此就跳过后面的 d.uniApply
// ② 如果e==null,说明任务d需要同步执行,因此需要尝试执行一下 d.uniApply
// 如果d依赖的任务this的Executor不为空,说明任务this是异步任务,所以后续的依赖任务
// 也异步执行
if (e != null || !d.uniApply(this, f, null)) {
// 针对异步和同步任务
// ① 如果任务d是异步任务,此刻无法判断它的前序任务是否已执行完成,所以需要入栈
// ② 如果任务d是同步任务,此刻前序任务确定没有执行完成,所以需要入栈
UniApply<T,V> c = new UniApply<T,V>(e, d, this, f);
// 入栈(注意:这里是添加到「当前任务」所依赖的任务的栈中,
// 这样当依赖的任务完成后就可以触发当前任务执行了)
push(c);
// 主动尝试触发任务d执行,
// 因为在入栈的过程中可能前序任务已经执行完成了,如果不主动触发,则
// 栈内任务可能永远也无法执行
// 模式为 SYNC
c.tryFire(SYNC);
}
// #3 返回新的「CompletableFuture」
return d;
}
首先,我们需要明确一点,如果任务 A 本身是异步任务,任务 B 是同步依赖任务 A,那么 uniApplyStage 中的 Executor 参数为 null。
我们对 uniapplyStage 源码做一下总结:
- 如果任务 B 的 Executor != null,表明任务 B 相对任务 A 是异步任务,需要异步执行。那么会直接将任务 B 封装为 UniApply(具体操作封装的对象不一样)并加入任务 A 的栈中。但任务 B 会主动触发执行,万一在入栈过程中刚好任务 A 执行完毕了呢。
- 如果任务 B 的 Executor == null,表明任务 B 相对任务 A 是同步任务,需要同步执行。则:
- 先尝试执行 uniApply 方法。万一成功了呢? 注意,此刻方法
uniApply(this, f, null)中第三个参数为 null,因为此时我们确认任务 B 是同步执行,所以该参数为 null,如果不确认,则需要传递 UniApply 对象。方法 uniApply 会先判断任务 B 的结果是否为空,如果为空,则直接返回 false,如果不为空,则会执行任务 B 并取得结果。 - 如果 uniApply 方法返回 false,会有两种情况出现:
- 任务 A 未执行完。
- 任务 A 已执行完且第三个参数不为 null(UniApply == null)且当前线程对任务 A 宣誓主权失败(宣誓执行权)。
- 先尝试执行 uniApply 方法。万一成功了呢? 注意,此刻方法
- 将任务 A 包装为 UniApply 对象并入栈的情况在源码中已经进行说明了。
入栈之后还会调用
tryFire(SYNC)尝试执行。这里 mode=SYNC,表示同步执行,这样接下来调用 uniApply 方法时第三个参数会为 null,表示线程不会对任务重新宣誓主权,因为我们确定他们是同步顺序执行的。uniApply
// java.util.concurrent.CompletableFuture#uniApply /** * 触发任务执行 * @param a 上一步任务 * @param f 函数 * @param c UniApply 对象 * @return */ final <S> boolean uniApply(CompletableFuture<S> a, Function<? super S,? extends T> f, UniApply<S,T> c) { Object r; // 依赖任务a的结果 Throwable x; // 依赖任务a可能抛出的异常 // #1 依赖任务a还未产生结果,直接返回false if (a == null || (r = a.result) == null || f == null) return false; // #2 依赖任务a已经产生结果 tryComplete: if (result == null) { if (r instanceof AltResult) { // 处理异常 if ((x = ((AltResult)r).ex) != null) { // 存在异常,使用AltResult包装并放入当前对象的result // 直接返回,并不会直接下面的操作 completeThrowable(x, r); break tryComplete; } // 无异常抛出,返回值为null r = null; } try { // #3 当前线程对任务c宣誓主权。如果任务c设置标志成功 // 且不包含Executor,则返回true,宣誓成功。其他情况返回 false, // 返回false表示要么它心有所属(有Executor,其他线程会执行),要么设置标志失败 // 该任务已经被其他线程设置过了,该标志可以避免任务重复执行 if (c != null && !c.claim()) // #4 宣誓失败,则让它所属的Executor执行吧(异步任务) return false; @SuppressWarnings("unchecked") S s = (S) r; // #5 宣誓成功,则调用Function#apply 获得值 // 并更新结果 result completeValue(f.apply(s)); } catch (Throwable ex) { // #6 有异常抛出,则更新为异常值 completeThrowable(ex); } } return true; }方法
uniApply其实就是根据任务 a 的结果是否为 null 而进一步执行后续步骤,它返回一个布尔值,true 表示任务 B 尝试执行成功,false 表示任务 A 尝试执行失败。若任务 A 还未执行完成,result==null 成立,则直接返回 false。
