gc吞吐量
吞吐量=用户线程执行时间/(用户线程执行时间+GC时间)
吞吐量和最短暂停时间
吞吐量高,就要少gc,gc少,每次gc的垃圾就多,时间长。
哪些对象是GC root
1.System Class----------Class loaded by bootstrap/system class loader. For example, everything from the rt.jar like java.util.* .2.JNI Local----------Local variable in native code, such as user defined JNI code or JVM internal code.3.JNI Global----------Global variable in native code, such as user defined JNI code or JVM internal code.4.Thread Block----------Object referred to from a currently active thread block.Thread----------A started, but not stopped, thread.5.Busy Monitor----------Everything that has called wait() or notify() or that is synchronized. For example, by calling synchronized(Object) or by entering a synchronized method. Static method means class, non-static method means object.6.Java Local----------Local variable. For example, input parameters or locally created objects of methods that are still in the stack of a thread.7.Native Stack----------In or out parameters in native code, such as user defined JNI code or JVM internal code. This is often the case as many methods have native parts and the objects handled as method parameters become GC roots. For example, parameters used for file/network I/O methods or reflection.7.Finalizable----------An object which is in a queue awaiting its finalizer to be run.8.Unfinalized----------An object which has a finalize method, but has not been finalized and is not yet on the finalizer queue.9.Unreachable----------An object which is unreachable from any other root, but has been marked as a root by MAT to retain objects which otherwise would not be included in the analysis.10.Java Stack Frame----------A Java stack frame, holding local variables. Only generated when the dump is parsed with the preference set to treat Java stack frames as objects.11.Unknown----------An object of unknown root type. Some dumps, such as IBM Portable Heap Dump files, do not have root information. For these dumps the MAT parser marks objects which are have no inbound references or are unreachable from any other root as roots of this type. This ensures that MAT retains all the objects in the dump.
Java中什么样的对象才能作为gc root,gc roots有哪些呢? - 知乎
- 虚拟机栈
- 类静态属性【1.7静态变量被转入堆中(原来在方法区,现在class对象中)】
- 常量引用(字符串常量池)【1.7被转入堆中】
- 本地方法栈JNI引用
- 被同步所持有(synchronized)
