概述
这是我们解读 Netty 内存管理的第三篇文章,前面两篇重点介绍了 ByteBuf 对象以及内存的分配和管理。比如利用分治思想创建多个 PoolArena 提供内存分配的能力、使用满二叉树数据结构管理内存的分配和回收等。但还有一个重要的东西我们没有讲,就是 jemalloc 从 tcmalloc 借鉴的本地线程缓存思想,这一篇就结合源码讲解 Netty 是如何利用本地线程缓存进一步提升 Netty 内存分配效率。
内存分配入口
回顾与池化内存分配的入口对象 PooledByteBufAllocator,内部有一个和今天主题相关的变量 PoolThreadLocalCache threadCache,它继承 FastThreadLocal,属于本地线程缓存变量。每个线程都可以(这个说法不绝对,因为可以修改默认配置不使用缓存)从本地线程缓存变量中获取 PoolThreadCache 对象,这个对象才是每个线程真正缓存内存的地方。具体关系图简单描述如下: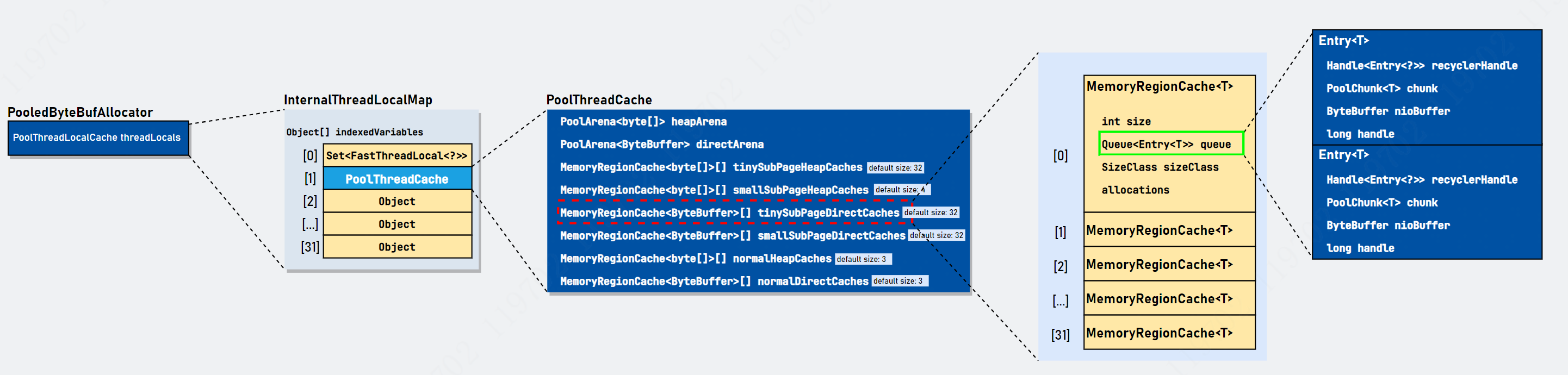
PooledByteBufAllocator 持有 PoolThreadLocalCache(功能和 ThreadLocal 相同,详见 Netty源码之FastThreadLocalThread)对象,因此每个线程拥有属于属于自己的 PoolThreadCache(线程私有)。当我们需要申请内存时,首先从 PoolThreadCache 中尝试获取(根据规范值在对应数组中查找即可),如果 PoolThreadCache 对象存在适配的内存块,直接返回,没有才委托 PoolArena 进行内存分配操作。相当于在线程和 PoolArena 对象之间加了一道缓存,从而进一步提升内存分配的效率。
当线程用完某段内存块,它并不直接归还至 PoolChunk,而是使用 PoolThreadCache 缓存起来。那有人问,PoolThreadCache 会一直在缓存着 PoolChunk 分配给线程的内存块么? 这个你不用担心,PoolThreadCache 在分配次数(allocations)超过阈值(freeSweepAllocationThreshold,默认值: 8192)之后,就会触发释放内存动作,将多余的空闲内存归还给 PoolArena,正所谓: 有借有还,再借不难嘛。在阅读源码之前,我们先对用到的类进行了解。
认识相关的类
PoolThreadLocalCache
这个类继承 FastThreadLocal,查看这里了解更多关于FastThreadLocal。
内部有一个重要的初始化方法,它说明了一件事情: 每个线程只会绑定其中一个 PoolArena(具体分为 heapArena 和 directArena),在整个线程生命周期内只与这个 PoolArena 打交道。这也是 jemalloc 的算法思想(分而治之)的体现(可以提升多线程内存分配的性能)。找到特定的 PoolArena 还是有讲究的: 通过比对每个 PoolArena 绑定的线程数量,选择最小值的 PoolArena 和当前进行内存申请的线程进行绑定。具体源码如下: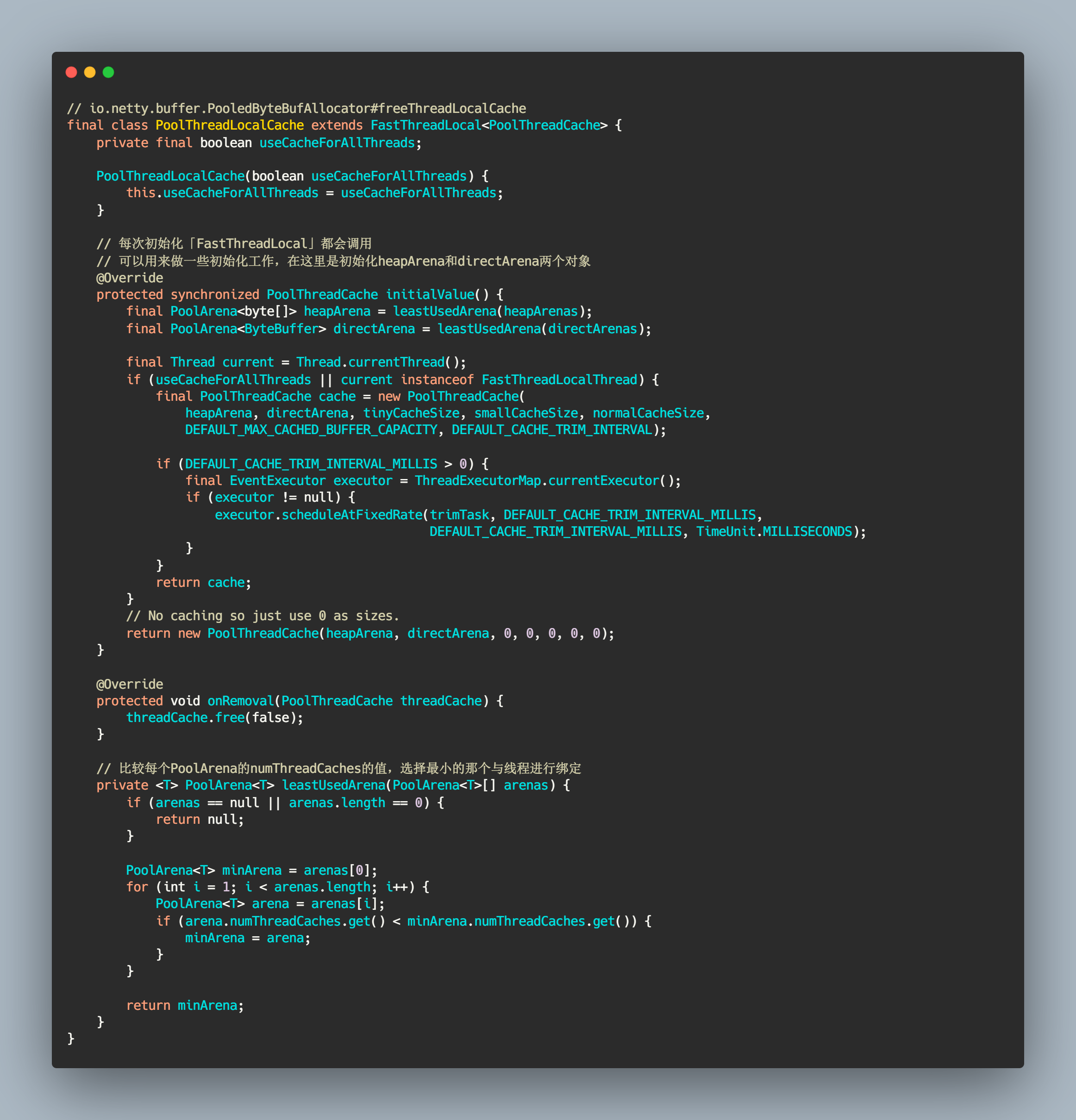
// io.netty.buffer.PooledByteBufAllocator#freeThreadLocalCachefinal class PoolThreadLocalCache extends FastThreadLocal<PoolThreadCache> {private final boolean useCacheForAllThreads;PoolThreadLocalCache(boolean useCacheForAllThreads) {this.useCacheForAllThreads = useCacheForAllThreads;}// 每次初始化「FastThreadLocal」都会调用// 可以用来做一些初始化工作,在这里是初始化heapArena和directArena两个对象@Overrideprotected synchronized PoolThreadCache initialValue() {final PoolArena<byte[]> heapArena = leastUsedArena(heapArenas);final PoolArena<ByteBuffer> directArena = leastUsedArena(directArenas);final Thread current = Thread.currentThread();if (useCacheForAllThreads || current instanceof FastThreadLocalThread) {final PoolThreadCache cache = new