本文包含三篇有关于DETR的改进,都是IDEA(粤港澳大湾区数字经济研究院)发表的,时间间隔不长。三篇文章循序渐进,是非常棒的工作。
这三篇文章分别是DAB-DETR、DN-DETR和DINO(不是对比学习的那篇)。
paper:DAB-DETR,DN-DETR,DINO
codebase:DAB-DETR,DN-DETR,DINO
总的来说,这三篇文章的贡献将DETR训练难,时间长,精度低的缺点全部解决,甚至使用在经过预训练(使用Object365)之后的SwinL作为主干网络在MS-COCO上取得了SOTA的好成绩,这无疑是给DETR-like models的研究者们打了一剂强心针。
在阅读本文之前,需要读者有着基本的深度学习、目标检测和DETR的基本知识。 由于在撰写本文时,DN-DETR和DINO的代码还未公开,未基于代码的解读可能会有错误。并且,限于笔者水平,本文可能出现诸如笔误、解读错误等,还请读者怒斥。 2022/4/20
我对于这三篇文章的总结是:解耦、解耦再解耦。
DAB-DETR
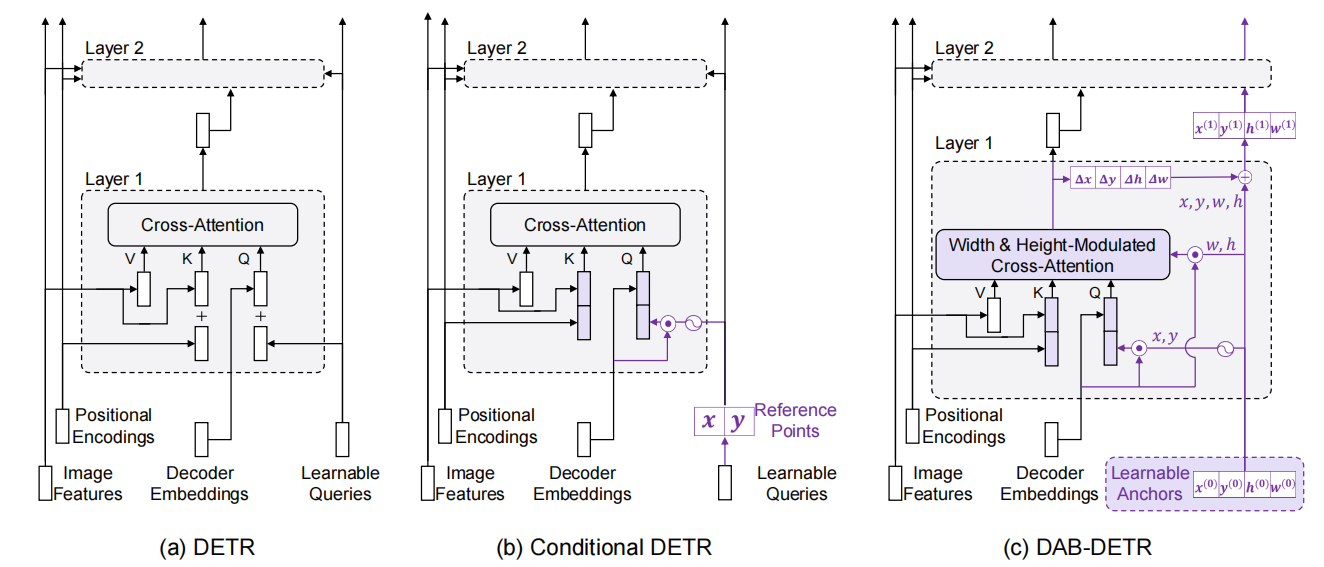
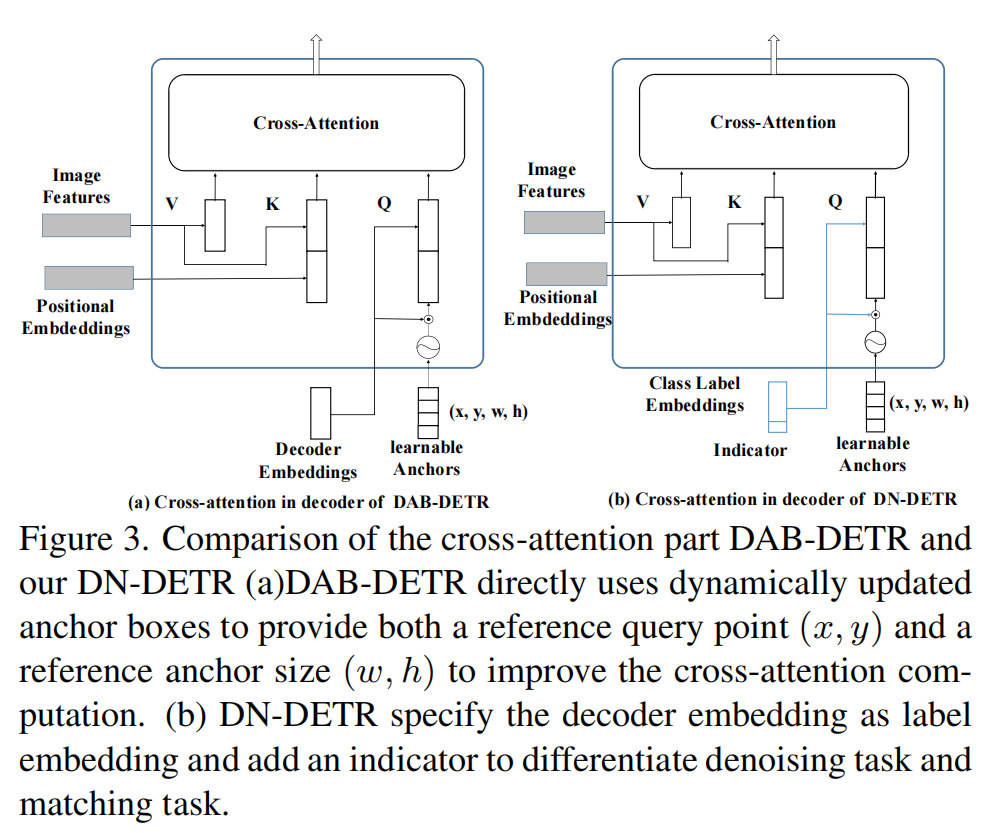
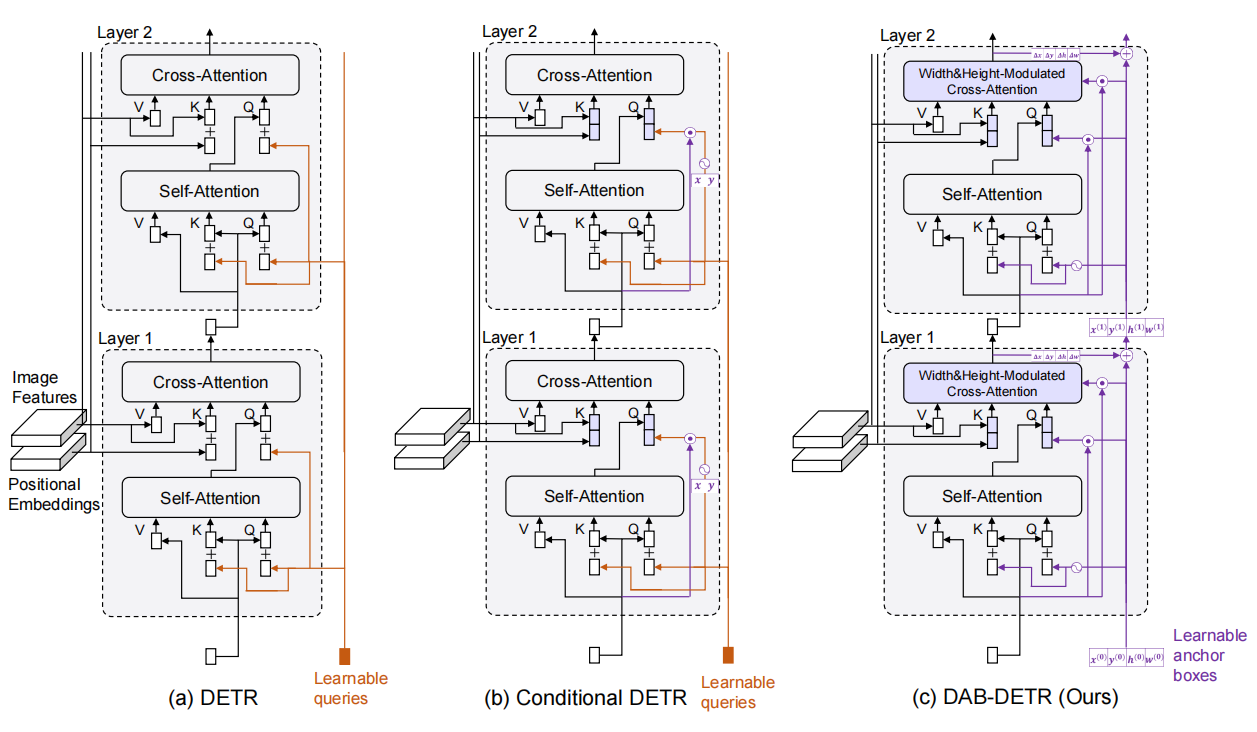
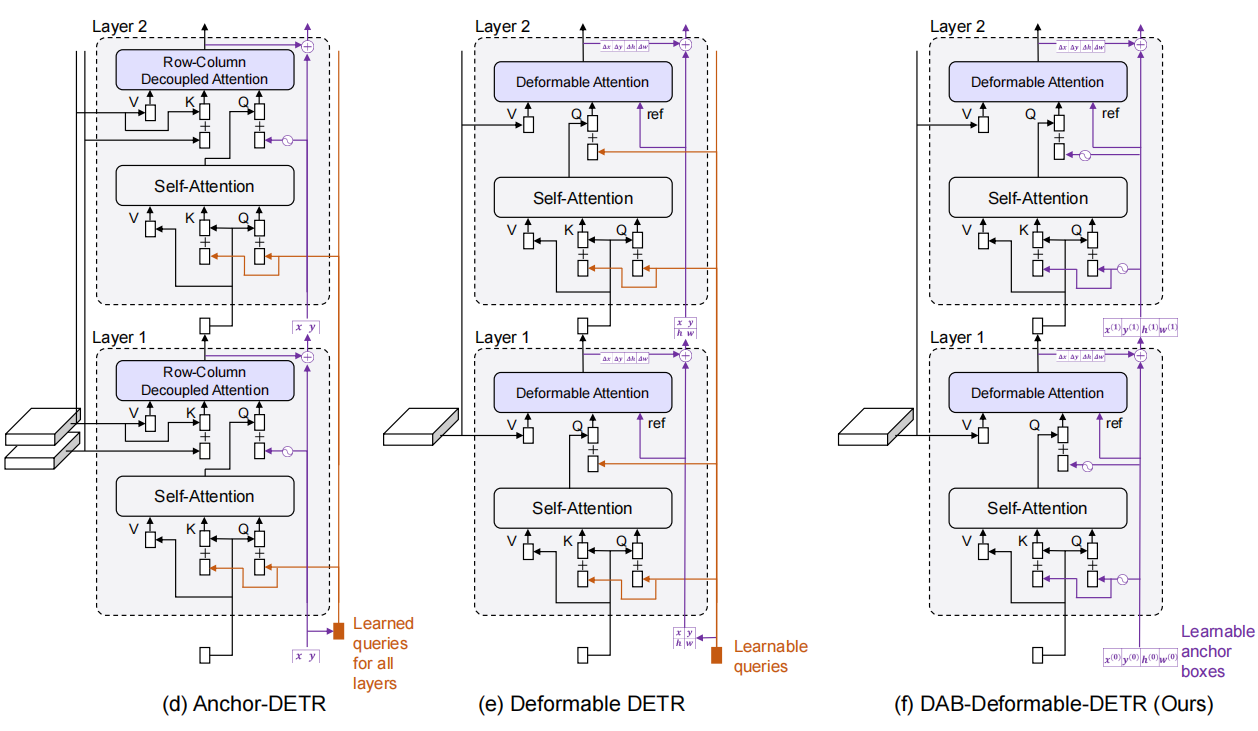
不同模型的decoder结构
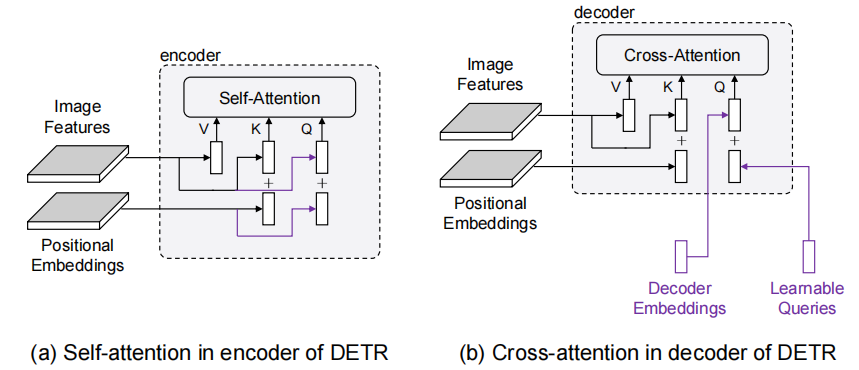
本文的思想在于正确地认识Transformer decoder query的作用,将query解耦成两部分:content query和positional query(文中将content query称为decoder embedding初始化为0;将positional query称为learnable anchors,显式地表示为 的形式),并且将learnable anchors动态更新。
的形式),并且将learnable anchors动态更新。
The key insight behind this formulation is that each query in DETR is formed by two parts: a content part (decoder self-attention output) and a positional part (e.g. learnable queries in DETR)
query的作用
作者认为:query是一种类似于soft-ROI的机制,在feature map上选定物体的大致位置(position),并且pool(原文如此)出相应的feature,而这在DETR中被耦合到了一起。
作者在这里显示地表示出来,有利于一层层地进行优化(每一层预测一个offset加在原来的learnable anchors上面),并且有加速训练的作用。
这里显式地表示为4D的bbox的形式也是一种先验(positional prior)。
为了和Conditional DETR对比,作者在这里阐述,Conditional DETR考虑了bbox的位置即 ,而真实的物体往往有不同的大小,因此需要考虑不同的长宽比。
,而真实的物体往往有不同的大小,因此需要考虑不同的长宽比。
为什么位置先验能够加速训练?