。。什么时候进入老年代?
- 根据对象年龄
- -XX:MaxTenuringThreshold:最多经过15次
- 根据动态年龄判断
- 一批对象的总大小大于这块Survivor内存的50%,那么大于这批对象年龄的对象,就可以直接进入老年代了。(1、2、3岁的已经超过50%,3岁以上直接进入老年代)
- -XX:TargetSurvivorRatio=n:用于设置Survivor区的目标使用率
- 大对象直接进入老年代
- 避免大对象来回复制
- -XX:PretenureSizeThreshold:大于这个值的参数直接在老年代分配
- -XX:+HandlePromotionFailure分配担保:避免多做young gc,按平时经验(平均大小),堆放不下就直接full gc。
- 不想冒险的话就直接full gc。
- 想冒风险(只做young gc不做full gc),看经验(平均大小),值不值得冒风险。
- 冒风险后(young gc),如果young gc之后不能放入survive区的话,【部分】直接进入老年代。【部分进入survive】、
- 冒风险后,老年代也放不下。那就full gc。(就是为了避免这种情况)
JVM 模拟对象进入老年代的四种情况_葫芦脸小眼睛的博客-CSDN博客
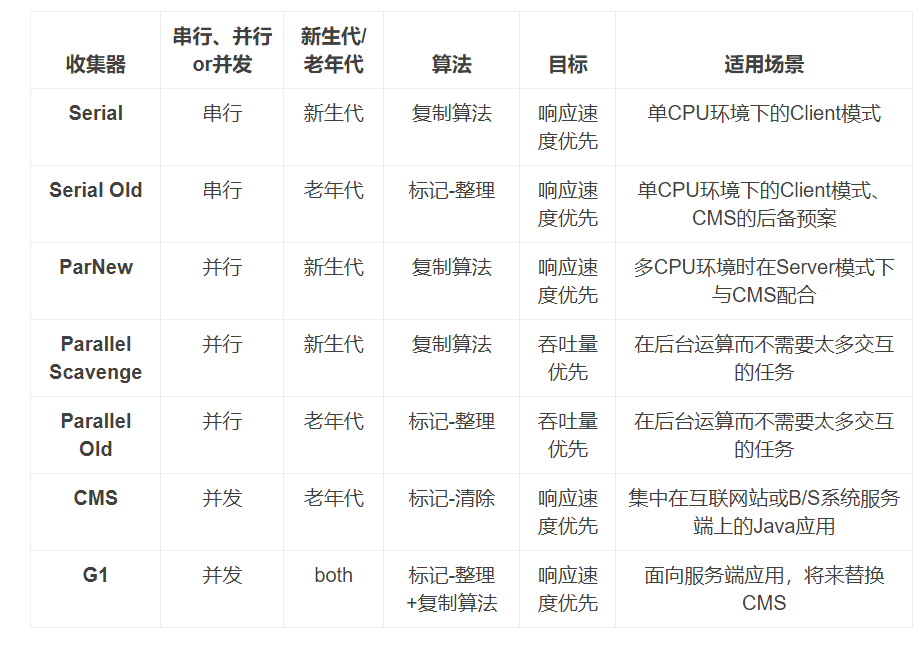
垃圾收集器
【年轻代】ParNewGC(deprecated)
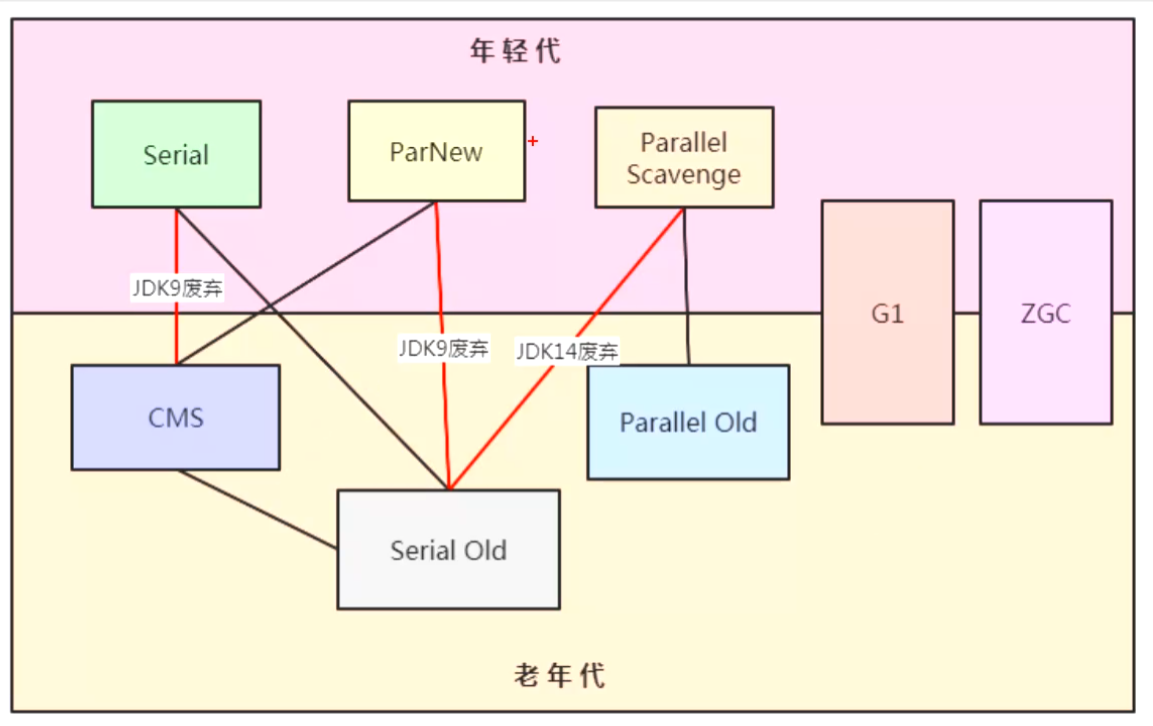
ParNewGC在JDK9中弃用了,JDK10中已经完全移除了
【年轻代】Paralel Scavenge【吞吐量优先】【java8默认】
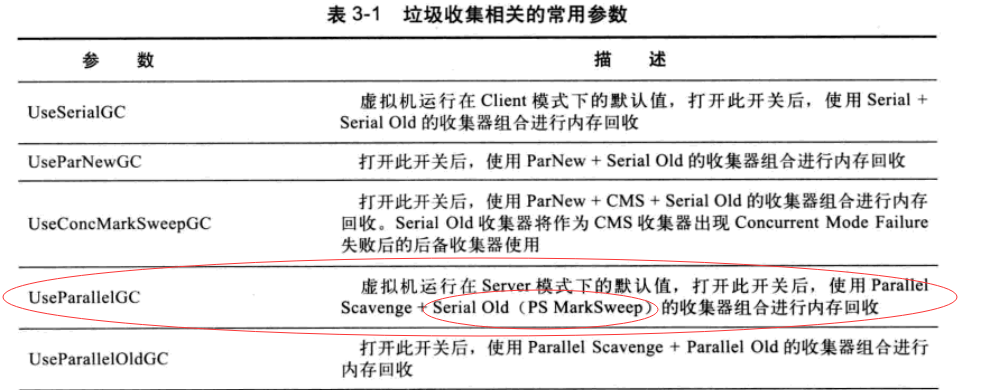
- +UseParallelGC = 新生代ParallelScavenge + 老年代SerialOld
- +UseParallelOldGC = 新生代ParallelScavenge + 老年代ParallelOld(ps+po)【java8默认】
其实自从JDK7u4开始,就对 “-XX:+UseParallelGC” 默认的老年代收集器进行了改进,改进使得HotSpot VM在选择使用 “-XX:+UseParallelGC” 时,会默认开启 “ -XX:+UseParallelOldGC “,也就是说默认的老年代收集器是 Parallel Old。综上,JDK8中默认的选择是”-XX:+UseParallelGC”,是 Parallel Scavenge + Parallel Old组合。 JDK8默认垃圾回收器详解_wholve的博客-CSDN博客
Parallel Scavenge收集器提供了两个参数用于精确控制吞吐量,分别是控制最大垃圾收集停顿时间的-XX:MaxGCPauseMillis参数以及直接设置吞吐量大小的-XX:GCTimeRatio参数。
- -XX:MaxGCPauseMills:收集器在工作时,会调整Java堆大小或者其他参数,尽可能把停顿时间控制在MaxGCPauseMillis以内。(谨慎使用)
-XX:GCTimeRatio:系统将花费不超过1/(1+n)的时间用于垃圾收集。
paralel scavenge相对于ParNew来说的优点
可以设置最大gc停顿时间(-XX:MaxGCPauseMills)以及gc时间占比(-XX:GCTimeRatio)
-XX:UseAdaptiveSizePolicy:JDK 1.8 默认使用 UseParallelGC 垃圾回收器,该垃圾回收器默认启动了 AdaptiveSizePolicy,会根据GC的情况自动计算 Eden、From 和 To 区的大小。
Parallel Scavenge收集器为何无法与CMS同时使用?
重点就是Parallel Scavenge没有使用原本HotSpot其它GC通用的那个GC框架,所以不能跟使用了那个框架的CMS搭配使用。 Parallel Scavenge收集器为何无法与CMS同时使用? - 知乎
【老年代】CMS【响应时间优先】【jdk14移除】
Concurrent Mark-Sweep并发标记清除
优点:stw时间短【响应时间优先】(控制暂停时间)
缺点:会产生空间碎片。大对象分配会因无法找到连续内存空间而触发FGC
5个阶段,两次stop-the-world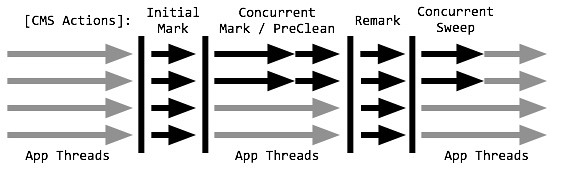
- CMS垃圾收集器 - 掘金
初始标记
初始标记为什么要stw?Problem is majority of roots are local variables. GC have to scan stacks for application threads. It can be done only with STW。
在CMS垃圾收集器中,为何要有初始化标记这一步?直接进入并发标记不可以吗? - 知乎
java - Why CMS is stop the world for Initial mark but not for sweeping phase? - Stack Overflow
并发标记
三色标记:
- 白色:未被垃圾收集器访问
- 黑色:已被垃圾收集器访问
- 灰色:已被访问,但对象上有新的引用没有被扫描