PoolThreadCache(heapArena, directArena, tinyCacheSize, smallCacheSize, normalCacheSize,DEFAULT_MAX_CACHED_BUFFER_CAPACITY, DEFAULT_CACHE_TRIM_INTERVAL);if (DEFAULT_CACHE_TRIM_INTERVAL_MILLIS > 0) {final EventExecutor executor = ThreadExecutorMap.currentExecutor();if (executor != null) {executor.scheduleAtFixedRate(trimTask, DEFAULT_CACHE_TRIM_INTERVAL_MILLIS,DEFAULT_CACHE_TRIM_INTERVAL_MILLIS, TimeUnit.MILLISECONDS);}}return cache;}// No caching so just use 0 as sizes.return new PoolThreadCache(heapArena, directArena, 0, 0, 0, 0, 0);}@Overrideprotected void onRemoval(PoolThreadCache threadCache) {threadCache.free(false);}// 比较每个PoolArena的numThreadCaches的值,选择最小的那个与线程进行绑定private <T> PoolArena<T> leastUsedArena(PoolArena<T>[] arenas) {if (arenas == null || arenas.length == 0) {return null;}PoolArena<T> minArena = arenas[0];for (int i = 1; i < arenas.length; i++) {PoolArena<T> arena = arenas[i];if (arena.numThreadCaches.get() < minArena.numThreadCaches.get()) {minArena = arena;}}return minArena;}}
PoolThreadLocalCache 的泛型是 PoolThreadCache 类型,因此可以通过 PoolThreadLocalCache#get() 获得 PoolThreadCache 对象,这个对象就是存放内存信息的地方。
PoolThreadCache
这个对象就是今天的重头戏了,它是缓存内存的核心类。相关变量我们已经在前面看过了,这里回顾一下: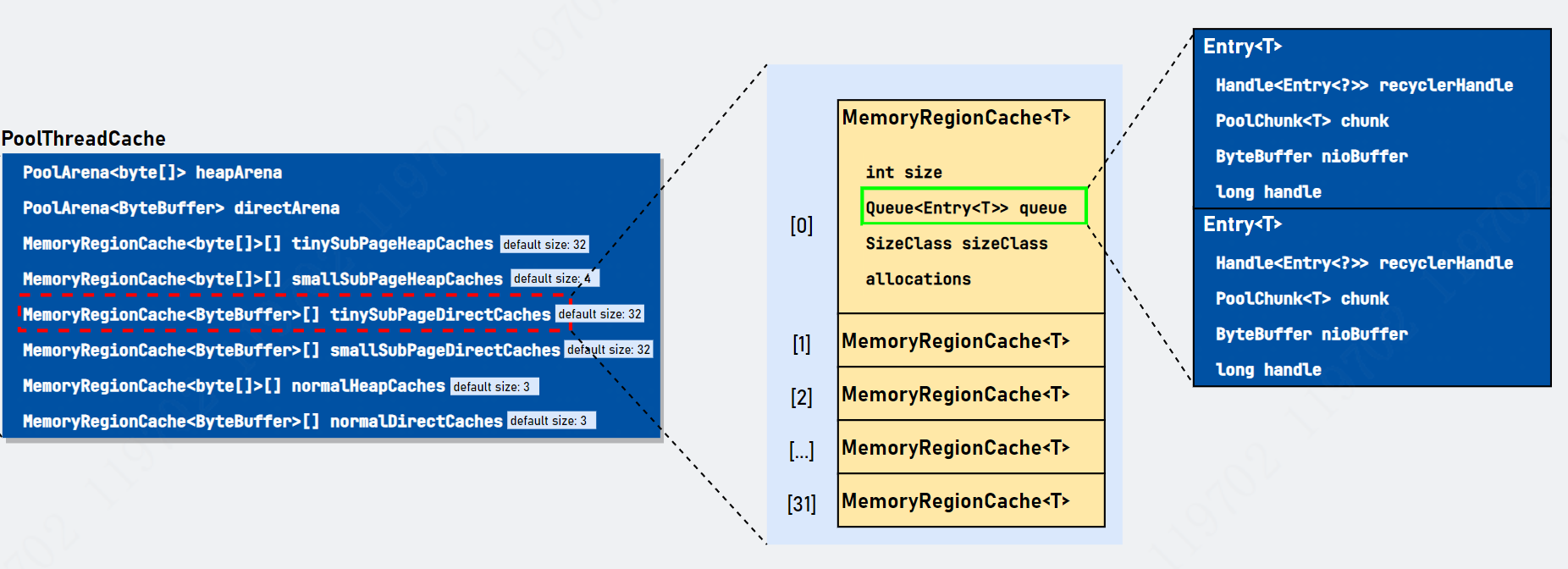
对相关变量进行解释:
heapArena 和 directArena 是在 PoolThreadLocalCache#initialValue() 初始化的,具体见上一节。剩余变量是这么分类的,一是根据数据容器类型分类: 存在两类数据容器,分别为 byte[] 和 ByteBuffer。二是根据内存规格分类,缓存tiny&small&normal级别内存,忽略 Huge。还有一个注意的点是 default size,我也在图中标注出来了,表示数组长度的默认大小,这些大小是依据什么呢? 先回顾下面的内存规格图(chunkSize 默认大小为 16MB):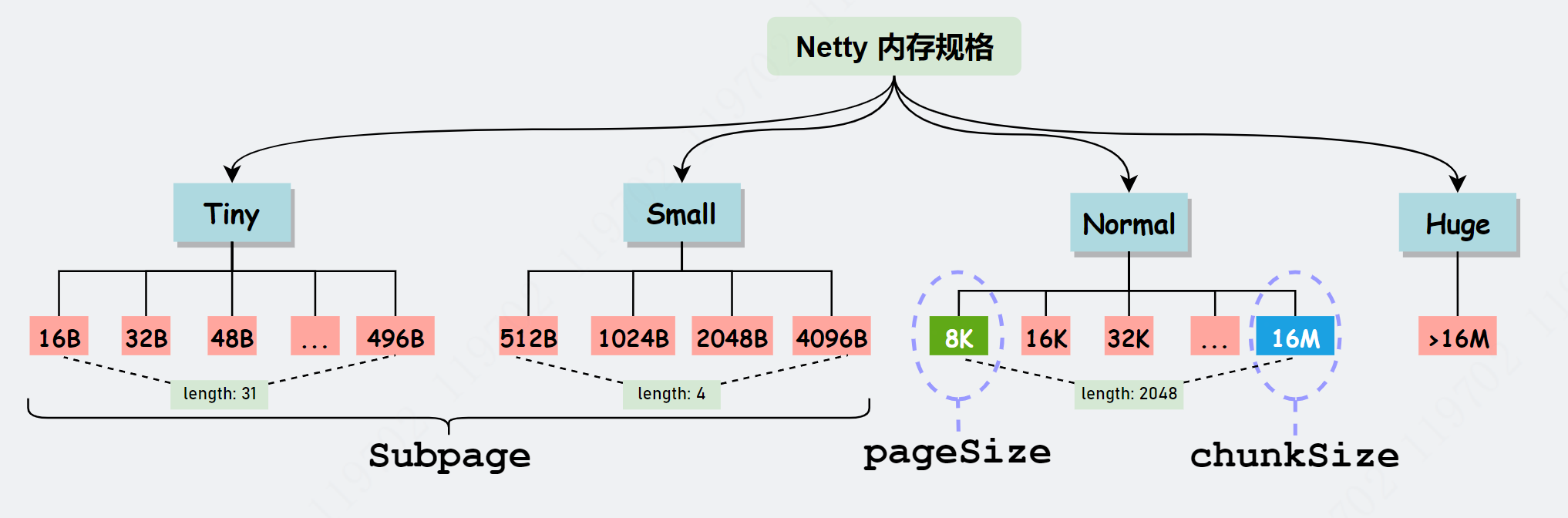
从上图可以看出,数组大小是和上面标注的 length 是一样的(Tiny 会多出 0,所以加在一起长度是 32),以上只是默认分配大小(ChunkSize默认大小为16MB,长度会根据ChunkSize大小不断变化,但一般不会被修改)。注意对于 Normal 级别数组长度只有 3,这是因为 PoolThreadLocalCache 只会缓存 8K、16KB 和 32KB 大小的内存块,而大于 32KB 的内存会直接归还给 PoolArena。下图是规格值和数组索引的对应关系图。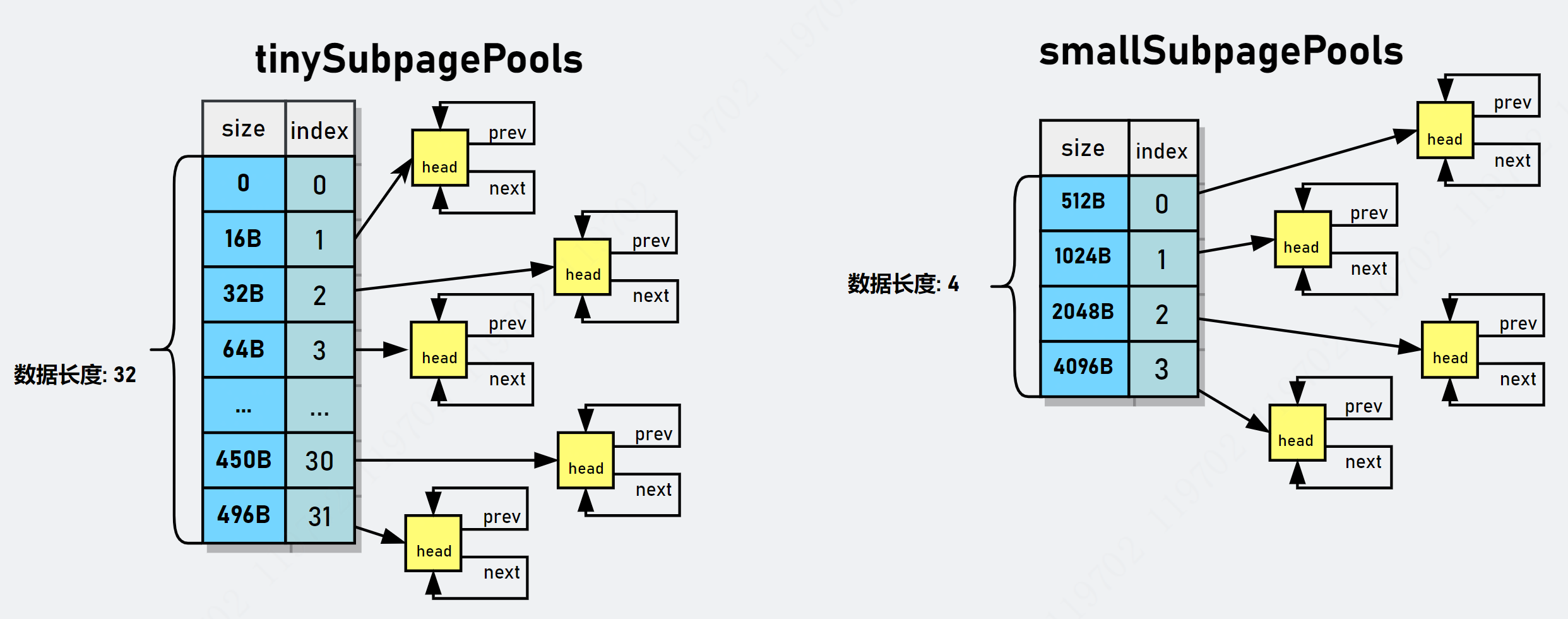
相关变量解析如下
// io.netty.buffer.PoolThreadCache/*** 本地缓存缓存缓存内存块信息对象*/final class PoolThreadCache {// 每一个线程都与一个「heapArena」和「directArena」对象绑定final PoolArena<byte[]> heapArena;final PoolArena<ByteBuffer> directArena;// 根据数据容器分类private final MemoryRegionCache<byte[]>[] tinySubPageHeapCaches;private final MemoryRegionCache<byte[]>[] smallSubPageHeapCaches;private