hdfs
参数优先级
参数优先级排序:(1)客户端代码中设置的值 >(2)ClassPath下的用户自定义配置文件 >(3)然后是服务器的自定义配置(xxx-site.xml) >(4)服务器的默认配置(xxx-default.xml)
hdfs写入数据流程
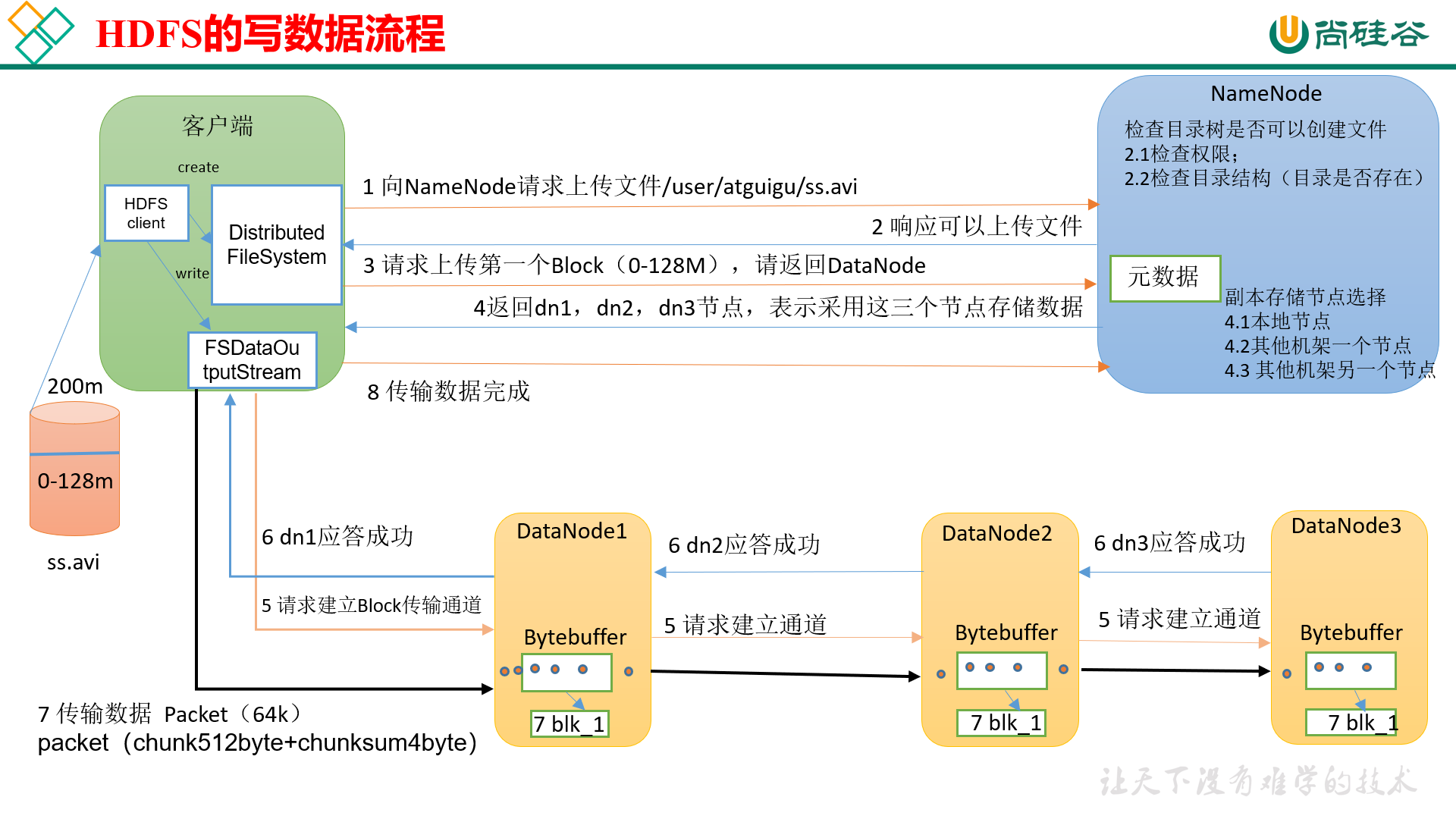
HDFS采取了串行写的方案,即客户端向第一个datanode写入文件,第一个datanode向第二个datanode写入,直到最后一个
hdfs读数据流程
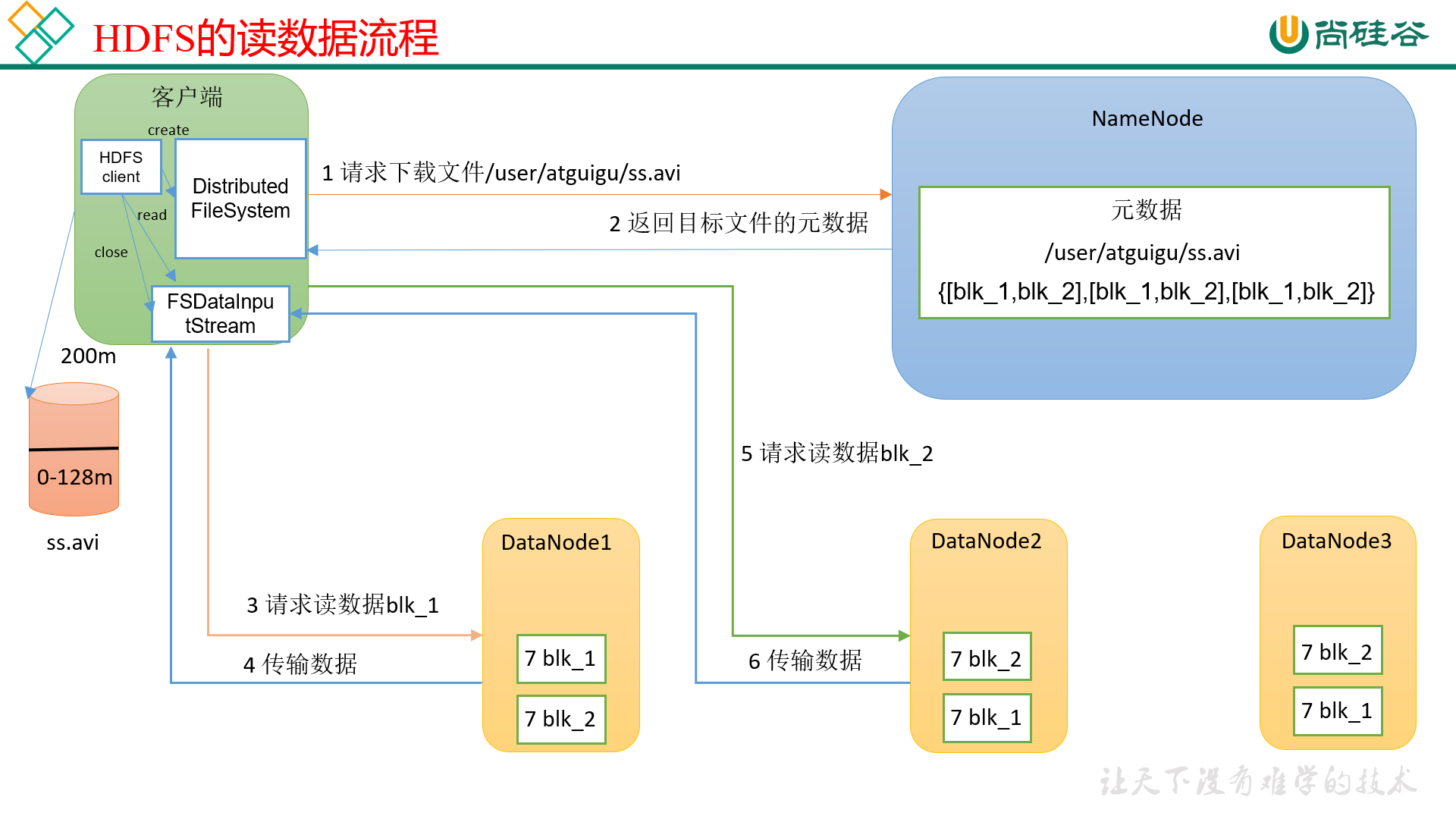
