1.Base64
1、Base64编码介绍
之前在很多业务中都有见过或者用到过Base64编码,但一直一知半解,没有对它有一个深入的认识和理解。今天就来聊一聊Base64编码的问题。
首先要明确的是,Base64是一种可逆的编码方式,提到编码方式,我们首先想到的肯定是Ascii、GBK、Unicode这些常用的编码方法,那么Base64与这些编码方式有什么不同呢?
简单来将,Base64就是一种用64个Ascii字符来表示任意二进制数据的方法。主要用于将不可打印的字符转换成可打印字符,或者简单的说将二进制数据编码成Ascii字符。Base64是网络上最常用的传输8bit字节数据的编码方式之一。
Base64的原理其实很简单,首先,需要准备一个包含64个字符的表格(如下表),0~63分别对应了唯一一个字符,比如18对应的是S。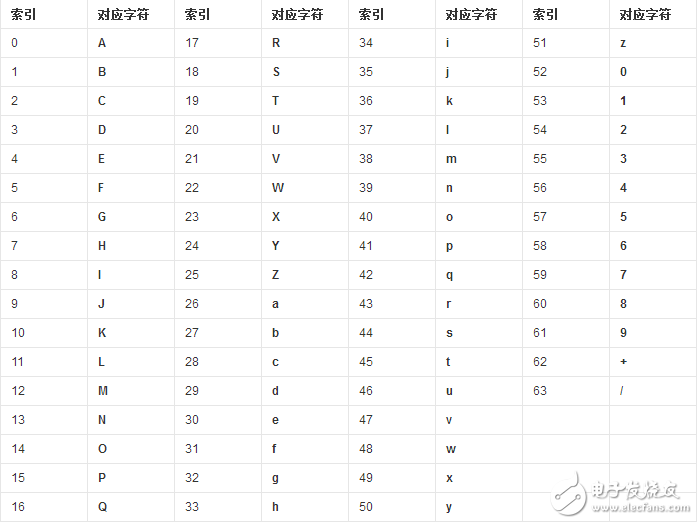
然后,对二进制数据进行处理,每3个字节一组,一共3x8=24bit,将这24bit划分为4组,每组正好6个bit,6bit的数据刚好可以表示0~63的范围,也就可以对应上表的64个字符。这样我们就得到了4个数字作为索引,然后查表获得相应的4个字符,就得到了编码后的字符串。下表将整个处理的过程描述的很清楚。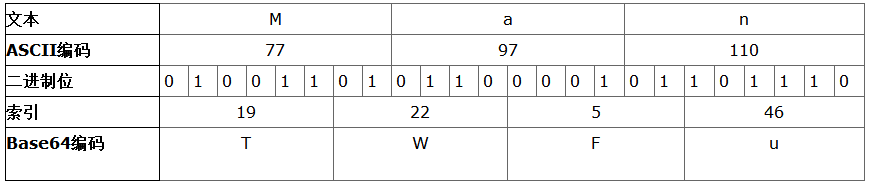
所以,Base64编码会把3字节的二进制数据编码为4字节的文本数据,长度增加为原来的4/3。如果要编码的二进制数据不是3的倍数,最后会剩下1个或2个字节怎么办?此时,需在原数据后面添加1个或2个零值字节,使其字节数是3的倍数。然后,在编码后的字符串后面添加1个或2个等号“=”,表示所添加的零值字节数。解码的时候,会自动去掉。
2、Base64作用
由于某些系统中只能使用ASCII字符。Base64就是用来将非ASCII字符的数据转换成ASCII字符的一种方法。
base64特别适合在http,mime协议下快速传输数据。
base64其实不是安全领域下的加密解密算法。虽然有时候经常看到所谓的base64加密解密。其实base64只能算是一个编码算法,对数据内容进行编码来适合传输。虽然base64编码过后原文也变成不能看到的字符格式,但是这种方式很初级,很简单。
3、Base64编码应用
Base64编码可用于在HTTP环境下传递较长的标识信息。例如,在Java Persistence系统Hibernate中,就采用了Base64来将一个较长的唯一标识符(一般为128-bit的UUID)编码为一个字符串,用作HTTP表单和HTTP GET URL中的参数。在其他应用程序中,也常常需要把二进制数据编码为适合放在URL(包括隐藏表单域)中的形式。此时,采用Base64编码不仅比较简短,同时也具有不可读性,即所编码的数据不会被人用肉眼所直接看到。
然而,标准的Base64并不适合直接放在URL里传输,因为URL编码器会把标准Base64中的“/”和“+”字符变为形如“%XX”的形式,而这些“%”号在存入数据库时还需要再进行转换,因为ANSI SQL中已将“%”号用作通配符。
为解决此问题,可采用一种用于URL的改进Base64编码,它不仅在末尾去掉填充的‘=’号,并将标准Base64中的“+”和“/”分别改成了“-”和“”,这样就免去了在URL编解码和数据库存储时所要作的转换,避免了编码信息长度在此过程中的增加,并统一了数据库、表单等处对象标识符的格式。
另有一种用于正则表达式的改进Base64变种,它将“+”和“/”改成了“!”和“-”,因为“+”,“*”以及前面在IRCu中用到的“[”和“]”在正则表达式中都可能具有特殊含义。
此外还有一些变种,它们将“+/”改为“-”或“.”(用作编程语言中的标识符名称)或“。-”(用于XML中的Nmtoken)甚至“:”(用于XML中的Name)。
其他应用
1)Mozilla Thunderbird和EvoluTIon用Base64来保密电子邮件密码