作者认为:因为每一次经过decoder的时候,其中的decoder embedding都被初始化为0,他们都被投影到同一个区域。而与encoder不同的是,encoder传入的是带有图像信息的query,因此收敛慢的原因很可能出在decoder的query上。
基于该问题,作者提出了两种假设:1)query优化很难;2)在learnable query上位置信息并没有像图像信息加入余弦位置那样被嵌入进去。
为了验证第一个猜想,作者直接使用训练好的query(并且fix住)进行训练,结果发现并没有加快收敛。因此第一个猜想是不对的。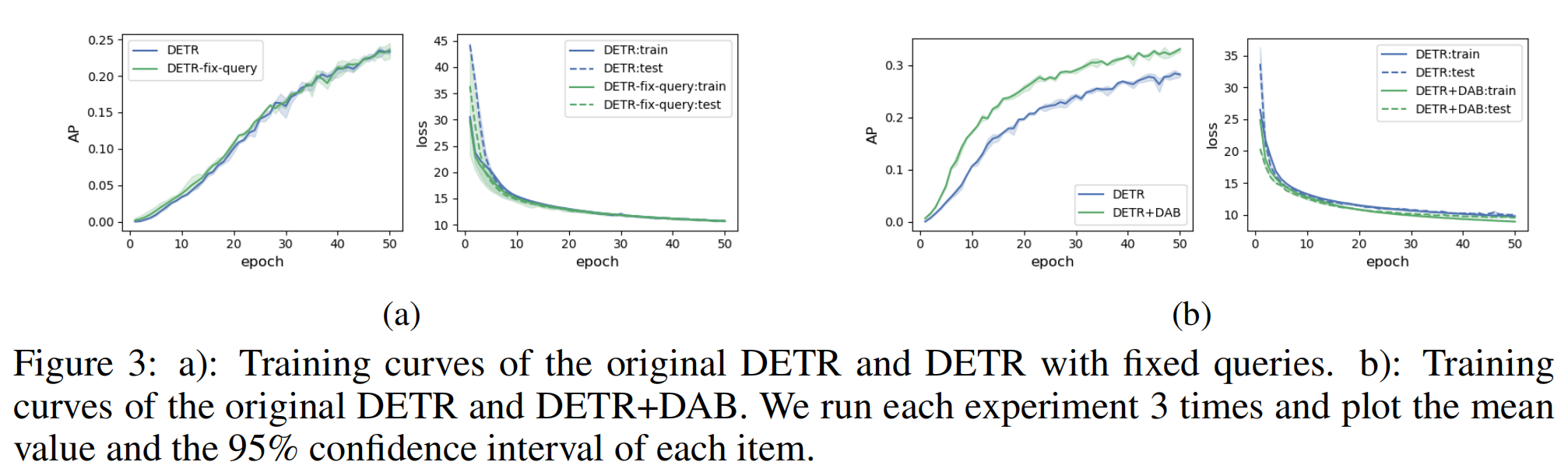
为了验证第二个猜想,作者猜测是否learnable query是否有一些我们不想要的性质,于是将query可视化了出来(positional attention maps)。可以看出,每一个query被当做一个指导decoder注意到可能有物体区域的先验(positional prior)。
进一步可以看出DETR的可视化图分布的比较稀疏,而且在不同的区域(不同的物体)有着较高的Attention,由于DETR类型的模型在预测时,每一个query表示一个物体(类别和位置),通常同一个物体不会分布在两个地方,所以这里的query的分布是不合理的。
而Conditional DETR分布地较为聚集,不会有分散在不同地方的情况,但是它的注意力的区域大小是几乎一样的(原形),这与它只优化了位置有关系。
在DAB-DETR中,由于直接优化4D的anchor,于是可以看出,它的注意力大小是不同的,而且分布紧密。
decoder的整体架构
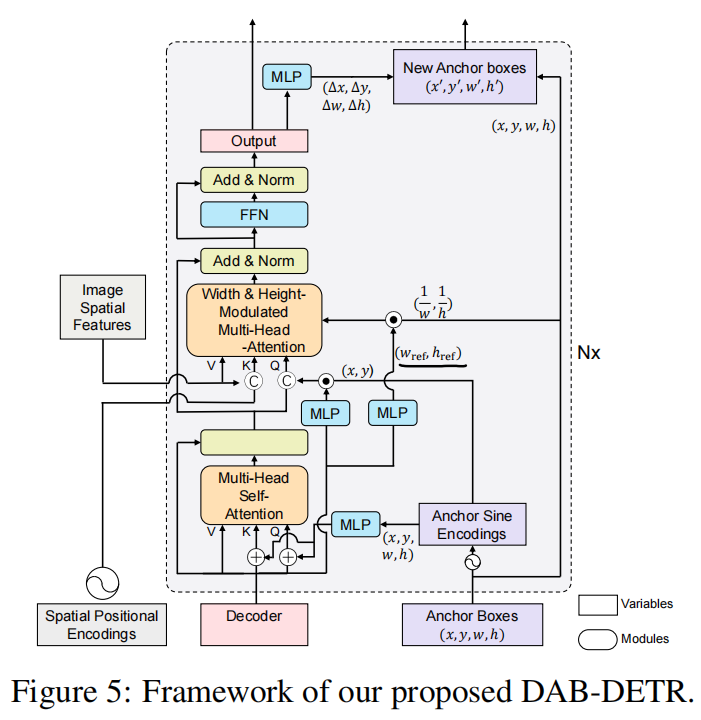
直接对anchor box进行优化
符号:第 个anchor
个anchor ,
, 表示content query和positional query。
表示content query和positional query。
首先对于anchor进行位置嵌入:
MLP是2D维输入,D维输出。 表示将位置的每一个元素都进行位置嵌入(将一个浮点数转换为维度是