DataNode的选择会考虑最近 和 负载
-
NameNode工作机制
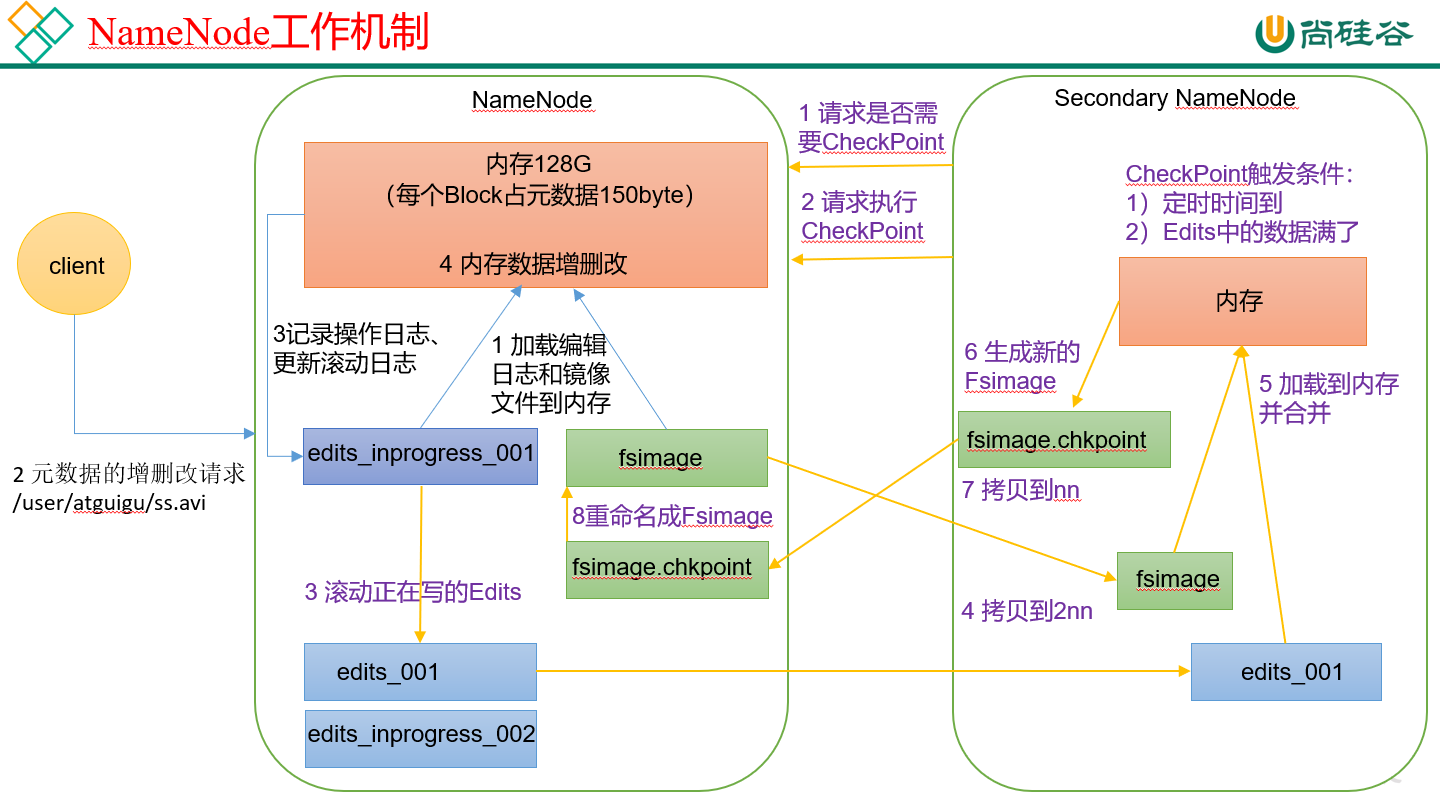
SecondaryNamenode专门用于FsImage和Edits的合并。
- 磁盘中 fsImage + edits(追加数据)= 内存中的数据
