- Spark streaming 是微批处理,延迟秒级。
- flink四大基石 :窗口 时间及水位线 状态 检查点
- flink序列化框架直接操作二进制

JobManager将JobGraph转换为数据流 图,包含所有可以并发执行的任务。
Opertator Chains
disableChaining()
- startNewChain() 不与上游合并
slotSharingGroup():设置group,不同group不共享slot
Source
自定义Source:flinkdemo/FileCountryDictSourceFunction.java at main · justforword/flinkdemo
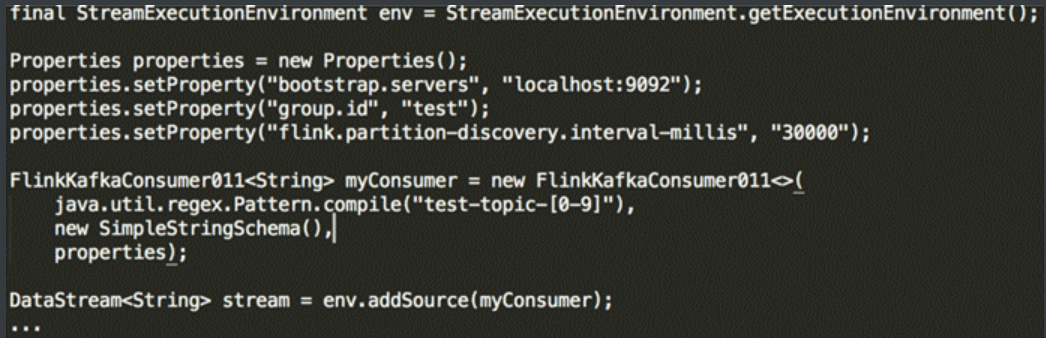
kafka Source

动态Topic discoveryFlink Kafka Consumer支持动态发现Kafka Topic,仅限通过正则表达式指定topic的方式
- 默认禁止动态发现topic,把flink.partition-discovery.interval-millis设置大于0即可启用
Transformation

-
operators
connect & union
connect之后生成ConnectedStreams,会对两个流的数据应用不同的处理方法,并且双流之间可以共享状态(比如计数)。这在第一个流的输入会影响第二个流时, 会非常有用。union 合并多个流,新的流包含所有流的数据。
- union是DataStream -> DataStream
- connect只能连接两个流,而union可以连接多于两个流
connect连接的两个流类型可以不一致,而union连接的流的类型必须一致
connect【各流处理各的】
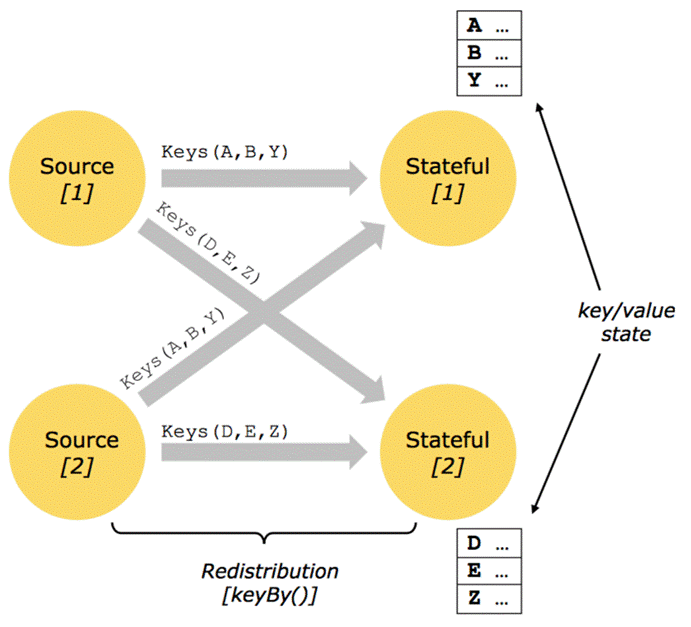
keyby
转换关系: DataStream -> KeyedStream
keyedStream.connect()
key的数据类型
不能是没有覆盖hashCode方法的POJO(也就是bean)
- 不能是数组
自定义分区器 解决数据倾斜

keySelector选择key,然后分区。


rebalance() & rescale

rescale
- 数据传输都在一个TaskManager内,不需要通过网络。
reduce
OutputTag:分流
定义:


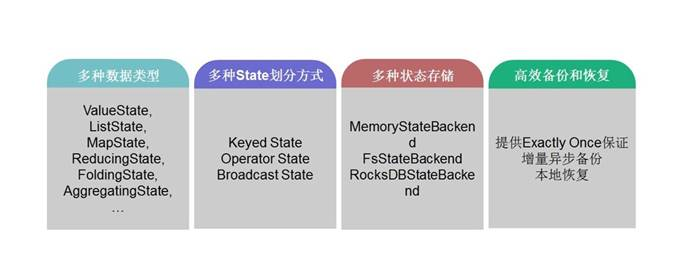
状态与容错
重启job策略

state

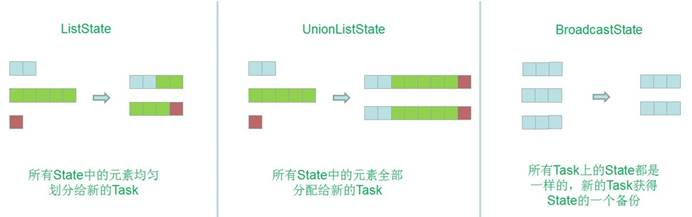
Operator State
- 只支持ListState
绑定到特定operator并行实例,每个operator的并行实例维护一个状态
Keyed State
只能在作用于KeyedStrem上的function/Operator里使用
- 每个并行keyed Operator的每个实例的每个key有一个Keyed State:即
- 支持所有类型
Broadcast State
- 只支持MapState
checkpoint开启
默认没有开启checkpointStreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//start a checkpoint every 1000 ms env.enableCheckpointing(1000);
//advanced options:
//set mode to exactly-once (this is the default) env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
//make sure 500 ms of progress happen between checkpoints env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);
//checkpoints have to complete within one minute,or are discarded env.getCheckpointConfig().setCheckpointTimeout(60000);
//allow only one checkpoint to be in progress at the same time env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
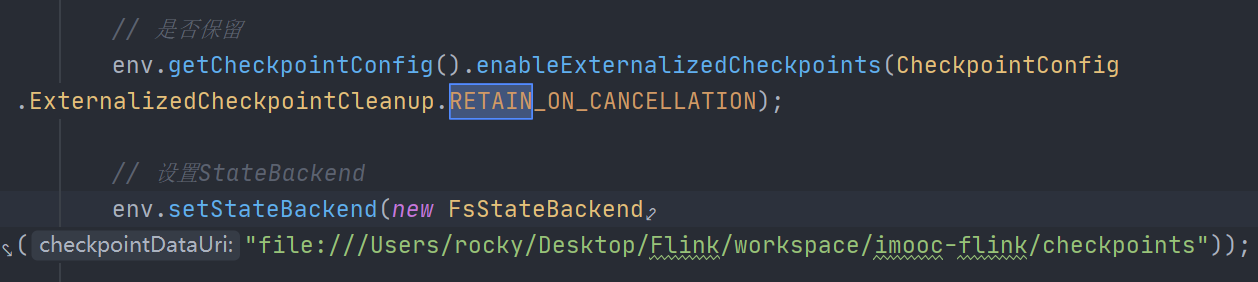
//enable externalized checkpoints which are retained after job cancellation env.getCheckpointConfig().enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
env.getCheckpointConfig().setFailOnCheckpointingErrors(true);
Flink检查点(checkpoint)、保存点(savepoint)的区别与联系_LittleMagic’s Blog-CSDN博客
使用Operator State
方式1:实现CheckpointedFunction
Stateful function(RichFunction)实现CheckpointedFunction接口,必须实现两个方法:
- void snapshotState(FunctionSnapshotContext context) throws Exception
- Checkpoint执行时调用
- 一般用于原始状态与托管状态进行交换
- Void initializeState(FunctionlnitializationContext context) throws Exception;(初始化以及恢复逻辑)
- Stateful function第一次初始化时调用
- Stateful function从较早的checkpoint恢复时调用
- 相比于open()方法:context可判断是否复活,恢复状态。