表示将位置的每一个元素都进行位置嵌入(将一个浮点数转换为维度是 的向量并且cat起来。
的向量并且cat起来。
对于decoder中的self attention,他们就如公式中计算(当然对应图):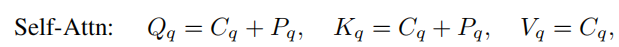
对于cross attention部分,相对复杂一点:
 是encoder输出的feature token,
是encoder输出的feature token, 这一部分表示content query经过一层D维到D维的MLP之后与Postional embedding做点乘,可以理解为将pe重新放缩。由于K和V来源于图像,所以K的pe来自于spatial positional encoding(如图,也是来自于encoder)。
这一部分表示content query经过一层D维到D维的MLP之后与Postional embedding做点乘,可以理解为将pe重新放缩。由于K和V来源于图像,所以K的pe来自于spatial positional encoding(如图,也是来自于encoder)。
长度高斯核
为了解决物体长宽比不一样没有引入到query的问题,作者这里给出了改造positioal attention maps的公式(在softmax之前)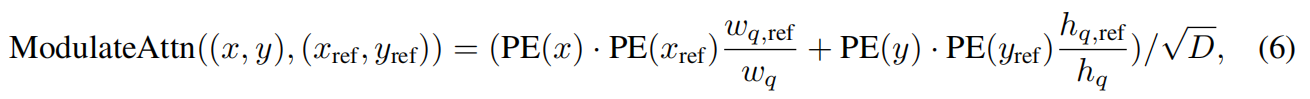
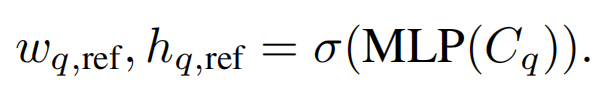
PE怎么做
作者直接follow了原Transformer的PE公式,但是将 改为了20,具体因为NLP句子的长度是整数,而CV中的是浮点数。
改为了20,具体因为NLP句子的长度是整数,而CV中的是浮点数。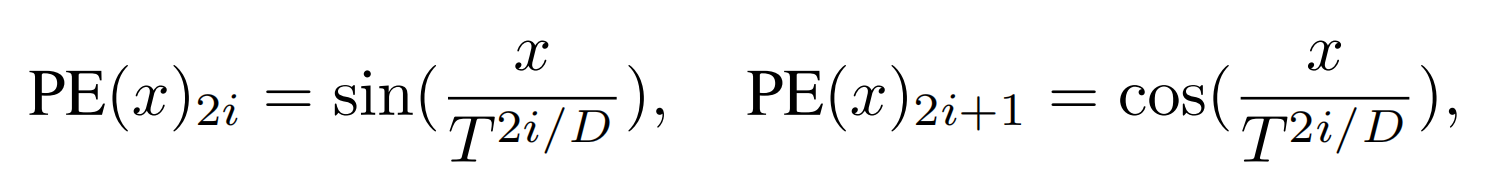
表现
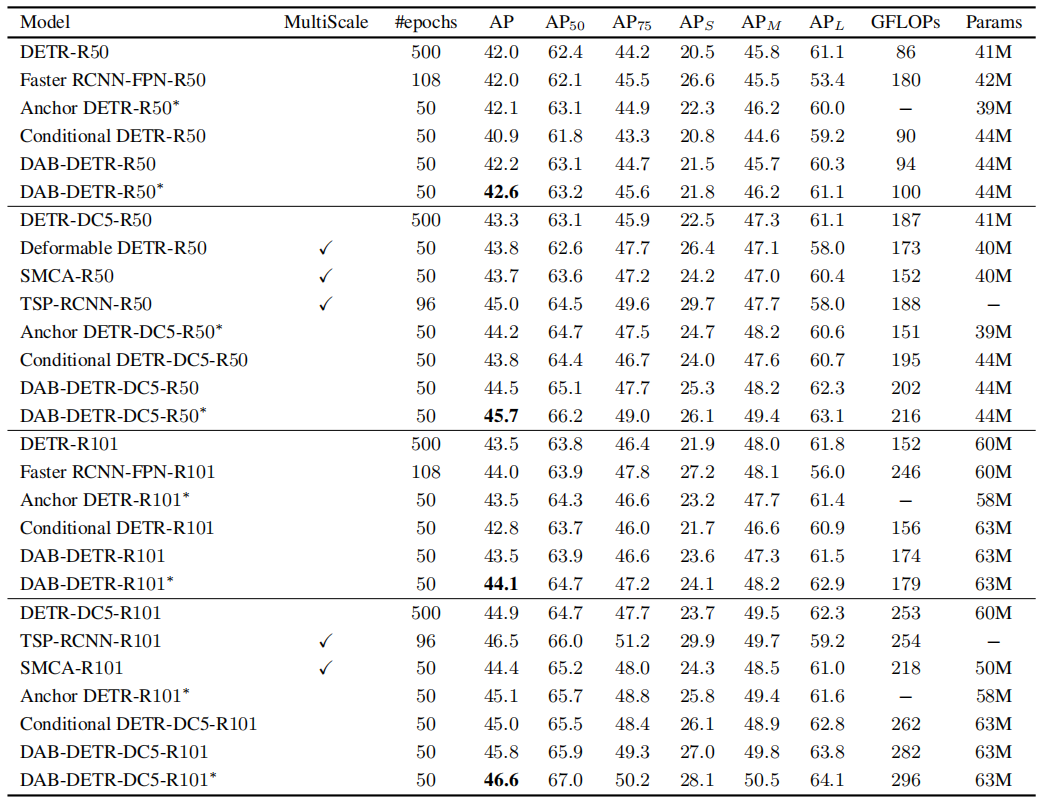
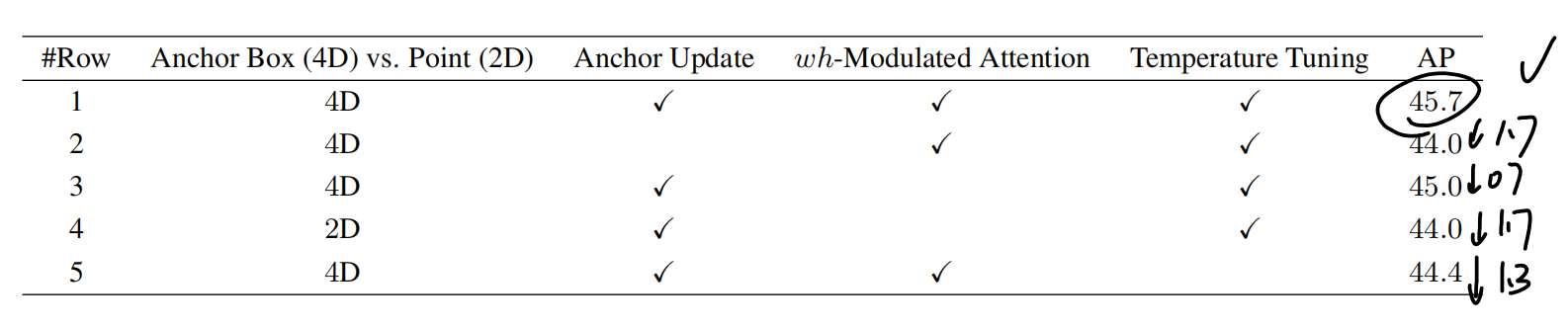
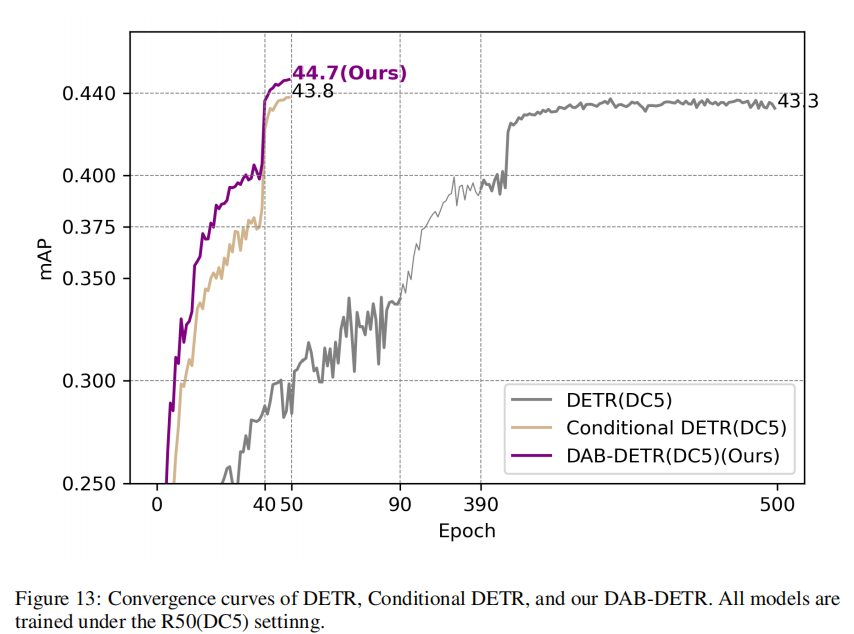
与其他模型的对比(decoder部分)
DN-DETR
本文在DETR的训练稳定性方面提出了新的方法。