- edits相当于redo log了。
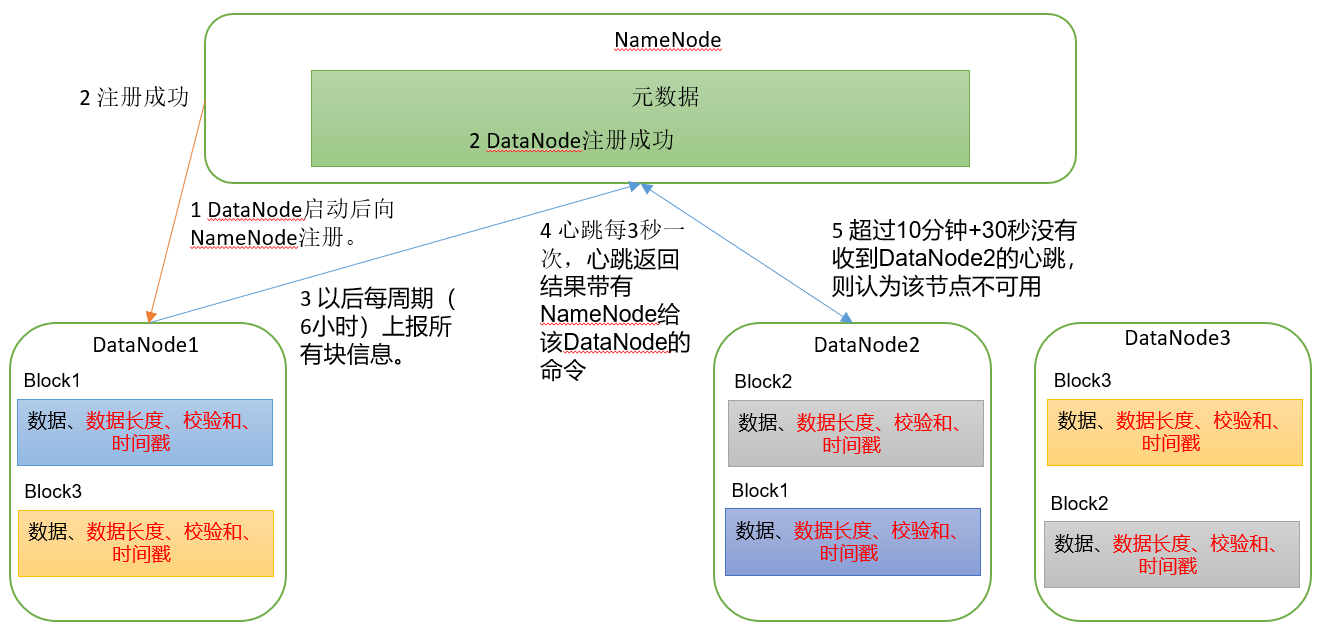
- NameNode不记录数据块在哪个DataNode。DataNode启动时汇报给NameNode。
DataNode工作机制