解决并发扫描时的对象消失问题
- 增量更新(Incremental Update write barrier)【cms】
- 黑色对象一旦插入了指向白色对象的引用之后,它就变回了灰色对象。【记录新增】
- 原始快照(SATB(Snapshot-At-The-Beginning))【G1】
- 无论引用关系删除与否,都会按照刚刚开始扫描那一刻的对象图快照开进行搜索。(按快照算)【如何保留快照呢?记录删除】

JVM-G1算法和数据结构那些事 - SegmentFault 思否
R大对SATB的解释:
其实只需要用pre-write barrier把每次引用关系变化时旧的引用值记下来就好了。这样,等concurrent marker到达某个对象时,这个对象的所有引用类型字段的变化全都有记录在案,就不会漏掉任何在snapshot里活的对象。当然,很可能有对象在snapshot中是活的,但随着并发GC的进行它可能本来已经死了,但SATB还是会让它活过这次GC。CMS的incremental update设计使得它在remark阶段必须重新扫描所有线程栈和整个young gen作为root(标记线程识别对象在并发阶段已经标记过了,就会跳过该对象);G1的SATB设计在remark阶段则只需要扫描剩下的satb_mark_queue ,解决了CMS垃圾收集器重新标记阶段长时间STW的潜在风险。”
remark
在并发标记阶段可能产生两种变动:
- 本来可达的对象,变得不可达了
- 浮动垃圾,本轮GC不会回收这部分内存。
- remark阶段不处理,需要重新扫描一遍,开销太大?增量
- 本来不可达的内存,变得可达了【只关注增量】
- 必须处理
- 通过增量更新,黑色对象一旦插入了指向白色对象的引用之后,它就变回了灰色对象。
CMS垃圾收集器——重新标记和浮动垃圾的思考 - caoPhoenix - 博客园
两次stop the word
其中,初始标记、重新标记这两个步骤仍然需要Stop-the-world。
- 初始标记仅仅只是标记一下GC Roots能直接关联到的对象,速度很快,
- 并发标记阶段就是进行GC Roots Tracing的过程,
- 而重新标记阶段则是为了修正并发标记期间因用户程序继续运作而导致标记产生变动的那一部分对象的标记记录,这个阶段的停顿时间一般会比初始阶段稍长一些,但远比并发标记的时间短。
图解 CMS 垃圾回收机制原理,-阿里面试题 - aspirant - 博客园
图解CMS垃圾回收机制,你值得拥有
cms配置参数
- -XX:+UseConcMarkSweepGC:开关
- -XX:ParallelGCThreads=n 并行垃圾回收线程数
- 默认情况下,当CPU数量小于8时,ParallelGCThreads的值就是CPU的数量,当CPU数量大于8时,ParallelGCThreads的值等于3+5*cpuCount/8。
- -XX:ConcGCThreads=threads 并发的线程数,CMS默认启动的并发线程数是(ParallelGCThreads+3)/4。
- -XX:CMSInitiatingOccupancyFraction=92:占用xx开始回收和-XX:+UseCMSInitiatingOccupancyOnly配套使用,如果不设置后者,jvm第一次会采用92%但是后续jvm会根据运行时采集的数据来进行GC周期,如果设置后者则jvm每次都会在92%的时候进行gc;
-XX:+CMSScavengeBeforeRemark:在重新标记之前执行minorGC减少重新标记时间;
ParallelGCThreads & ConcGCThreads区别
ParallelGCThreads:stw时
- ConcGCThreads:并发执行时
java - What is the difference between G1GC options -XX:ParallelGCThreads vs -XX:ConcGCThreads - Stack Overflow
cms碎片整理参数【配合full gc,一般是要做old gc】
- -XX:+UseCMSCompactAtFullCollection:full gc之后再次stw,进行碎片整理
