基本数据类型与包装类
- 数值型
- 整数型:byte、short、int、long
- 浮点型:float、double
- 字符型:char
- 布尔型:boolean | 基本数据类型 | 长度 | 默认值 | | —- | —- | —- | | byte | 字节、1 byte 就是 1 个字节,8 位二进制,-128 ~ 127 | 0 | | short | 2 字节,16 位,-2^15 ~ 2^15 - 1 | 0 | | int | 4 字节,32 位,-2^31 ~ 2^31 - 1 | 0 | | long | 8 字节,64 位,-2^63 ~ 2^63 -1 | 0 | | float | 4 字节,32 位;最高位符号位,8 位指数,23 位做基数 | 0.0 | | double | 8 字节,64 位,最高位符号位,11 位做指数,52 位做基数 | 0.0 | | char | 2 字节,单一的 16 位 Unicode 字符,最小值是 ‘\u0000’(即为0),最大值是 ‘\uffff’(即为65,535),可以当整数来用,它的每一个字符都对应一个数字 | ‘\u0000’ | | boolean | | false |
缓存机制
Integer f1 = 100, f2 = 100, f3 = 150, f4 = 150;System.out.println(f1 == f2); // trueSystem.out.println(f3 == f4); // falseSystem.out.println(f1.equals(f2)); // trueSystem.out.println(f3.equals(f4)); // truepublic static Integer valueOf(int i) {if (i >= IntegerCache.low && i <= IntegerCache.high)return IntegerCache.cache[i + (-IntegerCache.low)];return new Integer(i);}
在自动装箱的时候,JVM 会缓存 -128 ~ 127 之间的 int 值,所以当该 int i >= -128 && i <= 127 时,会直接返回已缓存的 Integer 对象,否则新建一个 Integer 对象。
f1 == f2 返回 true ,是因为 Integer f1 = 100 发生了自动装箱操作。
f3 == f4 返回 false,是因为 150 不在那个缓存区间,所以返回的是新的对象,所以不相等。
三目运算符引发的空指针异常
Map<String,Boolean> map = new HashMap<String, Boolean>();Boolean b = (map!=null ? map.get("test") : false); // 抛出 NullPointerExceptionBoolean b = (map!=null ? map.get("test") : Boolean.FALSE); // 正确做法,都转换为对象,就不会发生拆箱操作
三目运算符,当第二个参数和第三个参数是基本类型和对象时,会对对象进行拆箱操作,那么 map.get(“test”) 转换为 map.get(“test”).booleanValue(),由于 map.get(“test”) 为 null,而 null.booleanValue() 就会抛出空指针异常。
正确的做法就是将三目运算符第二个参数和第三个参数的类型一致即可。
自动拆箱导致空指针异常
为什么需要包装类?
Java 是一种面向对象语言,很多地方都需要使用对象而不是基本数据类型。比如,在集合类中,我们是无法将 int 、double 等类型放进去的。因为集合的容器要求元素是 Object 类型。
为了让基本类型也具有对象的特征,就出现了包装类型,它相当于将基本类型“包装起来”,使得它具有了对象的性质,并且为其添加了属性和方法,丰富了基本类型的操作。
boolean 类型数据大小
Oracle Java 文档指出,boolean 类型数据表示一个 bit 位的信息,但是其大小并不是确定的(The boolean data type has only two possible values: true and false. Use this data type for simple flags that track true/false conditions. This data type represents one bit of information, but its “size” isn’t something that’s precisely defined.)
后来有人做了实验,定义很多个 boolean 类型数据和 int 类型数据,输出它们占用的空间,发现 int 类型数据占用内存大概是 boolean 类型数据的 4 倍,得到 boolean 类型数据大小为 1 字节的结论。
Stack Overflow 上面也有相关讨论,指出单个 boolean 类型数据占用 1 bit,而 boolean 数组每个元素占用 1 字节。
总而言之,boolean 数据类型大小定义,占用 1 bit 或 1 字节并不能一概而论,要看具体场景。
The Java™ Tutorials Java中boolean到底占几个字节 Stack Overflow 参考
void 是否是基本数据类型?