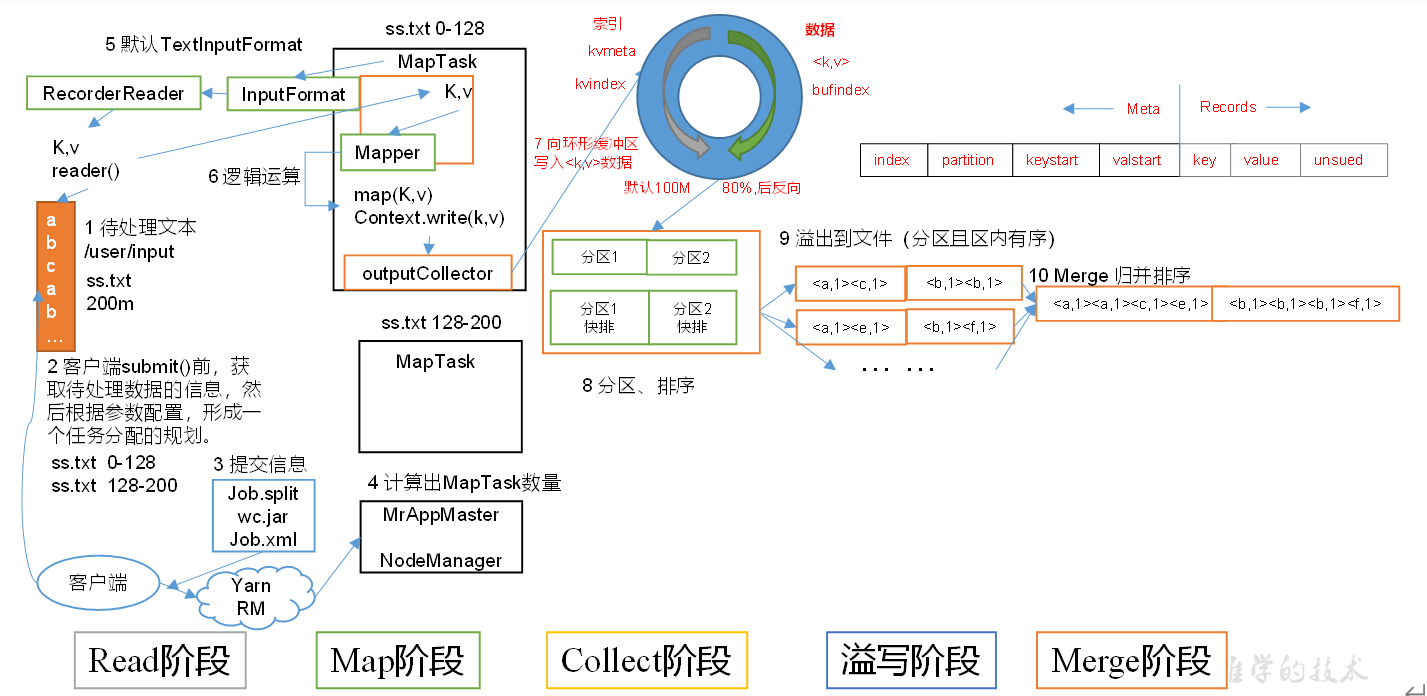
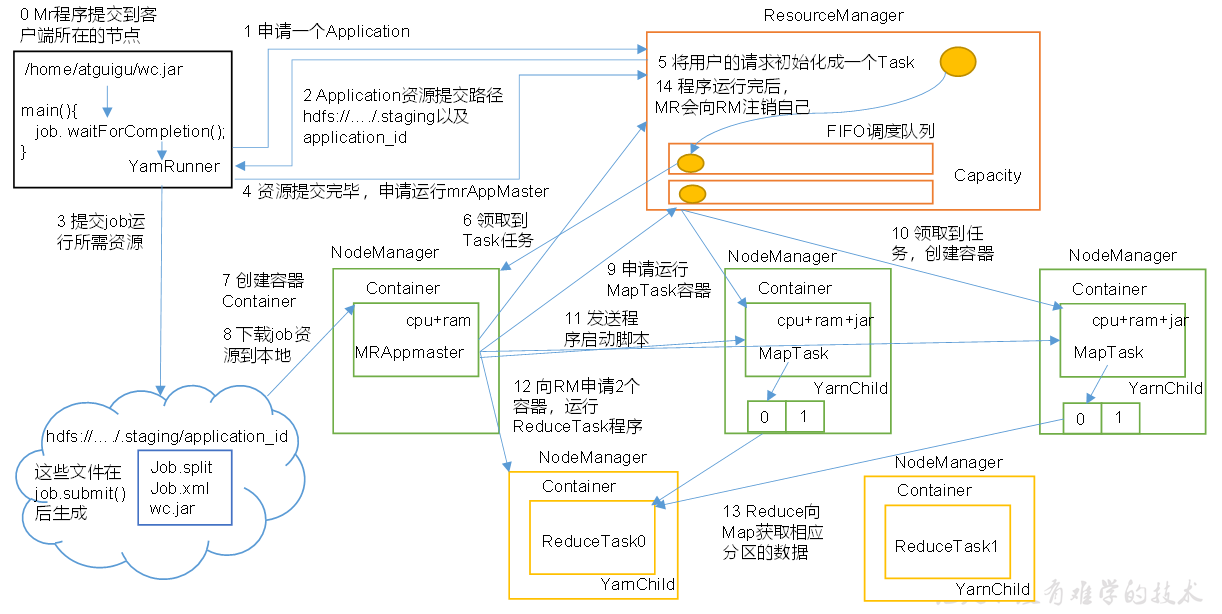
MapReduce工作流程
MapTask工作机制
ReduceTask工作机制
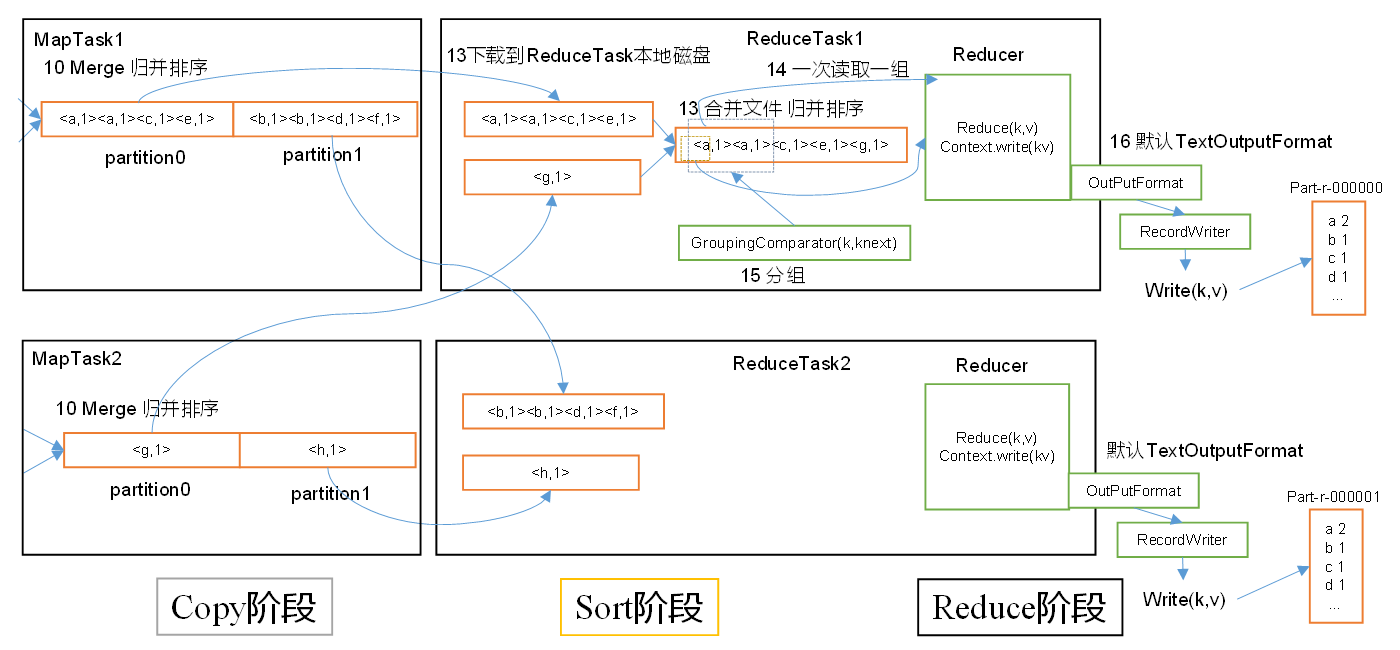