- -XX:CMSFullGCsBeforeCompaction:多少次full gc之后再进行碎片整理。默认0,每次gc都碎片整理。
-XX:+UseCMSCompactAtFullCollection -XX:CMSFullGCsBeforeCompaction=5
5次full gc 之后 碎片整理
什么情况下cms要进行full gc?
1. 没有配置阈值情况,jvm看情况full gc
如果没有设置-XX:+UseCMSInitiatingOccupancyOnly,虚拟机会根据收集的数据决定是否触发full gc(建议线上环境带上这个参数,不然会加大问题排查的难度)。
UseCMSInitiatingOccupancyOnly 设置老年代中占用多少后,进行full gc。始终基于设定的阈值,不根据运行情况进行调整。
2. 达到老年代阈值(配合UseCMSInitiatingOccupancyOnly)
老年代使用率达到阈值 CMSInitiatingOccupancyFraction,默认92%。【survive达到比例晋升老年代,老年代达到比例full gc】
JDK1.5时,CMSInitiatingOccupancyFraction的默认值是68;JDK1.6时,默认值调高为92。
concurrent mode failure【cms gc过程中老年代放不下了,用serial old 代替cms】
老年代占用了92%空间了,就自动进行CMS垃圾回收,预留8%的空间给并发回收期间,系统程序把一些新对象放入老年代中。那么如果CMS垃圾回收期间,系统程序要放入老年代的对象大于了可用内存空间,怎么办?
这就是concurrent mode failure
用serial old 代替cms。【为什么用serial old 用并行算法不行吗】
为什么cms退化用serial old 用并行算法不行吗
因为没足够开发资源,偷懒了
CMS GC发生concurrent mode failure时,为什么使用单线程的full GC? - 知乎
3. 达到永久代阈值
永久代的使用率达到阈值 CMSInitiatingPermOccupancyFraction,默认92%,前提是开启 CMSClassUnloadingEnabled。
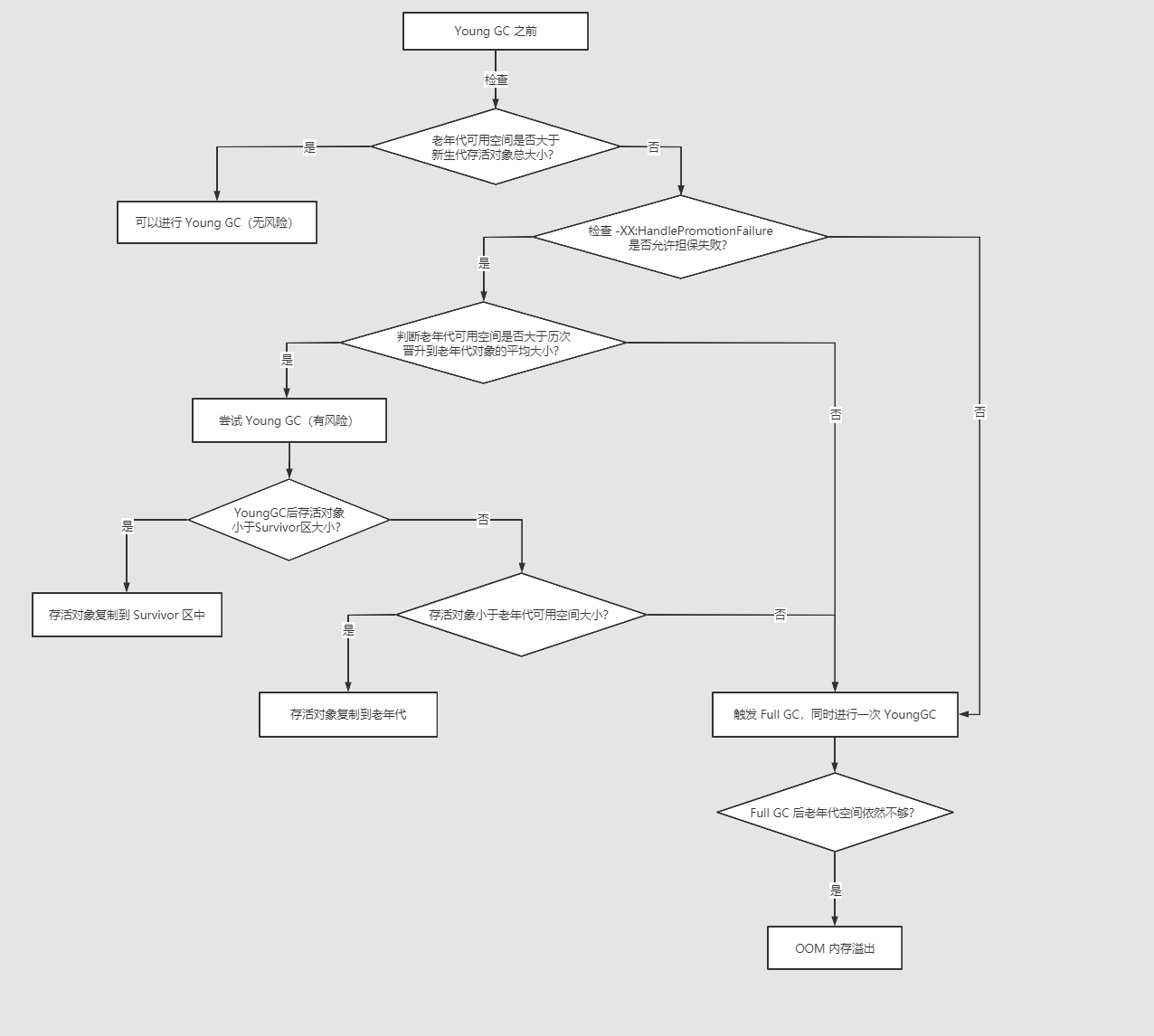
4. -XX:+HandlePromotionFailure晋升担保失败
-XX:+HandlePromotionFailure 【分配担保规则】【判断是否进行full gc】
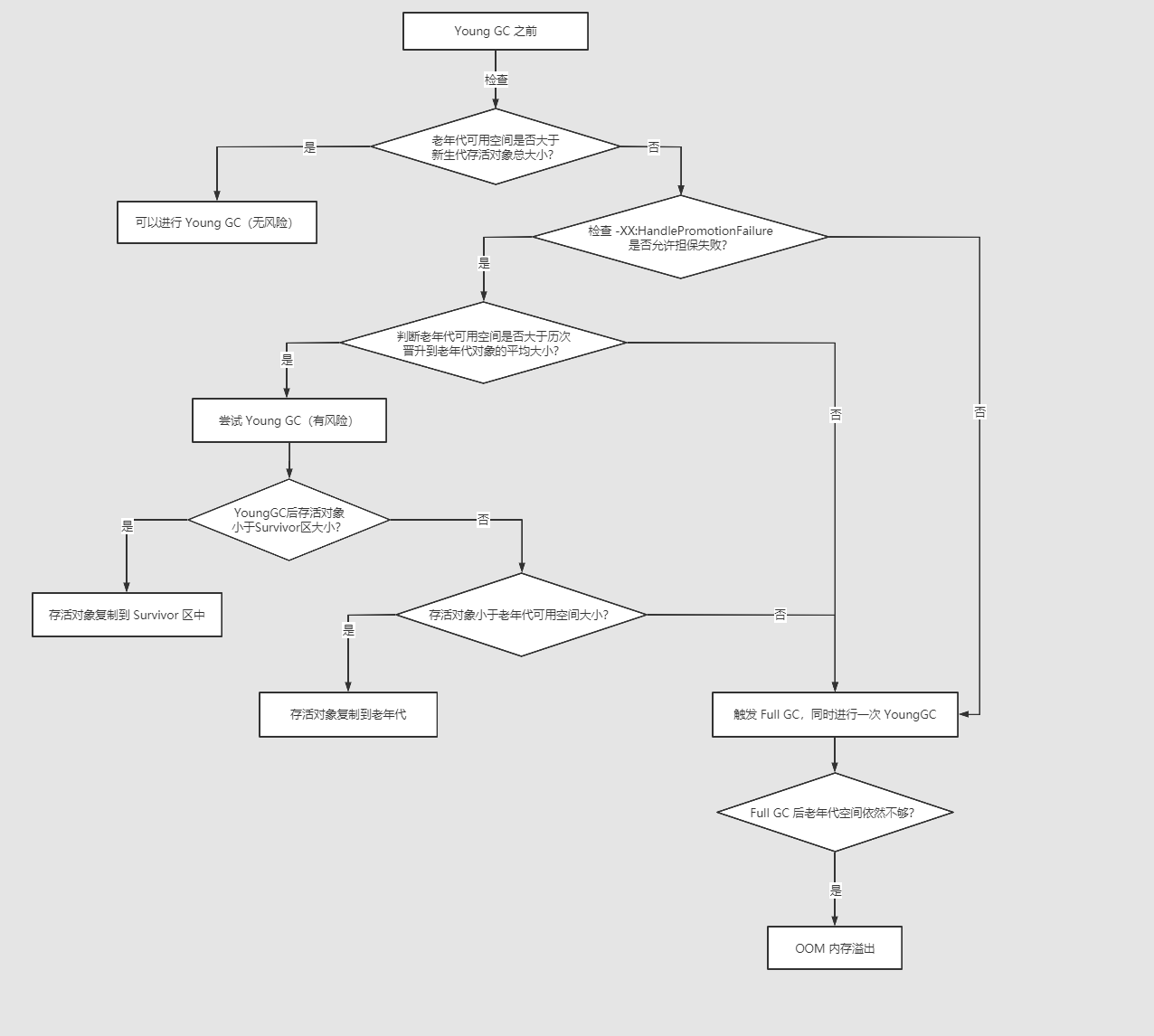
先判断新生代存活总大小,再判断平均晋升大小。
HandlePromotionFailure 就是是否去判断历次晋升大小和老年代剩余空间大小
分配担保规则在JDK7之后有些变化,不再判断 -XX:HandlePromotionFailure 参数。YoungGC发生时,只要老年代的连续空间大于新生代对象总大小,或者大于历次晋升的平均大小,就可以进行 YoungGC,否则就进行 FullGC。
5. 【大对象堆放不下】
G1
JVM中的垃圾回收策略
cms主要的问题就是碎片。
Jdk9 默认G1
G1也会有
- concurrent mode failure
- PromotionFailure
G1可以设置最大停顿时间(parallel scavenge也可以)。
G1主要就是在短时间内回收最应该回收的区域。(单位时间效用最大化)
G1内存结构
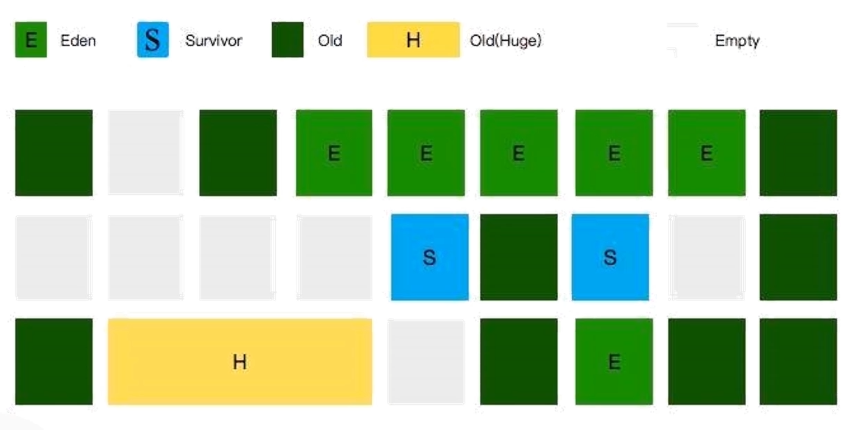
G1处理大对象
G1认为只要大小超过了一个Region容量一半的对象即可判定为大对象。
- -XX:G1HeapRegionSize:设置Region大小
Humongous区域, 专门用来存储大对象。超过了整个Region容量的超级大对象,将会被存放在N个连续的Humongous Region之中。
Region & Card
region内部又分为card(最小单位)。
所有card都记录在global card table中(记录干啥?)。
RSet & Card Table
- 【好文】卡表和 RSet [ 守株阁 ]
《深入理解Java虚拟机》这说的卡表就是rset的实现??