Void 类是一个不可实例化的占位符类,它持有对 Java 关键字 void 的 Class 对象的引用。
值类型或者引用类型的数据不同,表现在内存的分配方式,由于 void 不能 new 出对象,也就不能在堆中分配值,那就是一开始在栈中分配好空间了,所以这样也可以说它是基本数据类型。
不过绝大部分场合说 8 种是没有问题的。
HashMap、HashTable、ConcurrentHashMap 区别
- 继承、实现接口不同
- 初始大小、扩容倍数不同
- 线程安全
- NULL KEY,NULL VALUE 支持不同
- 计算 Hash 值的方式不同
Object 具备的方法
```java public final native Class<?> getClass()
public native int hashCode()
public boolean equals(Object obj)
protected native Object clone() throws CloneNotSupportedException
public String toString()
public final native void notify()
public final native void notifyAll()
public final native void wait(long timeout) throws InterruptedException
public final void wait(long timeout, int nanos) throws InterruptedException
public final void wait() throws InterruptedException
protected void finalize() throws Throwable {}
- String equals 实现- 检查是否为同一个对象的引用,如果是直接返回 true;- 检查是否是同一个类型,如果不是,直接返回 false;- 将 Object 对象进行转型;- 判断每个关键域是否相等。```javapublic boolean equals(Object anObject) {if (this == anObject) {return true;}if (anObject instanceof String) {String anotherString = (String)anObject;int n = value.length;if (n == anotherString.value.length) {char v1[] = value;char v2[] = anotherString.value;int i = 0;while (n-- != 0) {if (v1[i] != v2[i])return false;i++;}return true;}}return false;}
- toString()
默认返回 ToStringExample@XXXX 这种形式,其中 @ 后面的数值为散列码的无符号十六进制表示。
- clone()
clone() 是 Object 的 protected 方法,它不是 public,一个类不显式去重写 clone(),其它类就不能直接去调用该类实例的 clone() 方法。
应该注意的是,clone() 方法并不是 Cloneable 接口的方法,而是 Object 的一个 protected 方法。Cloneable 接口只是规定,如果一个类没有实现 Cloneable 接口又调用了 clone() 方法,就会抛出 CloneNotSupportedException。
使用 clone() 方法来拷贝一个对象即复杂又有风险,它会抛出异常,并且还需要类型转换,建议使用拷贝构造函数或者拷贝工厂来拷贝一个对象。
Comparator 和 Comparable