- 若任务 A 结果不为空:
- 任务 A 出现异常,则将异常设置为任务 B 的结果,不需要执行任务 B 的逻辑。
- 任务 A 返回正常,则根据参数 c 判断:
c != null,当前任务尝试对 c 宣誓执行权,其实就是判断对象 C (封装任务 B)中的 Executor 是否为空,如果不为空,表示任务 B 异步执行,返回 false。c == null,则回调任务 B 函数接口,并将结果写入 result 对象中,返回 true。
当返回 false 时我们需要入栈然后再尝试触发执行,因为在入栈的过程中可能任务刚好执行完成,这会出现一个真空期,而主动调用 tryFire 则是解决这个问题。
tryFire
tryFire 这个方法是由 Completion 抽象类所定义的:
/**
* Performs completion action if triggered, returning a
* dependent that may need propagation, if one exists.
*
* @param mode SYNC, ASYNC, or NESTED
*/
abstract CompletableFuture<?> tryFire(int mode);
这个方法会再次尝试执行任务,我们看看 UniApply 类的实现逻辑吧。
// java.util.concurrent.CompletableFuture.UniApply
static final class UniApply<T,V> extends UniCompletion<T,V> {
// 任务函数fn
Function<? super T,? extends V> fn;
/**
* @param executor 任务函数执行器
* @param dep 后置任务
* @param src 前置依赖任务
* @param fn 任务函数
*/
UniApply(Executor executor,
CompletableFuture<V> dep,
CompletableFuture<T> src,
Function<? super T,? extends V> fn) {
super(executor, dep, src); this.fn = fn;
}
/**
* 尝试触发执行任务函数fn
*/
final CompletableFuture<V> tryFire(int mode) {
CompletableFuture<V> d; // 依赖任务
CompletableFuture<T> a; // 前序任务
if ((d = dep) == null ||
// 仅当mode为嵌套模式时才传入this对象
!d.uniApply(a = src, fn, mode > 0 ? null : this))
return null;
// 尝试执行成功,会重置相关信息,表明当前任务已经执行完成
dep = null;
src = null;
fn = null;
// 尝试执行成功,表明任务a已经执行成功了
return d.postFire(a, mode);
}
}
UniApply 是 UniCompletion 抽象类的实现类,内部创建一个 Function 的函数式接口引用。重要的是 tryFire 方法:
- 如果 dep==null 成立,直接会返回 null。表明当前任务已执行成功。
- 如果 dep != null 不成立,然后调用
uniApply方法尝试执行。方法 uniApply 前面已经讲过了,这里需要注意 mode 这个选项。如果 mode 为嵌套模式的话,则会传入 this。后续会对 this 进行宣誓,宣誓失败则返回 false,并异步触发任务 this 执行。如果 this 没有包含 Executor,则会同步执行。 如果尝试执行成功,则会调用 postFire 触发后续任务执行。
postFire
// java.util.concurrent.CompletableFuture#postFire static final int SYNC = 0; // 同步 static final int ASYNC = 1; // 异步 static final int NESTED = -1; // 嵌套 /** * 当 UniCompleion#tryFire 方法调用完毕后 * ① 此方法会被依赖者调用。 * ② 会尝试清理前序任务对象a的栈空间。 * ③ 可能会返回本身或运行 postComplete,这取决于参数 mode * * @param a this所依赖的任务 * @param mode 模式 */ final CompletableFuture<T> postFire(CompletableFuture<?> a, int mode) { // #1 前序任务栈不为空 if (a != null && a.stack != null) { if (mode < 0 || a.result == null) // 在嵌套模式或结果集为空的情况下 // 只需要清理栈即可,通过isLive() 方法判断 // 在嵌套模式下 a.cleanStack(); else // 非嵌套模式且结果集不为空,表明已经完成函数调用, // 需要触发执行任务a的所有后置依赖 a.postComplete(); } // #2 当前任务this已经产生结果,触发执行this的所有后置依赖 if (result != null && stack != null) { if (mode < 0) // 在嵌套模式下,返回自身, // 这一步目的是重置指针指向this,而后开始依次出栈触发任务执行 return this; else // 非嵌套模式下(同步、异步), // 则直接触发后置依赖节点执行 postComplete(); } // 其他情况,返回null。比如: // 有结果,但是栈为空,表明已经走到头了 return null; }postFire 方法还是比较复杂的,它会对依赖任务 A 和当前任务做一些后置处理,这取决于 mode 和任务 A 的结果状态:
清理任务 A 的栈。
- 触发执行任务 A 的后置任务。
-
postComplete
// java.util.concurrent.CompletableFuture#postComplete /** * 递归执行其他依赖当前阶段的其他后序任务 * 使用「while+栈」模拟递归操作 */ final void postComplete() { /* * 在每一步,变量f持有当前的依赖项,需要对这个依赖项弹出和执行。 * 每次只沿着单条路径进入扩展,这能避免无限递归。 * On each step, variable f holds current dependents to pop * and run. It is extended along only one path at a time, * pushing others to avoid unbounded recursion. */ // f表示当前已完成的任务,接下来是需要触发依赖f任务完成的其他任务 // 所依赖的f的 CompletableFuture<?> f = this; // h指向栈顶 Completion h; while ((h = f.stack) != null || // 栈顶元素不为空 (f != this && (h = (f = this).stack) != null)) { // 如果f的栈顶为空, // 重新回到this,继续下一条路径 CompletableFuture<?> d; Completion t; // 通过CAS更新链表指针(相当于出栈pop操作) // 此时h if (f.casStack(h, t = h.next)) { // next节点不为空,则继续 if (t != null) { // f != this,说明当前应该以f为基点进行出栈操作 if (f != this) { pushStack(h); continue; } h.next = null; // detach } f = (d = h.tryFire(NESTED)) == null ? this : d; } } }waitAndGet
// 默认值:256 private static final int SPINS = (Runtime.getRuntime().availableProcessors() > 1 ? 1 << 8 : 0); // java.util.concurrent.CompletableFuture#waitingGet /** * * @param interruptible 是否允许被中断 */ private Object waitingGet(boolean interruptible) { Signaller q = null; boolean queued = false; int spins = -1; Object r; while ((r = result) == null) { // 首次更新spins的值 if (spins < 0) spins = SPINS; else if (spins > 0) { // 根据随机数是否>=0决定减少spins次数 if (ThreadLocalRandom.nextSecondarySeed() >= 0) --spins; } // 只有当 spins=0时才会进入下面这些判断 else if (q == null) // 创建一个通知者 q = new Signaller(interruptible, 0L, 0L); else if (!queued) // 将通知者入栈 queued = tryPushStack(q); else if (interruptible && q.interruptControl < 0) { // interruptible=true且当前执行线程已经被中断 // 清除引用,加速GC q.thread = null; // 清理栈 cleanStack(); // 返回null值 return null; } else if (q.thread != null && result == null) { // 自旋超过最大次数,只能阻塞线程了 try { // 阻塞等待 ForkJoinPool.managedBlock(q); } catch (InterruptedException ie) { // 线程被中断了 q.interruptControl = -1; } } } // result 存在结果 if (q != null) { // 清除引用,加速GC q.thread = null; // 判断是否被中断过 if (q.interruptControl < 0) { if (interruptible) // 如果支持中断,且已中断,则返回null r = null; else // 不支持中断,则设置线程的中断标志位 Thread.currentThread().interrupt(); } } // 递归触发执行其他依赖当前阶段的后序任务 postComplete(); // null:支持中断且被中断过。否则返回其他结果 return r; }总结
关于 CompletionFuture 的解析就暂告一段落了,里面的源码讲解并不是特别清楚。
JUC框架 CompletableFuture源码解析 JDK8
Java并发包异步执行器CompletableFuture

若有收获,就点个赞吧
0 人点赞