final MemoryRegionCache<byte[]>[] normalHeapCaches;// 根据内存规则分类private final MemoryRegionCache<ByteBuffer>[] tinySubPageDirectCaches;private final MemoryRegionCache<ByteBuffer>[] smallSubPageDirectCaches;private final MemoryRegionCache<ByteBuffer>[] normalDirectCaches;// 用于计算偏移值private final int numShiftsNormalDirect;private final int numShiftsNormalHeap;// 触发释放部分内存块阈值private final int freeSweepAllocationThreshold;// 当前「PoolThreadCache」是否需要被释放private final AtomicBoolean freed = new AtomicBoolean();// 从本地线程缓存中分配的次数// 当超过freeSweepAllocationThreshold时会重置为0private int allocations;// ...}
PoolThreadCache 定义了缓存内存块的规则,其实和 PoolArena 类似,使用数组缓存内存信息,数组序号与内存块大小一一对应,这样就可以通过规格值直接找到对应的序号判断是否有可用内存块了。这里出现了一个 MemoryRegionCache 对象,不用想,肯定是记录内存块信息的包装类。下面详细解析。
MemoryRegionCache
MemoryRegionCache 是记录缓存内存信息的核心类。相关核心属性解释如下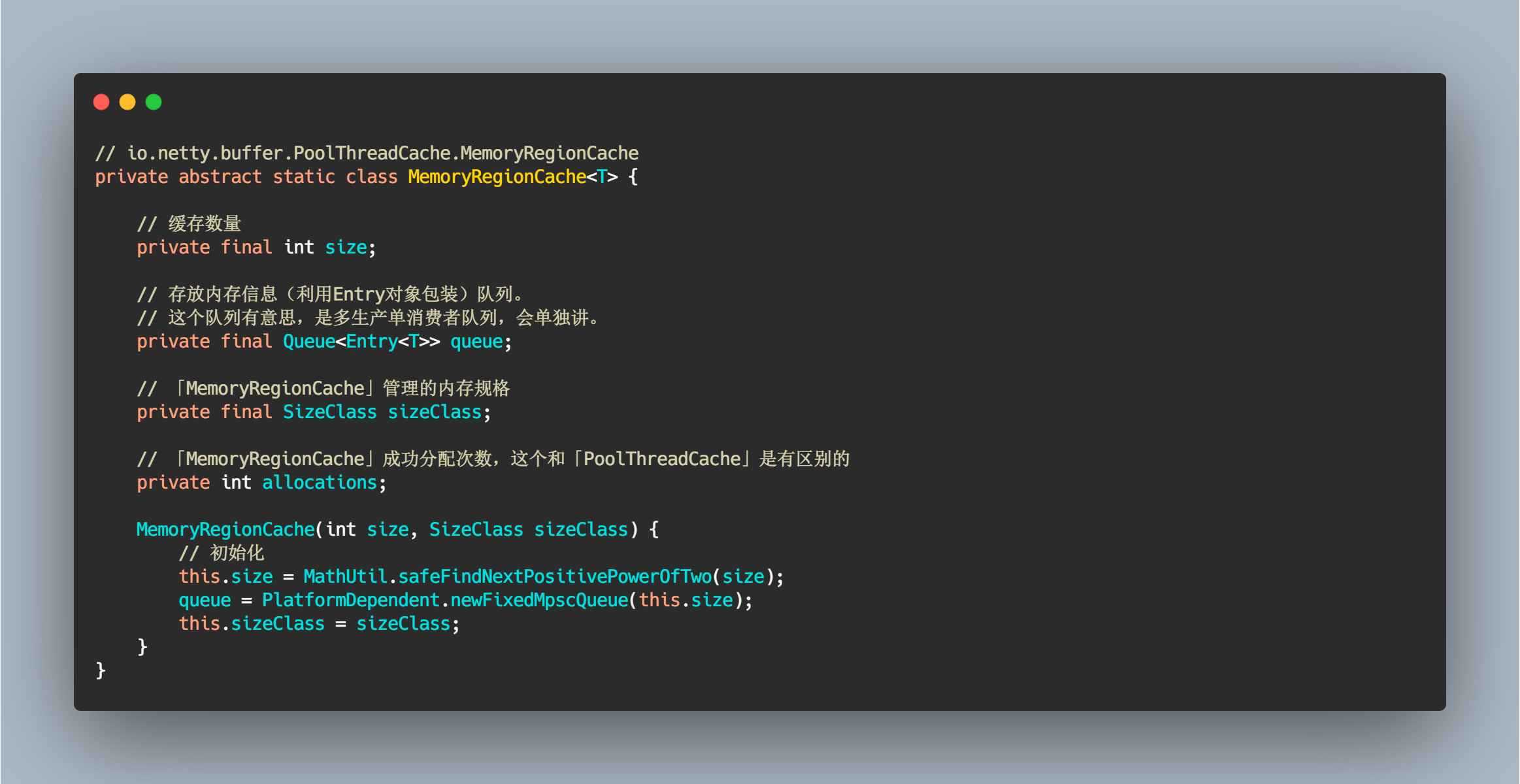
// io.netty.buffer.PoolThreadCache.MemoryRegionCacheprivate abstract static class MemoryRegionCache<T> {// 缓存数量private final int size;// 存放内存信息(利用Entry对象包装)队列。// 这个队列有意思,是多生产单消费者队列,会单独讲。private final Queue<Entry<T>> queue;// 「MemoryRegionCache」管理的内存规格private final SizeClass sizeClass;// 「MemoryRegionCache」成功分配次数,这个和「PoolThreadCache」是有区别的private int allocations;MemoryRegionCache(int size, SizeClass sizeClass) {// 初始化this.size = MathUtil.safeFindNextPositivePowerOfTwo(size);queue = PlatformDependent.newFixedMpscQueue(this.size);this.sizeClass = sizeClass;}}
内部的 Size 与内存规格值匹配,表示缓存队列的大小值。比如 Tiny 级别的 size 值为 512,Small 级别的 size 值为256(具体看 PooledByteBufAllocator cache size,可配置)。Queue<Entry<T>> 是来自 jctools 的多生产者单消费者队列,我们使用 Entry 对象封装内存信息( PoolChunk、nioBuffer 以及 handle 等信息)并放入 Queue 队列,待后续进行内存申请时可直接从队列弹出。allocations 记录着从 MemoryRegionCache 成功申请内存块的次数,这个 allocation 与 MemoryRegionCache 释放部分内存块相关。
本地线程回收内存块
当调用 ByteBuf#release() 会让引用计数 -1,当引用计数为 0 时就意味着该 ByteBuf 对象需要被回收,ByteBuf 对象进入对象池,ByteBuf 对象所管理的内存块进行内存池。但是 PoolThreadCache 内存内存块进入内存池之前截胡了,把待回收内存块放入本地线程缓存中,待后续本线程申请时使用。具体源码分析如下:
PoolArena#free
我们可以通过 DEBUG 来到 PoolArena#free,其他的调用方法省略。在调用 freeChunk() 方法之前会让 cache 进行回收。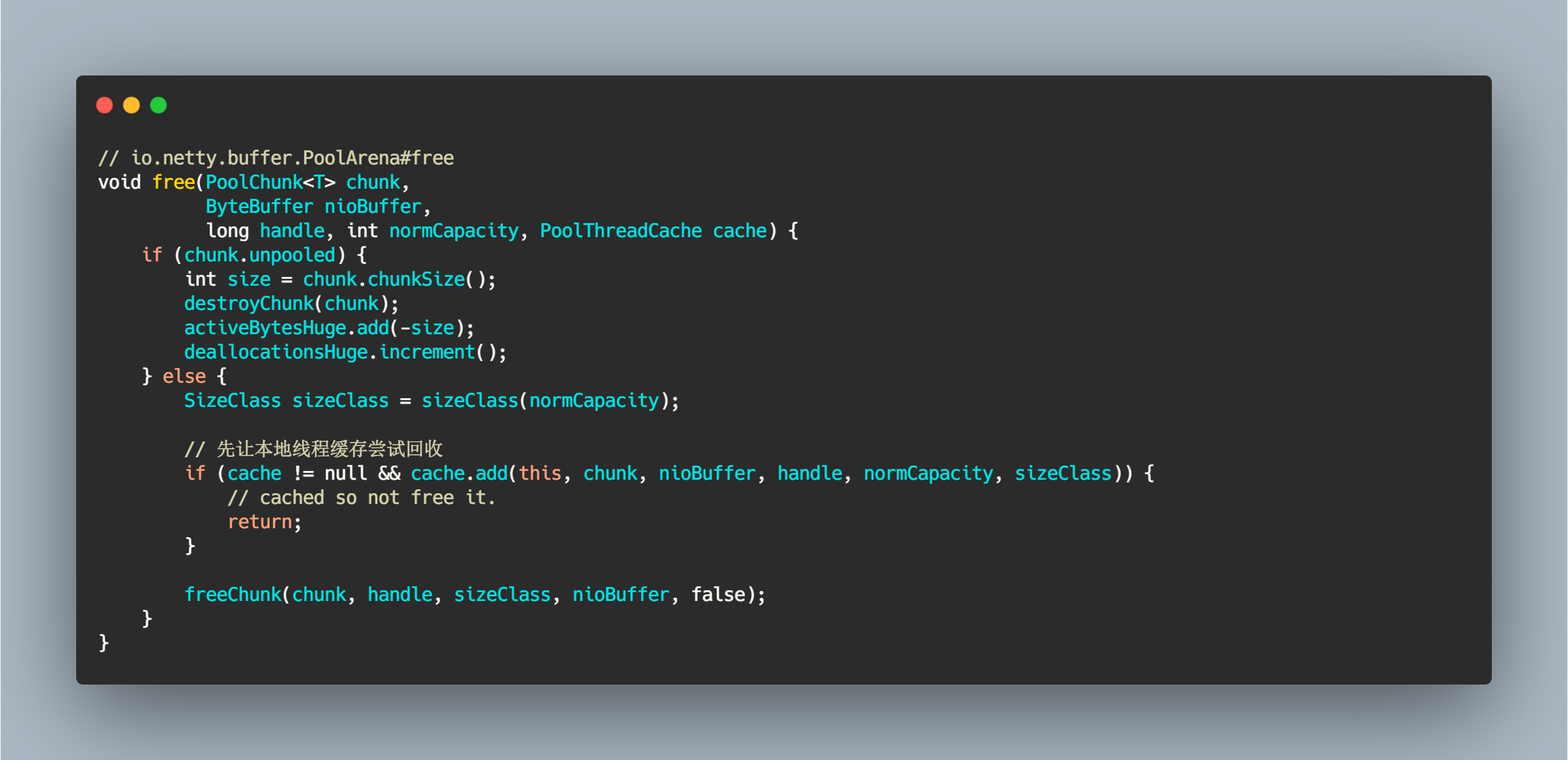
