本文重点在讨论Transformer的Positional embedding的形式。
笔者碎碎念:本文需要读者有基本的Transformer的知识。
参考链接:
1. Rotary Embeddings: A Relative Revolution
2. 让研究人员绞尽脑汁的Transformer位置编码
codebase:
TF版本:https://github.com/ZhuiyiTechnology/roformer
Pytorch版本:https://github.com/JunnYu/RoFormer_pytorch
各种不同的形式
总得来说,Transformer中的位置编码有下面几种:
- 绝对位置编码(可学习、三角、递归、相乘)
- 相对位置编码(经典、XLNET、T5、DeBERTa)
- 其他(CNN、复数)
各种位置编码的数学表达可以看参考链接2的文章,在本文不过多赘述。
Rotary Postional Embedding(RoPE)
位置编码的选择通常需要在简单、灵活和效率之间做取舍。一个绝对位置编码很简单,但是可能泛化能力并不好,比如预训练的模型的句子长度与下游任务不一致。
Intuition
我们想要找到一个位置编码函数 ,
, 表示位置,
表示位置, 可以为
可以为 或者
或者 (分别表示query和key),其位置分别为
(分别表示query和key),其位置分别为 。那么在计算attention的时候,他们之间的内积
。那么在计算attention的时候,他们之间的内积 应该只与
应该只与 的值以及他们的相对位置
的值以及他们的相对位置 有关。
有关。
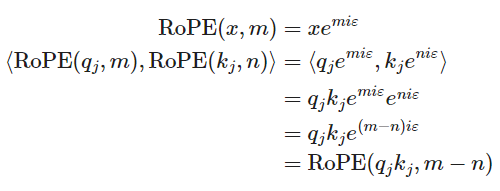
做法
RoPE将query表示为 。
。
一旦位置编码被嵌入,内积的形式如下: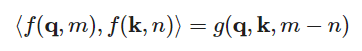
我们将位置编码函数写为复数的形式: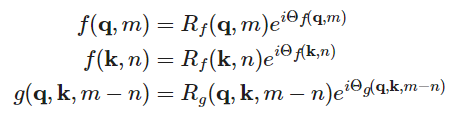
计算内积的相等形式为: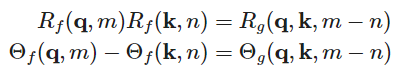
假设 ,应用初始条件
,应用初始条件 ,代入第一个式子得到:
,代入第一个式子得到: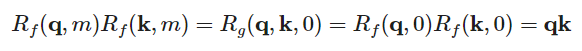
那我们可以假设 。
。
对于第二个式子得到 ,那么
,那么 可以分解为
可以分解为 。对于
。对于 有:
有: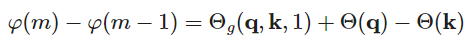
可以看出右边的式子与 无关,因此设置
无关,因此设置 ,并且有
,并且有 。
。
那么结合上述式子可以得到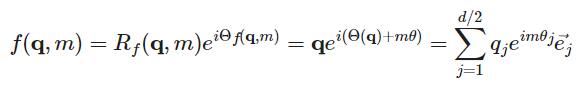
对于 也是一样的形式。
也是一样的形式。
在实现的过程中,需要写为矩阵形式而不是复数: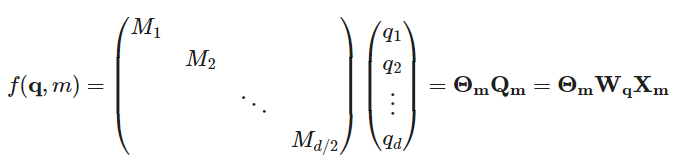
其中 ,也即:
,也即: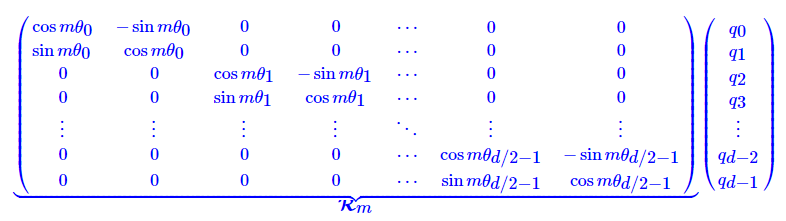
也就是说给位置为 的
的 乘上矩阵
乘上矩阵 ,位置为
,位置为 的
的 乘上矩阵
乘上矩阵 ,再做Attention就可以包含相对位置信息了:
,再做Attention就可以包含相对位置信息了:
并且可以看出矩阵很稀疏,所以直接进行矩阵乘法消耗很大,可以直接由下面算式实现: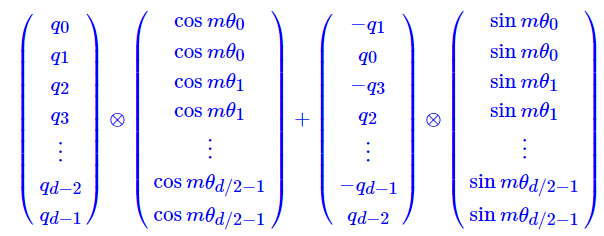
拓展到高维
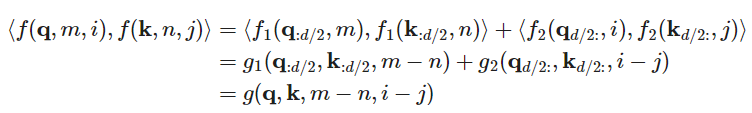
代码实现
看代码 的实现是按照google的余弦位置嵌入实现,即
的实现是按照google的余弦位置嵌入实现,即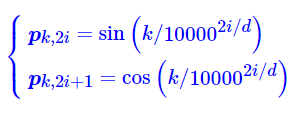
# Copied from transformers.models.marian.modeling_marian.MarianSinusoidalPositionalEmbedding with Marian->RoFormerclass RoFormerSinusoidalPositionalEmbedding(nn.Embedding):"""This module produces sinusoidal positional embeddings of any length."""def __init__(self, num_positions: int, embedding_dim: int, padding_idx: Optional[int] = None):super().