GroupBy
在Pandas中进行分组和其他语言如SQL类似,使用的是groupby语句,基本语句如下
tmp = df.groupby("DRG_CODE")
- 以DRG_CODE作为分组
- 分组过后,DRG_CODE这列会变成索引
下面两句代码的效果等价,在分组过后可以让分组列不变为索引列
tmp = df.groupby("DRG_CODE", as_index=False).agg(np.mean)tmp = df.groupby("DRG_CODE").agg(np.mean).reset_index()
需要注意的是,在对列进行聚合后,会形成一个层级结构
tmp2 = df.loc[df["hospital_name"]=="人民医院",["DRG_CODE","TOTAL_AMOUNT"]].groupby(["DRG_CODE"]).agg(["mean","count"]).rename(columns={"mean": "h_avg", "count": "h_num"})
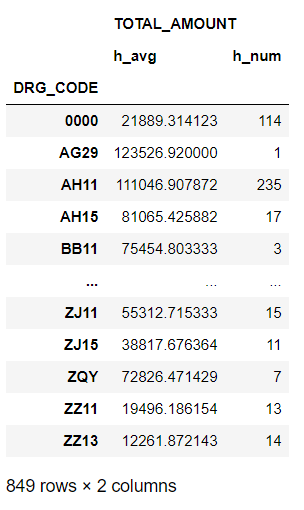
在上述代码中对TOTAL_AMOUNT这列进行了多个聚合,得到了均值和计数,可以看到这时的层级结构是在TOTAL_AMOUNT下有h_avg(mean)和h_num(count)两列,类似于在excel中的大类是合并单元格的,然后下面一行是小类。
如果要将上述分组后的结果转为正常的DataFrame形式,
tmp2.columns = tmp2.columns.get_level_values(1)
- 通过
columns.get_level_values(1)将第二层的列名字取出,这里就是h_avg和h_num。如果是columns.get_level_values(1)则是将第一层的列名取出就是TOTAL_AMOUNT - 最后我们重命名列,就将第一层的TOTAL_AMOUNT取代了
pivot
pivot_table就是我们在excel中常用的数据透视表,在pandas中数据透视表的功能通过pd.pivot_table提供。
pd.pivot_table(df.loc[df["机构名称"].map(lambda x: x in ["广西中医药大学第一附属医院","广西中医药大学附属瑞康医院","南宁市中医医院"]),["机构名称","分组类型","病例类型","支付差_追加"]],index=["机构名称","病例类型"],columns="分组类型",values="支付差_追加",aggfunc=lambda x: sum(x)/10000,margins=True)
- 这里从原始数据中筛选了三个医院的数据进行透视,有四列数据
["机构名称","分组类型","病例类型","支付差_追加"] index参数相当于excel透视表的行,如果要有多行的也就是一个大项下还有子项的形式,这里可以转入一个列表columns参数相当于excel透视表中的列,这里是用分组类型充当列名values相当于excel透视表中的值,这里用支付差充当aggfunc对values的运算,可以直接传入函数名如:np.sum,np.mean或是lambda函数margins在结果中增加行合计、列合计

如果需要对多个列进行计算的,可以使用字典,将列名函数对应起来
pd.pivot_table(df.loc[df["医院等级"] == 3, ["分组编码", "支付差_追加","医疗总费用"]],index="分组编码",aggfunc={"支付差_追加": lambda x: np.sum(x), "医疗总费用": lambda x: np.sum(x)}).round(2)
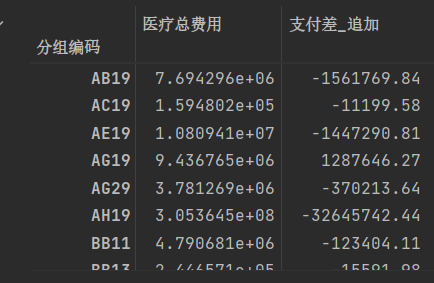
如果需要针对透视后的结果DataFrame再进行处理,又不想临时建一个变量存储DataFrame的情况,可以用pipe()函数,起到管道的作用
pd.pivot_table(df.loc[df["医院等级"] == 3, ["分组编码", "支付差_追加","医疗总费用"]],index="分组编码",aggfunc={"支付差_追加": lambda x: np.sum(x), "医疗总费用": lambda x: np.sum(x)})\.pipe(lambda x: x["支付差_追加"]/x["医疗总费用"])

若有收获,就点个赞吧
0 人点赞