2)Base64 也会经常用作一个简单的“加密”来保护某些数据,而真正的加密通常都比较繁琐。
3)垃圾讯息传播者用Base64来避过反垃圾邮件工具,因为那些工具通常都不会翻译Base64的讯息。
4)在LDIF档案,Base64用作编码字串。
2 URL编码与解码原理
一、概述
在开始讨论编码解码之前,首先来明确一下问题。 什么是application/x-www-form-urlencoded字符串? 答:它是一种编码类型。当URL地址里包含非西欧字符的字符串时,系统会将这些字符转换成application/x-www-form-urlencoded字符串。
表单里提交时也是如此,当包含非西欧字符的字符串时,系统也会将这些字符转换成application/x-www-form-urlencoded字符串。
然而,在向服务器发送大量的文本、包含非ASCII字符的文本或二进制数据时这种编码方式效率很低。这个时候我们就要使用另一种
编码类型“multipart/form-data”,比如在我们在做上传的时候,表单的enctype属性一般会设置成“multipart/form-data”。
Browser端
表单的ENCTYPE属性值为multipart/form-data,它告诉我们传输的数据要用到多媒体传输协议,由于多媒体传输的都是大量的数据,所以规 定上传文件必须是post方法,的type属性必须是file。
二、Java URL编码解码API
该方法要求你自己指定编码形式。这两个类都不用初始化:
public class URLDecoder extends Object
public class URLEncoder extends Object
String text1 = java.net.URLEncoder.encode(“中国”, “utf-8”);
String text2 = java.net.URLDecoder.decode(text1, “utf-8”);
复制代码
这两条语句在同一个页面中的话,得到的结果是:
text1: %E4%B8%AD%E5%9B%BD
tex2: 中国
String China=new String(request.getParameter(“China”).getBytes(“iso8859_1”));
China=java.net.URLDecoder.decode(zhongguo,”utf-8”);
复制代码
1、URLEncoder
java提供了一个类URLEncoder把string编码成这种形式。Java1.2增加了一个类URLDecoder它能以这种形式解码string。这个方法之前总是用它所在平台的默认编码形式,所以在不同系统上,它就会产生不同的结果。但是在java1.4中,这个方法被另一种方法取代了。 特别需要注意的是这个方法编码了符号,“\” ,“&”,“=”,和“:”,并把空格(“ ”)转换成了(+)。它不会尝试着去规定在一个URL中这些字符怎样被使用。由此,你不得不分块编码你的URL,而不是把整个URL一次传给这个方法。这是很重要的,因为对类URLEncoder最通常的用法就是查询string,为了和服务器端使用GET方式的程序进行交互。 例如,假设你想编码这个string:
pg=q&kl=XX&stype=stext&q=+”Java+I/O”&search.x=38&search.y=3
复制代码
这段代码对其进行编码:
String query = java.net.URLEncoder.encode( “pg=q&kl=XX&stype=stext&q=+”Java+I/O”&search.x=38&search.y=3”);
System.out.println(query);
复制代码
不幸的是,得到的输出是:
pg%3Dq%26kl%3DXX%26stype%3Dstext%26q%3D%2B%22Java%2BI%2FO%22%26search.x%3D38%26search.y%3D3
复制代码
