- 问题
- 根据UserID查订单
- 根据店铺ID查订单
- sharding jdbc
- 配置分库规则
- spring.shardingsphere.sharding.tables.product_order.database-strategy.inline.sharding-column=user_id
- spring.shardingsphere.sharding.tables.product_order.database-strategy.inline.algorithm-expression=ds$->{user_id % 2 }
- 精准分片-水平分表
- 指定product_order表的数据分布情况,配置数据节点,在 Spring 环境中建议使用 $->{…}
- TableRuleConfiguration
- spring.shardingsphere.sharding.tables.productorder.actual-data-nodes=ds0.product_order$->{0..1}
- 指定精准分片算法(水平分库) 根据user_id分库
- spring.shardingsphere.sharding.tables.product_order.database-strategy.standard.sharding-column=user_id
- spring.shardingsphere.sharding.tables.product_order.database-strategy.standard.precise-algorithm-class-name=net.xdclass.strategy.CustomDBPreciseShardingAlgorithm
- 指定精准分片算法(水平分表) 根据订单id分表
- spring.shardingsphere.sharding.tables.product_order.table-strategy.standard.sharding-column=id
- spring.shardingsphere.sharding.tables.product_order.table-strategy.standard.precise-algorithm-class-name=net.xdclass.strategy.CustomTablePreciseShardingAlgorithm
- 范围分片(水平分表)
- spring.shardingsphere.sharding.tables.product_order.table-strategy.standard.range-algorithm-class-name=net.xdclass.strategy.CustomRangeShardingAlgorithm
- spring.shardingsphere.sharding.tables.product_order.table-strategy.complex.sharding-columns=user_id,id
- spring.shardingsphere.sharding.tables.product_order.table-strategy.complex.algorithm-class-name=net.xdclass.strategy.CustomComplexKeysShardingAlgorithm
- hit分片
- 广播表
- 雪花算法id
- 配置绑定表(join)
- sharding-jdbc 主从读写分离
- 新老库切换
- join
- 事务
- 排序
根据UserID查订单
方法一:中间表
- 中间表可以使用es,根据UserID查OrderID
方法二:id融合
将uid作为tid的一部分,且作为分库的主键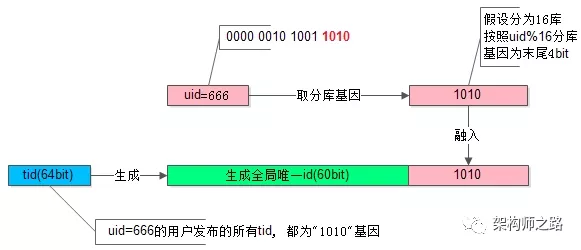
帖子中心,1亿数据,架构如何设计?
根据店铺ID查订单
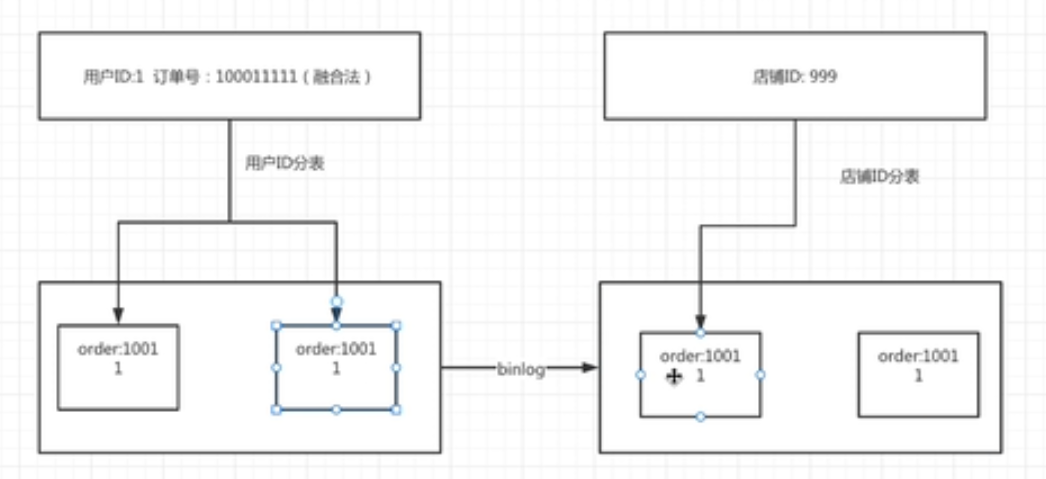
一个店铺的订单都是在不同的库中,即使使用中间表,查询效率也低。(用es存订单全量数据不行吗?)