// io.netty.buffer.PoolArena#freevoid free(PoolChunk<T> chunk,ByteBuffer nioBuffer,long handle, int normCapacity, PoolThreadCache cache) {if (chunk.unpooled) {int size = chunk.chunkSize();destroyChunk(chunk);activeBytesHuge.add(-size);deallocationsHuge.increment();} else {SizeClass sizeClass = sizeClass(normCapacity);// 先让本地线程缓存尝试回收if (cache != null && cache.add(this, chunk, nioBuffer, handle, normCapacity, sizeClass)) {// cached so not free it.return;}freeChunk(chunk, handle, sizeClass, nioBuffer, false);}}
PoolThreadCache#add
PoolThreadCache 是本地缓存缓存变量,属于线程私有。方法 add() 尝试回收内存块,因为可能回收失败(比如容量超出),这个方法并没有做太多事情,就是根据规格值和规格类型确定 MemoryRegionCache 对象,如果匹配失败,可能容量超出不允许回收,这种类型的内存块只能通过 PoolChunk 回收了。
// io.netty.buffer.PoolThreadCache#add/*** 本地缓存回收内存块* @param area 当前内存块所属的「PoolArena」* @param chunk 当前内存块所属的「PoolChunk」* @param nioBuffer 当前内存块包装的「ByteBuffer」对象* @param handle 当前内存块句柄值* @param normCapacity 容量规格值* @param sizeClass 容量规格类型* @return true: 本地线程回收成功*/boolean add(PoolArena<?> area,PoolChunk chunk,ByteBuffer nioBuffer,long handle,int normCapacity,SizeClass sizeClass) {// #1 根据规格类型和规格值获取「MemoryRegionCache」对象MemoryRegionCache<?> cache = cache(area, normCapacity, sizeClass);// #2 没有适配的「MemoryRegionCache」请回if (cache == null) {return false;}// #3 回收缓存return cache.add(chunk, nioBuffer, handle);}// 根据规格类型和规格值获取「MemoryRegionCache」对象// io.netty.buffer.PoolThreadCache#cacheprivate MemoryRegionCache<?> cache(PoolArena<?> area, int normCapacity, SizeClass sizeClass) {switch (sizeClass) {case Normal:return cacheForNormal(area, normCapacity);case Small:return cacheForSmall(area, normCapacity);case Tiny:return cacheForTiny(area, normCapacity);default:throw new Error();}}
MemoryRegionCache#add
最终还是委托 MemoryRegionCache 把内存块信息添加到内部的 Queue 队列中。添加过程也是十分简洁,使用内部类 Entry 封装内存块信息,然后入队就完事了。当 Queue#offer() 方法添加失败时,需要立即回收 Entry 对象,可能会造成内存泄漏。Entry 对象使用对象池化技术。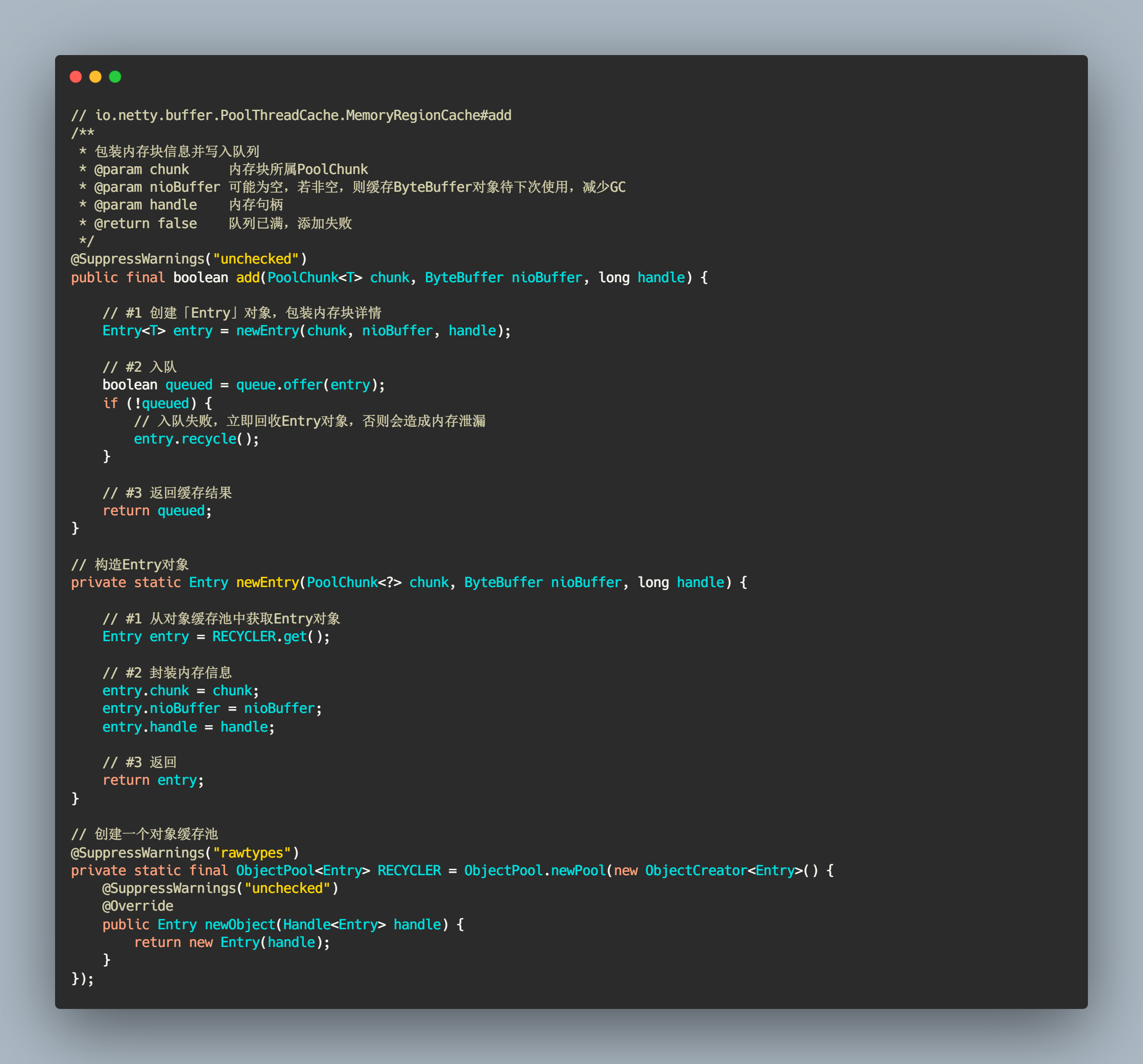
// io.netty.buffer.PoolThreadCache.MemoryRegionCache#add/*** 包装内存块信息并写入队列* @param chunk 内存块所属PoolChunk* @param nioBuffer 可能为空,若非空,则缓存ByteBuffer对象待下次使用,减少GC* @param handle 内存句柄* @return false 队列已满,添加失败*/@SuppressWarnings("unchecked")public final boolean add(PoolChunk<T> chunk, ByteBuffer nioBuffer, long handle) {// #1 创建「Entry」对象,包装内存块详情Entry<T> entry = newEntry(chunk, nioBuffer, handle);// #2 入队boolean queued = queue.offer(entry);if (!queued) {// 入队失败,立即回收Entry对象,否则会造成内存泄漏entry.recycle();}// #3 返回缓存结果return queued;}// 构造Entry对象private static Entry newEntry(PoolChunk<?