
概述
G1 全称 Garbage First,垃圾优先,也就是说首先收集垃圾最多的区域。
特点:
- 并发收集
- 压缩空闲空间不会延长 GC 的暂停时间
- 更容易预测的 GC 暂停时间
- 适用不需要实现很高的吞吐量的场景
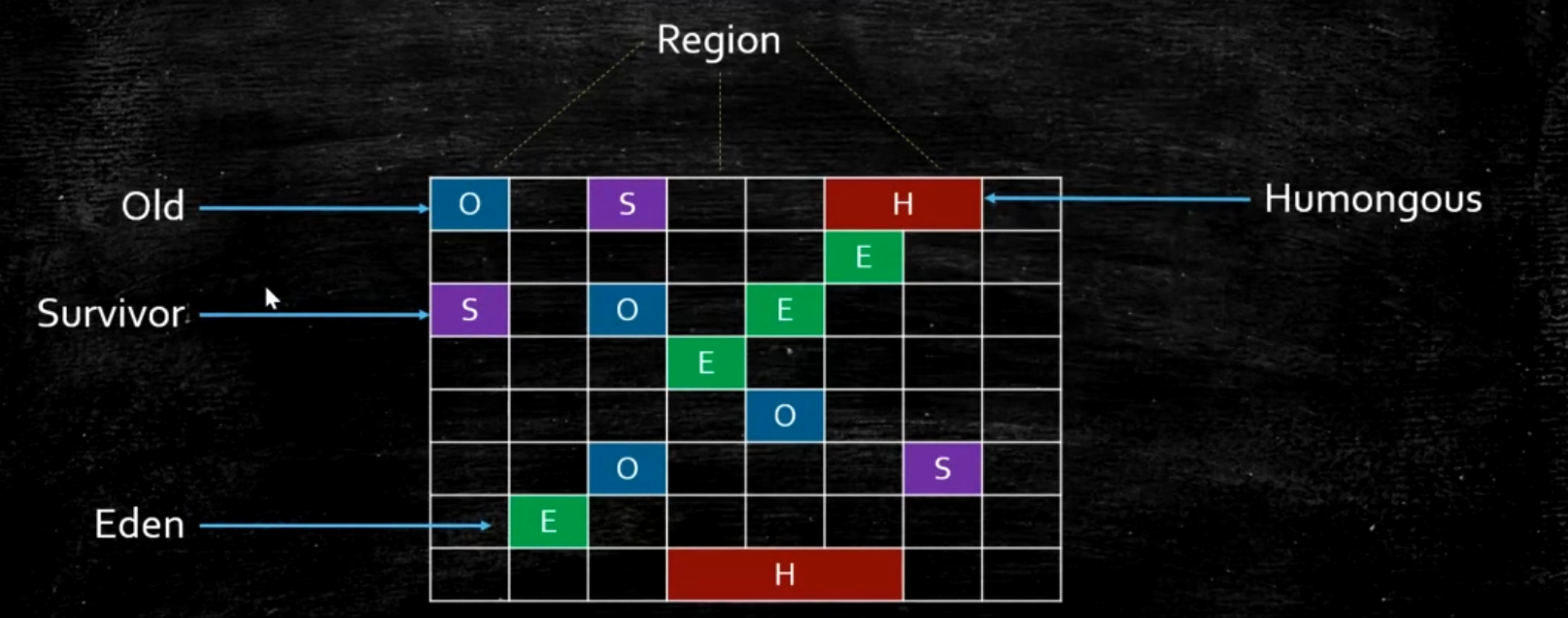
G1 的内存区域不是固定的 Eden 或 Old 区,它是可变的。
- CSet = Collection Set,一组可被回收的分区的集合。在 CSet 中存活的数据会在 GC 过程中被移动到另一个可用分区,CSet 中的分区可以来自 Eden 空间、Survivor 空间、或者老年代。CSet 会占用不到整个堆空间的 1% 大小。
- RSet = RememberedSet,每个 Region 都有。这个用来记录其它 Region 中的对象到本 Region 的引用。它的作用在于使得垃圾收集器不需要扫描整个堆找到谁引用了当前分区中的对象,只需要扫描 RSet 中即可。
- Card Table:解决年轻代和老年代相互引用的对象。由于做 YGC 时需要扫描整个 OLD 区,效率非常低,所以 JVM 设计了 Card Table。如果一个 OLD 区的 CardTable 中有对象指向 Y 区,就将它设置为 Dirty。下次扫描时,只需要扫描 Dirty Card Table 即可,减少搜索范围。Card Table 用 BitMap 来实现。
新老年代比例是动态的(5%~60%),一般不需要手动指定,也不需要指定:
- 因为这是 G1 预测停顿时间的基准
GC 何时触发
- YGC
- Eden 空间不足
- 多线程并行执行
- FGC
- Old 空间不足
- System.gc
如果 G1 产生 FGC,应该做什么?