- 数据冗余
- 使用canel或双写
sharding jdbc
配置数据源
# 打印执行的数据库以及语句spring.shardingsphere.props.sql.show=true# 数据源 db0spring.shardingsphere.datasource.names=ds0,ds1# 第一个数据库spring.shardingsphere.datasource.ds0.type=com.zaxxer.hikari.HikariDataSourcespring.shardingsphere.datasource.ds0.driver-class-name=com.mysql.cj.jdbc.Driverspring.shardingsphere.datasource.ds0.jdbc-url=jdbc:mysql://120.25.217.15:3306/xdclass_shop_order_0?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=truespring.shardingsphere.datasource.ds0.username=rootspring.shardingsphere.datasource.ds0.password=xdclass.net168# 第二个数据库spring.shardingsphere.datasource.ds1.type=com.zaxxer.hikari.HikariDataSourcespring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.cj.jdbc.Driverspring.shardingsphere.datasource.ds1.jdbc-url=jdbc:mysql://120.25.217.15:3306/xdclass_shop_order_1?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=truespring.shardingsphere.datasource.ds1.username=rootspring.shardingsphere.datasource.ds1.password=xdclass.net168
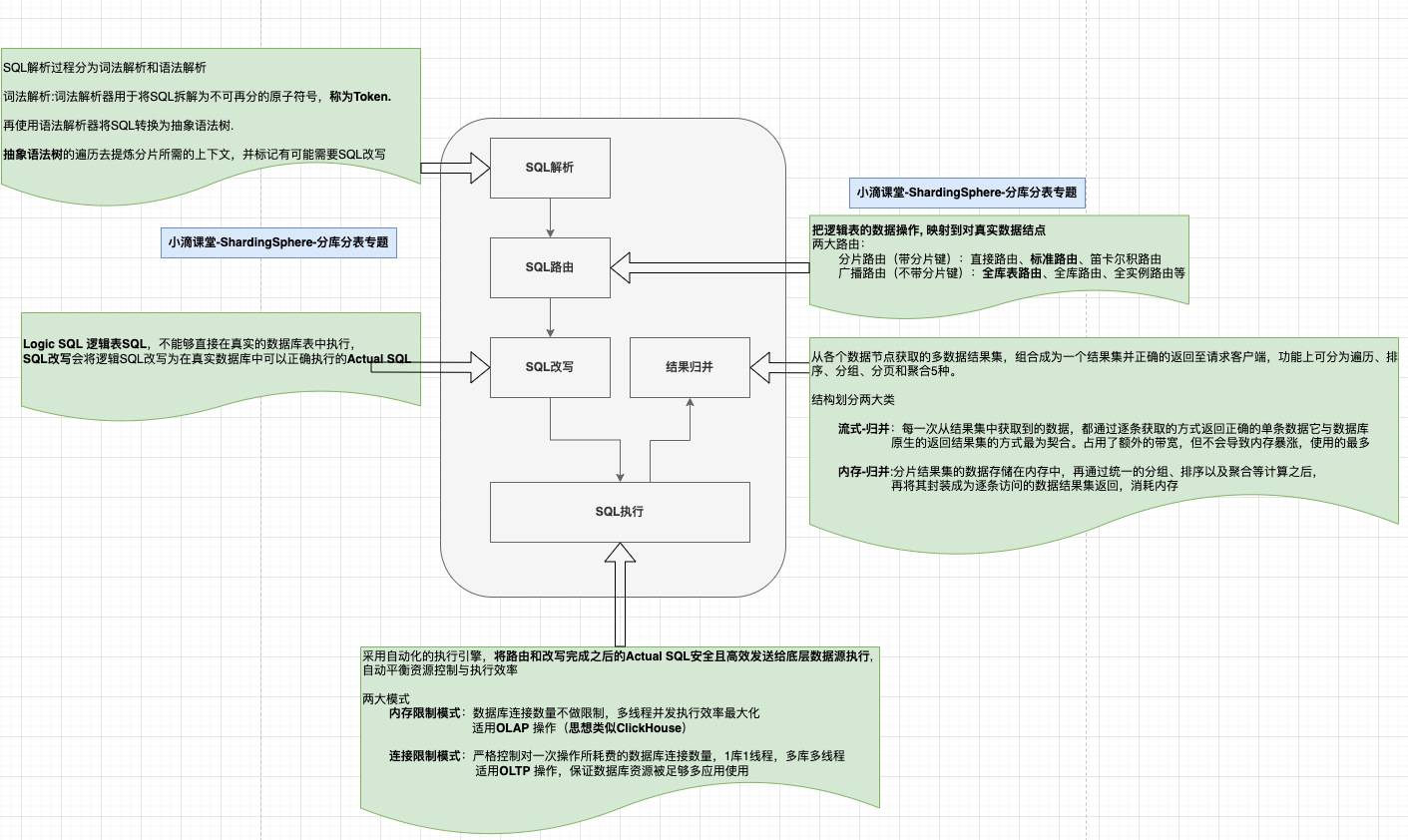
分库分表
- 虚拟表productorder,分到ds$->{0..1}.product_order$->{0..1},
- 这个0,1怎么根据什么算出来呢?下面配置 分片键 & 分片算法
```properties
配置分库规则
spring.shardingsphere.sharding.tables.product_order.database-strategy.inline.sharding-column=user_id
spring.shardingsphere.sharding.tables.product_order.database-strategy.inline.algorithm-expression=ds$->{user_id % 2 }
精准分片-水平分表
指定product_order表的数据分布情况,配置数据节点,在 Spring 环境中建议使用 $->{…}