Comparable 接口用于定义对象的自然顺序,而 comparator 通常用于定义用户定制的顺序。Comparable 总是只有一个,但是可以有多个 comparator 来定义对象的顺序。
注解
元注解 - @Target:描述注解的使用范围(即:被修饰的注解可以用在什么地方)
元注解 - @Retention & @RetentionTarget:描述注解保留的时间范围(即:被描述的注解在它所修饰的类中可以被保留到何时) 。
SOURCE, // 源文件保留
CLASS, // 编译期保留,默认值
RUNTIME // 运行期保留,可通过反射去获取注解信息
元注解 - @Inherited:被它修饰的Annotation将具有继承性。如果某个类使用了被@Inherited修饰的Annotation,则其子类将自动具有该注解。
异常体系
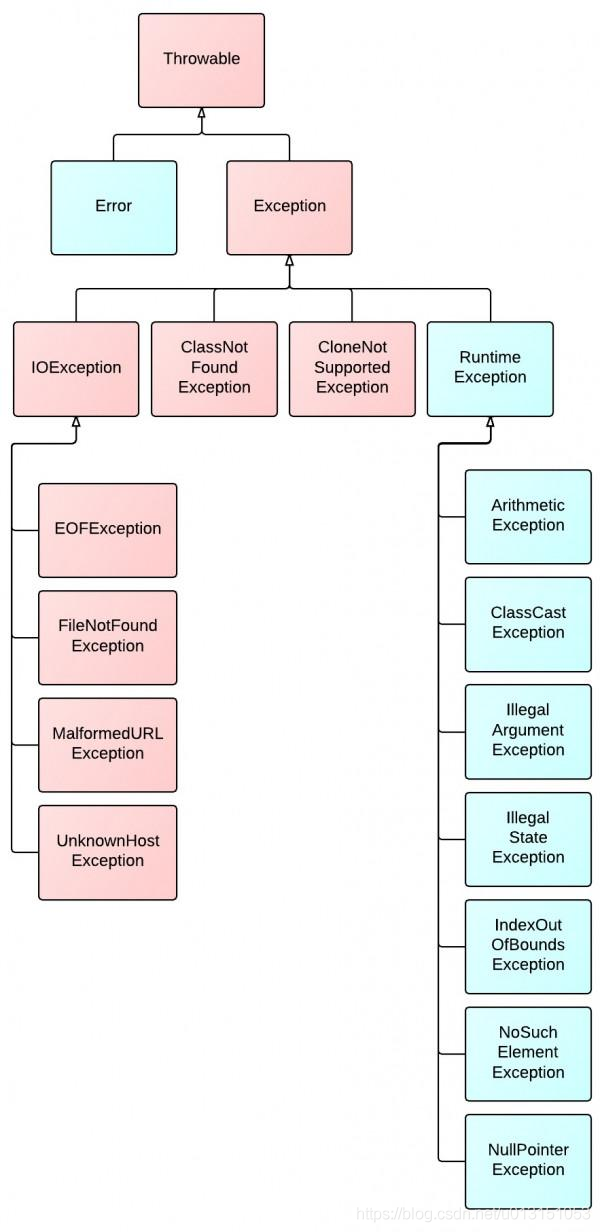
Throwable 类是 Error 和 Exception 的父类,只有是 Throwable 的实例才能被 JVM 或者 Java 语句抛出,捕获。
- Error:表示不希望被程序捕获或者是程序无法处理的错误,Error 类对象由 Java 虚拟机生成并抛出,大多数错误与代码编写者所执行的操作无关。
- Checked Exception:受检查异常,需要被 try catch 捕获或者 throws 抛出;如果不处理,IDE 会提示编译不通过。
- Runtime Exception(Unchecked Exception)extends Exception:运行时异常,由程序逻辑错误引起,程序应该尽可能的避免该类异常。
异常抛出限制
- 父类的方法没有声明异常,子类在重写该方法的时候不能声明异常;
- 子类重写父类抛出的异常方法时,可以抛出或者不抛出异常;若抛出异常,子类抛出的异常类型必须与父类方法抛出异常类型相同,或者子类抛出的异常类型是父类方法抛出异常的子类。
- 如果父类抛出了 CheckedException ,那么子类重写的方法可以抛出 RuntimeException
自定义异常
- 所有异常都必须是 Throwable 的子类。
- 如果希望写一个检查性异常类,则需要继承 Exception 类。
如果你想写一个运行时异常类,那么需要继承 RuntimeException 类。
反射
Class 类存在于 java.lang 包中,Class 类的实例,包含创建的类的类型信息,保存在 .class 文件中;Class 类只存在私有构造函数,只能由 JVM 创建和加载。
通过 class 关键字标志的类,无论创建多少个实例对象,在内存中只有一个与之对应的 Class 对象来描述其类型信息。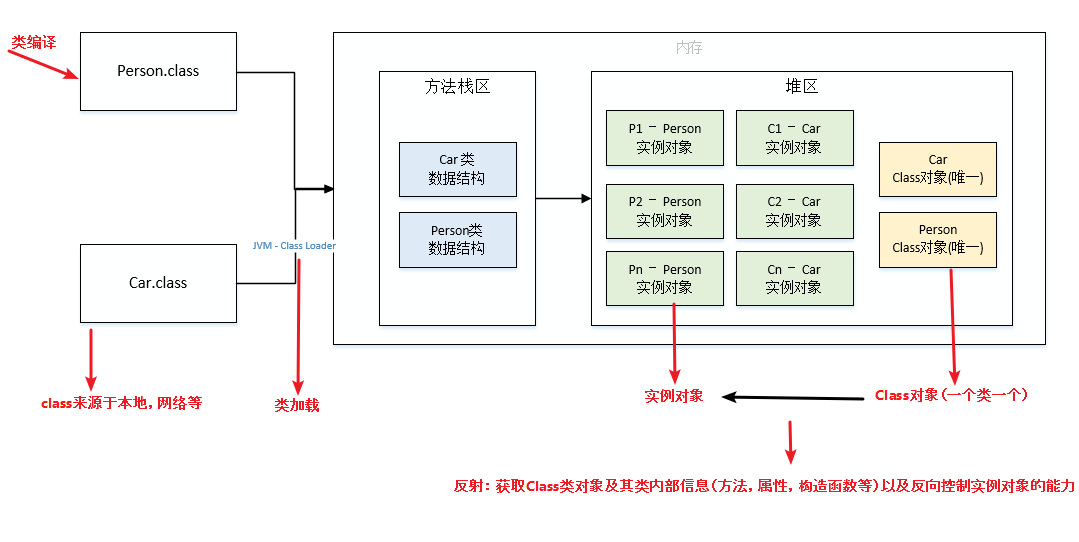
获取 Class 类对象根据类名:类名.class
- 根据对象:对象.getClass()
- 根据全限定类名:Class.forName(全限定类名)
Class 类方法
getName、getCanonicalName与getSimpleName的区别:
- getSimpleName:只获取类名
- getName:类的全限定名,jvm中Class的表示,可以用于动态加载Class对象,例如Class.forName。
- getCanonicalName:返回更容易理解的表示,主要用于输出(toString)或log打印,大多数情况下和getName一样,但是在内部类、数组等类型的表示形式就不同了。
参考:https://pdai.tech/md/java/basic/java-basic-x-reflection.html
泛型
泛型即参数化类型,将类型由原来的具体类型参数化,类似方法中的变量参数。
泛型通配符
- 限定通配符:
- E:元素
- K:键
- N:数字
- T:类型
- V:值
- S、U、V 等:多参数情况中的第 2、3、4 个类型
- 非限定通配符: ?