所谓的双向卡表结构?: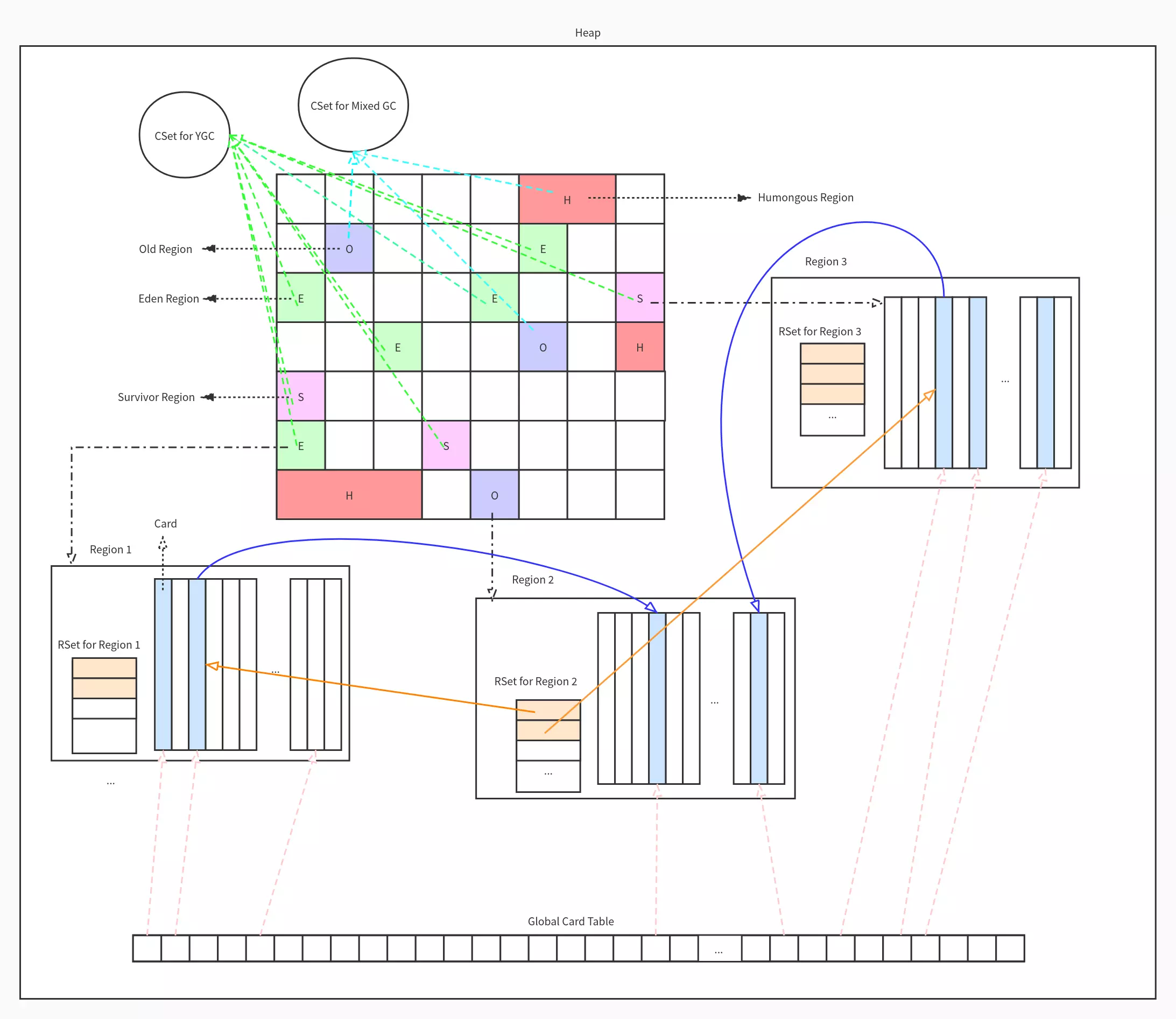
此图有误导性。这意思是G1是双向卡表结构,包含原来cms的卡表 + rset?【感觉写错了】
G1维护卡表占用空间,每个region都要有卡表-
cms的卡表【记录老年代引用年轻代】【young gc时使用】
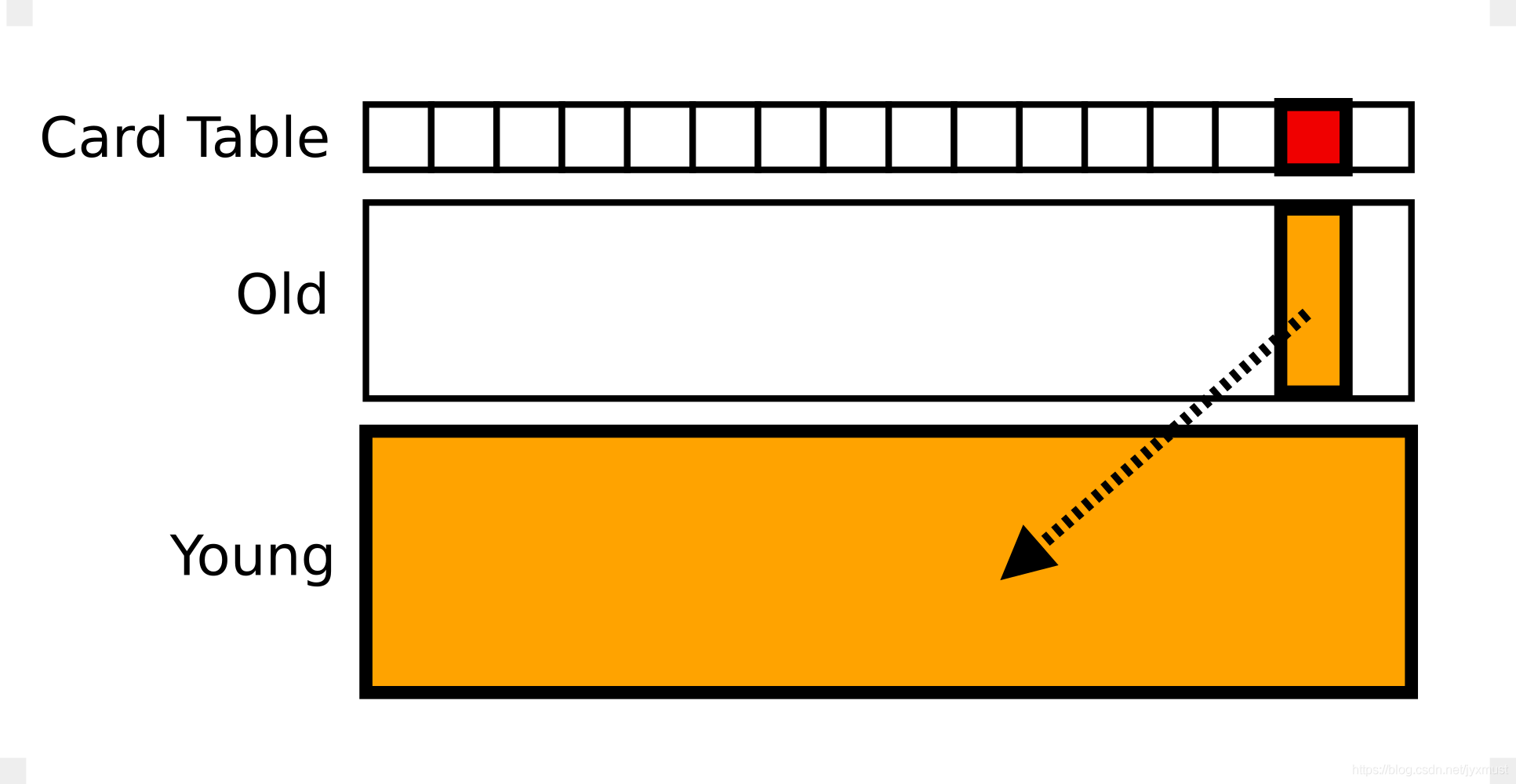
新生代垃圾收集器在收集live set 的时候:从栈/方法区出发,进入老年代扫描,且只扫描 dirty 的区域,略过其他区域。
G1的rset【G1没有卡表?】
cms卡表只解决 ygc 少扫老年代的问题,而 RSet 则解决了g1所有 Region 的扫描问题。