TableRuleConfiguration
spring.shardingsphere.sharding.tables.productorder.actual-data-nodes=ds$->{0..1}.product_order$->{0..1}
spring.shardingsphere.sharding.tables.productorder.actual-data-nodes=ds0.product_order$->{0..1}
指定精准分片算法(水平分库) 根据user_id分库
spring.shardingsphere.sharding.tables.product_order.database-strategy.standard.sharding-column=user_id
spring.shardingsphere.sharding.tables.product_order.database-strategy.standard.precise-algorithm-class-name=net.xdclass.strategy.CustomDBPreciseShardingAlgorithm
指定精准分片算法(水平分表) 根据订单id分表
spring.shardingsphere.sharding.tables.product_order.table-strategy.standard.sharding-column=id
spring.shardingsphere.sharding.tables.product_order.table-strategy.standard.precise-algorithm-class-name=net.xdclass.strategy.CustomTablePreciseShardingAlgorithm
范围分片(水平分表)
spring.shardingsphere.sharding.tables.product_order.table-strategy.standard.range-algorithm-class-name=net.xdclass.strategy.CustomRangeShardingAlgorithm
复合分片算法,order_id,user_id 同时作为分片健
spring.shardingsphere.sharding.tables.product_order.table-strategy.complex.sharding-columns=user_id,id
spring.shardingsphere.sharding.tables.product_order.table-strategy.complex.algorithm-class-name=net.xdclass.strategy.CustomComplexKeysShardingAlgorithm
hit分片
spring.shardingsphere.sharding.tables.product_order.database-strategy.hint.algorithm-class-name=net.xdclass.strategy.CustomDBHintShardingAlgorithm spring.shardingsphere.sharding.tables.product_order.table-strategy.hint.algorithm-class-name=net.xdclass.strategy.CustomTableHintShardingAlgorithm