作者认为DETR训练的不稳定来源于二向图的匹配过程,网络对于预测的bbox和类别与GT进行匹配,在训练的早期,优化的目标不稳定,导致训练的不稳定。
为解决这个问题,作者将其建模为denoise问题,将原先DETR的二向图匹配问题变成两部分:denoising part和matching part。
对于denoising part,作者将带有噪声的GT输入给decoder,要求网络输出GT。loss就是一个reconstruction loss,更具体的来说就是:对于类别来说是focal loss,对于bbox来说是L1和GIOU;对于matching part,还是二向图的匹配。
作者认为denoising part可以起到稳定和加速训练的作用。
为什么denosing part可以加速训练
为了进行二向图的匹配,DETR使用了匈牙利算法,后续的工作也基本沿用了这一算法。DETR将GT匹配的过程是动态的,会带来一些不稳定的问题。更新前后的网络可能对于相同的GT匹配到的bbox和class并不相同,从而带来不稳定性。
作者这里使用了denoising的方法,可以绕过二向图的匹配问题。作者在此验证了其方法的有效性:
在第 轮,被预测出来的物体为
轮,被预测出来的物体为 ,GT为
,GT为 。在进行二向图的匹配
。在进行二向图的匹配 之后,匹配的索引为
之后,匹配的索引为 。
。 的值为:
的值为:
这样作者就通过计算前后两轮的不同来表示第 轮的不稳定性
轮的不稳定性 :
:
 表示预测出来的物体的个数。
表示预测出来的物体的个数。 表示GT中物体的个数。
表示GT中物体的个数。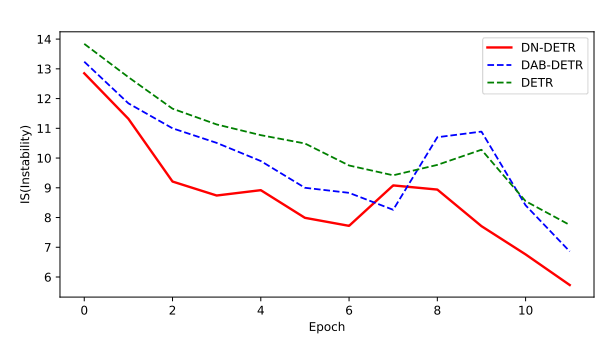
可以看出明显的DN-DETR比DETR的训练过程更加稳定。
denoising part
作者将带有噪声的GT输入给decoder,要求网络输出GT。noisy的GT可以被视为好的anchor(query可以视为4-D bbox)。
在DAB-DETR的基础上,作者将decoder embedding改为带有indicator的class label embeddings。
如何加noise
主要有两个方面:bbox中心的偏移和bbox的缩放。一些更加具体的设置可以原文中查找。
