1 对于Stream最终的收集操作有两个重载的版本:
<R, A> R collect(Collector<? super T, A, R> collector);<R> R collect(Supplier<R> supplier,BiConsumer<R, ? super T> accumulator,BiConsumer<R, R> combiner);
3 Collector【重要】 Collectors工具类:他的内部类CollectorImpl就是实现了Collector并重写了以下方法的
Collector接口提供了几个方法,这里的方法都是Stream.collect()方法中真实要用的,组合起来就是创建一个空结果容器,将元素添加到容器中,将结果世纪到容器之后,再转换成目标类型返回;(如果是并行的话,中间还有一步是合并中间结果)
/*** @param <T> Stream中的元素类型* @param <A> 收集过程中的临时中间类型* @param <R> 收集完成后输出结果的类型**/public interface Collector<T, A, R> {/*** 提供一个结果容器。*/Supplier<A> supplier();/*** 两个参数的消费型接口。将迭代中的当前元素添加到结果容器中。*/BiConsumer<A, T> accumulator();/*** 转换型接口,两个相同输入,同类型的输出。* 在并行处理中,将各个子Stream返回结果合并。*/BinaryOperator<A> combiner();/*** 收集操作的最后一步。* 转换型接口,用于将收集过程中的临时中间类型元素(A)转换为结果类型(R)。*/Function<A, R> finisher();/*** 返回一个集合。描述了被收集的流的一些特性。* 比如:是否是顺序相关的、支不支持并行等。* 详情见:3.4 Characteristics*/Set<Characteristics> characteristics();}
3.1 Stream.collect()源码
源码中是这样的:
public final <R, A> R collect(Collector<? super P_OUT, A, R> collector) {A container;if (// 并行流(stream().parallel()方法被调用)的情况isParallel()&&// 优化提示中包含 CONCURRENT 属性(collector.characteristics().contains(Collector.Characteristics.CONCURRENT))&&// 流是无序的(!isOrdered()||// 优化提示中包含 UNORDERED 属性collector.characteristics().contains(Collector.Characteristics.UNORDERED))) {container = collector.supplier().get();BiConsumer<A, ? super P_OUT> accumulator = collector.accumulator();forEach(u -> accumulator.accept(container, u));}else {container = evaluate(ReduceOps.makeRef(collector));}return// 优化提示中包含 IDENTITY_FINISH(恒等函数) 属性?collector.characteristics().contains(Collector.Characteristics.IDENTITY_FINISH)?