__init__(num_positions, embedding_dim)self.weight = self._init_weight(self.weight)@staticmethoddef _init_weight(out: nn.Parameter):"""Identical to the XLM create_sinusoidal_embeddings except features are not interleaved. The cos features are inthe 2nd half of the vector. [dim // 2:]"""n_pos, dim = out.shapeposition_enc = np.array([[pos / np.power(10000, 2 * (j // 2) / dim) for j in range(dim)]for pos in range(n_pos)])out.requires_grad = False # set early to avoid an error in pytorch-1.8+sentinel = dim // 2 if dim % 2 == 0 else (dim // 2) + 1# 前0到dim//2为sin# 后dim//2为cosout[:, 0:sentinel] = torch.FloatTensor(np.sin(position_enc[:, 0::2]))out[:, sentinel:] = torch.FloatTensor(np.cos(position_enc[:, 1::2]))out.detach_()return out@torch.no_grad()def forward(self, seq_len: int, past_key_values_length: int = 0):"""`input_ids_shape` is expected to be [bsz x seqlen]."""positions = torch.arange(past_key_values_length,past_key_values_length + seq_len,dtype=torch.long,device=self.weight.device,)return super().forward(positions)# .....# google sinusoidal# [sequence_length, embed_size_per_head] -> sin & cos [batch_size, num_heads, sequence_length, embed_size_per_head // 2]sinusoidal_pos = self.embed_positions(hidden_states.shape[1], past_key_values_length)[None, None, :, :].chunk(2, dim=-1)# [1(bs),1(num_head),seq_len,embed_sz//2]
然后才是旋转
@staticmethod
def apply_rotary(x, sinusoidal_pos):
sin, cos = sinusoidal_pos # 这里直接拿出sin,cos
# rotary matrix M=[cos(m\theta) -sin(m\theta)\\
# sin(m\theta) cos(m\theta)]
x1, x2 = x[..., 0::2], x[..., 1::2] # 分奇偶拿出x1,x2
# 以query为例,x1=[q0,q2,...,qd], x2=[q1,q3,...,q(d-1)]
# 如果是旋转query key的话,下面这个直接cat就行,因为要进行矩阵乘法,最终会在这个维度求和。(只要保持query和key的最后一个dim的每一个位置对应上就可以)
# torch.cat([x1 * cos - x2 * sin, x2 * cos + x1 * sin], dim=-1)
# 如果是旋转value的话,下面这个stack后再flatten才可以,因为训练好的模型最后一个dim是两两之间交替的。
return torch.stack([x1 * cos - x2 * sin, x2 * cos + x1 * sin], dim=-1).flatten(-2, -1)

若有收获,就点个赞吧
0 人点赞
