细说:Unicode, UTF-8, UTF-16, UTF-32, UCS-2, UCS-4 - malecrab - 博客园
How does UTF-8 turn “😂” into “F09F9882”?
编码
从Unicode 2.0开始,Unicode采用了与ISO 10646-1相同的字库和字码
- Unicode编码点分为17个平面(plane),每个平面包含216(即65536)个码位(code point)。17个平面的码位可表示为从U+00 0000到U+10 FF FF【三个字节就够了其实】
- ISO 10646:编码空间为0x00000000~0x7F FF FF FF【四个字节】
usc-4
Unicode 的学名是 “Universal Multiple-Octet Coded Character Set”,简称为UCS。UCS 可以看作是 “Unicode Character Set” 的缩写。
为了能表示更多的文字,人们又提出了UCS-4,即用四个字节表示代码点。它的范围为 U+00000000~U+7FFFFFFF
usc-4与utf-32
Unicode 的 4 字节形式被称为 UCS-4 或 UTF-32
utf-32编码与ucs-4相同。可以说:UTF-32是UCS-4的一个子集。
uft8和unicode的关系

字符集、编码 - 知乎
unicode UCS-4 32位。
utf8是为了传输方便(英文用较少位表示)
utf16和unicode的关系
Unicode中UTF-8与UTF-16编码详解 - SegmentFault 思否
UTF-16可以为Unicode中所有的字符编码。
utf16和ucs-2的关系
UTF-16 与UCS-2一样,它使用两个字节为全世界最常用的63K字符编码,不同的是,它使用4个字节对不常用的字符进行编码。UTF-16属于变长编码。
ucs-2是定长的。
ansi 编码是什么
其实ANSI并不是某一种特定的字符编码,而是在不同的系统中,ANSI表示不同的编码。你的美国同事Bob的系统中ANSI编码其实是ASCII编码(ASCII编码不能表示汉字,所以汉字为乱码),而你的系统中(“汉字”正常显示)ANSI编码其实是GBK编码,而韩文系统中(“한국어”正常显示)ANSI编码其实是EUC-KR编码。
BOM(Byte Order Mark)
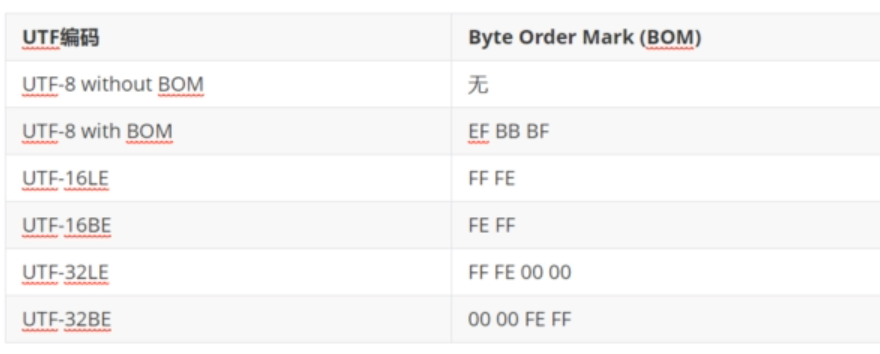
- utf-16 utf-32表示字节序
- utf-8 with BOM就表示使用的utf-8编码。
-
String
getBytes()默认使用file.encoding编码来得到对应的bytes。(可以指定编码)

String utf-16
乱码
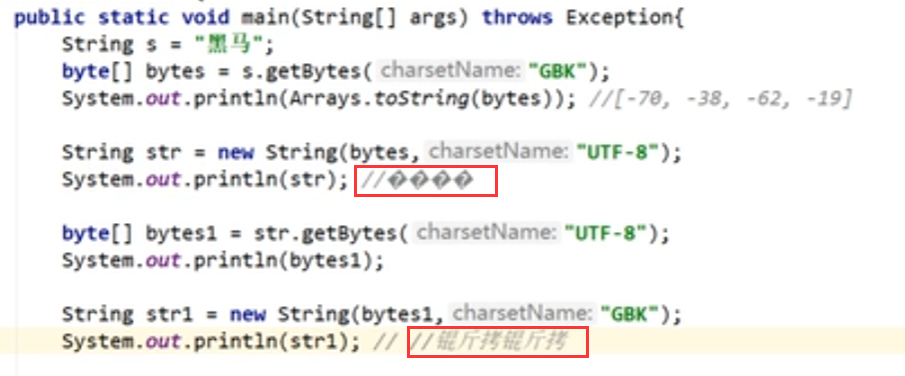
- ??:字符 -> 二进制时,编码找不到对应字符,就用?代替了。
- 方框问号(utf-8特有字符):二进制 -> 字符,utf-8找不到就用方框问号替代。
- 锟斤拷:方框问号 -> 二进制(utf-8)-> 再转为GBK字符就会出现“锟斤拷”
乱码不能还原的根本是,找不到字符,产生了替代。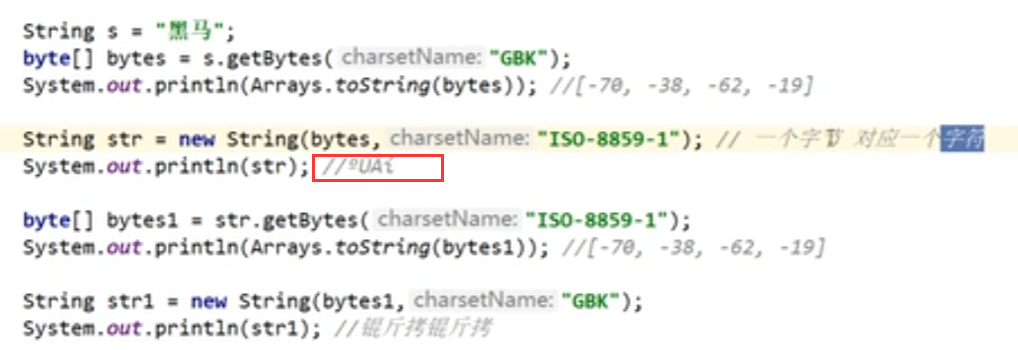
复制图片应该使用ISO-8859-1编码

若有收获,就点个赞吧
0 人点赞
