教程
zookeeper角色&流程
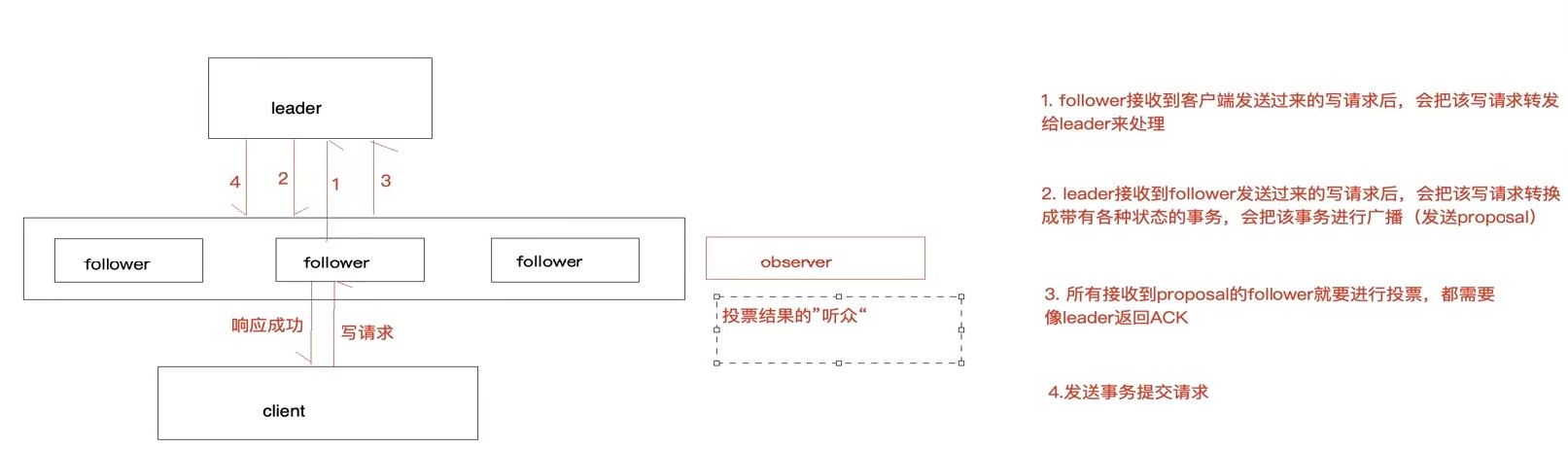
读写流程
peerType=observer 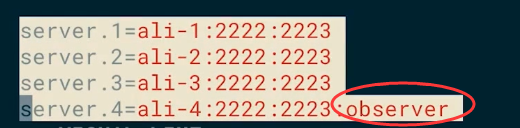
服务器之间的通讯端口:服务器之间的投票选举端口
节点类型
- 持久节点
- 顺序
- 不顺序
- 临时节点
- 顺序
- 不顺序
zookeeper属于cp还是ap?
Is ZooKeeper CP or AP · warrenzhu25/Knowledge Wiki
- zookeeper 并不是强一致性 不是C
- 是弱一致性
- zookeeper确保对znode树的每一个修改都会被复制到集合体中超过半数的机器上。那么就有可能有节点的数据不是最新的而被客户端访问到。并且会有一个时间点,在集群中是不一致的.也就是Zookeeper只保证最终一致性,
- zookeeper并没有可用性,不是A
- follow负责读请求的处理,follow接收到写请求也会转发给leader,交由leader来处理。所以当产生分区,写不可用。
zookeeper 不是ap也不是cp,因为
【出现分区,可读,不可写。可读是p满足分区容错,不可写就是不可用状态?】
【p就是出现分区可以对外提供服务,a是数据同步的时候可以对外提供服务,c是数据同步一致】