<a name="zXxMm"></a>### 配置默认分库策略```properties#配置【默认分库策略】#spring.shardingsphere.sharding.default-database-strategy.inline.sharding-column=user_id#spring.shardingsphere.sharding.default-database-strategy.inline.algorithm-expression=ds$->{user_id % 2 }
ShardingAlgorithm
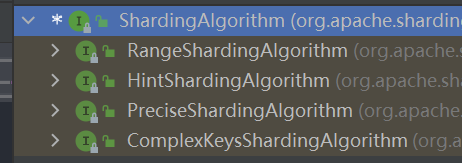
ShardingAlgorithm和ShardingStrategy关系

PreciseShardingAlgorithm
包括RangeShardingAlgorithm,都是单分片键
public class CustomTablePreciseShardingAlgorithm implements PreciseShardingAlgorithm<Long> {/**** @param dataSourceNames 数据源集合* 在分库时值为所有分片库的集合 databaseNames* 分表时为对应分片库中所有分片表的集合 tablesNames** @param shardingValue 分片属性,包括* logicTableName 为逻辑表,* columnName 分片健(字段),* value 为从 SQL 中解析出的分片健的值* @return*/@Overridepublic String doSharding(Collection<String> dataSourceNames, PreciseShardingValue<Long> preciseShardingValue) {for(String datasourceName : dataSourceNames){String value = preciseShardingValue.getValue() % dataSourceNames.size() + "";//product_order_0if(datasourceName.endsWith(value)){return datasourceName;}}return null;}}
ComplexKeysShardingAlgorithm 支持多分片键
订单id=xx and userid = yy
product_order_0_0、product_order_0_1、product_order_1_0、product_order_1_1
用的少 ```java public class CustomComplexKeysShardingAlgorithm implements ComplexKeysShardingAlgorithm{ /* - @param dataSourceNames 数据源集合