方式2:实现ListCheckpointed(@Deprecated)
这个接口自己本身就带了一个ListState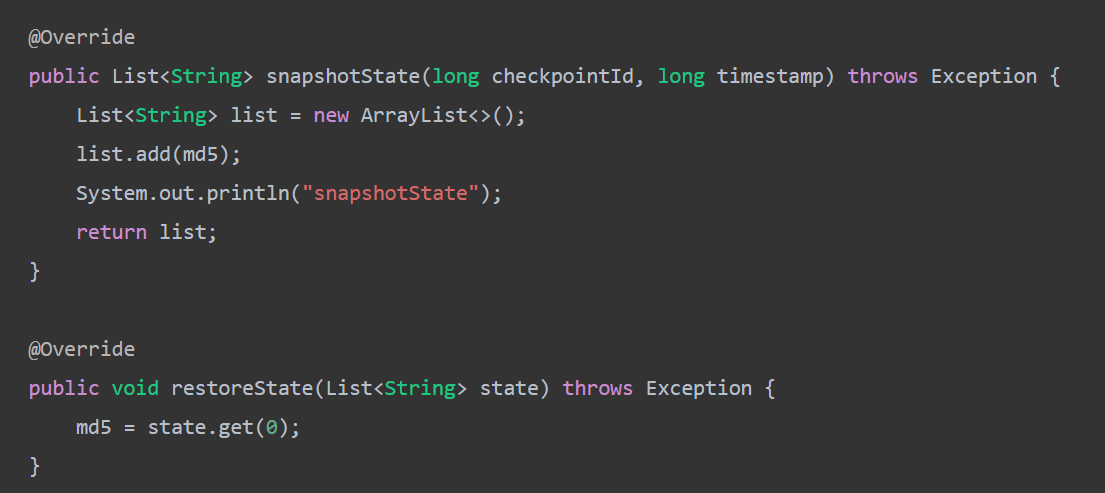
使用KeyedState
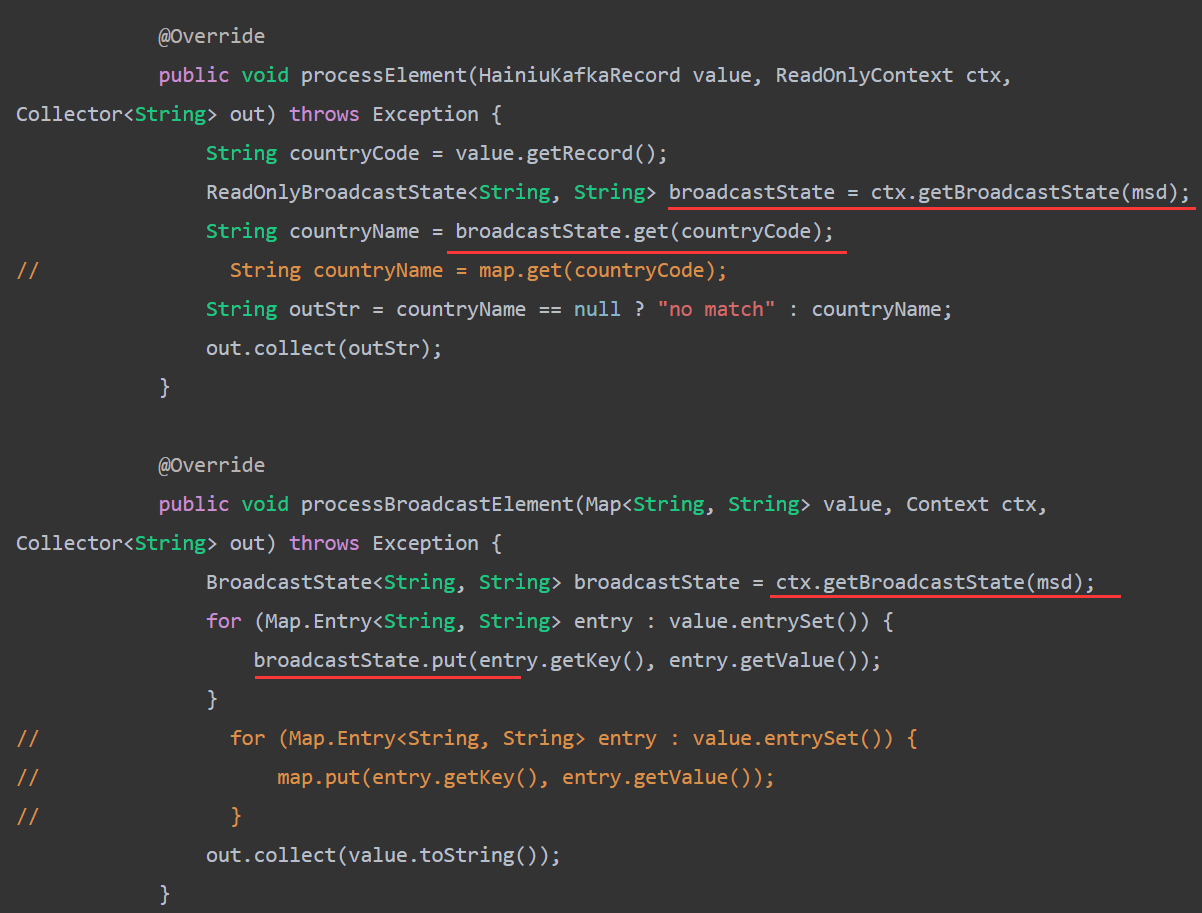
public class CountryCodeConnectKeyByKeyedState {
public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.enableCheckpointing(1000);CheckpointConfig checkpointConfig = env.getCheckpointConfig();//保存EXACTLY_ONCEcheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);//每次ck之间的间隔,不会重叠checkpointConfig.setMinPauseBetweenCheckpoints(2000L);//每次ck的超时时间checkpointConfig.setCheckpointTimeout(20000L);//如果ck执行失败,程序是否停止checkpointConfig.setFailOnCheckpointingErrors(true);//job在执行CANCE的时候是否删除ck数据checkpointConfig.enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);//恢复策略env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, // number of restart attemptsTime.of(0, TimeUnit.SECONDS) // delay));DataStreamSource<String> countryDictSource = env.addSource(new FileCountryDictSourceFunction());Properties kafkaConsumerProps = new Properties();kafkaConsumerProps.setProperty("bootstrap.servers", "s1.hadoop:9092,s2.hadoop:9092,s3.hadoop:9092,s4.hadoop:9092,s5.hadoop:9092,s6.hadoop:9092,s7.hadoop:9092,s8.hadoop:9092");kafkaConsumerProps.setProperty("group.id", "qingniuflink");kafkaConsumerProps.setProperty("flink.partition-discovery.interval-millis", "30000");FlinkKafkaConsumer010<HainiuKafkaRecord> kafkaSource = new FlinkKafkaConsumer010<>("flink_event", new HainiuKafkaRecordSchema(), kafkaConsumerProps);// kafkaSource.setStartFromEarliest()// kafkaSource.setStartFromGroupOffsets()kafkaSource.setStartFromLatest();DataStreamSource<HainiuKafkaRecord> kafkainput = env.addSource(kafkaSource);KeyedStream<Tuple2<String, String>, String> countryDictKeyBy = countryDictSource.map(new MapFunction<String, Tuple2<String, String>>() {@Overridepublic Tuple2<String, String> map(String value) throws Exception {String[] split = value.split("\t");return Tuple2.of(split[0], split[1]);}}).keyBy(new KeySelector<Tuple2<String, String>, String>() {@Overridepublic String getKey(Tuple2<String, String> value) throws Exception {return value.f0;}});KeyedStream<HainiuKafkaRecord, String> record = kafkainput.keyBy(new KeySelector<HainiuKafkaRecord, String>() {@Overridepublic String getKey(HainiuKafkaRecord value) throws Exception {return value.getRecord();}});ConnectedStreams<Tuple2<String, String>, HainiuKafkaRecord> connect = countryDictKeyBy.connect(record);SingleOutputStreamOperator<String> connectInput = connect.process(new KeyedCoProcessFunction<String, Tuple2<String, String>, HainiuKafkaRecord, String>() {private MapState<String,String> map = null;@Overridepublic void open(Configuration parameters) throws Exception {//keyState的TTL策略StateTtlConfig ttlConfig = StateTtlConfig//keyState的超时时间为100秒.newBuilder(Time.seconds(100))//当创建和更新时,重新计时超时时间.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)//失败时不返回keyState的值//.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)//失败时返回keyState的值.setStateVisibility(StateTtlConfig.StateVisibility.ReturnExpiredIfNotCleanedUp)//ttl的时间处理等级目前只支持ProcessingTime.setTimeCharacteristic(StateTtlConfig.TimeCharacteristic.ProcessingTime).build();//从runtimeContext中获得ck时保存的状态MapStateDescriptor<String,String> msd = new MapStateDescriptor<String, String>("map",String.class,String.class);msd.enableTimeToLive(ttlConfig);map = getRuntimeContext().getMapState(msd);}@Overridepublic void processElement1(Tuple2<String, String> value, Context ctx, Collector<String> out) throws Exception {map.put(ctx.getCurrentKey(), value.f1);out.collect(value.toString());}@Overridepublic void processElement2(HainiuKafkaRecord value, Context ctx, Collector<String> out) throws Exception {for(Map.Entry<String,String> m:map.entries()){System.out.println(m.getKey());System.out.println(m.getValue());}if(value.getRecord().equals("CN")){int a = 1/0;}String countryCode = ctx.getCurrentKey();String countryName = map.get(countryCode);String outStr = countryName == null ? "no match" : countryName;out.collect(outStr);}});connectInput.print();env.execute();}}
使用BroadcastState
Broadcast State使用套路(三步)
- 创建常规事件流DataStream / KeyedDataStream
- 创建BroadcastedStream:创建规则流 / 配置流(低吞吐)并广播
- 连接两个Stream,生成BroadcastConnectedStream并实现计算处理
- proccess(BroadcastProcessFunction and KeyedBroadcastProcessFunction)
BroadcastedStream和 keyedStream做connect:
KeyedBroadcastProcessFunction
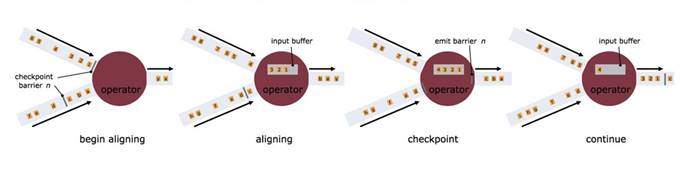
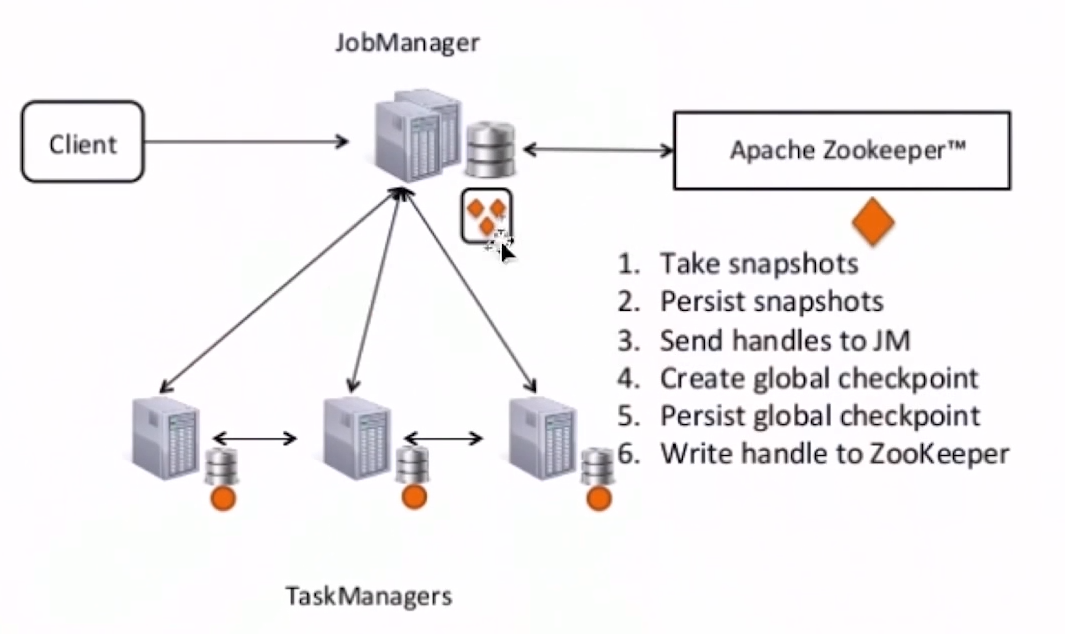
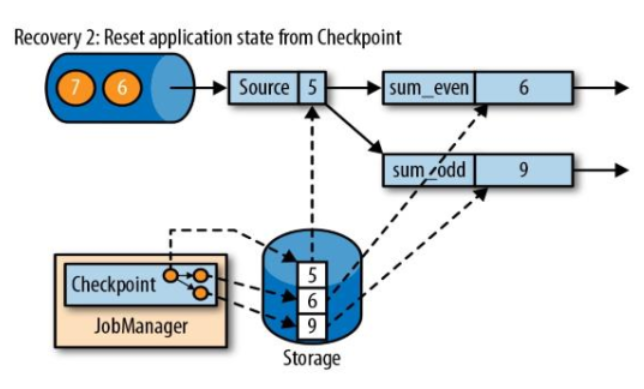
Checkpoint原理
- 通过往source 注入barrier
- barrier作为checkpoint的标志
flink怎么保证Exactly Once
- barrier n 所属的数据流先不处理,从这些数据流中接收到数据被放入接收缓存里(input buffer)
- 当从最后一个流中提取到barrier n 时,operator 会发射出所有等待向后发送的数据,然后发射snapshot n 所属的barrier
State Backend

