数据分析概述
当今世界对信息技术的依赖程度在不断加深,每天都会有大量的数据产生,我们经常会感到数据越来越多,但是要从中发现有价值的信息却越来越难。这里所说的信息,可以理解为对数据集处理之后的结果,是从数据集中提炼出的可用于其他场合的结论性的东西,而从原始数据中抽取出有价值的信息的这个过程我们就称之为数据分析,它是数据科学工作的一部分。
数据分析师的职责和技能栈
我们通常将从事数据分析、数据科学和数据相关产品的岗位都统称为数据分析岗位,但是根据工作性质的不同,又可以分为数据分析方向、数据挖掘方向、数据产品方向和数据工程方向。我们通常所说的数据分析师主要是指业务数据分析师,很多数据分析师的职业生涯都是从这个岗位开始的,而且这个岗位也是招聘数量最大的岗位。业务数据分析师在公司通常不属于研发部门而属于运营部门,所以这个岗位也称为数据运营或商业分析,通常招聘信息对这个岗位的描述是:
- 负责各部门相关的报表。
- 建立和优化指标体系。
- 监控数据波动和异常,找出问题。
- 优化和驱动业务,推动数字化运营。
- 找出潜在的市场和产品的上升空间。
根据上面的描述,作为业务数据分析师,我们的工作不是给领导一个简单浅显的结论,而是结合公司的业务,完成揪出异常、找到原因、探索趋势的工作。所以作为数据分析师,不管是用Python语言、Excel、SPSS或其他的商业智能工具,工具只是达成目标的手段,数据思维是核心技能,而从实际业务问题出发到最终发现数据中的商业价值是终极目标。
数据分析师在很多公司只是一个基础岗位,精于业务的数据分析师可以向数据分析经理或数据运营总监等管理岗位发展;对于熟悉机器学习算法的数据分析师来说,可以向数据挖掘工程师或算法专家方向发展,而这些岗位除了需要相应的数学和统计学知识,在编程能力方面也比数据分析师有更高的要求,可能还需要有大数据存储和处理的相关经验;作为数据产品经理,除了传统产品经理的技能栈之外,也需要较强的技术能力,例如要了解常用的推荐算法、机器学习模型,能够为算法的改进提供依据,能够制定相关埋点的规范和口径,虽然不需要精通各种算法,但是要站在产品的角度去考虑数据模型、指标、算法等的落地;数据工程师是一个偏技术的岗位,基本上的成长道路都是从SQL开始,逐步向Hadoop生态圈迁移,然后每天跟Flume和Kafka亲密接触的一个过程。
以下是我总结的数据分析师的技能栈,仅供参考。
- 计算机科学(数据分析工具、编程语言、数据库、……)
- 数学和统计学(数据思维、统计思维)
- 人工智能(机器学习算法)
- 业务理解能力(沟通、表达、经验)
- 总结和表述能力(商业PPT、文字总结)
数据分析的流程
我们提到数分析这个词很多时候可能指的都是狭义的数据分析,这类数据分析主要目标就是生成可视化报表并通过这些报表来洞察业务中的问题。广义的数据分析还包含了数据挖掘的部分,不仅要通过数据实现对业务的监控和分析,还要利用机器学习算法,找出隐藏在数据背后的知识,并利用这些知识为将来的决策提供支撑。简单的说,一个完整的数据分析应该包括基本的数据分析和深入的数据挖掘两个部分。
基本的数据分析工作一般包含以下几个方面的内容,当然因为行业和工作内容的不同会略有差异。
- 确定目标(输入):理解业务,确定指标口径
- 获取数据:数据库、电子表格、三方接口、网络爬虫、开放数据集、……
- 清洗数据:缺失值处理、异常值处理、格式化处理、数据变换、归一化、离散化、……
- 探索数据:运算、统计、分组、聚合、可视化(趋势、变化、分布等)、……
- 数据报告(输出):数据发布,工作成果总结汇报
- 分析洞察(后续):数据监控、发现趋势、洞察异常、……
深入的数据挖掘工作应该包含一下几个方面的内容,当然因为行业和工作内容的不同会略有差异。
- 确定目标(输入):理解业务,明确挖掘目标
- 数据准备:数据采集、数据描述、数据探索、质量判定、……
- 数据加工:提取数据、清洗数据、数据变换、归一化、离散化、特殊编码、降维、特征选择、……
- 数据建模:模型比较、模型选择、算法应用、……
- 模型评估:交叉检验、参数调优、结果评价、……
-
数据分析相关库
使用Python从事数据科学相关的工作是一个非常棒的选择,因为Python整个生态圈中,有大量的成熟的用于数据科学的软件包(工具库)。而且不同于其他的用于数据科学的编程语言(如:Julia、R),Python除了可以用于数据科学,能做的事情还很多,可以说Python语言几乎是无所不能的。