- 在分库时值为所有分片库的集合 databaseNames
- 分表时为对应分片库中所有分片表的集合 tablesNames *
- @param shardingValue 分片属性,包括
- logicTableName 为逻辑表,
- columnName 分片健(字段),
- value 为从 SQL 中解析出的分片健的值
@return */ @Override public Collection
doSharding(Collection dataSourceNames, ComplexKeysShardingValue complexKeysShardingValue) { // 得到每个分片健对应的值 Collection
orderIdValues = this.getShardingValue(complexKeysShardingValue, “id”); Collection userIdValues = this.getShardingValue(complexKeysShardingValue, “user_id”); List
shardingSuffix = new ArrayList<>(); // 对两个分片健取模的方式 product_order_0_0、product_order_0_1、product_order_1_0、product_order_1_1 for (Long userId : userIdValues) { for (Long orderId : orderIdValues) {String suffix = userId % 2 + "_" + orderId % 2;for (String databaseName : dataSourceNames) {if (databaseName.endsWith(suffix)) {shardingSuffix.add(databaseName);}}}
} return shardingSuffix; }
/**
- shardingValue 分片属性,包括
- logicTableName 为逻辑表,
- columnNameAndShardingValuesMap 存储多个分片健 包括key-value
- key:分片key,id和user_id
- value:分片value,66和99 *
@return shardingValues 集合 */ private Collection
getShardingValue(ComplexKeysShardingValue shardingValues, final String key) { Collection valueSet = new ArrayList<>(); Map if (columnNameAndShardingValuesMap.containsKey(key)) {
valueSet.addAll(columnNameAndShardingValuesMap.get(key));
} return valueSet; }
}