某些情况下,编写指定未知类型的代码很有用。问号 (?) 通配符可用于使用泛型代码表示未知类型。通配符可用于参数、字段、局部变量和返回类型。但最好不要在返回类型中使用通配符,因为确切知道方法返回的类型更安全。? extends T
描述了通配符的上界,即具体的泛型参数必须是 T 类型或者 T 的子类型
List<? extends Number> numberArray = new ArrayList<Number>(); // Number 是 Number 类型的List<? extends Number> numberArray = new ArrayList<Integer>(); // Integer 是 Number 的子类List<? extends Number> numberArray = new ArrayList<Double>(); // Double 是 Number 的子类
读取:numberArray 中可以读到 Number 对象,因为里面存放的元素必须是 Number or Number 的子类型
写入:不能写入,因为 numberArray 可以是子类型的任一类型,编译器不知道写入哪种,Double 类型的元素不能写入到 `List
? super T
描述了通配符的下届,即具体的泛型参数必须是 T 类型或者它的父类
// 在这里, Integer 可以认为是 Integer 的 "父类"List<? super Integer> array = new ArrayList<Integer>();// Number 是 Integer 的 父类List<? super Integer> array = new ArrayList<Number>();// Object 是 Integer 的 父类List<? super Integer> array = new ArrayList<Object>();
读取:只能保证从 array 读取到 Object 实例,并不能知道具体是哪个实例
写入:可以添加 Integer 或者 Integer 的子类对象到 array 中,若 T 是 Integer,那么可以无障碍地添加 Integer 或者 Integer 子类的对象到容器中,因为对象都可以向上转型为 Integer。若 T 是 Integer 的父类,那么添加的类型都可以向上转型为 Integer 的父类到容器中。
// 使用原则《Effictive Java》
// 为了获得最大限度的灵活性,要在表示 生产者或者消费者 的输入参数上使用通配符,使用的规则就是:生产者有上限、消费者有下限
1. 如果参数化类型表示一个 T 的生产者,使用 <?extendsT>;
2. 如果它表示一个 T 的消费者,就使用 <?superT>;
3. 如果既是生产又是消费,那使用通配符就没什么意义了,因为你需要的是精确的参数类型。
List<?>与 List<Object>区别
- List,原始类型,其引用变量可以添加任意类型的元素,但是编译器很难发现错误,不建议使用。
List<Object>表示可以容纳任意类型的对象,万事万物皆为 ObjectList<?>无限定通配符类型,只能包含某一种未知对象类型,?表示未知类型的泛型,它只有读的能力,并没有写的能力,因为编译器不知道放哪个子类型到集合中。
public void test(List<?> list) {Object o = list.get(0);//编译器不允许该操作// list.add("jaljal");}
泛型类
用于类的定义,通过泛型完成一组类的操作,并对外开放相同的接口,参考 容器类。
在实例化 Test 的时候,若指定 T 的具体类型那么该类型不能是基本数据类型。
public class Generic<T> {private T key;public Generic(T key){this.key = key;}public T getKey(){return key;}}Generic generic = new Generic(123);System.out.println(generic.getKey());Generic generic1 = new Generic<Integer>(123);System.out.println(generic.getKey());
泛型接口
与泛型类定义基本相同,泛型接口的实现类可以是普通的类,也可以是泛型类。