// 直接将中间临时元素(A)当做最终结果(R)(R) container:// 使用 finisher 转换成最终结果collector.finisher().apply(container);}
3.2 串行流的执行过程

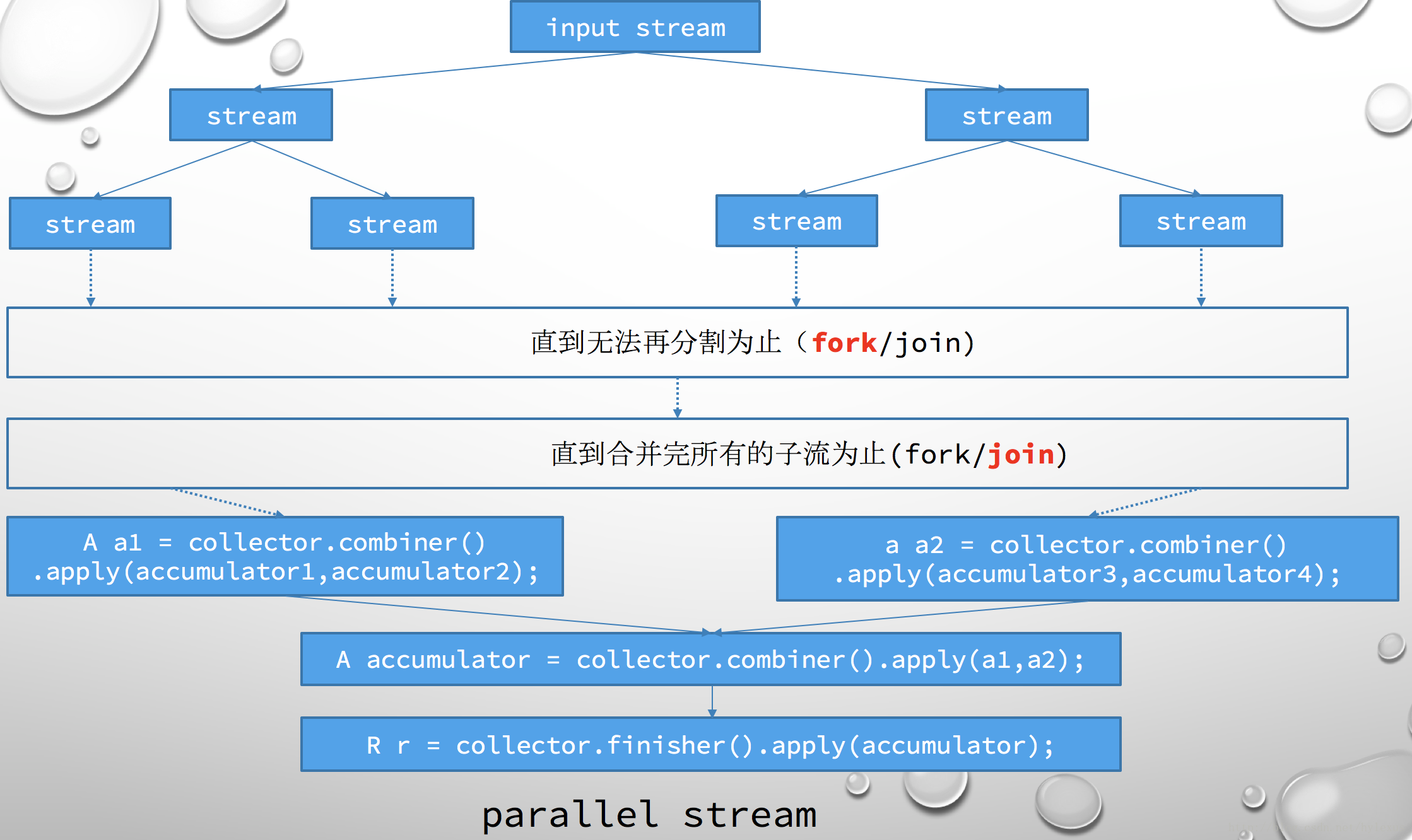
3.3 并行流的执行过程
3.4 Characteristics
enum Characteristics {/*** 支持多线程调用,并行收集。*/CONCURRENT,/*** 流中元素是无序的,收集过程不受元素先后顺序的影响。*/UNORDERED,/*** 恒等函数。* 此时不再使用finisher再转换一次元素。直接将中间元素(A)当做最终结果(R)。*/IDENTITY_FINISH}
这三个特性的常用组合在 Collectors 工具类中也有定义:
static final Set<Collector.Characteristics> CH_CONCURRENT_ID= Collections.unmodifiableSet(EnumSet.of(Collector.Characteristics.CONCURRENT,Collector.Characteristics.UNORDERED,Collector.Characteristics.IDENTITY_FINISH));static final Set<Collector.Characteristics> CH_CONCURRENT_NOID= Collections.unmodifiableSet(EnumSet.of(Collector.Characteristics.CONCURRENT,Collector.Characteristics.UNORDERED));static final Set<Collector.Characteristics> CH_ID= Collections.unmodifiableSet(EnumSet.of(Collector.Characteristics.IDENTITY_FINISH));static final Set<Collector.Characteristics> CH_UNORDERED_ID= Collections.unmodifiableSet(EnumSet.of(Collector.Characteristics.UNORDERED,Collector.Characteristics.IDENTITY_FINISH));static final Set<Collector.Characteristics> CH_NOID = Collections.emptySet();

若有收获,就点个赞吧
0 人点赞
