paper: https://arxiv.org/abs/2203.08679
代码仓库:https://github.com/megvii-research/mdistiller/blob/master/mdistiller/distillers/DKD.py
Intuition
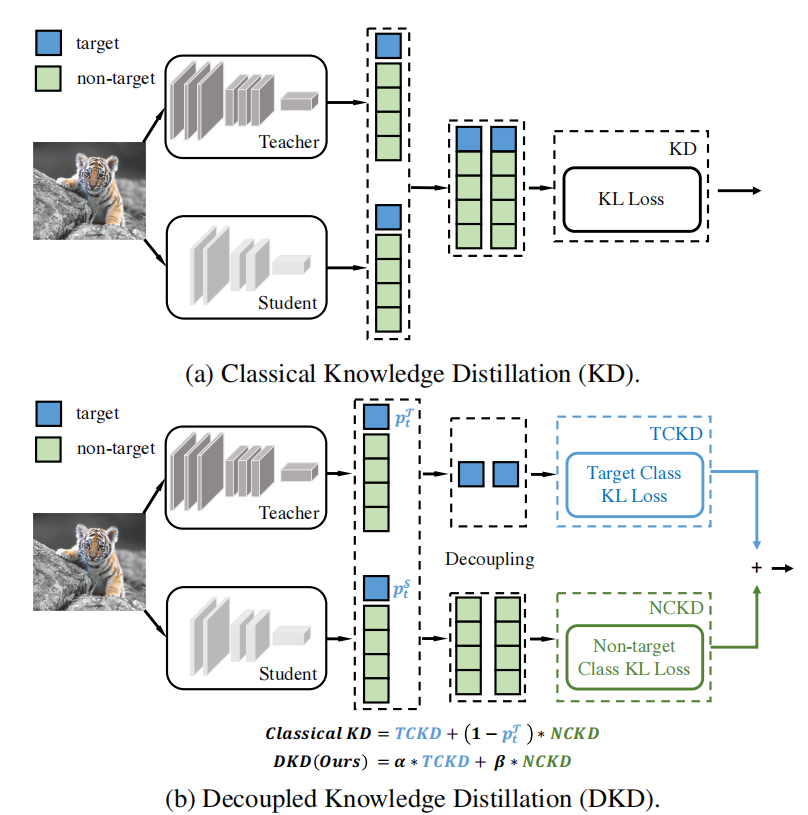
论文中说现在SoTA的蒸馏方法是对中间层的特征进行蒸馏,因为其含有高级的语义信息(Semantic feature),但是直接对网络输出的logits进行蒸馏的效果却不是很好。这很违反直觉,因为按照道理,logits应该含有更高的语义信息才对。
解耦(decouple)
为此作者将标准的知识蒸馏的loss解耦为下面公式
第一项称之为Target Class Knowledge Distillation,第二项称之为Non-target Class Knowledge Distillation。
Firstly, we divide a classification prediction into two levels: (1) a binary prediction for the target class and all the non-target classes _and (2) a multi-category prediction for _each non-target class.
推导
下面我们来一步一步地推导。
首先,对于经典的KD方法,输出概率为 ,
, 是总共的类别数,
是总共的类别数, 是logits。
是logits。
我们将其解耦为ground truth的部分 和不为ground truth的部分
和不为ground truth的部分 (对于论文中的target和non-target):
(对于论文中的target和non-target):
定义一个 表示non-target的部分(注意现在就不是多个类别了)
表示non-target的部分(注意现在就不是多个类别了)
至此,我们就可以将经典的KD loss改写为下面式子:
然后就可以写为这样
第一项就是TCKD,第二项就是NCKD。
表现
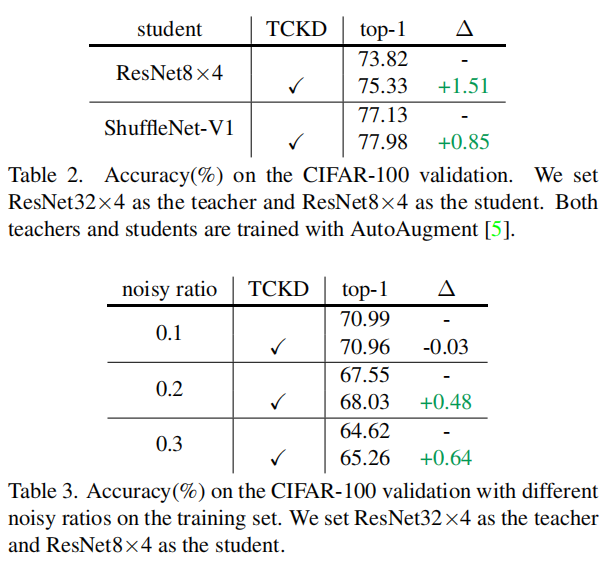
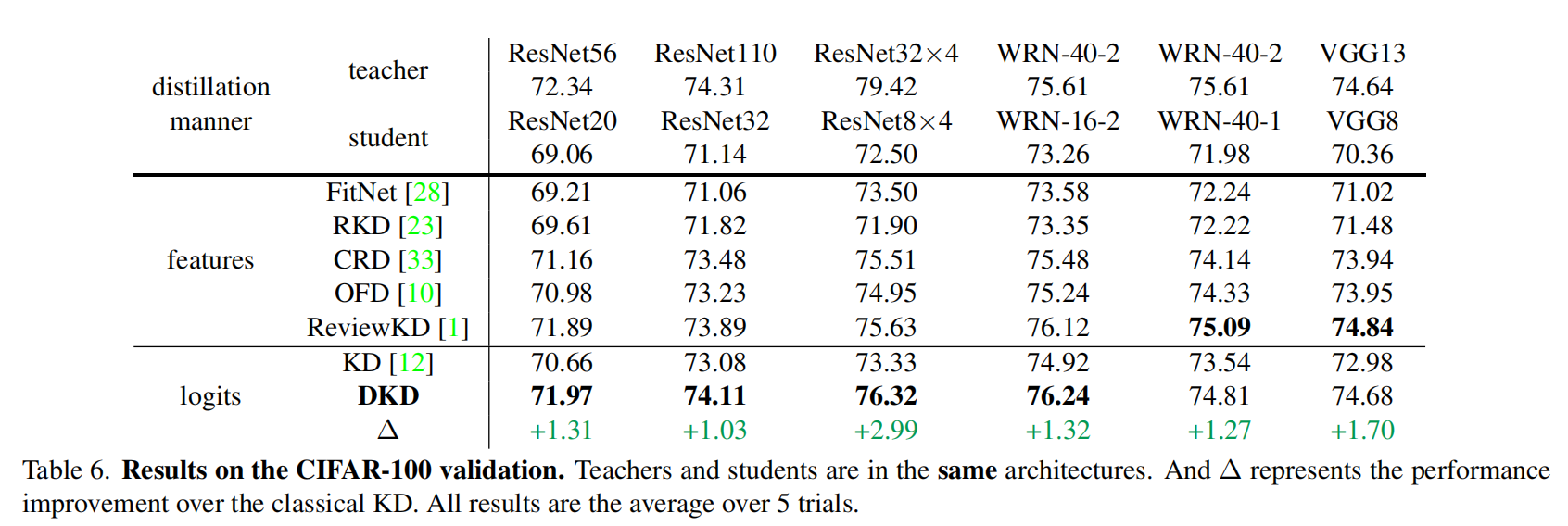
作者经过实验认为NCKD在KD中的贡献很大,在一些干净的数据集上可以和经典KD媲美甚至好于KD。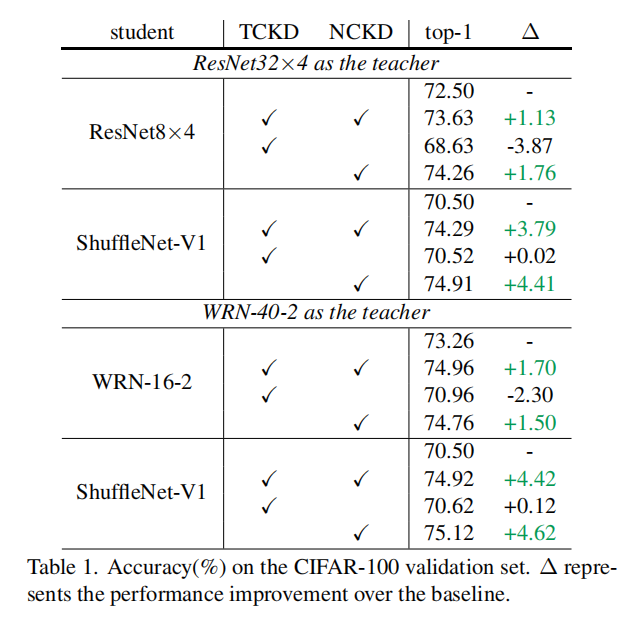
当然TCKD也不是没有用,在一些很难的任务上可以发挥很大的作用。

代码
def dkd_loss(logits_student, logits_teacher, target, alpha, beta, temperature):gt_mask = _get_gt_mask(logits_student, target)other_mask = _get_other_mask(logits_student, target)pred_student = F.softmax(logits_student / temperature, dim=1)pred_teacher = F.softmax(logits_teacher / temperature, dim=1)pred_student = cat_mask(pred_student, gt_mask, other_mask)pred_teacher = cat_mask(pred_teacher, gt_mask, other_mask)log_pred_student = torch.log(pred_student) # 使用teacher去指导student,需要将student log一下# 对应论文中的KL(\bm b^T\| \bm b^S)tckd_loss = (F.kl_div(log_pred_student, pred_teacher, size_average=False)* (temperature**2)/ target.shape[0])# 对应论文中的KL(\hat {\bm p}^T\| \hat {\bm p}^S)pred_teacher_part2 = F.softmax(logits_teacher / temperature - 1000.0 * gt_mask, dim=1)log_pred_student_part2 = F.log_softmax(logits_student / temperature - 1000.0 * gt_mask, dim=1)nckd_loss = (F.kl_div(log_pred_student_part2, pred_teacher_part2, size_average=False)* (temperature**2)/ target.shape[0])return alpha * tckd_loss + beta * nckd_lossdef _get_gt_mask(logits, target):target = target.reshape(-1)mask = torch.zeros_like(logits).scatter_(1, target.unsqueeze(1), 1).bool()return maskdef _get_other_mask(logits, target):target = target.reshape(-1)mask = torch.ones_like(logits).scatter_(1, target.unsqueeze(1), 0).bool()return maskdef cat_mask(t, mask1, mask2):'''将target变成binary的形式'''t1 = (t * mask1).sum(dim=1, keepdims=True) # target classt2 = (t * mask2).sum(1, keepdims=True)# non-target classrt = torch.cat([t1, t2], dim=1) # concatenatereturn rt
测试
logits_s = torch.tensor([[.2, .3, .5, .9], [1.1, .3, .02, .9]])
logits_t = torch.tensor([[.4, .1, .5, 1.3], [0.9, .1, .02, 1.2]])
target = torch.tensor([3, 3], dtype=torch.int64)
dkd_loss(logits_s, logits_t, target, alpha=0.1, beta=0.9, temperature=1)
输出:
tensor(0.0092)

若有收获,就点个赞吧
0 人点赞