- 扩大内存
- 提高 CPU 性能(更快回收内存,业务逻辑产生对象的速度固定,垃圾回收越快,内存空间越大)
- 降低 MixedGC 触发的阈值,让 MixedGC 提早发生(默认是 45%)。
MixedGC 相当于是 CMS。-XX:InitiatingHeapOccupacyPercent,默认值是 45%。当 Old 区超过这个值时,启动 MixedGC。
MixedGC 的过程:
- 初始标记 STW。
- 并发标记
- 最终标记 STW(重新标记)
- 筛选回收 STW(并行)
Java10 以前是串行 FullGC,之后是并行 FullGC。
并发标记算法
- 难点:在标记对象的过程中,对象引用关系正在发生改变。
- 三色标记法:
- 白色:未被标记的对象
- 灰色:自身被标记,成员变量未被标记
- 黑色:自身和成员变量均已标记完成
- 漏标
- 在 remark 过程中,黑色指向白色,如果不对黑色重新扫描,则会漏标。会把白色 D 对象当做没有新引用指向从而回收掉。
- 并发标记过程中,Mutator 删除了所有从灰色到白色的引用,会产生漏标,此时白色对象应该被回收。

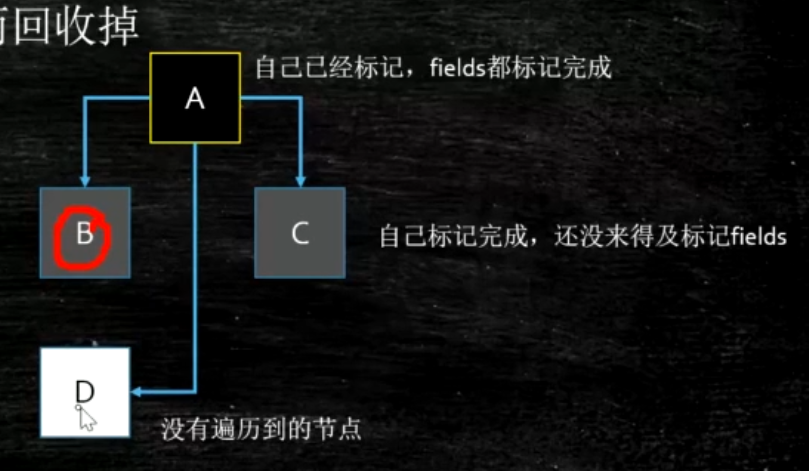
解决方案:
- 跟踪路径 A 指向 D 的增加。即 incremental update。增量更新,关注引用的增加,把黑色重新标记为灰色,下次重新扫描属性。
- 跟踪路径 B 指向 D 的消息。SATB snapshot at the beginning。关注引用的删除,当 B->D 消息时,要把这个引用推到 GC 的堆栈,保证 D 还能被 GC 扫描到。
RSet
概述
RSet 是一个抽象的概述,记录对象在不同代际之间的引用关系,目的是加速垃圾回收的速度。
不使用 RSet 的瓶颈:
- JVM 使用根对象引用的收集算法,即从根集合出发,标记所有存活对象,然后遍历对象的每一个成员变量并继续标记,直接所有的对象标记完成。
- 在分代垃圾回收中,新生代和老年代处于不同的回收阶段,如果还是采用这样的标记方法,不合理也没必要。比如我们只回收新生代,但是对老年代中的活跃对象全部标记,但并没有回收老年代,白白浪费时间。回收老年代同理。
- 算法设计者使用
Rset记录从非收集部分指向收集部分的指针的集合。这个集合描述的就是对象的引用关系。实现细节
两种引用关系
通常有两种方法记录引用关系,如下表所示:
| 引用关系 | 描述 | 优缺点 |
|---|---|---|
| Point Out | 写操作简单,但需要对 RSet 做全部扫描 | |
| Point In | 写操作复杂,但在标记扫描时可以直接找到有用和无用对象,不需要进行额外的扫描,因为 RSet 里面的可看作根对象。G1 使用 Point In 的方式。 |
3 种数据结构
为了提高 RSet 的存储效率,使用了 3 种数据结构:
| 数据结构 | 描述 |
|---|---|
| 稀疏表 | 通过哈希表方式(哈希表底层使用数组)来存储 |
| 细粒度表 | 通过数组来存储,每个数组元素指向引用者分区中 512 字节内存块对本分区的引用情况 |
| 粗粒度表 | 通过位图来表示,第 1 位表示对应的分区有引用到本分区 |
Refine 线程池
Refine 有两大功能,分别是:
- 用于处理新生代分区的抽样,并在满足响应时间指标情况下,更新新第一代分区的数目,通常由一个单独的线程来处理。
- 更新
RSet。也是最重要的功能,对于 RSet 的更新并不是同步完成的,G1 会把所有引用关系都放入一个队列中,称为 Dirty Card Queue(DCQ),然后使用 Refine 线程来消费这个队列完成引用关系的记录。正常来说有G1ConcRefinementThread个线程处理,实际上除了 Refine 线程池更新 RSet 外,GC 工作线程或应用程序线程也可能会更新 RSet。DCQ 通过 Dirty Card Queue Set(DCQS) 来管理。为了能够快速、并发地处理,每个 Refine 线程只负责 DCQS 中的某几个 DCQ。记录哪些对象间的引用
虽然 RSet 是为了记录对象在代际之间的引用,但是并不是所有代际之间的引用都需要记录。分区之间的引用关系可以归纳为:
- 分区内部有引用关系。
- 新生代分区到新生代分区之间有引用关系。