值得注意的是,在推理阶段,denoising part会被移除,只留下matching part。
attention mask
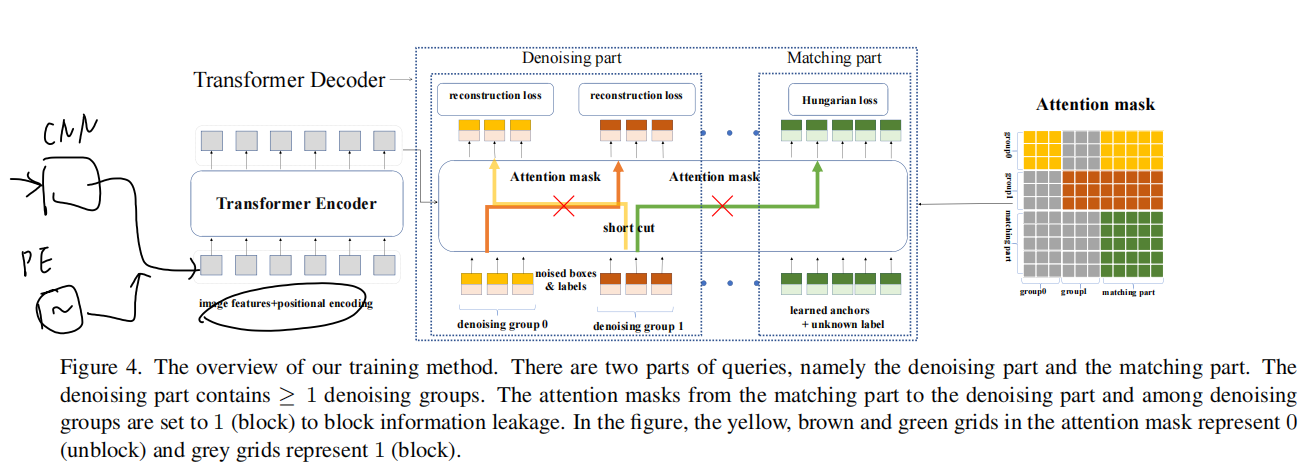
Attention mask是训练的denoising part的重要一部分。在介绍attention mask之前,先需要将带噪声的GT分成组,每一组就是一种(version)带noise的GT object。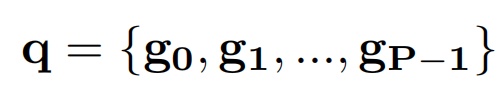
每一组都有 个query,
个query, 是GT的个数。
是GT的个数。
笔者猜测:因为输入的是一个mini-batch,每张图的GT不一样,那么query的个数需要相同,因此剩下的query就是learnable anchors。DETR有900个query,假设有
个组、DN-DETR有900个query,那么就有
个denoising query,剩下的query有
个。
由于分成了很多组,组与组之间不能有信息的交互;此外,denoising part和matching part不能有信息的交互,防止在denosing part的GT信息泄露到matching part中,导致学不到东西。
具体的Attention mask公式: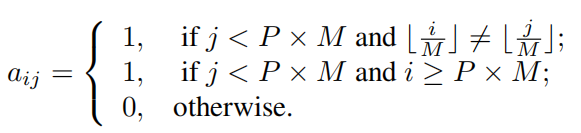
label embedding
label embedding中的indicator为1表示denoising part,为0表示mathcing part。
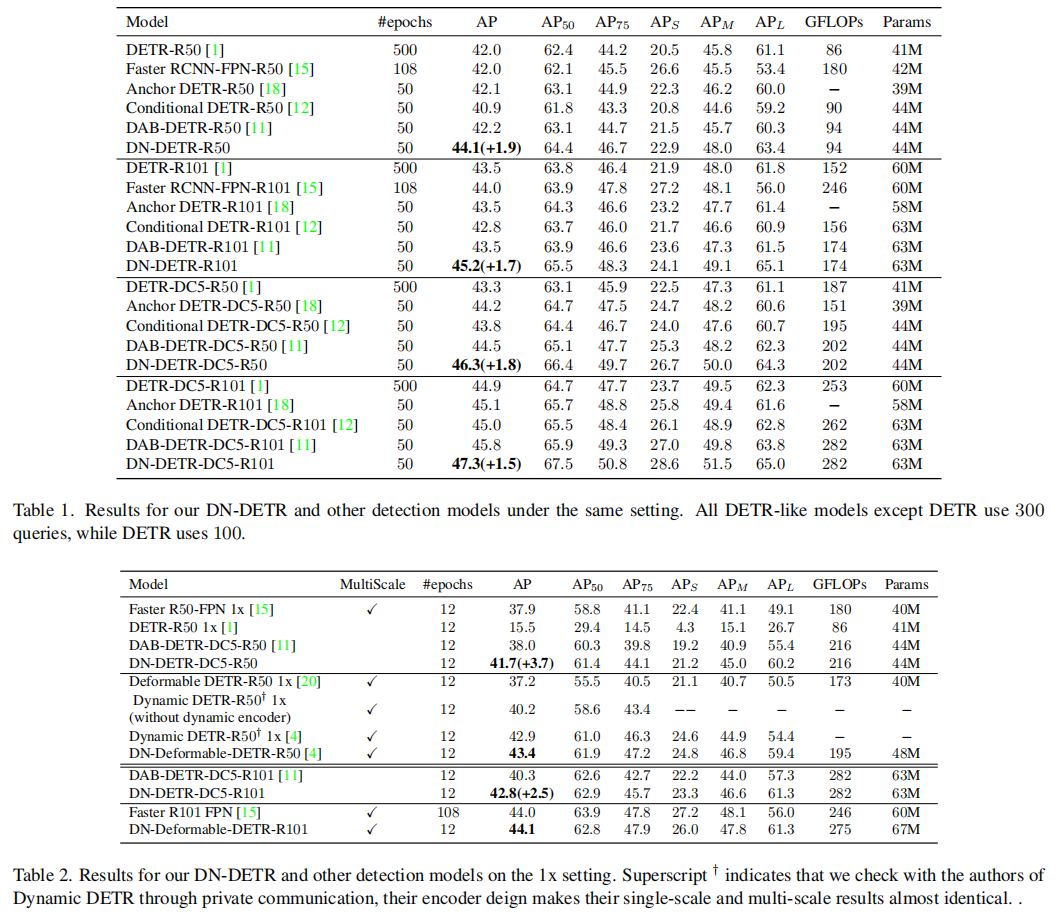
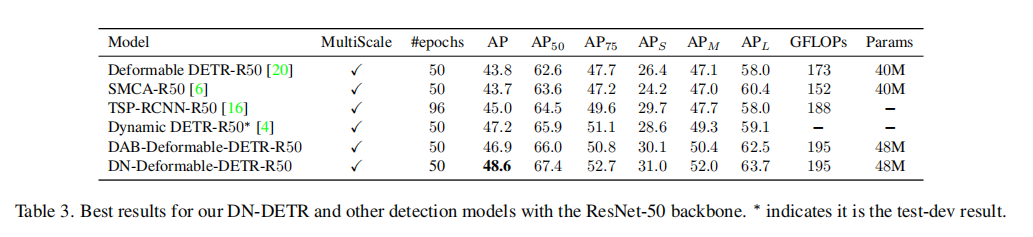
表现
DINO
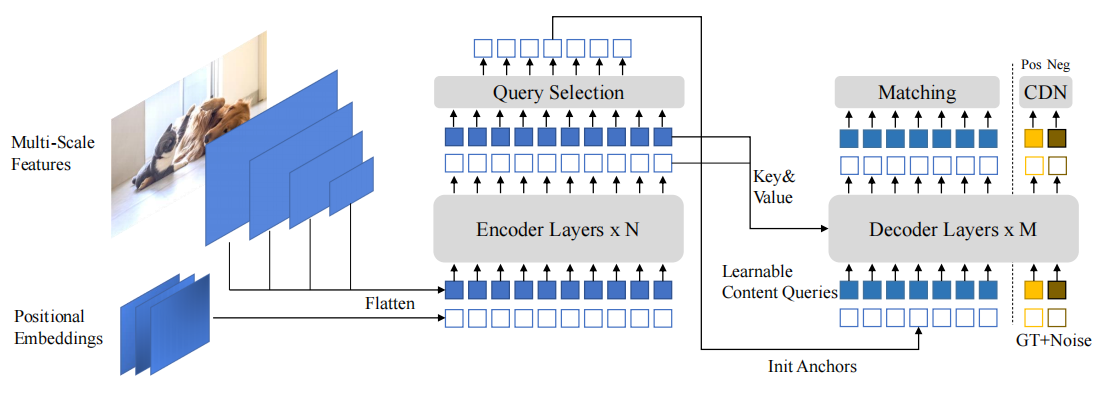
DINO综合前两者,在其基础上提出了使用对比的方法进行denoise,一个混合query的选择方法(为anchor的初始化),一个前向看两次(look forward twice)的方法用于bbox的预测。