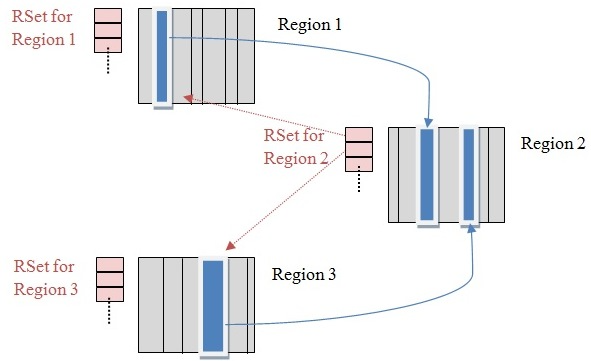
RSet其实是一个Hash Table,Key是别的Region的起始地址,Value是一个集合,里面的元素是Card Table的Index。【g1还有卡表?】
Java Hotspot G1 GC的一些关键技术 - 美团技术团队
一个region1不知道谁引用了他,那就只能扫描所有region,才能判断这个region1是不是垃圾。扫描所有太慢,相当于每次都是full gc?所以单独建立一个rset来记录谁引用了我。
如何维护RSet呢?Write Barrier
G1清理流程【young gc,mixed gc】

G1 young GC:只收集young gen里的所有region
- G1 mixed GC:收集young gen里的所有region,外加若干选定的old gen region。【之所以不叫full gc,就是因为g1不是要回收所有垃圾】
- -XX:InitiatingHeapOccupancyPercent //45%,这里是整体堆中存活对象(不是老年代)占据堆内存45% 的Region的时候,尝试mixed GC混合回收。大概是接近1000个region。【jdk9之后会动态调整此值】

- G1的正常处理流程中没有Full GC,只有在垃圾回收处理不过来(或者主动触发)时才会出现, G1的Full GC就是单线程执行的Serial old gc。【听说g1 full gc变成多线程了?】
Young GC年轻代回收流程

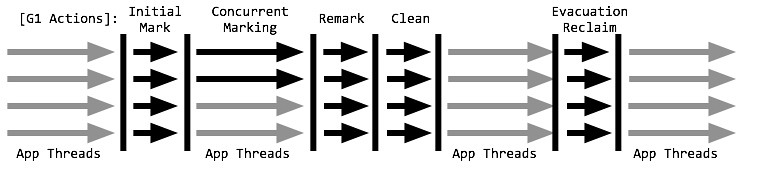
- 初始标记:借用Minor GC的时候同步完成的。
- global concurrent marking
- remark
- 独占清理(cleanup,STW):
- 计算各个区域的存活对象和GC回收比例,并进行排序,识别可以混合回收的区域。为下阶段做铺垫。是STW的。(这个阶段并不会实际上去做垃圾的收集)
- 该阶段会计算每一个region里面存活的对象,并把完全没有存活对象的Region直接放到空闲列表中。在该阶段还会重置Remember Set。该阶段在计算Region中存活对象的时候,是STW(Stop-the-world)的,而在重置Remember Set的时候,却是可以并行的;
- Evacuation
Evacuation阶段是全暂停的。它负责把一部分 Region 里的活对象拷贝到空 Region 里去,然后回收原本的 Region 的空间。
- 【好文】JVM G1(Garbage-First Garbage Collector)收集器全过程剖析_编程不离宗-CSDN博客
- 可能是最全面的G1学习笔记 - 知乎
- 【好文】[JVM(四) G1 收集器工作原理介绍 - float123 - 博客园
](https://www.cnblogs.com/Benjious/p/10304799.html)
初始标记(initial mark,STW)【借用young gc的暂停】
- 它标记了从GC Root开始直接可达的对象。
并发标记阶段【SATB】
- 增量更新(Incremental Update write barrier)【cms没有额外的空间记录哪些变化,直接在三色标记上修改成灰色】
- 黑色对象一旦插入了指向白色对象的引用之后,它就变回了灰色对象。【之后remark再重新扫描一遍】
- 原始快照(SATB(Snapshot-At-The-Beginning))【G1新加对象都存活,修改对象记录到另外的空间A中,remark只扫描空间A,不用像cms一样全扫描了】
- 无论引用关系删除与否,都会按照刚刚开始扫描那一刻的对象图快照开进行搜索。(按快照算)