- MemoryStateBackend:将state保存到JobManager中。默认,异步。
- FsStateBackend(全量存储)
- 需要配合ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION
- RocksDBStateBackend(增量存储)
Savepoint:手动checkpoint

恢复:
- 从指定Savepoint恢复job
$ bin/flink run -s :savepointPath [:runArgs] - 从指定Savepoint恢复job(允许跳过不能映射的状态,例如删除了一个operator)
$ bin/flink run -s :savepointPath -n [:runArgs]
状态重新分配
kafka的source与sink的容错
- 如果Flink启用了检查点,Flink Kafka Consumer将会周期性的checkpoint其Kafka偏移量到快照。
kafka Consumer Offset提交:

time
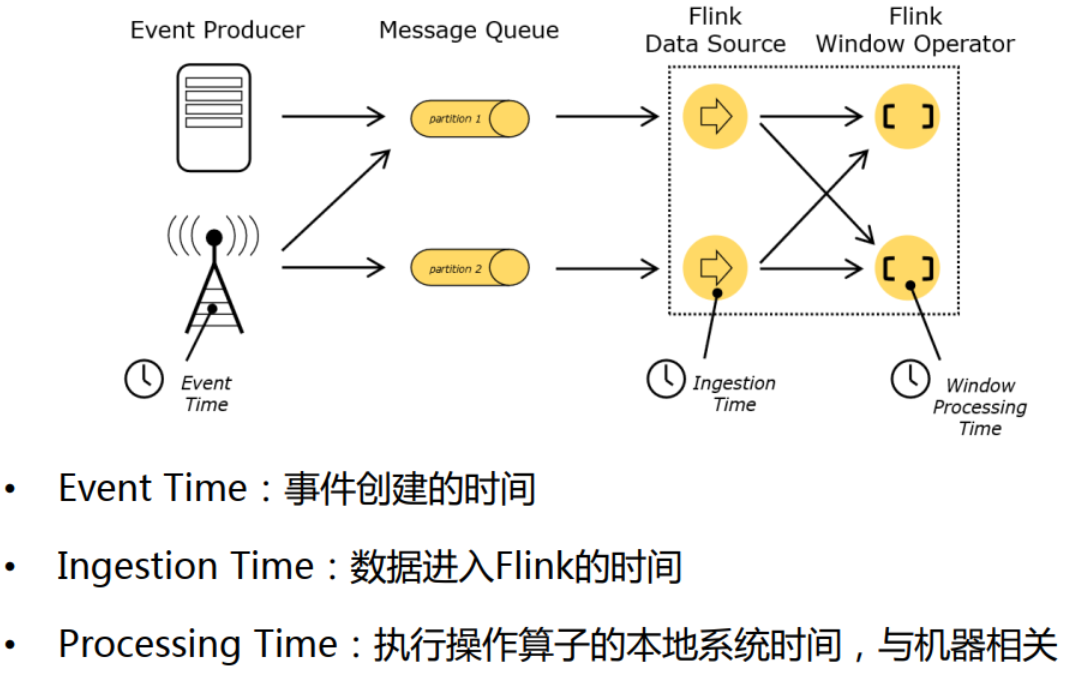

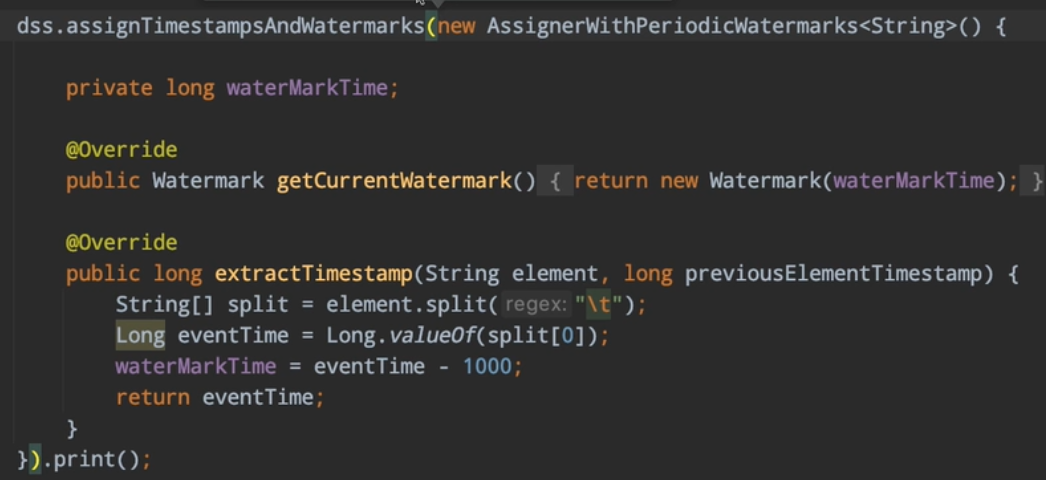
watermarker

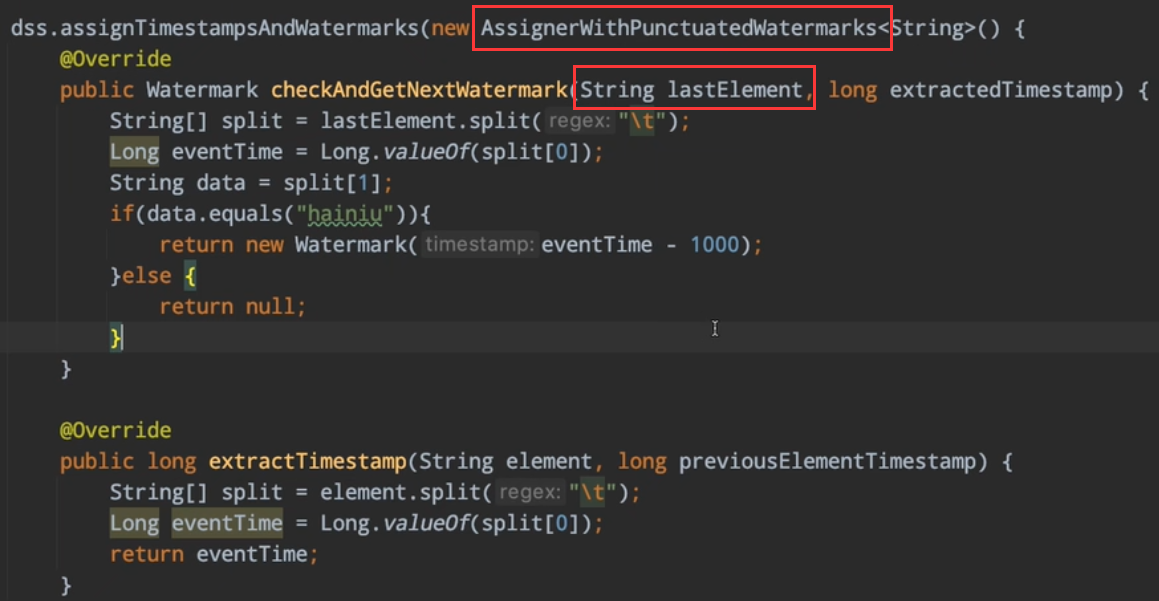

window

window分类
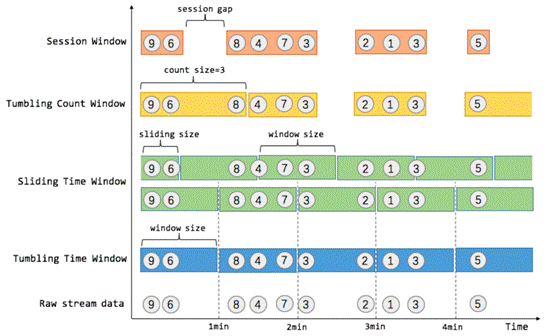
按时间
按数量
Global window
需要配置触发器,来触发窗口执行。
- Trigger :触发器
- Evictor :“驱逐者”