普通类必须定义的时候指定参数类型;泛型类实现泛型接口的时候,需要声明泛型参数
// 定义泛型接口public interface Test<T> {public T next();}// 普通类 指定参数类型public class TestA implements Test<String>{@Overridepublic String get() {return null;}@Overridepublic void set(String s) {}}// 泛型类 传递参数类型public class TestB<T> implements Test<T>{private T t;public TestB(T t){set(t);}@Overridepublic T get() {return t;}@Overridepublic void set(T t) {this.t = t;}}// 也可声明多个参数public class TestC<T,K,V> implements Test<T> {private T t;private K k;private V v;public TestC(T t,K k,V v){this.t = t;this.k = k;this.v = v;}@Overridepublic T get() {return t;}@Overridepublic void set(T t) {this.t = t;}}
泛型方法
使用规则
- 在方法返回值前面,声明 类型参数,用尖括号括起来,将表示这是一个泛型方法
- 类型参数只能是引用类型,不能是基本数据类型
public static < E > void printArray( E[] inputArray ){}public <E, C extends E> void testDependys(E e, C c) {} // 第二个参数必须是 E 类型或者 E 的子类型
若静态方法要使用泛型,那么静态方法必须为泛型方法
public static <T> void show(T t){}
泛型擦除
泛型值存在于编译期,代码在进入虚拟机后泛型就会会被擦除掉,这个者特性就叫做类型擦除。
当泛型被擦除后,他有两种转换方式,第一种是如果泛型没有设置类型上限,那么将泛型转化成Object 类型。
下面所示,get,set 方法是 Object,在操作的时候会 checkcast
public class ManipulatorA <T>{private T t;public void setT(T t) {this.t = t;}public T getT() {return t;}public static void main(String[] args) {ManipulatorA<String> manipulatorA = new ManipulatorA<>();manipulatorA.setT("123");System.out.println(manipulatorA.getT());}}Compiled from "ManipulatorA.java"public class fanxing.ManipulatorA<T> {public fanxing.ManipulatorA();Code:0: aload_01: invokespecial #1 // Method java/lang/Object."<init>":()V4: returnpublic void setT(T);Code:0: aload_01: aload_12: putfield #2 // Field t:Ljava/lang/Object;5: returnpublic T getT();Code:0: aload_01: getfield #2 // Field t:Ljava/lang/Object;4: areturnpublic static void main(java.lang.String[]);Code:0: new #3 // class fanxing/ManipulatorA3: dup4: invokespecial #4 // Method "<init>":()V7: astore_18: aload_19: ldc #5 // String 12311: invokevirtual #6 // Method setT:(Ljava/lang/Object;)V14: getstatic #7 // Field java/lang/System.out:Ljava/io/PrintStream;17: aload_118: invokevirtual #8 // Method getT:()Ljava/lang/Object;21: checkcast #9 // class java/lang/String24: invokevirtual #10 // Method java/io/PrintStream.println:(Ljava/lang/String;)V27: return}