三大神器
NumPy:支持常见的数组和矩阵操作,通过
ndarray类实现了对多维数组的封装,提供了操作这些数组的方法和函数集。由于NumPy内置了并行运算功能,当使用多核CPU时,Numpy会自动做并行计算。- Pandas:pandas的核心是其特有的数据结构
DataFrame和Series,这使得pandas可以处理包含不同类型的数据的负责表格和时间序列,这一点是NumPy的ndarray做不到的。使用pandas,可以轻松顺利的加载各种形式的数据,然后对数据进行切片、切块、处理缺失值、聚合、重塑和可视化等操作。 Matplotlib:matplotlib是一个包含各种绘图模块的库,能够根据我们提供的数据创建高质量的图形。此外,matplotlib还提供了pylab模块,这个模块包含了很多像MATLAB一样的绘图组件。
其他相关库
SciPy:完善了NumPy的功能,封装了大量科学计算的算法,包括线性代数、稀疏矩阵、信号和图像处理、最优化问题、快速傅里叶变换等。
- Seaborn:Seaborn是基于matplotlib的图形可视化工具,直接使用matplotlib虽然可以定制出漂亮的统计图表,但是总体来说还不够简单方便,Seaborn相当于是对matplotlib做了封装,让用户能够以更简洁有效的方式做出各种有吸引力的统计图表。
- Scikit-learn:Scikit-learn最初是SciPy的一部分,它是Python数据科学运算的核心,提供了大量机器学习可能用到的工具,包括:数据预处理、监督学习(分类、回归)、无监督学习(聚类)、模式选择、交叉检验等。
- Statsmodels:包含了经典统计学和经济计量学算法的库。
使用Jupyter Notebook
安装和使用Anaconda
如果希望快速开始使用Python处理数据科学相关的工作,建议大家直接安装Anaconda,它是工具包最为齐全的Python科学计算发行版本。对于新手来说,先安装官方的Python解释器,再逐个安装工作中会使用到的库文件会比较麻烦,尤其是在Windows环境下,经常会因为构建工具或DLL文件的缺失导致安装失败,而一般新手也很难根据错误提示信息采取正确的解决措施,容易产生严重的挫败感。
对于个人用户来说,可以从Anaconda的官方网站下载它的“个人版(Individual Edition)”安装程序,安装完成后,你的计算机上不仅拥有了Python环境和Spyder(类似于PyCharm的集成开发工具),还拥有了与数据科学工作相关的近200个工具包,包括我们上面提到的那些库。除此之外,Anaconda还提供了一个名为conda的包管理工具,通过这个工具不仅可以管理Python的工具包,还可以用于创建运行Python程序的虚拟环境。
可以通过Anaconda官网提供的下载链接选择适合自己操作系统的安装程序,建议大家选择图形化的安装程序,下载完成后双击安装程序开始安装,如下所示。
完成安装后,找到名为“Anaconda-Navigator”的应用程序,运行该程序可以看到如下所示的界面,我们可以在这里选择需要执行的操作。
conda命令
如果希望使用conda工具来管理依赖项或者创建项目的虚拟环境,可以在终端或命令行提示符中使用conda命令。Windows用户可以在“开始菜单”中找到“Anaconda3”,然后点击“Anaconda Prompt”来启动支持conda的命令行提示符。macOS用户建议直接使用“Anaconda-Navigator”中的“Environments”,通过可视化的方式对虚拟环境和依赖项进行管理。
- 版本和帮助信息。
- 查看版本:
conda -V或conda --version - 获取帮助:
conda -h或conda --help - 相关信息:
conda list
- 查看版本:
虚拟环境相关。
- 显示所有虚拟环境:
conda env list - 创建虚拟环境:
conda create --name venv - 指定Python版本创建虚拟环境:
conda create --name venv python=3.7 - 指定Python版本创建虚拟环境并安装指定依赖项:
conda create --name venv python=3.7 numpy pandas - 通过克隆现有虚拟环境的方式创建虚拟环境:
conda create --name venv2 --clone venv - 分享虚拟环境并重定向到指定的文件中:
conda env export > environment.yml - 通过分享的虚拟环境文件创建虚拟环境:
conda env create -f environment.yml - 激活虚拟环境:
conda activate venv - 退出虚拟环境:
conda deactivate - 删除虚拟环境:
conda remove --name venv --all说明:上面的命令中,
venv和venv2是虚拟环境文件夹的名字,可以将其替换为自己喜欢的名字,但是强烈建议使用英文且不要出现空格或其他特殊字符。
- 显示所有虚拟环境:
包(三方库或工具)管理。
- 查看已经安装的包:
conda list - 搜索指定的包:
conda search matplotlib - 安装指定的包:
conda install matplotlib - 更新指定的包:
conda update matplotlib - 移除指定的包:
conda remove matplotlib说明:在搜索、安装和更新软件包时,默认会连接到官方网站进行操作,如果觉得速度不给力,可以将默认的官方网站替换为国内的镜像网站,推荐使用清华大学的开源镜像网站。将默认源更换为国内镜像的命令是:
conda config --add channels [https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/](https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/)。如果需要换回默认源,可以使用命令conda config --remove-key channels。
- 查看已经安装的包:
安装和启动Notebook
如果已经安装了Anaconda,macOS用户可以按照上面所说的方式在“Anaconda-Navigator”中直接启动“Jupyter Notebook”(以下统一简称为Notebook)。Windows用户可以在“开始菜单”中找到Anaconda文件夹,接下来选择运行文件夹中的“Jupyter Notebook”就可以开始数据科学的探索之旅。
对于安装了Python环境但是没有安装Anaconda的用户,可以用Python的包管理工具pip来安装jupyter,然后在终端(Windows系统称之为命令行提示符)中运行jupyter notebook命令来启动Notebook,如下所示。
# 安装Notebook:pip install jupyter# 安装三大神器pip install numpy pandas matplotlib#c运行Notebook:jupyter notebook
Notebook是基于网页的用于交互计算的应用程序,可以用于代码开发、文档撰写、代码运行和结果展示。简单的说,你可以在网页中直接编写代码和运行代码,代码的运行结果也会直接在代码块下方进行展示。如在编写代码的过程中需要编写说明文档,可在同一个页面中使用Markdonw格式进行编写,而且可以直接看到渲染后的效果。此外,Notebook的设计初衷是提供一个能够支持多种编程语言的工作环境,目前它能够支持超过40种编程语言,包括Python、R、Julia、Scala等。
首先,我们可以创建一个用于书写Python代码的Notebook,如下图所示。
接下来,我们就可以编写代码、撰写文档和运行程序啦,如下图所示。
Notebook使用技巧
如果使用Python做工程化的项目开发,PyCharm肯定是最好的选择,它提供了一个集成开发环境应该具有的所有功能,尤其是智能提示、代码补全、自动纠错这类功能会让开发人员感到非常舒服。如果使用Python做数据科学相关的工作,Notebook并不比PyCharm逊色,在数据和图表展示方面Notebook更加优秀。这个工具的使用非常简单,大家可以看看Notebook菜单栏,相信理解起来不会有太多困难,在知乎上有一篇名为《最详尽使用指南:超快上手Jupyter Notebook》的文章,也可以帮助大家快速认识Notebook。
下面我为大家介绍一些Notebook的使用技巧,希望能够帮助大家提升工作效率。
- 自动补全。在使用Notebook编写代码时,按