> chunk, ByteBuffer nioBuffer, long handle) {// #1 从对象缓存池中获取Entry对象Entry entry = RECYCLER.get();// #2 封装内存信息entry.chunk = chunk;entry.nioBuffer = nioBuffer;entry.handle = handle;// #3 返回return entry;}// 创建一个对象缓存池@SuppressWarnings("rawtypes")private static final ObjectPool<Entry> RECYCLER = ObjectPool.newPool(new ObjectCreator<Entry>() {@SuppressWarnings("unchecked")@Overridepublic Entry newObject(Handle<Entry> handle) {return new Entry(handle);}});
到这里,本地线程回收内存块的整个逻辑都已经解释清楚了。本质就是使用 Entry 对象封装内存块信息,然后写入对应 MemoryRegionCache[] 数组中。MemoryRegionCache 对象内部维护一个队列,该队列是存放 Entry 对象的地方。
从缓存中尝试申请内存
当通过分配器进行内存申请时,对于 Tiny&Small 两种级别的内存规格会先尝试从本地线程缓存中申请。相关源码如下: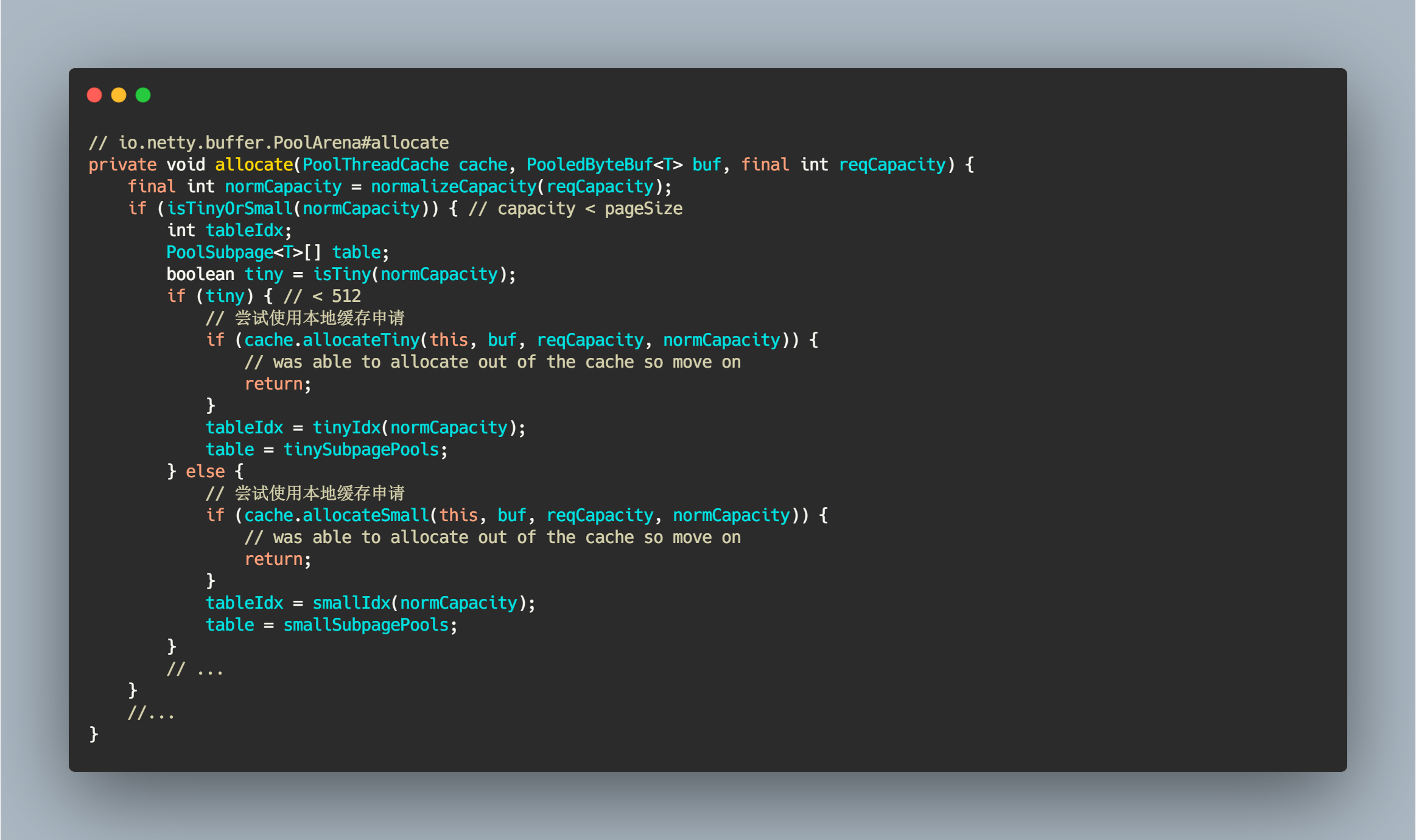
// io.netty.buffer.PoolArena#allocateprivate void allocate(PoolThreadCache cache, PooledByteBuf<T> buf, final int reqCapacity) {final int normCapacity = normalizeCapacity(reqCapacity);if (isTinyOrSmall(normCapacity)) { // capacity < pageSizeint tableIdx;PoolSubpage<T>[] table;boolean tiny = isTiny(normCapacity);if (tiny) { // < 512// 尝试使用本地缓存申请if (cache.allocateTiny(this, buf, reqCapacity, normCapacity)) {// was able to allocate out of the cache so move onreturn;}tableIdx = tinyIdx(normCapacity);table = tinySubpagePools;} else {// 尝试使用本地缓存申请if (cache.allocateSmall(this, buf, reqCapacity, normCapacity)) {// was able to allocate out of the cache so move onreturn;}tableIdx = smallIdx(normCapacity);table = smallSubpagePools;}// ...}//...}
PoolThreadCache#allocateTiny
PoolThreadCache#allocateTiny() 方法尝试申请 Tiny 规格内存。PoolThreadCache#allocateSmall() 其实也是一样,这里就不重复解释了。
// 尝试分配 Tiny 级别内存并初始化PooledByteBuf对象// io.netty.buffer.PoolThreadCache#allocateTinyboolean allocateTiny(PoolArena<?> area, PooledByteBuf<?> buf, int reqCapacity, int normCapacity) {return allocate(cacheForTiny(area, normCapacity), buf, reqCapacity);}/*** 根据数据容器以及规格值获取对应的MemoryRegionCache对象*/// io.netty.buffer.PoolThreadCache#cacheForTinyprivate MemoryRegionCache<?