数据的集中趋势
均值
均值代表某个数据集的整体水平,我们经常提到的客单价、平均访问时长、平均配送时长等指标都是均值。均值的缺点是容易受极值的影响,虽然可以使用加权平均值来消除极值的影响,但是可能事先并不清楚数据的权重;对于正数可以用几何平均值来替代算术平均值。
- 算术平均值:

- 几何平均值:

中位数
将数据按照升序或降序排列后位于中间的数,它描述了数据的中等水平。
众数
数据集合中出现频次最多的数据,它代表了数据的一般水平。数据的趋势越集中,众数的代表性就越好。众数不受极值的影响,但是无法保证唯一性和存在性。
例子:有A和B两组数据。
A组:5, 6, 6, 6, 6, 8, 10均值:6.74,中位数:6,众数:6。B组:3, 5, 5, 6, 6, 9, 12均值:6.57,中位数:6,众数:5, 6。
对A组的数据进行一些调整。
A组:5, 6, 6, 6, 6, 8, 10, 20
A组的均值会大幅度提升,但中位数和众数却没有变化。
| 优点 | 缺点 | |
|---|---|---|
| 均值 | 充分利用了所有数据,适应性强 | 容易收到极端值(异常值)的影响 |
| 中位数 | 能够避免被极端值(异常值)的影响 | 不敏感 |
| 众数 | 能够很好的反映数据的集中趋势 | 有可能不存在(数据没有明显集中趋势) |
数据的离散趋势
如果说数据的集中趋势,说明了数据最主要的特征是什么;那么数据的离散趋势,则体现了这个特征的稳定性。例如A地区冬季平均气温0摄氏度,最低气温-10摄氏度;B地区冬季平均气温-2摄氏度,最低气温-4摄氏度;如果你是一个特别怕冷的人,在选择A和B两个区域作为工作和生活的城市时,你会做出怎样的选择?
极值
就是最大值(maximum)、最小值(minimum),代表着数据集的上限和下限。
极差
又称“全距”,是一组数据中的最大观测值和最小观测值之差,记作。一般情况下,极差越大,离散程度越大,数据受极值的影响越严重。
方差
将每个值与均值的偏差进行平方,然后除以总数据量得到的值。简单来说就是表示数据与期望值的偏离程度。方差越大,就意味着数据越不稳定、波动越剧烈,因此代表着数据整体比较分散,呈现出离散的趋势;而方差越小,意味着数据越稳定、波动越平滑,因此代表着数据整体比较集中。
- 总体方差:

- 样本方差:

- 标准差
将方差进行平方根运算后的结果,与方差一样都是表示数据与期望值的偏离程度。


频数分析的意义:
- 大问题变小问题,迅速聚焦到需要关注的群体。
- 找到合理的分类机制,有利于长期的数据分析(维度拆解)。
例如:一个班有40个学生,考试成绩如下所示:
73, 87, 88, 65, 73, 76, 80, 95, 83, 69, 55, 67, 70, 94, 86, 81, 87, 95, 84, 92, 92, 76,69, 97, 72, 90, 72, 85, 80, 83, 97, 95, 62, 92, 67, 73, 91, 95, 86, 77
用上面学过的知识,先解读学生考试成绩的数据。
均值:81.275,中位数:83,众数:95,最高分:97,最低分:55,极差:42,方差:118.15,标准差:10.87。
但是,仅仅依靠上面的数据是很难对一个数据集做出全面的解读,我们可以把学生按照考试成绩进行分组,如下所示。
| 分数段 | 学生人数 |
|---|---|
| <60 | 1 |
| [60, 65) | 1 |
| [65, 69) | 5 |
| [70, 75) | 6 |
| [75, 80) | 3 |
| [80, 85) | 6 |
| [85, 90) | 6 |
| [90, 95) | 6 |
| >=95 | 6 |
数据的概率分布
基本概念
- 随机试验:在相同条件下对某种随机现象进行观测的试验。随机试验满足三个特点:
- 可以在相同条件下重复的进行。
- 每次试验的结果不止一个,事先可以明确指出全部可能的结果。
- 重复试验的结果以随机的方式出现(事先不确定会出现哪个结果)。
- 可以在相同条件下重复的进行。
- 随机变量:如果
 指定给概率空间
指定给概率空间 中每一个事件
中每一个事件 有一个实数
有一个实数 ,同时针对每一个实数
,同时针对每一个实数 都有一个事件集合
都有一个事件集合 与其相对应,其中
与其相对应,其中 ,那么被称作随机变量。从这个定义看出,的本质是一个实值函数,以给定事件为自变量的实值函数,因为函数在给定自变量时会产生因变量,所以将称为随机变量。
,那么被称作随机变量。从这个定义看出,的本质是一个实值函数,以给定事件为自变量的实值函数,因为函数在给定自变量时会产生因变量,所以将称为随机变量。- 离散型随机变量:数据可以一一列出。
- 连续型随机变量:数据不可以一一列出。
- 离散型随机变量:数据可以一一列出。
如果离散型随机变量的取值非常庞大时,可以近似看做连续型随机变量。
概率质量函数/概率密度函数:概率质量函数是描述离散型随机变量为特定取值的概率的函数,通常缩写为PMF。概率密度函数是描述连续型随机变量在某个确定的取值点可能性的函数,通常缩写为PDF。二者的区别在于,概率密度函数本身不是概率,只有对概率密度函数在某区间内进行积分后才是概率。
离散型分布
伯努利分布(Bernoulli distribution):又名两点分布或者0-1分布,是一个离散型概率分布。若伯努利试验成功,则随机变量取值为1。若伯努利试验失败,则随机变量取值为0。记其成功概率为
 ,失败概率为
,失败概率为 ,则概率质量函数为:
,则概率质量函数为:- 二项分布(Binomial distribution):
 个独立的是/非试验中成功的次数的离散概率分布,其中每次试验的成功概率为
个独立的是/非试验中成功的次数的离散概率分布,其中每次试验的成功概率为 。一般地,如果随机变量服从参数为和的二项分布,记为
。一般地,如果随机变量服从参数为和的二项分布,记为 。次试验中正好得到
。次试验中正好得到 次成功的概率由概率质量函数给出,
次成功的概率由概率质量函数给出, 。
。 泊松分布(Poisson distribution):适合于描述单位时间内随机事件发生的次数的概率分布。如某一服务设施在一定时间内受到的服务请求的次数、汽车站台的候客人数、机器出现的故障数、自然灾害发生的次数、DNA序列的变异数、放射性原子核的衰变数等等。泊松分布的概率质量函数为:
 ,泊松分布的参数
,泊松分布的参数 是单位时间(或单位面积)内随机事件的平均发生率。
是单位时间(或单位面积)内随机事件的平均发生率。
连续型分布
均匀分布(Uniform distribution):如果连续型随机变量
具有概率密度函数
%3D%5Cbegin%7Bcases%7D%7B%5Cfrac%7B1%7D%7Bb-a%7D%7D%20%5Cquad%20%26%7Ba%20%5Cleq%20x%20%5Cleq%20b%7D%20%5C%5C%20%7B0%7D%20%5Cquad%20%26%7B%5Cmbox%7Bother%7D%7D%5Cend%7Bcases%7D#card=math&code=f%28x%29%3D%5Cbegin%7Bcases%7D%7B%5Cfrac%7B1%7D%7Bb-a%7D%7D%20%5Cquad%20%26%7Ba%20%5Cleq%20x%20%5Cleq%20b%7D%20%5C%5C%20%7B0%7D%20%5Cquad%20%26%7B%5Cmbox%7Bother%7D%7D%5Cend%7Bcases%7D),则称
上的均匀分布,记作
。
- 指数分布(Exponential distribution):如果连续型随机变量
的指数分布,记为
#card=math&code=X%20%5Csim%20Exp%28%5Clambda%29)。指数分布可以用来表示独立随机事件发生的时间间隔,比如旅客进入机场的时间间隔、客服中心接入电话的时间间隔、知乎上出现新问题的时间间隔等等。指数分布的一个重要特征是无记忆性(无后效性),这表示如果一个随机变量呈指数分布,它的条件概率遵循:
%3DP(T%20%5Cgt%20s)%2C%20%5Cforall%20s%2Ct%20%5Cge%200#card=math&code=P%28T%20%5Cgt%20s%2Bt%5C%20%7C%5C%20T%20%5Cgt%20t%29%3DP%28T%20%5Cgt%20s%29%2C%20%5Cforall%20s%2Ct%20%5Cge%200)。
- 正态分布(Normal distribution):又名高斯分布(Gaussian distribution),是一个非常常见的连续概率分布,经常用自然科学和社会科学中来代表一个不明的随机变量。若随机变量
、尺度参数为
的正态分布,记为
#card=math&code=X%20%5Csim%20N%28%5Cmu%2C%5Csigma%5E2%29),其概率密度函数为:
%3D%7B%5Cfrac%20%7B1%7D%7B%5Csigma%20%7B%5Csqrt%20%7B2%5Cpi%20%7D%7D%7D%7De%5E%7B-%7B%5Cfrac%20%7B%5Cleft(x-%5Cmu%20%5Cright)%5E%7B2%7D%7D%7B2%5Csigma%20%5E%7B2%7D%7D%7D%7D#card=math&code=%5Cdisplaystyle%20f%28x%29%3D%7B%5Cfrac%20%7B1%7D%7B%5Csigma%20%7B%5Csqrt%20%7B2%5Cpi%20%7D%7D%7D%7De%5E%7B-%7B%5Cfrac%20%7B%5Cleft%28x-%5Cmu%20%5Cright%29%5E%7B2%7D%7D%7B2%5Csigma%20%5E%7B2%7D%7D%7D%7D)。