SATB,snapshot-at-the-beginning。
- 【理想情况】就是开始做一个快照,此时快照中存活的,本次垃圾回收就算存活的,不回收
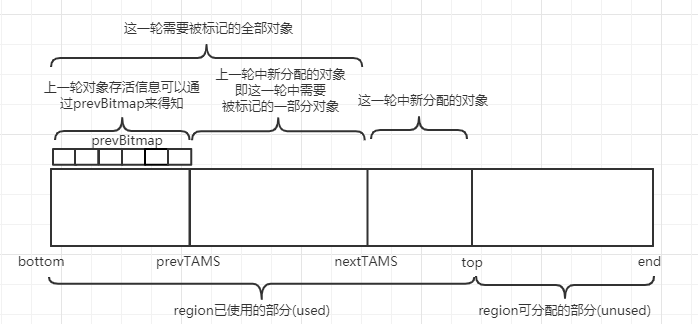
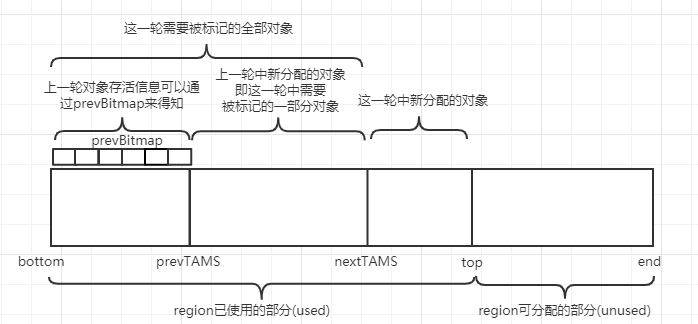
1. 新添加的对象
视为存活的。为了好管理,新添加的和快照中的分开存放。如何分开存放呢?
每个region记录着两个top-at-mark-start(TAMS)指针,分别为prevTAMS和nextTAMS。在TAMS以上的对象就是新分配的,因而被视为隐式marked。
2. 修改已经在snapshot的对象
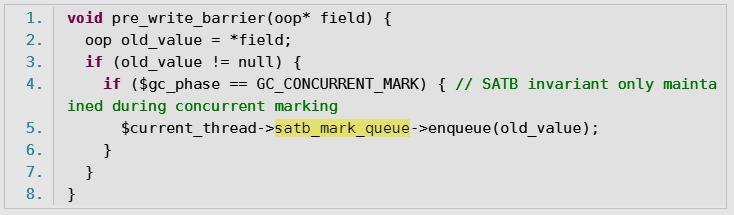
总结:【对于修改的对象,利用SATB write barrier,记录到satb_mark_queue中,remark阶段只扫描queue】
为解决已经标记过的对象做修改,例如这种情况:
就有了SATB write barrier
用pre-write barrier
- 把字段原本引用的对象变灰
- 把每次引用关系变化时旧的引用值记下来(记录到satb_mark_queue中)
- CMS的incremental update设计使得它在remark阶段必须重新扫描所有线程栈和整个young gen作为root;
G1的SATB设计在remark阶段则只需要扫描剩下的satb_mark_queue。
两个BitMap
两个TAMS指针
并发标记产生新对象处理【TAMS】


GC 线程工作在 prevTAMS 和 NextTAMS 之间
- NextTAMS 与 Top 之间的对象,就是本次并发标记阶段用户线程新分配的对象,它们是隐式存活的。


- 【好文】【原创】面试官问我G1回收器怎么知道你是什么时候的垃圾? - why技术 - 博客园
- 【好文】[HotSpot VM] 请教G1算法的原理 - 资料 - 高级语言虚拟机 - ITeye群组
- 【好文】G1 收集器原理理解与分析 - 知乎
有变动的对象【SATB】
SATB记录下有变动的对象

R大对SATB的解释:
其实只需要用pre-write barrier把每次引用关系变化时旧的引用值记下来就好了。这样,等concurrent marker到达某个对象时,这个对象的所有引用类型字段的变化全都有记录在案,就不会漏掉任何在snapshot里活的对象。当然,很可能有对象在snapshot中是活的,但随着并发GC的进行它可能本来已经死了,但SATB还是会让它活过这次GC。CMS的incremental update设计使得它在remark阶段必须重新扫描所有线程栈和整个young gen作为root;G1的SATB设计在remark阶段则只需要扫描剩下的satb_mark_queue ,解决了CMS垃圾收集器重新标记阶段长时间STW的潜在风险。”
筛选回收阶段【判断回收价值,所以要筛选】
负责更新 Region 的统计数据,对各个 Region 的回收价值和成本进行排序
CSet【判断回收价值】
如何选出垃圾最多的region呢,需要一个cset(collection set)来存放要回收的region。
CSet的选定完全靠统计模型找处收益最高、开销不超过用户指定的上限的若干region。

G1参数
- -XX:+UseG1GC
- 【Region大小】-XX:G1HeapRegionSize //默认把堆内存按照2048份均分,也可以指定,如1,2,4,8,16,32,最大值为32M
- 【新生代region比例】-XX:G1NewSizePercent //5%,刚开始默认新生代堆内存的占比是5%,对应大概100个region
- 【新生代region比例】-XX:G1MaxNewSizePercent //60%,G1会根据实际的GC情况(主要是暂停时间)来动态的调整新生代的大小
- 【老年代gc阈值比例】-XX:InitiatingHeapOccupancyPercent //45%,这里是整体堆中存活对象(不是老年代)占据堆内存45%的Region的时候,尝试混合回收。大概是接近1000个region。【jdk9动态调整】
- 【暂停时间】-XX:MaxGCPauseMills=200
- 不要使用-xmn设置young区大小,设置后会覆盖MaxGCPauseMills
- 年轻代会动态调整eden区个数:-XX:G1MaxNewSizePercent
- 老年代会调整cset的回收比例:-XX:G1OldCSetRegionThresholdPercent
- 【一个周期内触发Mixed GC最大次数】-XX:G1MixedGCCountTarget:指定一个周期内触发Mixed GC最大次数,默认值8。也就是在一次全局并发标记后,最多接着8此Mixed GC,也就是会把全局并发标记阶段生成的Cset里的Region拆分为最多8部分
G1垃圾回收参数优化 - 知乎
G1调优常用参数及其作用_低调的JVM的博客-CSDN博客_g1参数
G1对比CMS

- G1 优点:
- 停顿时间短;
- 用户可以指定最大停顿时间;
- 不会产生内存碎片:G1 的内存布局并不是固定大小以及固定数量的分代区域划分,而是把连续的Java堆划分为多个大小相等的独立区域 (Region),G1 从整体来看是基于“标记-整理”算法实现的收集器,但从局部 (两个Region 之间)上看又是基于“标记-复制”算法实现,不会像 CMS (“标记-清除”算法) 那样产生内存碎片。
- G1 缺点:
G1 需要记忆集 (具体来说是卡表card table,card table是remembered set的一种实现)来
记录新生代和老年代之间的引用关系,这种数据结构在 G1 中需要占用大量的内存,可能达到整个堆内存容量的 20% 甚至更多。而且 G1 中维护记忆集的成本较高,带来了更高的执行负载,影响效率。
按照《深入理解Java虚拟机》作者的说法,CMS 在小内存应用上的表现要优于 G1,而大内存应用上 G1 更有优势,大小内存的界限是6GB到8GB。
java - jvm G1垃圾收集器有什么缺点? - SegmentFault 思否
jvm系列(三):GC算法 垃圾收集器
GC日志
UseParallelGC日志格式
- +UseParallelGC = 新生代ParallelScavenge + 老年代SerialOld
- +UseParallelOldGC = 新生代ParallelScavenge + 老年代ParallelOld(ps+po)
YoungGC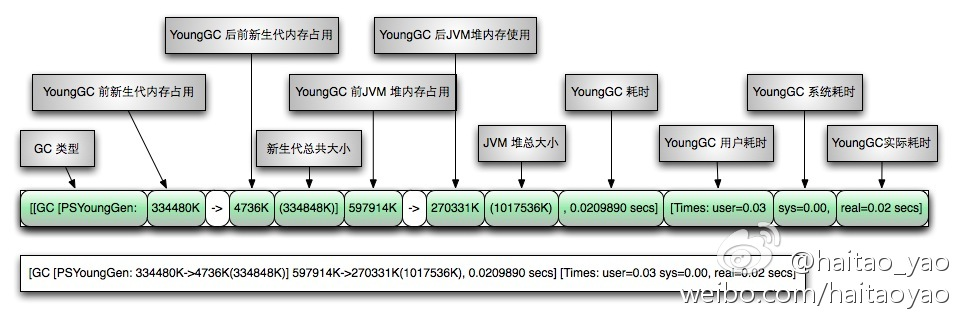