> cacheForTiny(PoolArena<?> area, int normCapacity) {// #1 根据规格值确定数组索引值int idx = PoolArena.tinyIdx(normCapacity);// #2 根据数据容器从不同数组中获取对应的MemoryRegionCache对象if (area.isDirect()) {return cache(tinySubPageDirectCaches, idx);}return cache(tinySubPageHeapCaches, idx);}// 返回对应cache下标的MemoryRegionCache对象// io.netty.buffer.PoolThreadCache#cacheprivate static <T> MemoryRegionCache<T> cache(MemoryRegionCache<T>[] cache, int idx) {if (cache == null || idx > cache.length - 1) {return null;}return cache[idx];}
PoolThreadCache#allocate
这个方法比较简单,就是委托 MemoryRegionCache 对象分配内存。然后再判断当前分配总数是否超过阈值,如果超过了需要对所有的 MemoryRegionCache 数组进行清理工作。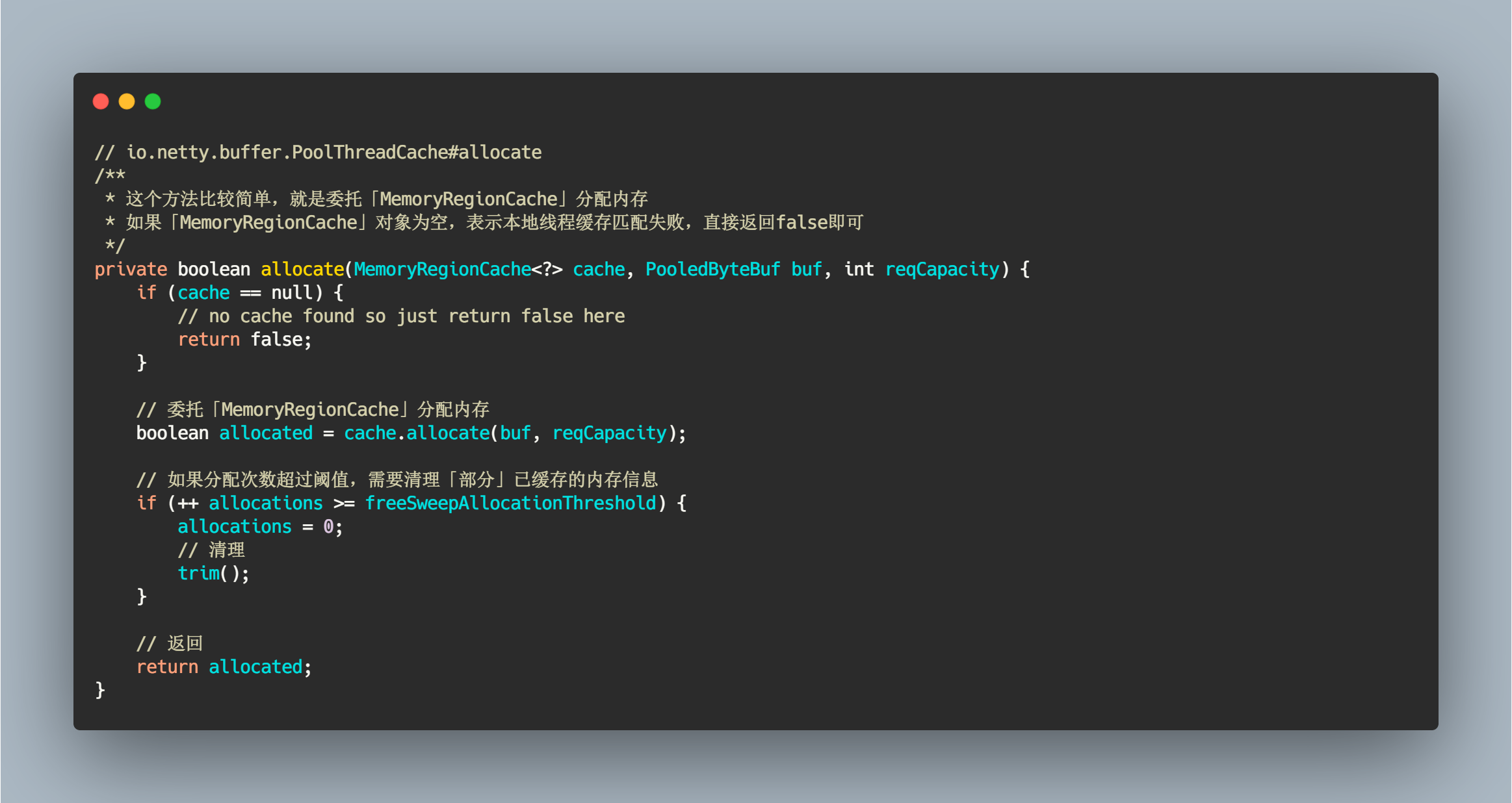
// io.netty.buffer.PoolThreadCache#allocate/*** 这个方法比较简单,就是委托「MemoryRegionCache」分配内存* 如果「MemoryRegionCache」对象为空,表示本地线程缓存匹配失败,直接返回false即可*/private boolean allocate(MemoryRegionCache<?> cache, PooledByteBuf buf, int reqCapacity) {if (cache == null) {// no cache found so just return false herereturn false;}// 委托「MemoryRegionCache」分配内存boolean allocated = cache.allocate(buf, reqCapacity);// 如果分配次数超过阈值,需要清理「部分」已缓存的内存信息if (++ allocations >= freeSweepAllocationThreshold) {allocations = 0;// 清理trim();}// 返回return allocated;}
MemoryRegionCache#allocate
终于到了真正内存分配的地方了,逻辑也十分清楚,从 Queue 弹出一个 Entry 对象,里面包含了我们需要的内存信息,如果弹出对象为空,那此次分配失败,返回false,如果有,那就通过 init() 方法初始化 ByteBuf 对象,并把 Entry 对象回收。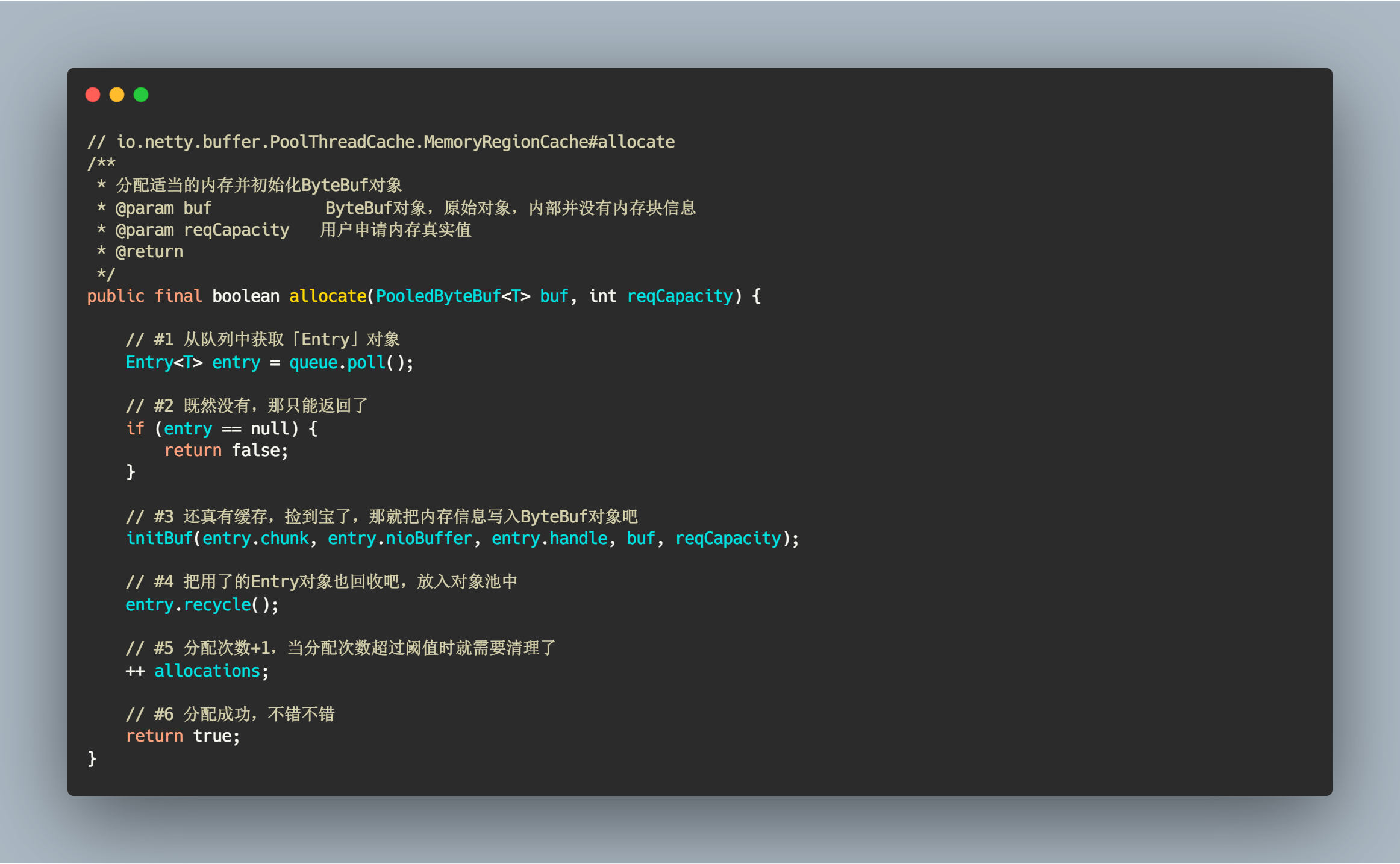
// io.netty.buffer.PoolThreadCache.MemoryRegionCache#allocate/*** 分配适当的内存并初始化ByteBuf对象* @param buf ByteBuf对象,原始对象,内部并没有内存块信息* @param reqCapacity 用户申请内存真实值* @return*/public final boolean allocate(PooledByteBuf<T> buf, int reqCapacity) {// #1 从队列中获取「Entry」对象Entry<T> entry = queue.poll();// #2 既然没有,那只能返回了if (entry == null) {return false;}// #3 还真有缓存,捡到宝了,那就把内存信息写入ByteBuf对象吧initBuf(entry.chunk, entry.nioBuffer, entry.handle, buf, reqCapacity);// #4 把用了的Entry对象也回收吧,放入对象池中entry.recycle();// #5 分配次数+1,当分配次数超过阈值时就需要清理了++ allocations;// #6 分配成功,不错不错return true;}
步骤 3 的方法其实是一个抽象方法,MemoryRegionCache 其实是一个抽象类,它还有另外两个子类的实现:
两个子类就只实现 initBuf 这个抽象方法,在子类实现中分别调用不同的初始化方法。初始化 ByteBuf 逻辑主要区别是计算 offset 和 maxLength 逻辑不同,其它都是相同的。相关源码如下: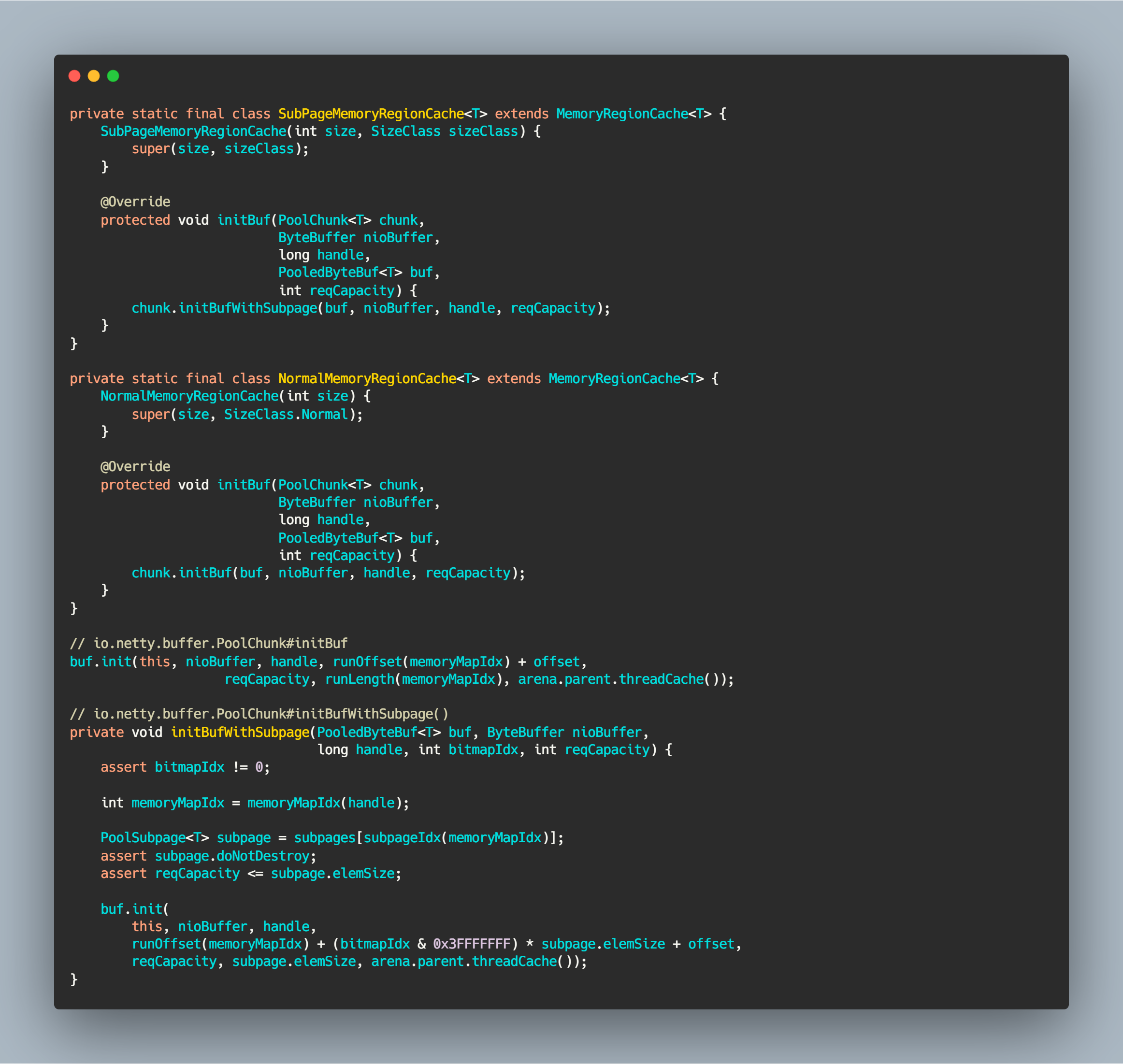