Tab键会获得代码提示。 - 获得帮助。在使用Notebook时,如果希望了解一个对象(如变量、类、函数等)的相关信息或使用方式,可以在对象后面使用
?并运行代码, 窗口下方会显示出对应的信息,帮助我们了解该对象,如下所示。

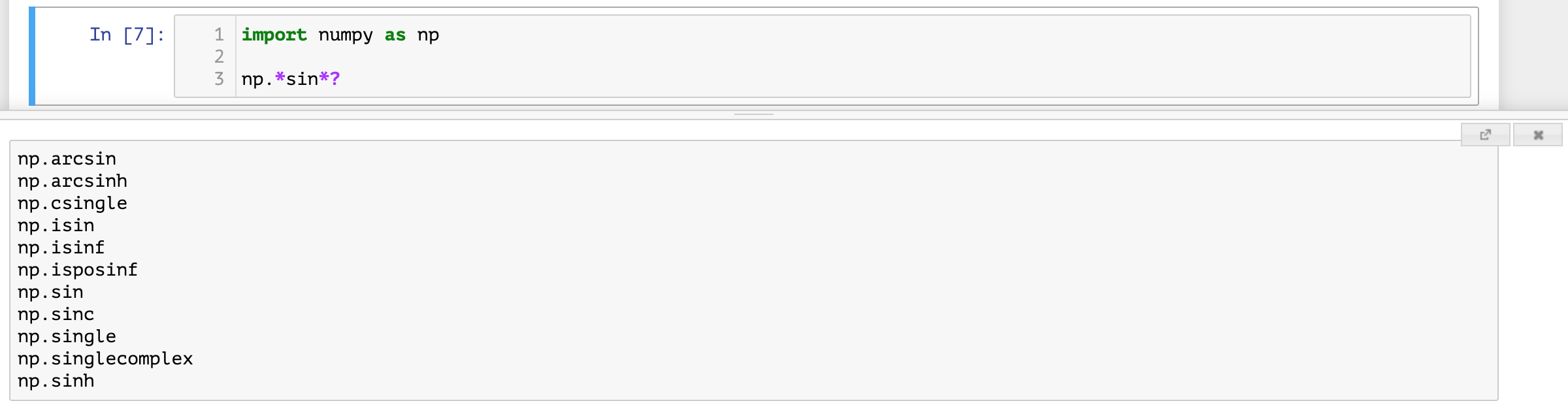
- 搜索命名。如果只记得一个类或一个函数名字的一部分,可以使用通配符
*并配合?进行搜索,如下所示。
- 调用命令。可以在Notebook中使用
!后面跟系统命令的方式来执行系统命令。 - 魔法指令。Notebook中有很多非常有趣且有用的魔法指令,例如可以使用
%timeit测试语句的执行时间,可以使用%pwd查看当前工作目录等。如果想查看所有的魔法指令,可以使用%lsmagic,如果了解魔法指令的用法,可以使用%magic来查看,如下图所示。

常用的魔法指令有:
| 魔法指令 | 功能说明 |
|---|---|
%pwd |
查看当前工作目录 |
%ls |
列出当前或指定文件夹下的内容 |
%cat |
查看指定文件的内容 |
%hist |
查看输入历史 |
%matplotlib inline |
设置在页面中嵌入matplotlib输出的统计图表 |
%config Inlinebackend.figure_format='svg' |
设置统计图表使用SVG格式(矢量图) |
%run |
运行指定的程序 |
%load |
加载指定的文件到单元格中 |
%quickref |
显示IPython的快速参考 |
%timeit |
多次运行代码并统计代码执行时间 |
%prun |
用cProfile.run运行代码并显示分析器的输出 |
%who / %whos |
显示命名空间中的变量 |
%xdel |
删除一个对象并清理所有对它的引用 |
- 快捷键。Notebook中的很多操作可以通过快捷键来实现,使用快捷键可以提升我们的工作效率。Notebook的快捷键又可以分为命令模式下的快捷键和编辑模式下的快捷键,所谓编辑模式就是处于输入代码或撰写文档状态的模式,在编辑模式下按
Esc可以回到命令模式,在命令模式下按Enter可以进入编辑模式。
命令模式下的快捷键:
| 快捷键 | 功能说明 |
|---|---|
| Alt + Enter(Option + Enter) | 运行当前单元格并在下面插入新的单元格 |
| Shift + Enter | 运行当前单元格并选中下方的单元格 |
| Ctrl + Enter(Command + Enter) | 运行当前单元格 |
| j / k、Shift + j / Shift + k | 选中下方/上方单元格、连续选中下方/上方单元格 |
| a / b | 在下方/上方插入新的单元格 |
| c / x | 复制单元格 / 剪切单元格 |
| v / Shift + v | 在下方/上方粘贴单元格 |
| dd / z | 删除单元格 / 恢复删除的单元格 |
| l / Shift + l | 显示或隐藏当前/所有单元格行号 |
| ii / 00 | 中断/重启Notebook内核 |
| Space / Shift + Space | 向下/向上滚动页面 |
编辑模式下的快捷键:
| 快捷键 | 功能说明 |
|---|---|
| Shift + Tab | 获得提示信息 |
| Ctrl + ](Command + ])/ Ctrl + [(Command + [) | 增加/减少缩进 |
| Alt + Enter(Option + Enter) | 运行当前单元格并在下面插入新的单元格 |
| Shift + Enter | 运行当前单元格并选中下方的单元格 |
| Ctrl + Enter(Command + Enter) | 运行当前单元格 |
| Ctrl + Left / Right(Command + Left / Right) | 光标移到行首/行尾 |
| Ctrl + Up / Down(Command + Up / Down) | 光标移动代码开头/结尾处 |
| Up / Down | 光标上移/下移一行或移到上/下一个单元格 |
温馨提示:如果记不住这些快捷键也没有关系,在命令模式下按
h键可以打开Notebook的帮助系统,马上就可以看到快捷键的设置,而且可以根据实际的需要重新编辑快捷键,如下图所示。


若有收获,就点个赞吧
0 人点赞