出现这个问题就是方法URLEncoder.encode( ) 在进行盲目地编码。它不能区分在URL或者查询string中被用到的特殊字符(像前面string中的“=”,和“&”)和确实需要被编码的字符。所以URL需要一次只编码一块。
2、URLDecoder
与URLEncoder 类相对应的URLDecoder 类有两种静态方法。它们解码以x-www-form-url-encoded这种形式编码的string。也就是说,它们把所有的加号(+)转换成空格符,把所有的%xx分别转换成与之相对应的字符:
public static String decode(String s) throws Exception
public static String decode(String s, String encoding) // Java 1.4 throws UnsupportedEncodingException
复制代码
如果string包含了一个“%”,但紧跟其后的不是两位16进制的数或者被解码成非法序列,该方法就会抛出IllegalArgumentException 异常。当下次再出现这种情况时,它可能就不会被抛出了。这是与运行环境相关的,当检查到有非法序列时,抛不抛出IllegalArgumentException 异常,这时到底会发生什么是不确定的。在Sun’s JDK 1.4中,不会抛出什么异常,它会把一些莫名其妙的字节加进不能被顺利编码的string中。这的确令人头疼,可能就是一个安全漏洞。
由于这个方法没有触及到非转义字符,所以你可以把整个URL作为参数传给该方法<如下面的qerry>。不用像之前那样分块进行,依然可以得到你想要的正确的解码结果。例如:
String input = “http://www.altavista.com/cgi-bin/“+”qerry?pg=q&kl=XX&stype=stext&q=%2B”Java+I%2FO”&search.x=38&search.y=3“;
try {
String output = java.net.URLDecoder.decode(input, “UTF-8”);
System.out.println(output);
}
复制代码
通常如果一样东西需要编码,说明这样东西并不适合传输。原因多种多样,如Size过大,包含隐私数据,对于Url来说,之所以要进行编码,是因为Url中有些字符会引起歧义。
例如,Url参数字符串中使用key=value键值对这样的形式来传参,键值对之间以&符号分隔,如/s?q=abc&ie=utf-8。如果你的value字符串中包含了=或者&,那么势必会造成接收Url的服务器解析错误,因此必须将引起歧义的&和=符号进行转义,也就是对其进行编码。
又如,Url的编码格式采用的是ASCII码,而不是Unicode,这也就是说你不能在Url中包含任何非ASCII字符,例如中文。否则如果客户端浏览器和服务端浏览器支持的字符集不同的情况下,中文可能会造成问题。
Url编码的原则:就是使用安全的字符(没有特殊用途或者特殊意义的可打印字符)去表示那些不安全的字符。 预备知识:URI是统一资源标识的意思,通常我们所说的URL只是URI的一种。典型URL的格式如下所示。下面提到的URL编码,实际上应该指的是URI编码。
foo://example.com:8042/over/there?name=ferret#nose
/ __/ /__/ /
| | | | |
scheme authority path query fragment
复制代码
哪些字符需要编码