拥有大多数节点的分区还可以继续提供服务;但对于少数节点分区来说,即使节点都活着,也不能正常处理读写请求。所以在出现网络分区时,ZK 的写操作不满足CAP可用性
-
ZAB协议
ZooKeeper并没有完全采用Paxos算法,而是使用了一种称为ZooKeeper Atomic Broadcast(ZAB,zookeeper原子消息广播协议)的协议
(1)集群在半数以下节点宕机的情况下,能正常对外提供服务;
(2)客户端的写请求全部转交给leader来处理,leader需确保写变更能实时同步给所有follower及observer;
(3)leader宕机或整个集群重启时,需要确保那些已经在leader服务器上提交的事务最终被所有服务器都提交(过半节点的ack反馈),确保丢弃那些只在leader服务器上被提出的事务(没有被半数提交,丢弃),并保证集群能快速恢复到故障前的状态。

leader选举
发送(myid,ZXID)ZXID也就是节点本地的最新事务编号
- ZXID大的优先(数据新)
- 再比较myid,大的优先
zookeeper 事件监听丢失问题
虽然curator帮开发人员封装了重复注册监听的过程,但是内部依旧需要重复进行注册,而在第一个watcher触发第二个watcher还未注册成功的间隙,进行节点数据的修改,显然无法收到watcher事件。
Zookeeper之Watcher监听事件丢失分析_程序新视界-CSDN博客
应用