第二种是如果设置了类型上限,那么将泛型转化成他的类型上限。下面的例子就只会擦除到 HasF 类型。
如下所示,get,set 都是 Number 类型,也不用转换
public class Manipulator <T extends Number>{private T t;public T getT() {return t;}public void setT(T t) {this.t = t;}public static void main(String[] args) {Manipulator manipulator = new Manipulator();manipulator.setT(123);System.out.println(manipulator.getT());}}Compiled from "Manipulator.java"public class fanxing.Manipulator<T extends java.lang.Number> {public fanxing.Manipulator();Code:0: aload_01: invokespecial #1 // Method java/lang/Object."<init>":()V4: returnpublic T getT();Code:0: aload_01: getfield #2 // Field t:Ljava/lang/Number;4: areturnpublic void setT(T);Code:0: aload_01: aload_12: putfield #2 // Field t:Ljava/lang/Number;5: returnpublic static void main(java.lang.String[]);Code:0: new #3 // class fanxing/Manipulator3: dup4: invokespecial #4 // Method "<init>":()V7: astore_18: aload_19: bipush 12311: invokestatic #5 // Method java/lang/Integer.valueOf:(I)Ljava/lang/Integer;14: invokevirtual #6 // Method setT:(Ljava/lang/Number;)V17: getstatic #7 // Field java/lang/System.out:Ljava/io/PrintStream;20: aload_121: invokevirtual #8 // Method getT:()Ljava/lang/Number;24: invokevirtual #9 // Method java/io/PrintStream.println:(Ljava/lang/Object;)V27: return}
I/O
I/O 分类
- 按传输数据方式:
字节流:以 byte 为基本单位进行,XXXStream 表示字节流
字符流:以字符为基本单位,字符又根据编码方式不同,一个字符对应不同大小的 byte。XXXReader、xxxWriter 表示字符流相关类
字节流可以处理任何类型的数据,如图片,视频等;字符流只能处理字符类型的数据。
- 按输入输出方向:
输入流(InXXX)、输出流(OutXXX)
Java 中的 I/O 种类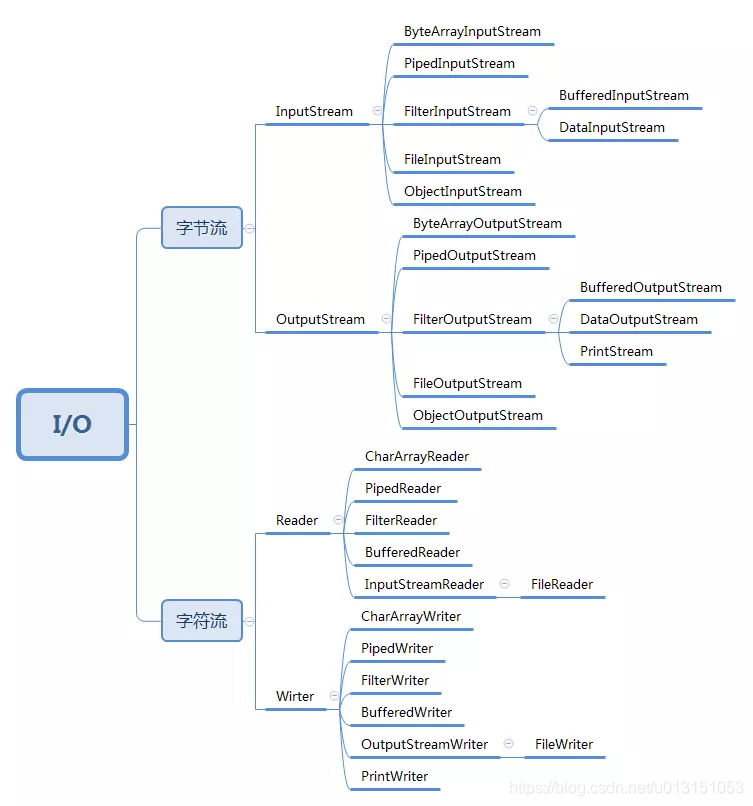
同步与异步
调用者是否主动等待调用的返回结果
同步和异步关注的是消息通信机制,即消息是怎么返回的,是直接返回还是通过回调返回。
同步和异步的区别最大在于异步的话调用者不需要等待处理结果,被调用者会通过回调等机制来通知调用者其返回结果。
阻塞与非阻塞
阻塞和非阻塞关注的是程序在等待调用结果(消息,返回值)时的状态.