并在使用在Object 365上预训练之后的SwinL作为backbone,其精度达到了63.2AP(COCO val 2017)和63.3AP(test-dev)。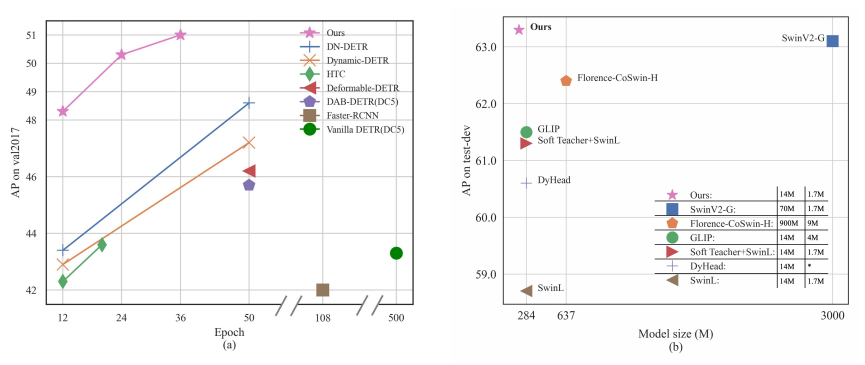

并且作者不但只在训练收敛慢(动态anchor)和训练不稳定(DN)这些前作已经探究过的任务进行了改进,而且在DETR类模型的scalability进行了探究,具体来说就是切换到大的主干网络和使用大的数据集的适应程度。
有了这些trick,DINO能在36轮达到51.0AP(主干网络为resnet 50),在小物体上具有更好的性能。
Constrastive Denoising(CDN)
由于在DN-DETR中,denoising part只看到了GT(带噪声),没有No Object,因此缺少了一种对anchor预测No Object的能力。
原来的DN-DETR只是加上了noise,但是DINO对noise进行了调整。对于噪声程度大小下的GT进行了区分,噪声小的为负样本,噪声大的为正样本。以此有两个超参数 分别控制噪声的大小。
分别控制噪声的大小。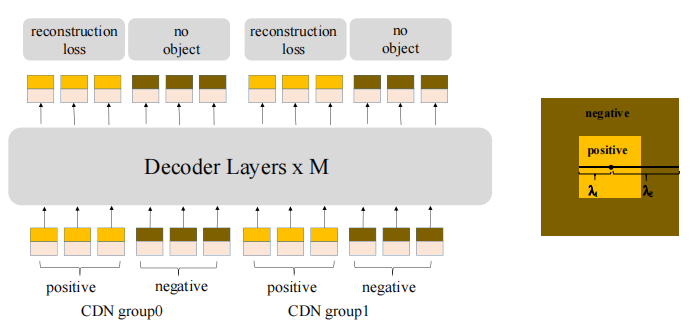
正样本(postive query)在正方形的中间,负样本(negtive query)在外面。类似于DN-DETR,query被分成了好几组,假设一张图片有 个GT box,那么每一组都有
个GT box,那么每一组都有 个query。
个query。
同样的,denoising bbox部分仍然是L1和GIOUloss,class部分是focal loss。因为引入了负样本作为背景(原文如此),区别负样本的loss是focal loss。
作者称CDN具有拒绝无用anchor的能力。
此外,作者对其为什么有作用进行了分析
有效性
为了验证其有效性,作者定义了ATK(average top-K Distance),使用它来测量在matching part中对应的anchor和GT的距离。使用top-K是由于在较远的距离,这种confusion的问题更严重。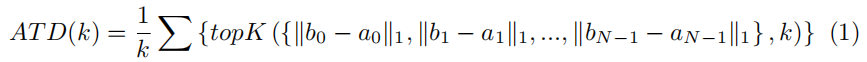
相减操作是计算L1距离。
