
类似这样的数据,有很多的其他手术字段,现在想要知道一个编码下有多少种手术,可能出现在其他手术1,其他手术2这样,这个时候需要将多列聚合到一起,最后得到的结果类似这样
这个时候可以用以下代码进行处理
data = data.fillna("空白")data["手术编码"] = data["主要手术编码"] + ',' + data["其他手术编码1"] + ',' + data["其他手术编码2"]data["手术编码处理"] = data["手术编码"].apply(lambda x: x.split(","))clist = []for i in df['DRG_CODE'].unique():tmp = df[df["DRG_CODE"]==i].explode("手术编码处理")tmp = (tmp[tmp['手术编码处理']!='空白'])tmp.drop_duplicates(subset=['手术编码处理','手术名称处理'],keep='first',inplace=True)clist.append(tmp)tmp["数量"] = 1shit = tmp.groupby(["DRG_CODE","手术编码处理","手术名称处理"],as_index=False).agg("count")final = pd.concat(clist)
- 首先将分布在这些列的数据汇聚到一个单元格中,这里是新建一个字段,用加号将各个字段的值一一连接,用逗号作为分隔符
- 之前汇聚的结果相当于是一个长支付穿,这里用
lambda函数以逗号作为分隔符,将这个单元格的数据放入列表之中 - pandas有一个名为explode的函数
data.explode(),可以将单元格中的列表数据炸开到行中,由于过程中会涉及到索引的变化,有时候会报错 - 使用如果要explode多列,可以用
data.explode(["xxx","yyy"])如果是需要忽略索引的影响,加上data.explode(["xxx","yyy"], ignore_index=True) - 对于多列的情况还可以使用apply的方式,
data.apply(pd.Series.explode) - 留一列作为分组统计的聚合指标
最后结果如图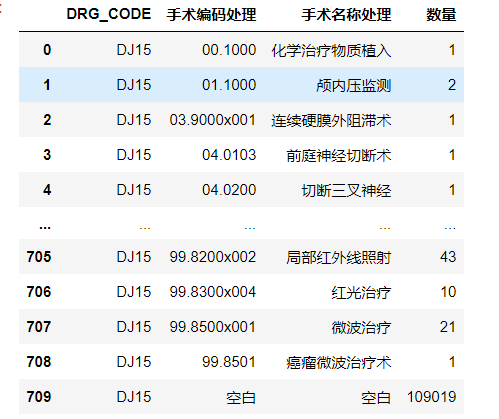 如果要explode多列的情况,需要两列中的列表是一样长度的
如果要explode多列的情况,需要两列中的列表是一样长度的

若有收获,就点个赞吧
0 人点赞