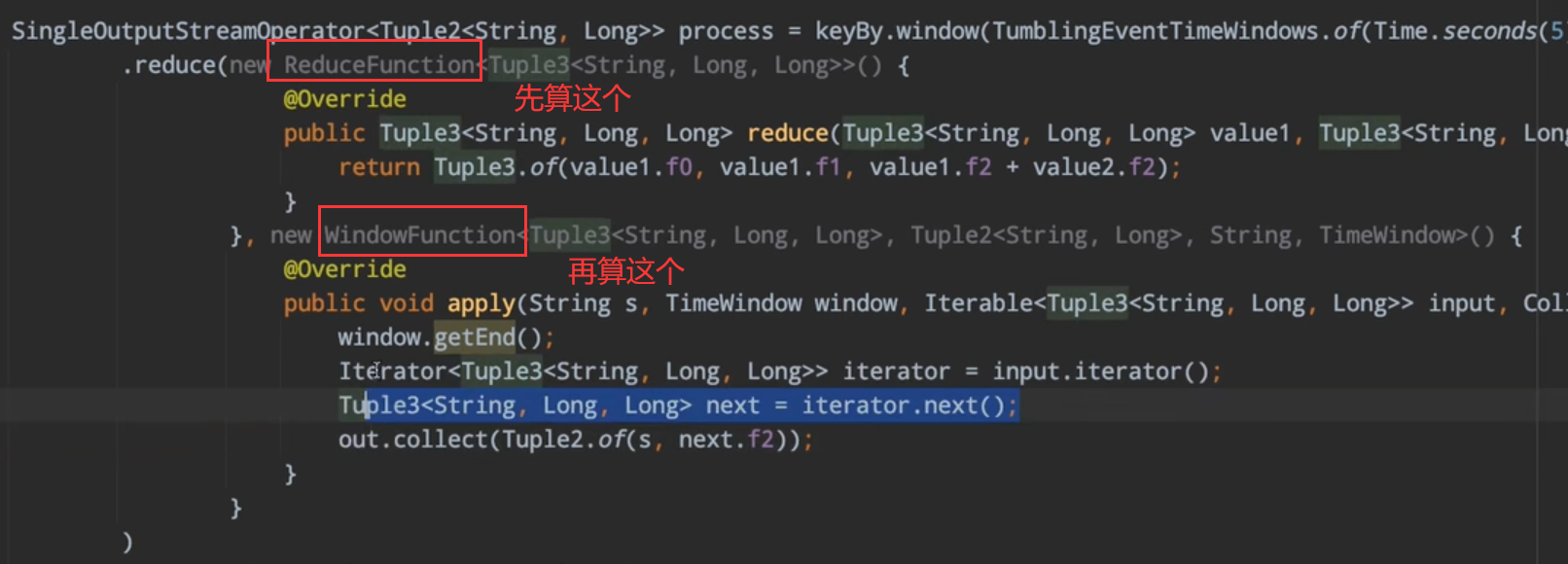
window operator
WindowsAll
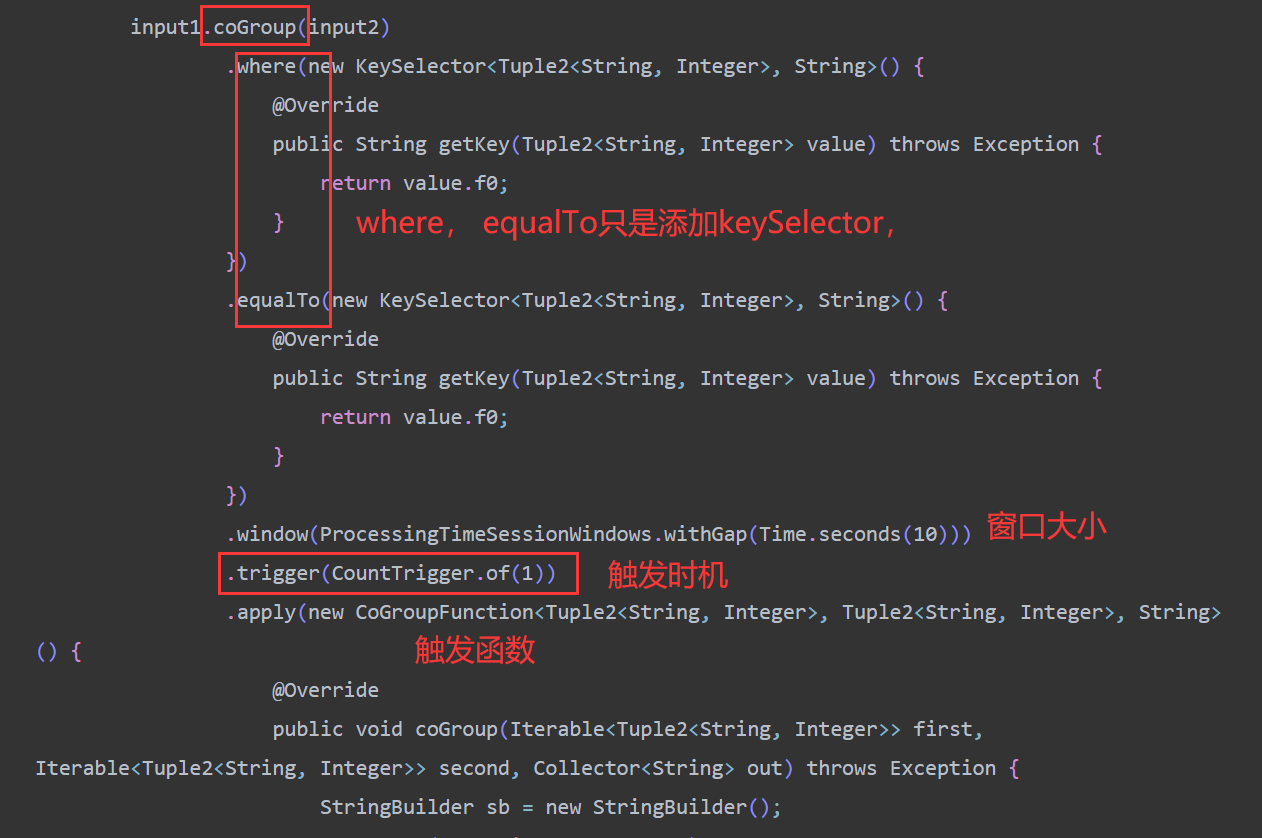
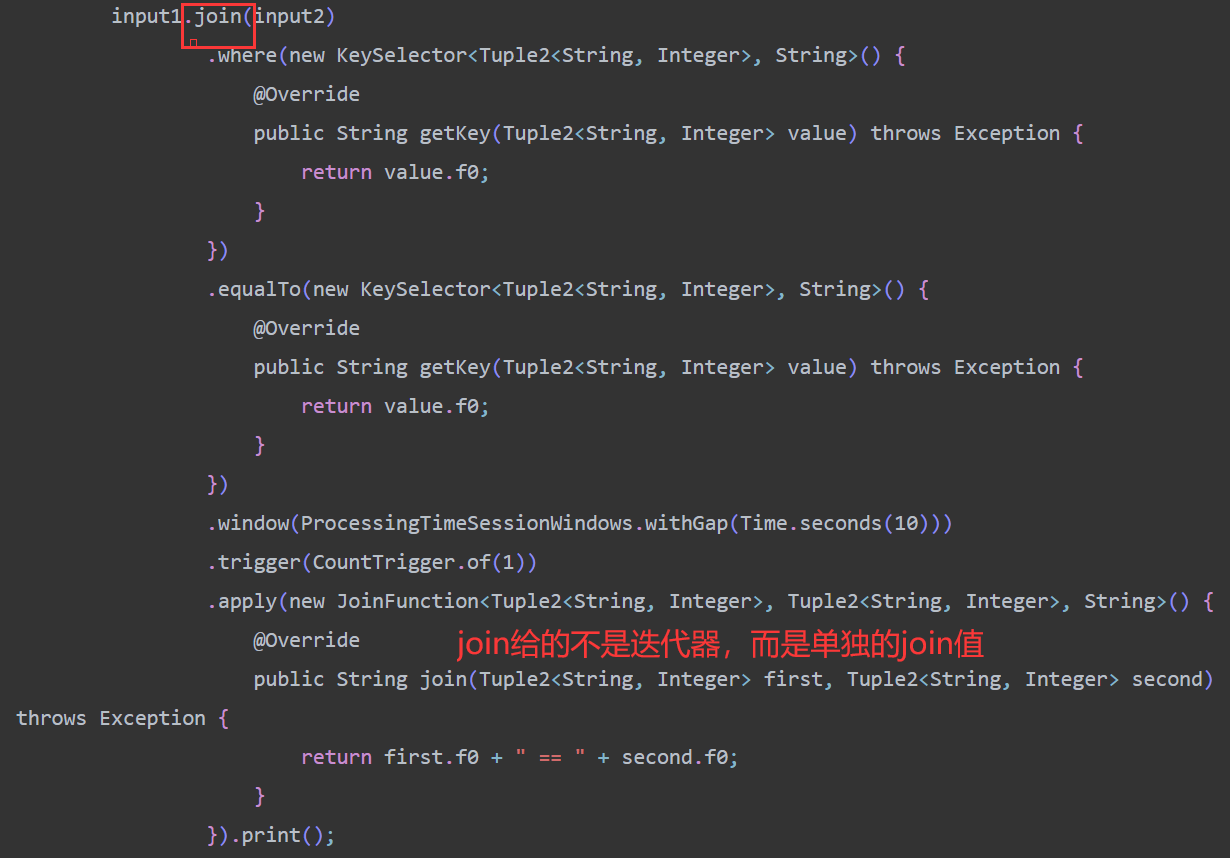
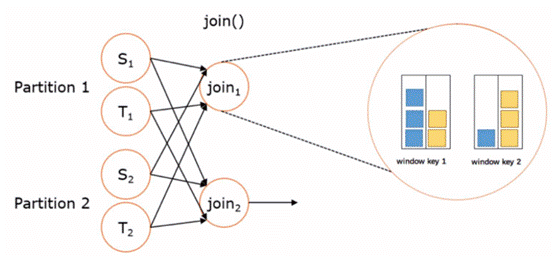
windows join
- cogroup
- join
ProcessFunction
ProcessFunction可以看作是一个具有keyed state 和 timers访问权的FlatMapFunction。
timerService