Mixed Query Selection
这一部分主要受到deformable DETR的two-stage(原文如此,可能容易混淆,并不是Faster-RCNN的两阶段)的启发。
因为原来的DETR的decoder query是不会拿encoder的输出作为输入,在deformable DETR中,使用了一个query selection的方法,拿出top K个encoder输出的token加强decoder的query。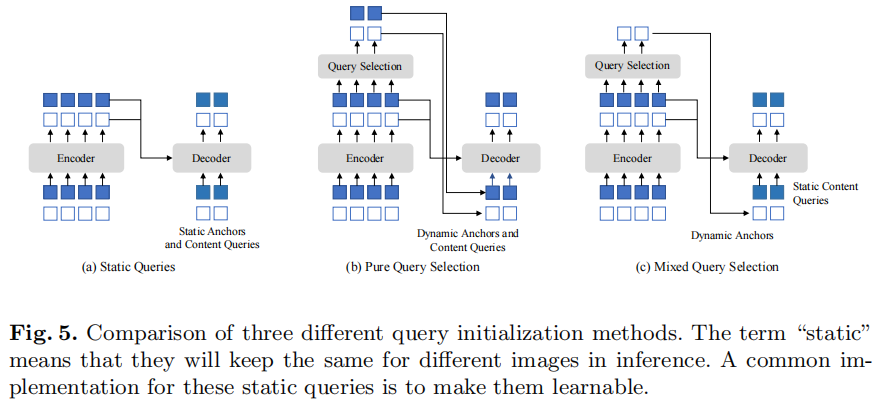
与deformable DETR不同的是,DINO只是将position token取了出来用来初始化anchor。
这样可以帮助模型使用更好的位置信息,去从encoder中提取更复杂的内容信息。
Look Forward Twice
新的box预测的方法。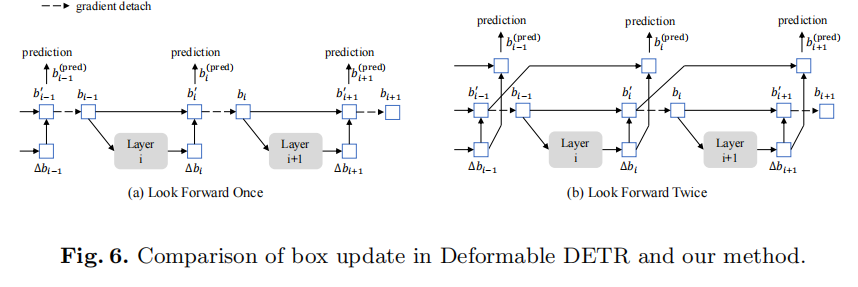
也是受到Deformable DETR的启发,在Deformable DETR中,在refine box的位置时,将梯度detach掉,以稳定训练,可以从图中看出,每个layer只会被预测自己预测出来的box的梯度更新。
与Deformable DETR不同的是,对 其梯度会传到第
其梯度会传到第 层和第
层和第 层。
层。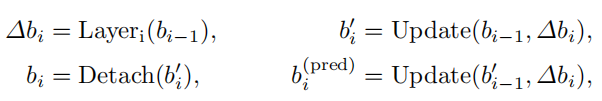
 就是图中的layer,用来计算offset。
就是图中的layer,用来计算offset。
表现
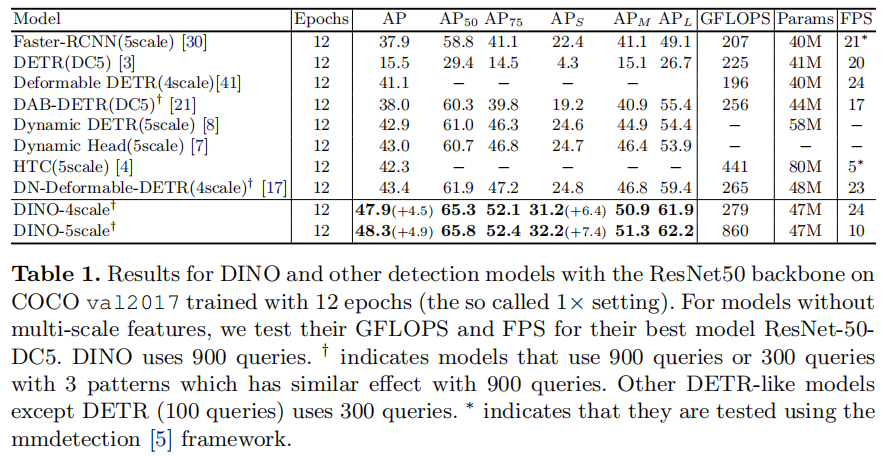
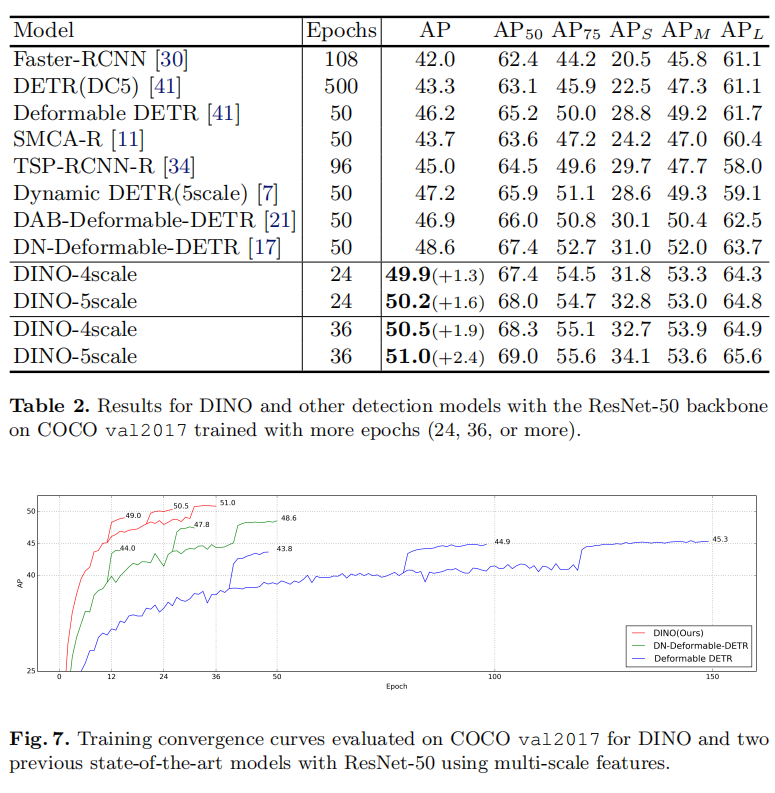
与SOTA模型的比较
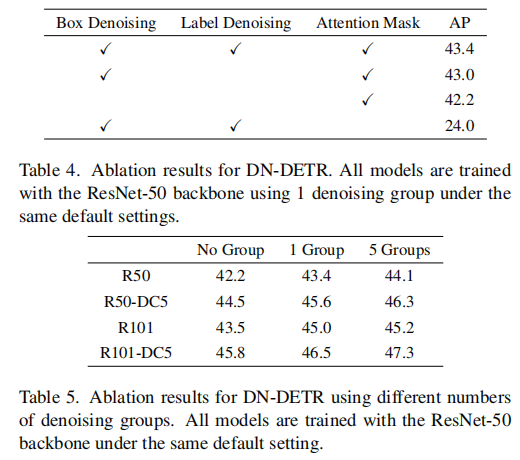
消融实验
更多详细的实验和结果参看原文实验和附录部分。
总结
总的来说,这三篇文章是一个连续的工作,对于decoder query的解释很有参考价值,提出的改进方法很有效。
鉴于DN-DETR和DINO的代码还未放出,可能会写一期DAB-DETR的代码解读文章。

若有收获,就点个赞吧
0 人点赞