<a name="lidG7"></a>#### HintShardingAlgorithm- 外部指定分片键值->从 **hintManager.addTableShardingValue**("product_order", 1)参数进行指定```javapublic void testHit(){//清除历史规则HintManager.clear();//获取对应的实例HintManager hintManager = HintManager.getInstance();//设置库的分片键值,value是用于库分片取模hintManager.addDatabaseShardingValue("product_order",3L);//设置表的分片键值,value是用于表分片取模hintManager.addTableShardingValue("product_order",8L);//如果在读写分离数据库中,Hint 可以强制读主库(主从复制存在一定延时,但在业务场景中,可能更需要保证数据的实时性)//hintManager.setMasterRouteOnly();//对应的value,只做查询,不做sql解析productOrderMapper.selectList(new QueryWrapper<ProductOrderDO>().eq("id",66L));}
广播表
每个库都有的表
#配置广播表spring.shardingsphere.sharding.broadcast-tables=ad_configspring.shardingsphere.sharding.tables.ad_config.key-generator.column=idspring.shardingsphere.sharding.tables.ad_config.key-generator.type=SNOWFLAKE
雪花算法id
- 注意workerId不同(确保机器间id不同)
- 注意时钟回拨(确保单个机器id不同)
设置workerId
#配置workIdspring.shardingsphere.sharding.tables.product_order.key-generator.props.worker.id=1
#id生成策略spring.shardingsphere.sharding.tables.product_order.key-generator.column=idspring.shardingsphere.sharding.tables.product_order.key-generator.type=SNOWFLAKE
配置绑定表(join)
避免笛卡尔积
#配置绑定表#spring.shardingsphere.sharding.binding‐tables[0] = product_order,product_order_item

sharding-jdbc 主从读写分离
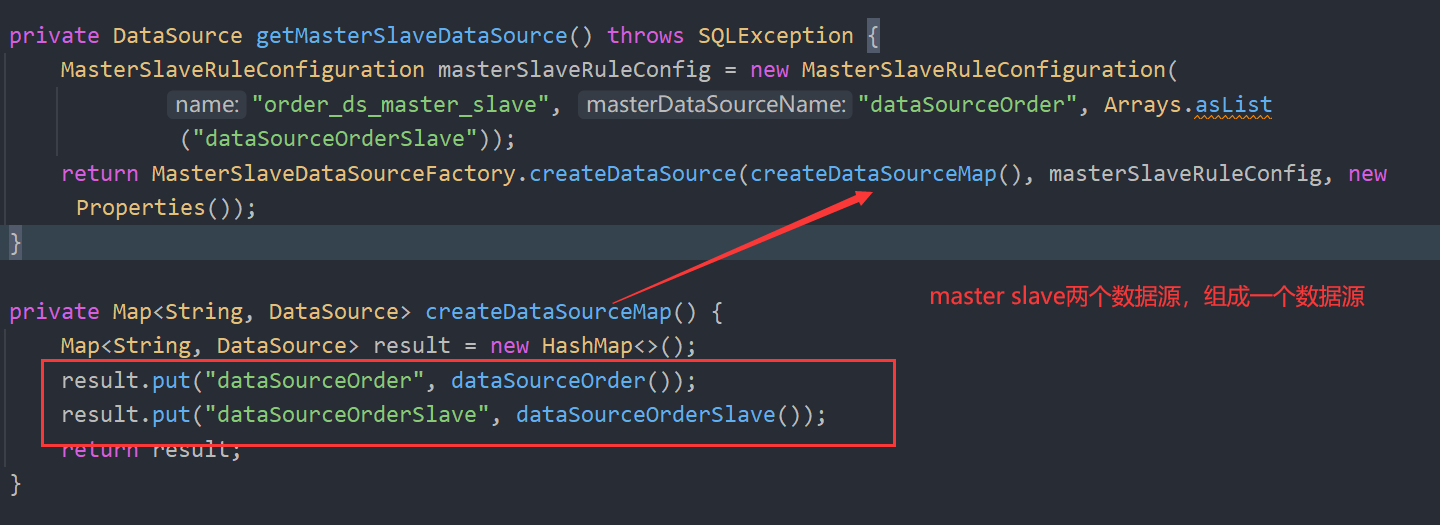
注解强制走主库
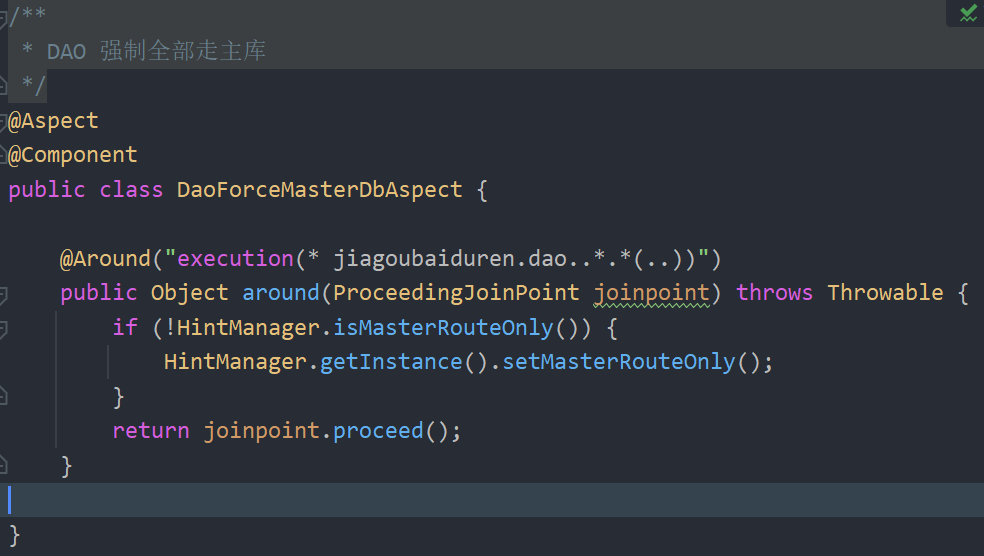
注解走从库
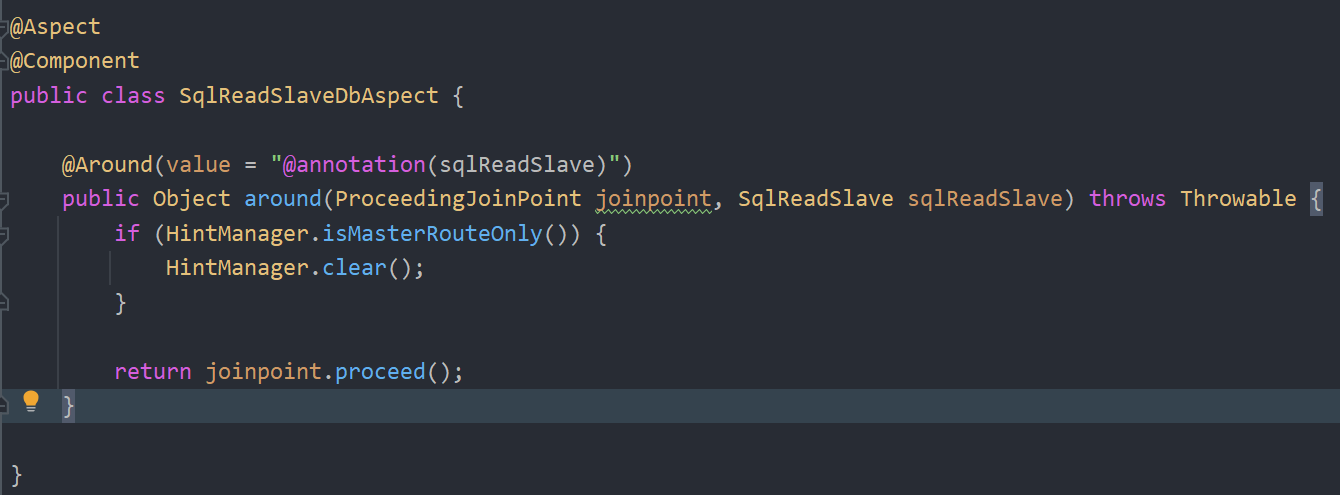
新老库切换
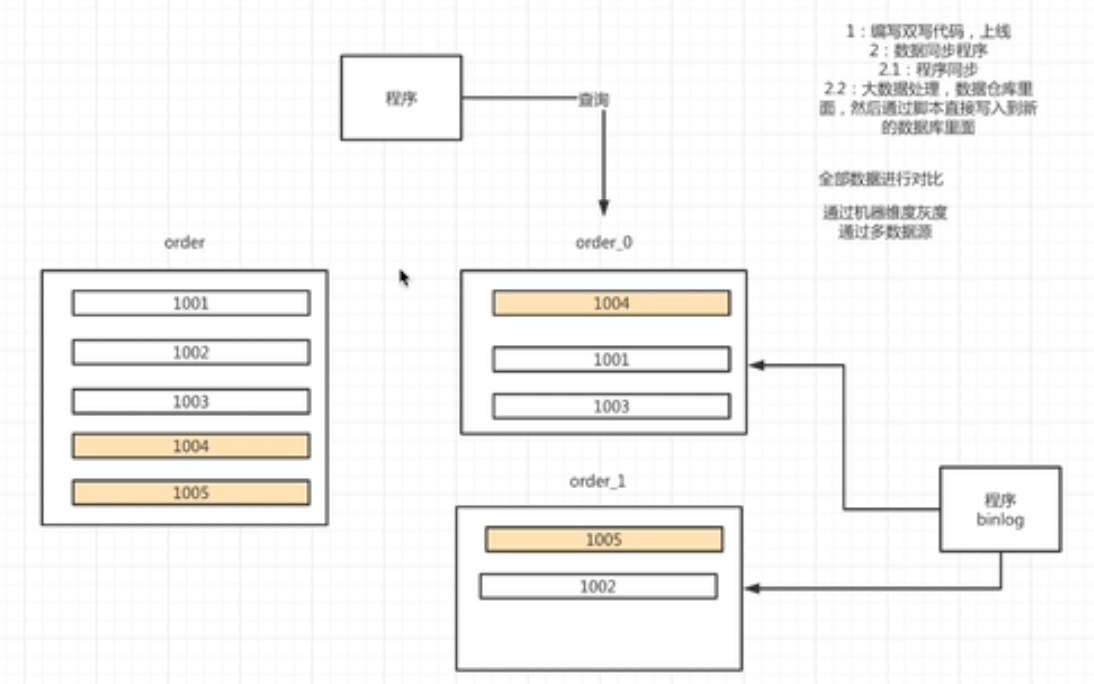
- 新数据双写
- 老数据同步
- 全量数据比对

若有收获,就点个赞吧
0 人点赞