shuffle
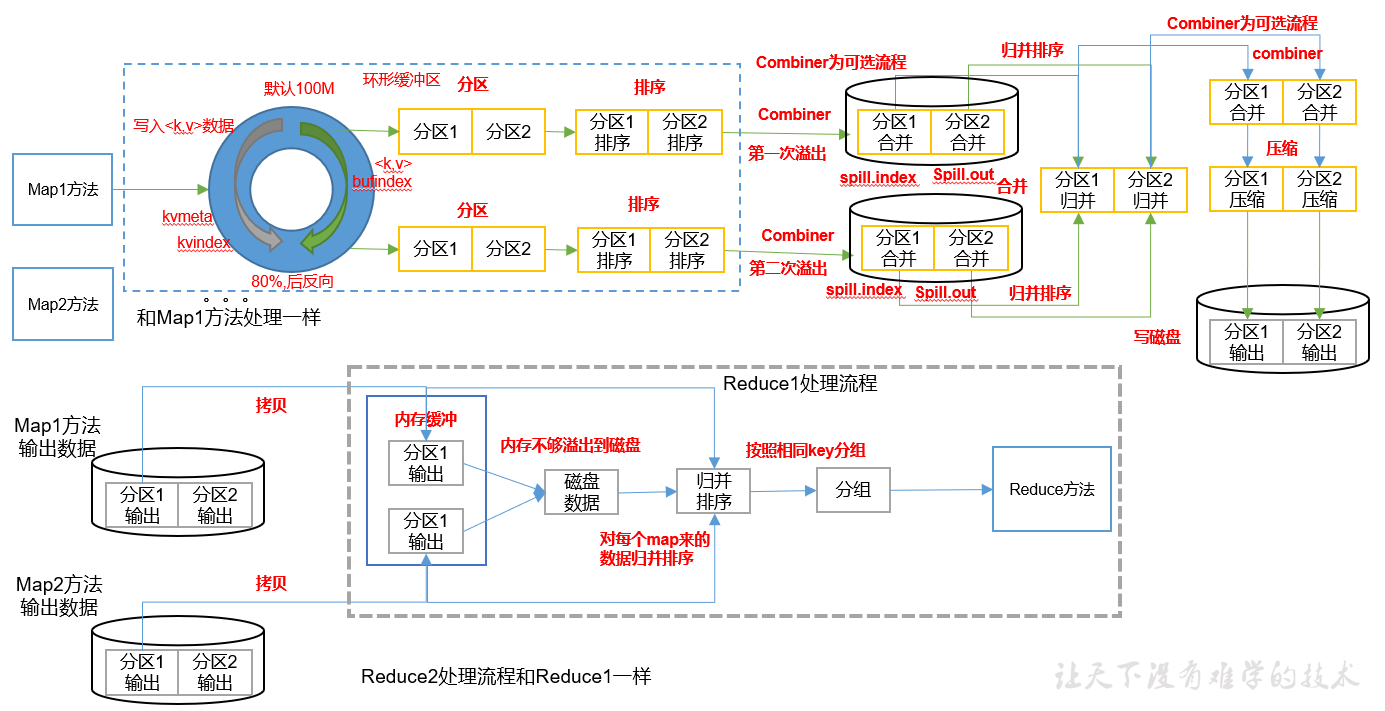
- 缓冲区,左侧存索引,右侧存数据?
- 缓冲区达到80%,反向溢写。
Partition分区

- reduceTask数量和分区数量不同
Combiner