KeyedCoProcessFunction中的变量,所有key共享。解决方法:使用ValueState。
- 由于Flink对每个键和时间戳只维护一个计时器,因此可以通过降低计时器频率来合并计时器,从而减少计时器的数量。
- event-time timer只会在watermarks到来时触发
- 使用ctx.timerService().deleteEventTimeTimer删除过期Timer
累加器
————
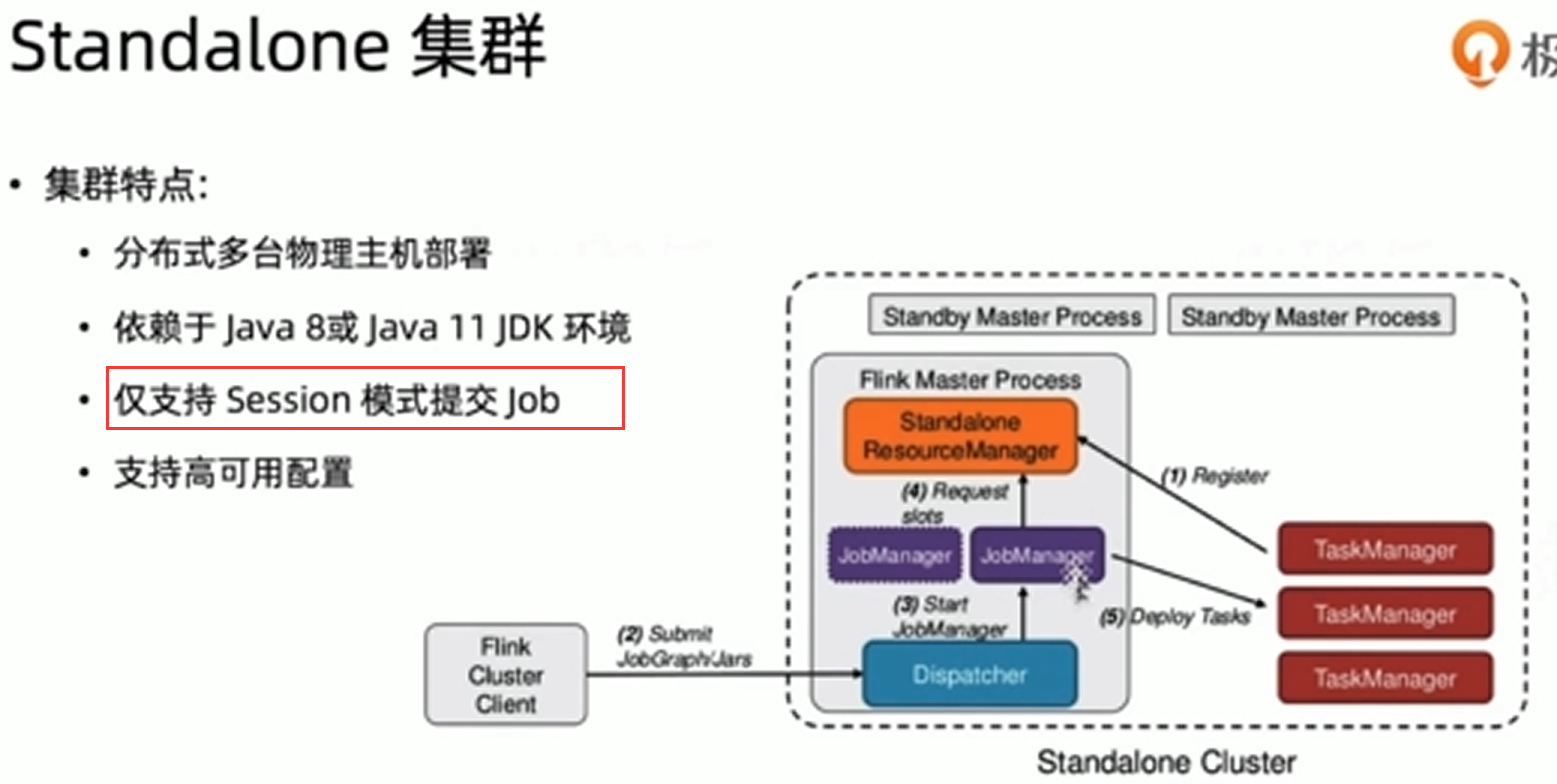
任务提交流程
window
window分类
window function 窗口函数

- sum函数其实调用的aggregate函数,aggregate调用reduce
- reduce接受两个相同类型的输入,生成一个同类型输出,所以泛型就一个
- aggregate的输入值、中间结果值、输出值它们3个类型可以各不相同,泛型有


其他api

延迟数据处理
时间语义
watermark
-
ProcessFunction API
定时器
-
状态管理
状态的分类
 f
f 算子状态
- 作用范围是一个算子(分区)
- kafka记录
- 键控状态
- 作用范围是每个key


- reduce
状态后端
exactly-once(默认)
- al least once




Flink检查点(checkpoint)、保存点(savepoint)的区别与联系_LittleMagic’s Blog-CSDN博客
state backends
默认异步快照
- MemoryStateBackend:将state保存到JobManager中。
- FsStateBackend
- 需要配合ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION

- RocksDBStateBackend
restart strategies

默认没有重启策略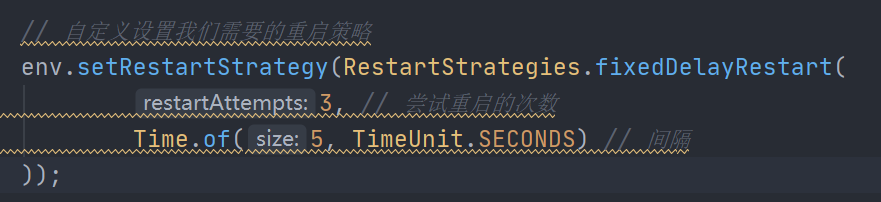
高可用
job持久化

checkpoint
 -
-
检查点

若有收获,就点个赞吧
0 人点赞