RFC3986文档规定,Url中只允许包含英文字母(a-zA-Z)、数字(0-9)、-_.~4个特殊字符以及所有保留字符。RFC3986文档对Url的编解码问题做出了详细的建议,指出了哪些字符需要被编码才不会引起Url语义的转变,以及对为什么这些字符需要编码做出了相应的解释。 US-ASCII字符集中没有对应的可打印字符:Url中只允许使用可打印字符。US-ASCII码中的10-7F字节全都表示控制字符,这些字符都不能直接出现在Url中。同时,对于80-FF字节(ISO-8859-1),由于已经超出了US-ACII定义的字节范围,因此也不可以放在Url中。 保留字符:Url可以划分成若干个组件,协议、主机、路径等。有一些字符(:/?#[]@)是用作分隔不同组件的。例如:冒号用于分隔协议和主机,/用于分隔主机和路径,?用于分隔路径和查询参数,等等。还有一些字符(!$&’()*+,;=)用于在每个组件中起到分隔作用的,如=用于表示查询参数中的键值对,&符号用于分隔查询多个键值对。 当组件中的普通数据包含这些特殊字符时,需要对其进行编码。
RFC3986中指定了以下字符为保留字符:! * ‘ ( ) ; : @ & = + $ , / ? # [ ]
不安全字符:还有一些字符,当他们直接放在Url中的时候,可能会引起解析程序的歧义。这些字符被视为不安全字符,原因有很多。
空格:Url在传输的过程,或者用户在排版的过程,或者文本处理程序在处理Url的过程,都有可能引入无关紧要的空格,或者将那些有意义的空格给去掉。
引号以及<>:引号和尖括号通常用于在普通文本中起到分隔Url的作用
#:通常用于表示书签或者锚点
%:百分号本身用作对不安全字符进行编码时使用的特殊字符,因此本身需要编码
{}|[1]`~:某一些网关或者传输代理会篡改这些字符
需要注意的是,对于Url中的合法字符,编码和不编码是等价的,但是对于上面提到的这些字符,如果不经过编码,那么它们有可能会造成Url语义的不同。因此对于Url而言,只有普通英文字符和数字,特殊字符$-_.+!*’()还有保留字符,才能出现在未经编码的Url之中。其他字符均需要经过编码之后才能出现在Url中。
但是由于历史原因,目前尚存在一些不标准的编码实现。例如对于符号,虽然RFC3986文档规定,对于波浪符号,不需要进行Url编码,但是还是有很多老的网关或者传输代理会进行编码。
如何对Url中的非法字符进行编码
Url编码通常也被称为百分号编码(Url Encoding,also known as percent-encoding),是因为它的编码方式非常简单,使用%百分号加上两位的字符——0123456789ABCDEF——代表一个字节的十六进制形式。Url编码默认使用的字符集是US-ASCII。例如a在US-ASCII码中对应的字节是0x61,那么Url编码之后得到的就是%61,我们在地址栏上输入http://g.cn/search?q=%61%62%63,实际上就等同于在google上搜索abc了。又如@符号在ASCII字符集中对应的字节为0x40,经过Url编码之后得到的是%40。 对于非ASCII字符,需要使用ASCII字符集的超集进行编码得到相应的字节,然后对每个字节执行百分号编码。对于Unicode字符,RFC文档建议使用utf-8对其进行编码得到相应的字节,然后对每个字节执行百分号编码。如”中文”使用UTF-8字符集得到的字节为0xE4 0xB8 0xAD 0xE6 0x96 0x87,经过Url编码之后得到”%E4%B8%AD%E6%96%87”。 如果某个字节对应着ASCII字符集中的某个非保留字符,则此字节无需使用百分号表示。例如”Url编码”,使用UTF-8编码得到的字节是0x55 0x72 0x6C 0xE7 0xBC 0x96 0xE7 0xA0 0x81,由于前三个字节对应着ASCII中的非保留字符”Url”,因此这三个字节可以用非保留字符”Url”表示。最终的Url编码可以简化成”Url%E7%BC%96%E7%A0%81” ,当然,如果你用”%55%72%6C%E7%BC%96%E7%A0%81”也是可以的。
很多HTTP监视工具或者浏览器地址栏等在显示Url的时候会自动将Url进行一次解码(使用UTF-8字符集),这就是为什么当你在Firefox中访问Google搜索中文的时候,地址栏显示的Url包含中文的缘故。但实际上发送给服务端的原始Url还是经过编码的。

若有收获,就点个赞吧
0 人点赞