mapTask中的局部汇总
自定义OutputFormat

Join
reduceJoin
MapJoin
- 适合一张小表,一张大表。
数据清洗etl
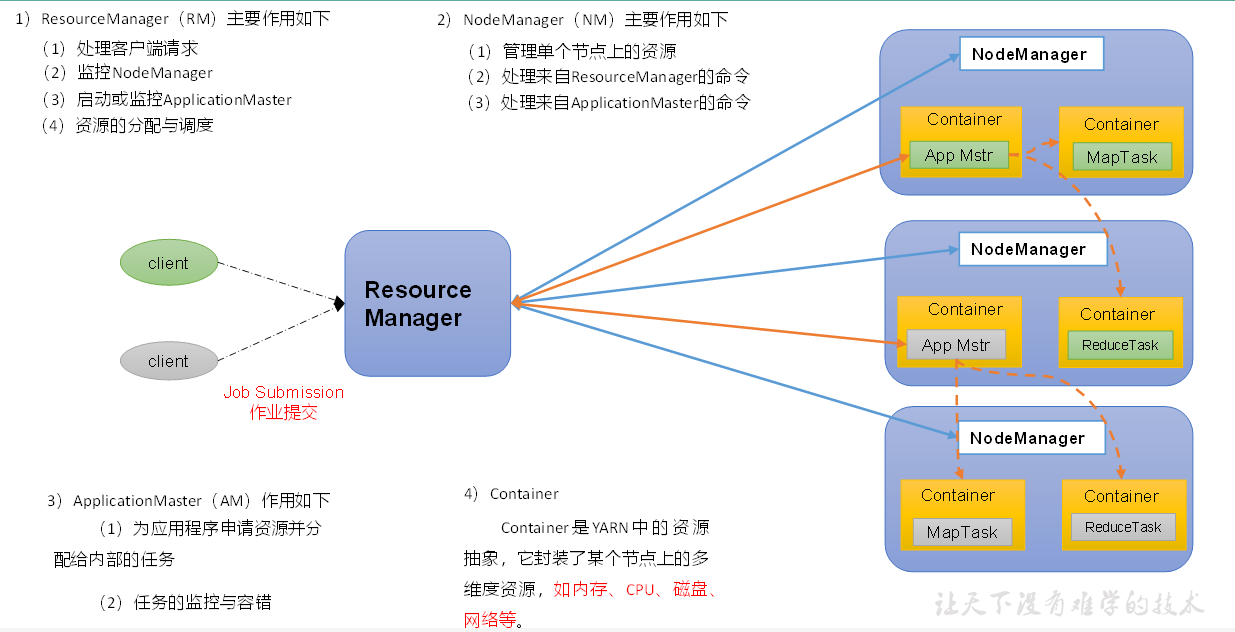
yarn

若有收获,就点个赞吧
0 人点赞