private static final class SubPageMemoryRegionCache<T> extends MemoryRegionCache<T> {SubPageMemoryRegionCache(int size, SizeClass sizeClass) {super(size, sizeClass);}@Overrideprotected void initBuf(PoolChunk<T> chunk,ByteBuffer nioBuffer,long handle,PooledByteBuf<T> buf,int reqCapacity) {chunk.initBufWithSubpage(buf, nioBuffer, handle, reqCapacity);}}private static final class NormalMemoryRegionCache<T> extends MemoryRegionCache<T> {NormalMemoryRegionCache(int size) {super(size, SizeClass.Normal);}@Overrideprotected void initBuf(PoolChunk<T> chunk,ByteBuffer nioBuffer,long handle,PooledByteBuf<T> buf,int reqCapacity) {chunk.initBuf(buf, nioBuffer, handle, reqCapacity);}}// io.netty.buffer.PoolChunk#initBufbuf.init(this, nioBuffer, handle, runOffset(memoryMapIdx) + offset,reqCapacity, runLength(memoryMapIdx), arena.parent.threadCache());// io.netty.buffer.PoolChunk#initBufWithSubpage()private void initBufWithSubpage(PooledByteBuf<T> buf, ByteBuffer nioBuffer,long handle, int bitmapIdx, int reqCapacity) {assert bitmapIdx != 0;int memoryMapIdx = memoryMapIdx(handle);PoolSubpage<T> subpage = subpages[subpageIdx(memoryMapIdx)];assert subpage.doNotDestroy;assert reqCapacity <= subpage.elemSize;buf.init(this, nioBuffer, handle,runOffset(memoryMapIdx) + (bitmapIdx & 0x3FFFFFFF) * subpage.elemSize + offset,reqCapacity, subpage.elemSize, arena.parent.threadCache());}
释放缓存中的内存块
正所谓有借有还,在借不难嘛,我们应该在适当的时候归还部分内存块,不能被一个线程独占,毕竟还有其他线程需要内存块嘛。触发释放缓存中的内存块的时机前面已经提到过,就是当分配次数大于释放阈值(默认值: 8192)时就进行释放操作。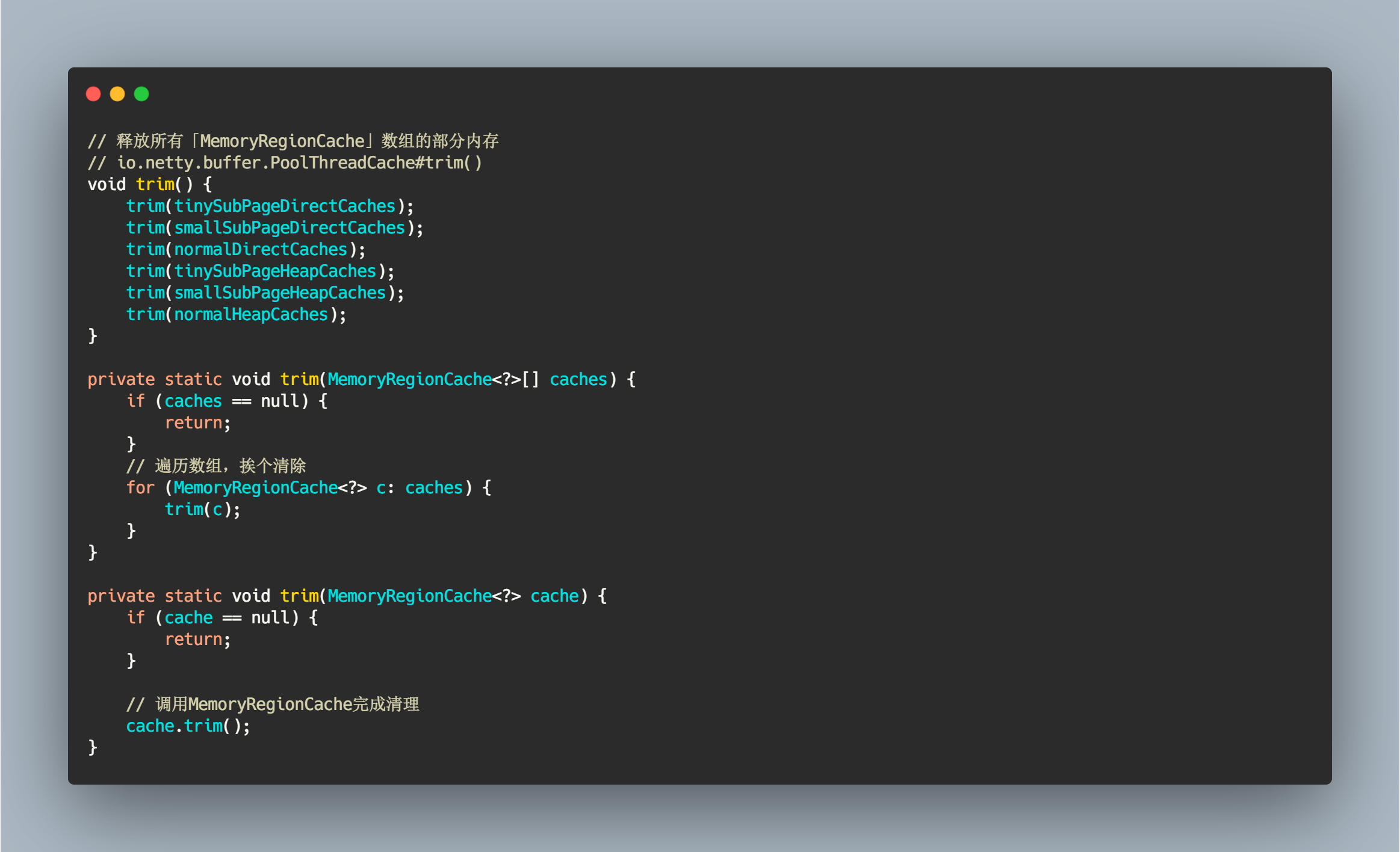
// 释放所有「MemoryRegionCache」数组的部分内存// io.netty.buffer.PoolThreadCache#trim()void trim() {trim(tinySubPageDirectCaches);trim(smallSubPageDirectCaches);trim(normalDirectCaches);trim(tinySubPageHeapCaches);trim(smallSubPageHeapCaches);trim(normalHeapCaches);}private static void trim(MemoryRegionCache<?>[] caches) {if (caches == null) {return;}// 遍历数组,挨个清除for (MemoryRegionCache<?> c: caches) {trim(c);}}private static void trim(MemoryRegionCache<?> cache) {if (cache == null) {return;}// 调用MemoryRegionCache完成清理cache.trim();}
MemoryRegionCache#trim
简单计算了需要释放的最大数量。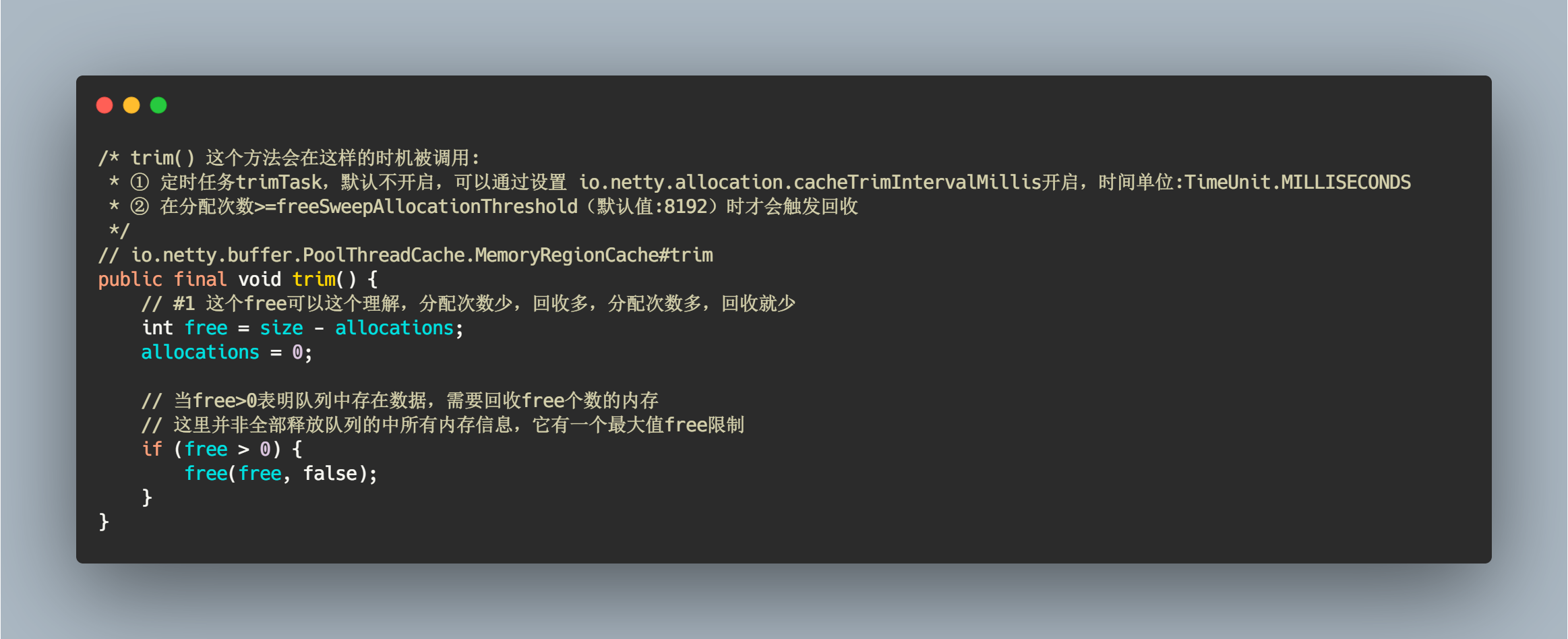