分布式唯一id
-
集群管理
监控zk目录
- 注册:目录下创建临时节点
- 宕机:临时节点删除,被监控到。
【临时节点】【临时节点】【临时节点】
连接断了之后,ZK不会马上移除临时数据,只有当SESSIONEXPIRED之后,才会把这个会话建立的临时数据移除。因此,用户需要谨慎设置Session_TimeOut
1. 【非公平锁】利用节点名唯一性
谁创建成功,谁获得锁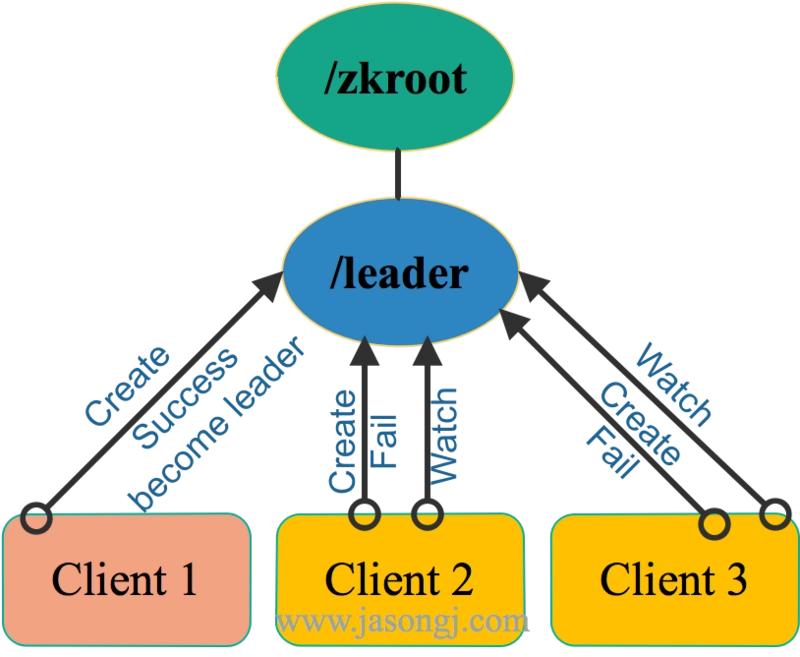
zookeeper分布式锁 - 个人文章 - SegmentFault 思否
同时一旦 Leader 放弃领导权,Zookeeper 需要同时通知上万个 Follower,负载较大。
2. 【公平锁】利用顺序节点
谁创建的顺序节点最小,谁获得锁。
顺序节点优化
一个节点只需watch比他小的节点,不用watch所有。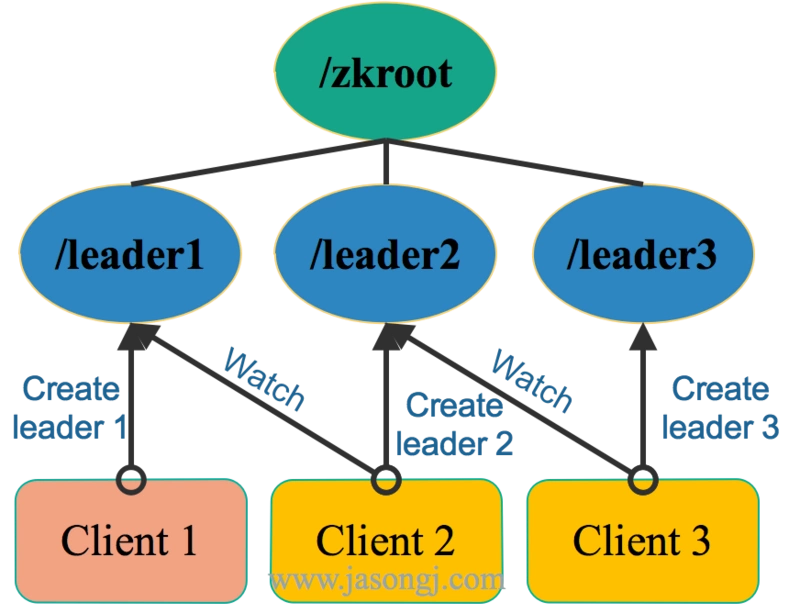
- 使用zookeeper实现分布式锁 - 为程序员服务
- 使用zookeeper实现分布式锁 - 简书
3. 【读写锁】读写锁原理
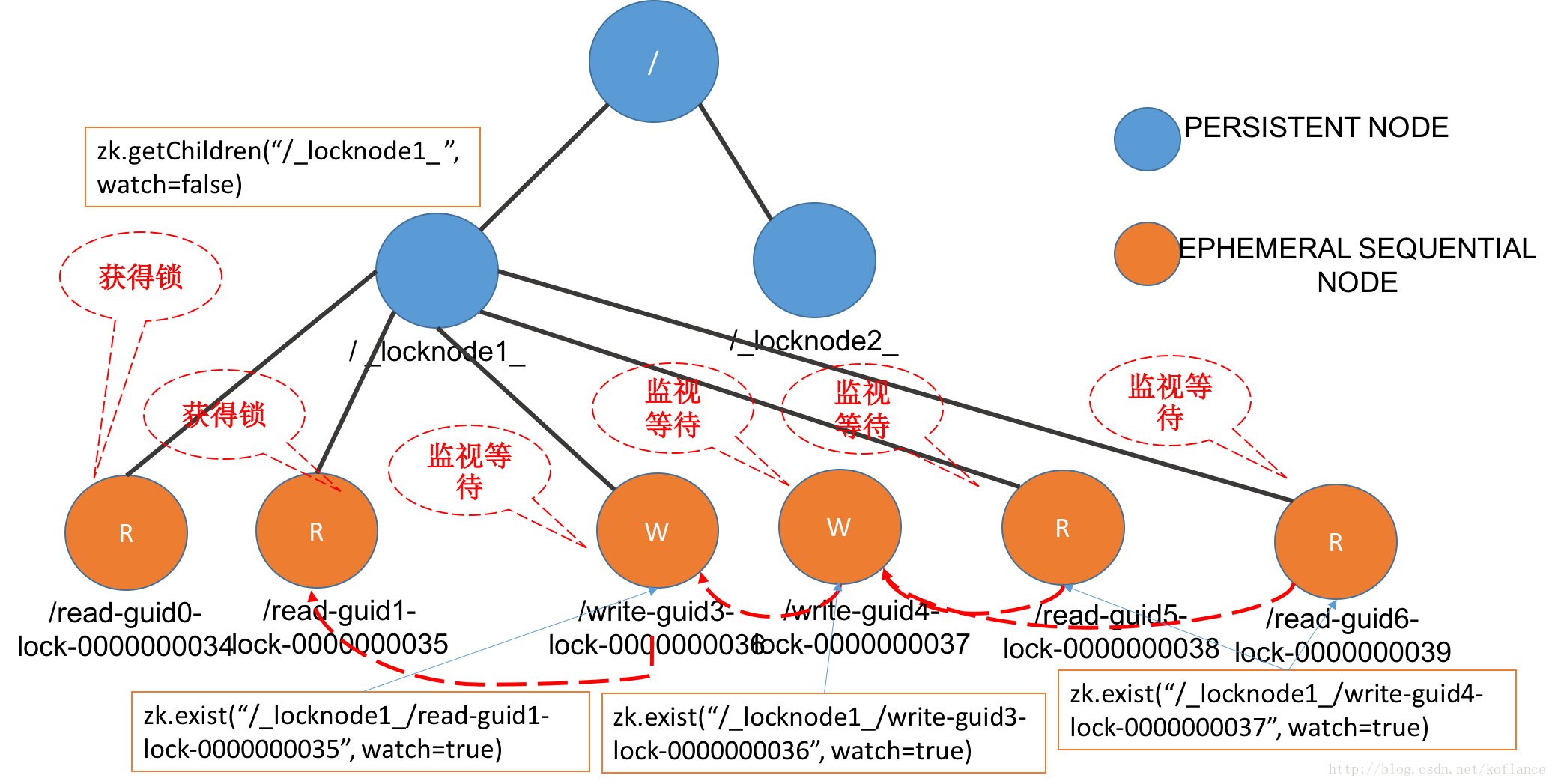
临时顺序节点
read 监视 前面的 write
write 监视 前面的 节点(不管是read还是write)

若有收获,就点个赞吧
0 人点赞