“3法则”:
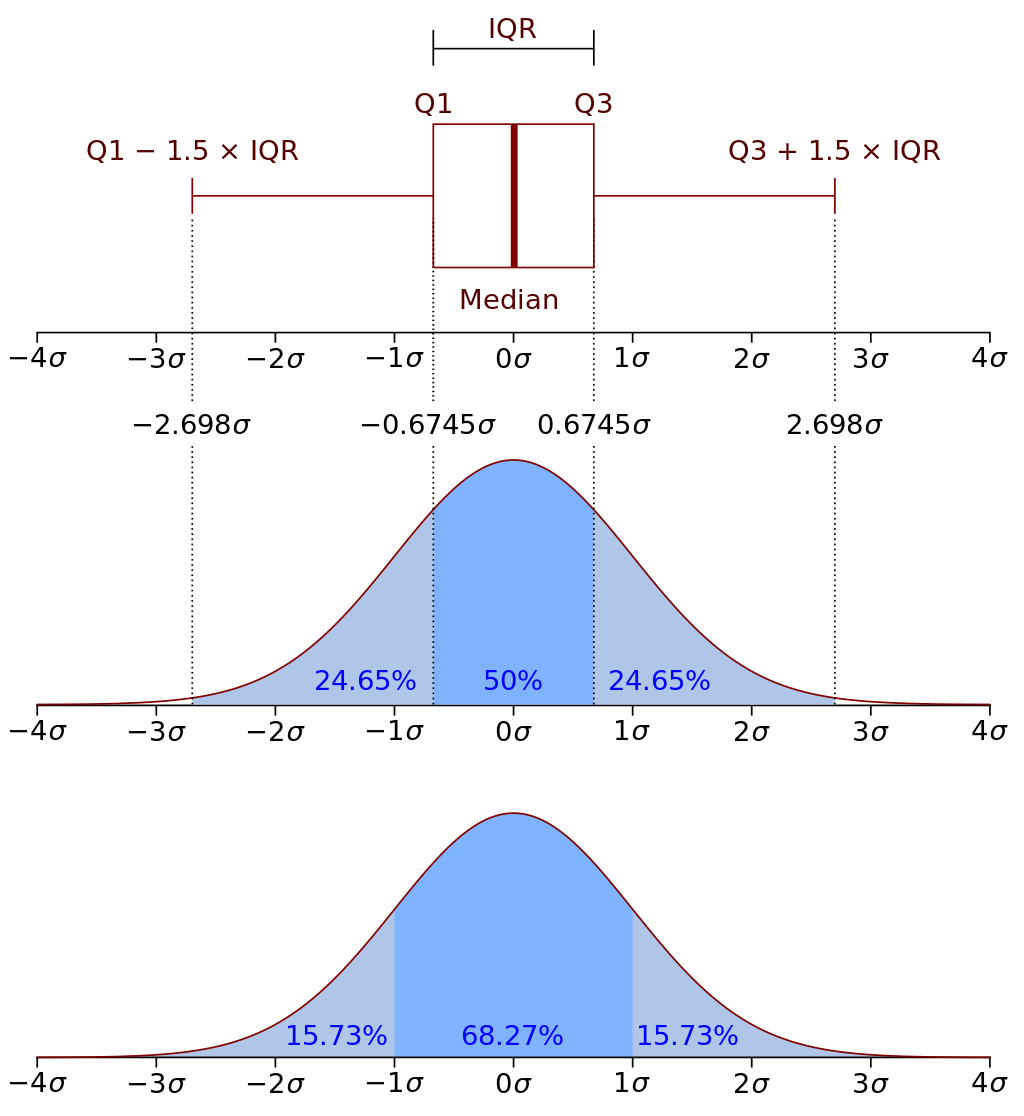
- 伽马分布(Gamma distribution):假设
为连续发生事件的等候时间,且这
次等候时间为独立的,那么这
(
)服从伽玛分布,即
#card=math&code=Y%20%5Csim%20%5CGamma%28%5Calpha%2C%5Cbeta%29),其中
,这里的
- 卡方分布(Chi-square distribution):若
个随机变量
是相互独立且符合标准正态分布(数学期望为0,方差为1)的随机变量,则随机变量
的平方和
被称为服从自由度为
#card=math&code=X%20%5Csim%20%5Cchi%5E2%28k%29)。

若有收获,就点个赞吧
0 人点赞