/* trim() 这个方法会在这样的时机被调用:* ① 定时任务trimTask,默认不开启,可以通过设置 io.netty.allocation.cacheTrimIntervalMillis开启,时间单位:TimeUnit.MILLISECONDS* ② 在分配次数>=freeSweepAllocationThreshold(默认值:8192)时才会触发回收*/// io.netty.buffer.PoolThreadCache.MemoryRegionCache#trimpublic final void trim() {// #1 这个free可以这个理解,分配次数少,回收多,分配次数多,回收就少int free = size - allocations;allocations = 0;// 当free>0表明队列中存在数据,需要回收free个数的内存// 这里并非全部释放队列的中所有内存信息,它有一个最大值free限制if (free > 0) {free(free, false);}}
MemoryRegionCache#free(int, boolean)
最多可能会回收 max 个对象。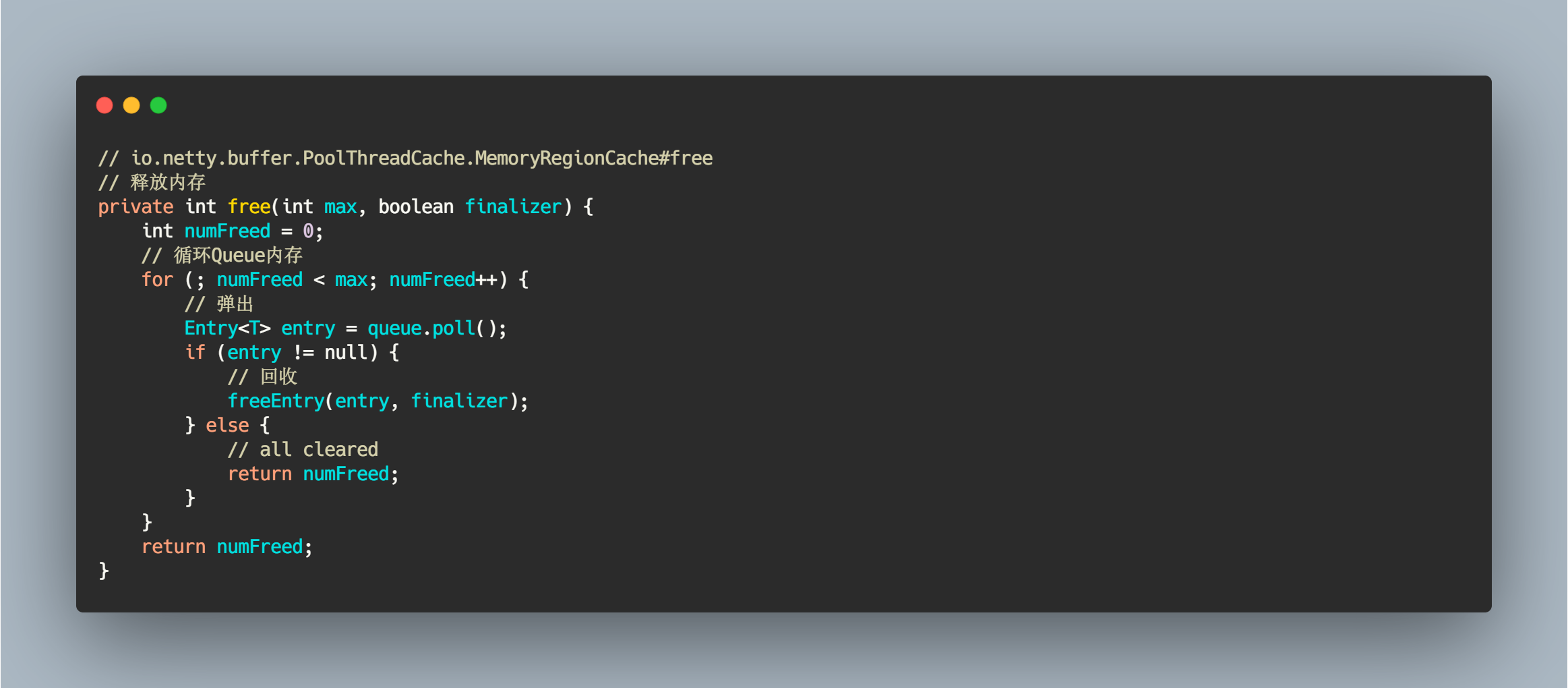
// io.netty.buffer.PoolThreadCache.MemoryRegionCache#free// 释放内存private int free(int max, boolean finalizer) {int numFreed = 0;// 循环Queue内存for (; numFreed < max; numFreed++) {// 弹出Entry<T> entry = queue.poll();if (entry != null) {// 回收freeEntry(entry, finalizer);} else {// all clearedreturn numFreed;}}return numFreed;}
MemoryRegionCache#freeEntry
这个方法会根据是否从 Object#finalizer() 调用来判断是否需要对 Entry 对象回收。如果为 true,表明此时进行的时线程销毁动作,调用 PoolThreadCache#finalize() 方法会回收所有只与此线程相关的数据,比如 Entry、ObjectPool 等对象,线程销毁这些对象就会自动销毁了。但是平常的释放动作不同,虽然调用 entry.crecycle() 对象,假设此时 PoolChunk 对象只有 Entry 这么一个引用指向它,如果不调用这个方法就会造成 PoolChunk 一直被强引用,无法被回收,从而造成内存泄漏,个人愚见,如有错误,麻烦指出。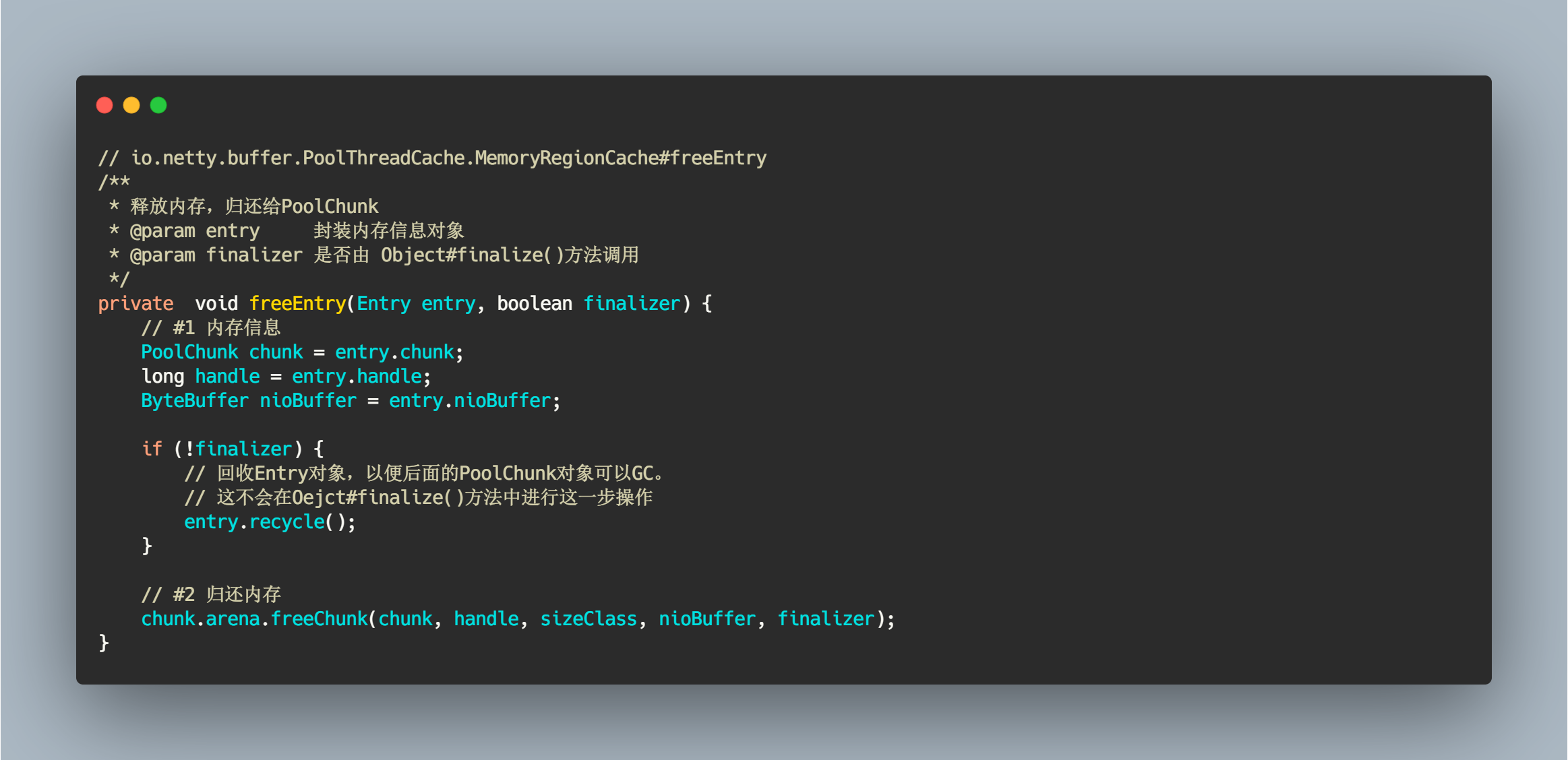
// io.netty.buffer.PoolThreadCache.MemoryRegionCache#freeEntry/*** 释放内存,归还给PoolChunk* @param entry 封装内存信息对象* @param finalizer 是否由 Object#finalize()方法调用*/private void freeEntry(Entry entry, boolean finalizer) {// #1 内存信息PoolChunk chunk = entry.chunk;long handle = entry.handle;ByteBuffer nioBuffer = entry.nioBuffer;if (!finalizer) {// 回收Entry对象,以便后面的PoolChunk对象可以GC。// 这不会在Oejct#finalize()方法中进行这一步操作entry.recycle();}// #2 归还内存chunk.arena.freeChunk(chunk, handle, sizeClass, nioBuffer, finalizer);}
总结
Netty 为每个线程都会分配 PoolThreadCache 用来本地缓存内存信息,当申请内存分配时首先尝试从本地缓存中分配,如果底层容器类型以及内存规格值在 MemoryRegionCache 匹配成功,则直接从队列获取一份内存块信息并初始化 ByteBuf 对象返回,否则还是向 PoolArena 申请内存分配。
当 ByteBuf 释放内存时,并不会把内存块信息归还给 PoolChunk,而是利用 PoolThreadCache 本地缓存下来,使用 Entry 对象包装内存块信息并放入队列,待下次分配时使用。PoolThreadCache 并不会一味缓存线程释放的内存块,当分配次数超过 freeSweepAllocationThreshold(默认值: 8192) 阈值后就会触发本地缓存回收动作,根据分配次数回收部分(也可能全部)缓存。
我的公众号


若有收获,就点个赞吧
0 人点赞