cms gc日志格式

- 查看GC前后的堆、方法区可用容量变化,在JDK 9之前使用-XX:+PrintHeapAtGC,JDK 9之后使用-Xlog:gc+heap=debug

- 【根据日志调优】Understanding CMS GC Logs
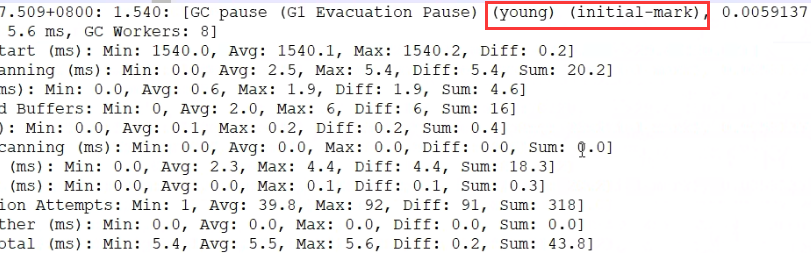
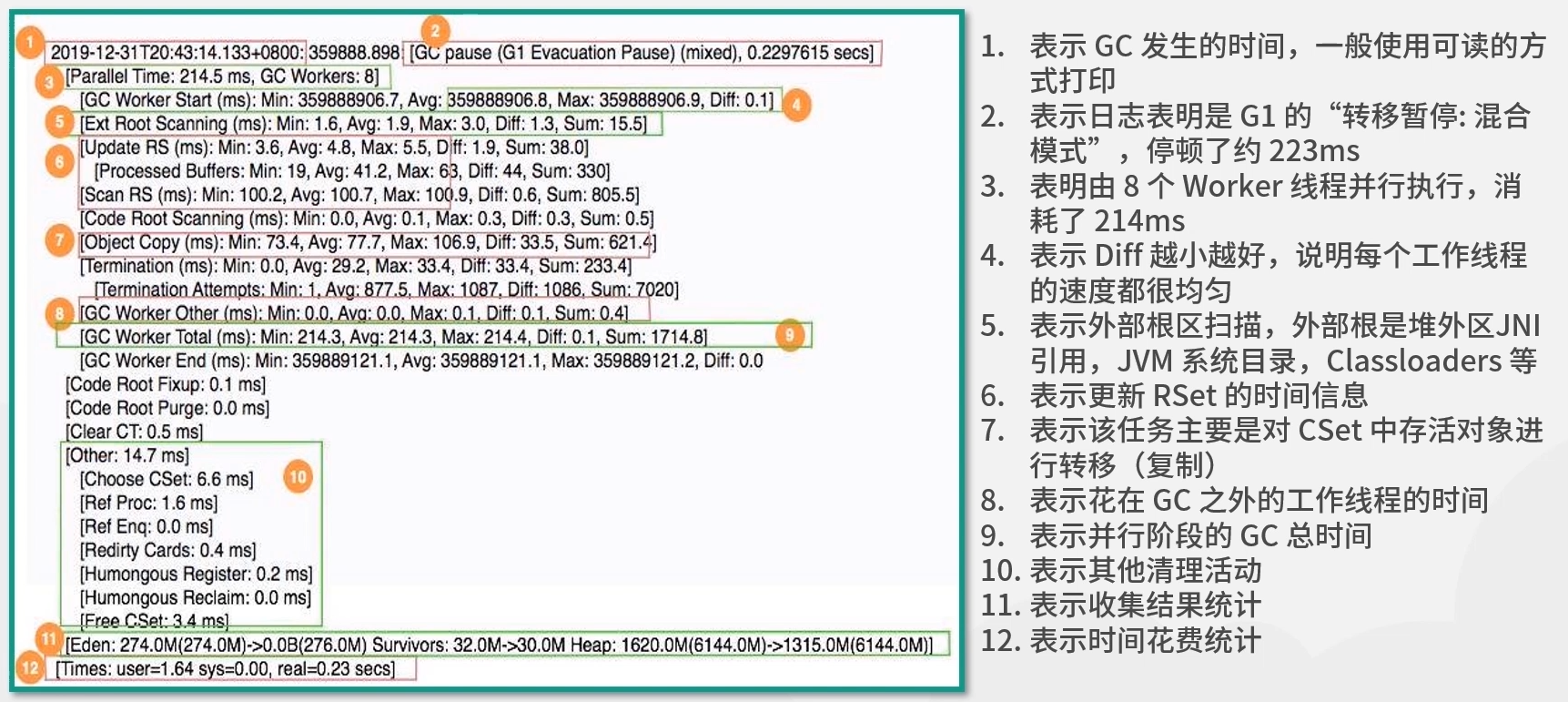
G1 gc日志
Metaspace日志中的used,capacity,committed,reserved
【好文】GC日志中,Metaspace的committed和reserved含义_G-CSDN博客_metaspace committed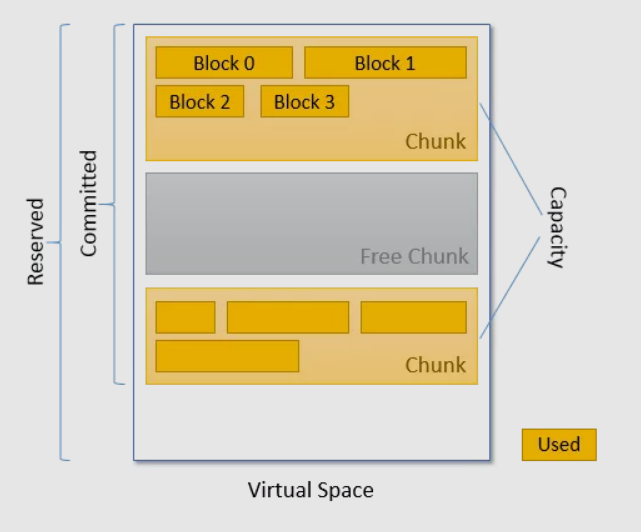
reserved:元数据的保留空间【总空间?】、
- reserved是jvm启动时根据参数和操作系统预留的内存大小。
committed:提交过的空间,以前分配过的空间
capacity:按chunk计算的空间。
- 有些Chunk的数据可能会被回收,那么这些Chunk属于committe的一部分,但不属于capacity
used:因为chunk不会100%使用,chunk中实际使用的空间。
最佳实践
不要使用-xmn设置young区大小,设置后会覆盖MaxGCPauseMills

若有收获,就点个赞吧
0 人点赞