- 新生代分区到老年代分区之间有引用关系。
- 老年代分区到新生代分区之间有引用关系。
- 老年代分区到老年代分区之间有引用关系。
| 解决方案 | 优点 | 缺点 |
| —- | —- | —- |
| 在 RSet 中记录所有的引用关系 | 实现简单 |
1. 需要额外的内存空间,这部分通常是 G1 最大开销,一般会达到 1%~20%。
1. 可能导致浮动垃圾。因为 RSet 里面的对象可能已经死亡,但仍被视为活跃对象。
| | 只记录特定引用:
1. 分区内部的引用关系无需记录。因为回收是针对一个分区而言,分区回收时会遍历整个分区。
1. 新生代到另一新生代 Region 的引用关系无需记录。原因在 G1 的 YGC/Mixed GC/FGC 回收算法都会全量处理新生代分区,它们都会被遍历。
1. 新生代分区到老年代的引用关系无需记录。YGC 针对是新生代分区,不需要这个引用关系。Mixed GC 发生时,G1 会使用新第一代分区作为 Root 对象,那么遍历新生代分区时自然就能找到新生代分区到老年代分区的引用。
1. 老年代到新生代分区之间的引用关系需要被记录。在 YGC 时有两种根,分别是栈空间/全局空间变量的引用,另一个就是老年代分区到新新第生代分区的引用。
1. 老年代分区到老年代分区之间的引用关系需要记录。因为 Mixed GC 只回收部分老年代,所以这部分关系必须要记录,快速找到存活的对象。
| 占用空间小 | 实现复杂 |
SATB(Snapshot At The Beginning)
问题:并发标记时,并发标记线程和用户线程并发执行,一边在标记垃圾对象,一边还在生成垃圾对象。
解决方案:旧的垃圾回收算法采用串行执行(标记工作和对象生成工作不同时进行)。而在 G1 中引入了新的算法 SATB。
对象分配
在堆分区中分配对象时,对象都是连续分配的,所以可以设计几个指针,分别是
Prev 和 Next 指针解决了并发标记工作内存区域的问题,还需要引入两个额外的数据结构来记录内存标记的状态,典型的是使用位图(BitMap)来指示哪块内存已经使用,哪块内存还未使用,所以并发标记引入两个位图 PrevBitmap 和 NextBitmap,用 PreBitmap 记录 Prev 指针之前内存的标记情况,用 NextBitmap 表示整个内存从 Bottom 到 Next 指针之前的标记状态。引入 PreBitmap 目标是应对标记失败场景。
G1 中的屏障
在 G1 中使用了两种屏障:
- 读屏障。为了处理 SATB 并发标记而引入。
- 写屏障。为了处理 RSet 而引入。
一句简单的 Java 赋值语句,实际被 JVM 处理成 3 条伪代码:
JVM ---> Insert Pre-write barrier, 处理 SATB,保证标记的正确性Object.Field = other_object; 真正的赋值语句JVM ---> Insert Post-write barrier, 处理 RSet,即产生对象到 DCQ 中
G1 不足
- 停顿时间过长。通常 G1 的停顿时间要达到几十到几百毫秒,其实这个数字已经非常小了,但是垃圾回发生导致应用程序在这几十到几百毫秒中不能提供服务,在这些场景中还是不能接受的。
- 内存利用率不高。额外记录对象间的引用关系占用大量内存,一般占用整个内存的 1%~20%左右。以空间换时间。
-
ZGC
ZGC 作为新一代的垃圾回收器,在设计之初就定义了三大目标:
支持 TB 级内存。
- 停顿时间控制在 10ms 之内。
- 对程序吞吐量影响小于 15%。
ZGC 的设计思想是借鉴了一款商业垃圾回收器 — Azul 的 C4。
JVM 在进入安全点时会进行字符串回收(这里是指使用 Stirng#intern() 方法而产生的垃圾),所以 ZGC 为了保证进入安全点的时间足够短,会把这一部分工作优化成并发处理。
简单地说,ZGC 把一切能并发处理的工作都并发执行。ZGC 是在 G1 的基础上发展而来,G1 中的停顿时间主要来自垃圾回收(YGC/Mixed GC)阶段中的复制算法,在复制算法中,需要把对象转移到新的空间中,并且更新其它对象到这个对象的引用。在 G1 中对象的转移都是在 STW 期间并行执行。而 ZGC 把对象的转移则是并发执行,从而满足停顿时间在 10ms 以下。ZGC 每次都是 FGC,停顿时间可控。

若有收获,就点个赞吧
0 人点赞
