在可视化的时候,如果有object类型的数据,我们无法进行聚合可视化,我们需要将其转化为数值类型。比如工资(19K,20K…)这类的文本和数值混合的,我们需要去掉后面的英文K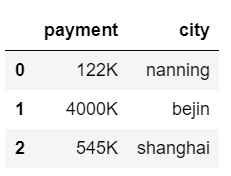
def payment_split(x):try:return int(x.split("K")[0])*1000except:return 0data['payment'] = data['payment'].apply(lambda x: payment_split(x))
- 这里要对try这里的代码解释一下,通过split拆分122K后会形成(‘122’,‘‘),[0]是选择元组里面的第一个也就是’122’
- 在遍历每行的时候我们可以用apply,然后运用lambda函数,将行的只传入我们定义的清除文本的函数中
使用上述代码的时候有一个注意点,在pandas中所有混合型的数据类型都是object,执行上述操作的时候,可能会有有提示
'float' object has no attribute 'replace'或'float' object has no attribute 'split'碰到这样的提示时我们先使用astype强制转换数据类型def payment_split(x):return float(x.replace('$','').replace(',',''))data['payment'] = data['payment'].astype(str).apply(lambda x: income_split(x))
这里的运用了replace进行字符串的修改
- strip只能去除首尾字符串,不能修改字符串中间的,所以使用replace代替

若有收获,就点个赞吧
0 人点赞