阻塞调用是指调用结果返回之前,当前线程会被挂起,不能执行其它业务。调用线程只有在得到结果之后才会返回。
非阻塞调用指在不能立刻得到结果之前,该调用不会阻塞当前线程。
你妈妈让你烧水,小时候你比较笨啊,在那里傻等着水开(同步阻塞)。等你稍微再长大一点,你知道每次烧水的空隙可以去干点其他事,然后只需要时不时来看看水开了没有(同步非阻塞)。后来,你们家用上了水开了会发出声音的壶,这样你就只需要听到响声后就知道水开了,在这期间你可以随便干自己的事情,你需要去倒水了(异步非阻塞)。
聊聊同步、异步、阻塞与非阻塞
BIO、NIO 和 AIO 的区别
- BIO 就是传统的 java.io 包,它是基于流模型实现的,交互的方式是同步、阻塞方式,也就是说在读入输入流或者输出流时,在读写动作完成之前,线程会一直阻塞在那里,它们之间的调用时可靠的线性顺序。它的有点就是代码比较简单、直观;缺点就是 IO 的效率和扩展性很低,容易成为应用性能瓶颈。
- NIO 是 Java 1.4 引入的 java.nio 包,提供了 Channel、Selector、Buffer 等新的抽象,可以构建多路复用的、同步非阻塞 IO 程序,同时提供了更接近操作系统底层高性能的数
据操作方式。什么是NIO?NIO的原理是什么机制? AIO 是 Java 1.7 之后引入的包,是 NIO 的升级版本,提供了异步非堵塞的 IO 操作方式,所以人们叫它 AIO(Asynchronous IO),异步 IO 是基于事件和回调机制实现的,也就是应用操作之后会直接返回,不会堵塞在那里,当后台处理完成,操作系统会通知相应的线程进行后续的操作。
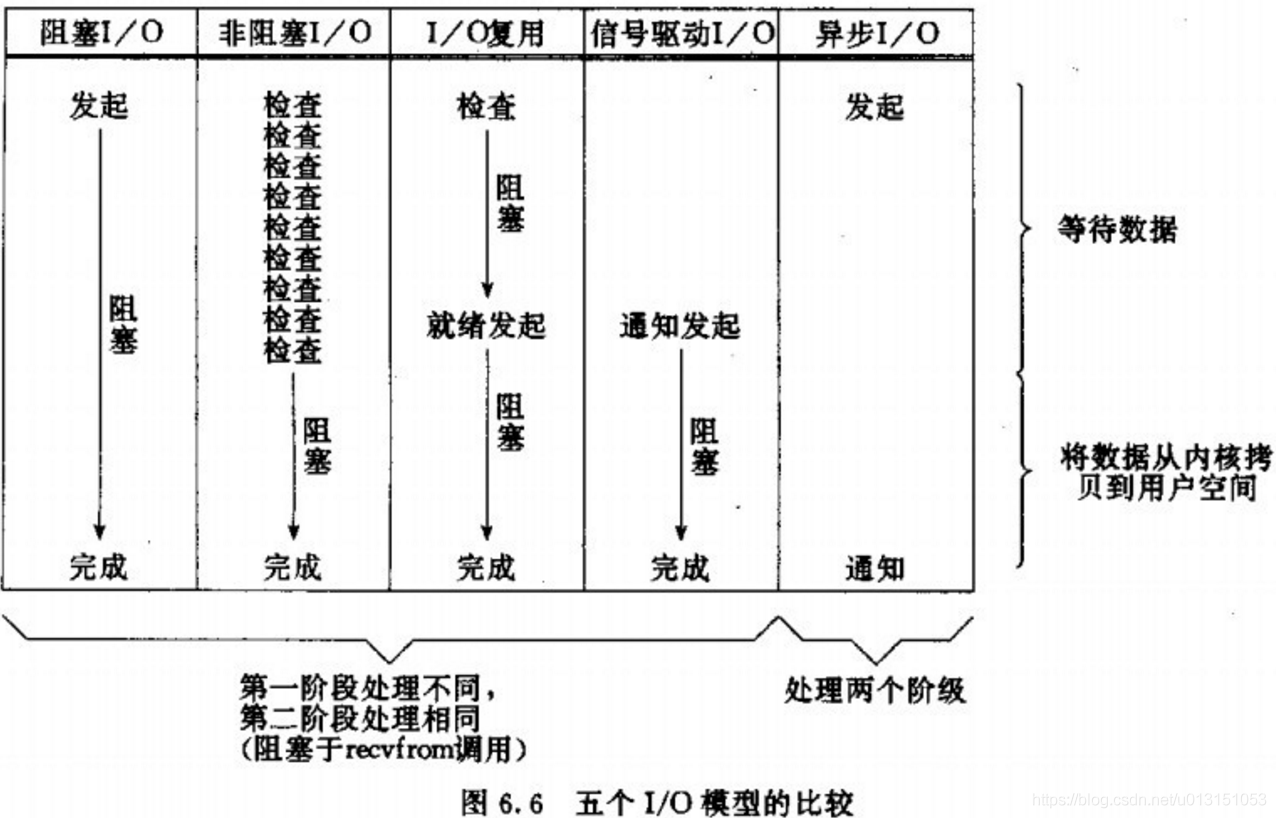
Linux 5 种 I/O 模型
Linux IO 模型中,会经历数据准备(等待数据到达并赋值到内核缓冲区),数据处理(从内核拷贝到进程)两个阶段。
Blocking IO 同步阻塞
进程阻塞在等待数据和处理数据阶段,啥也不干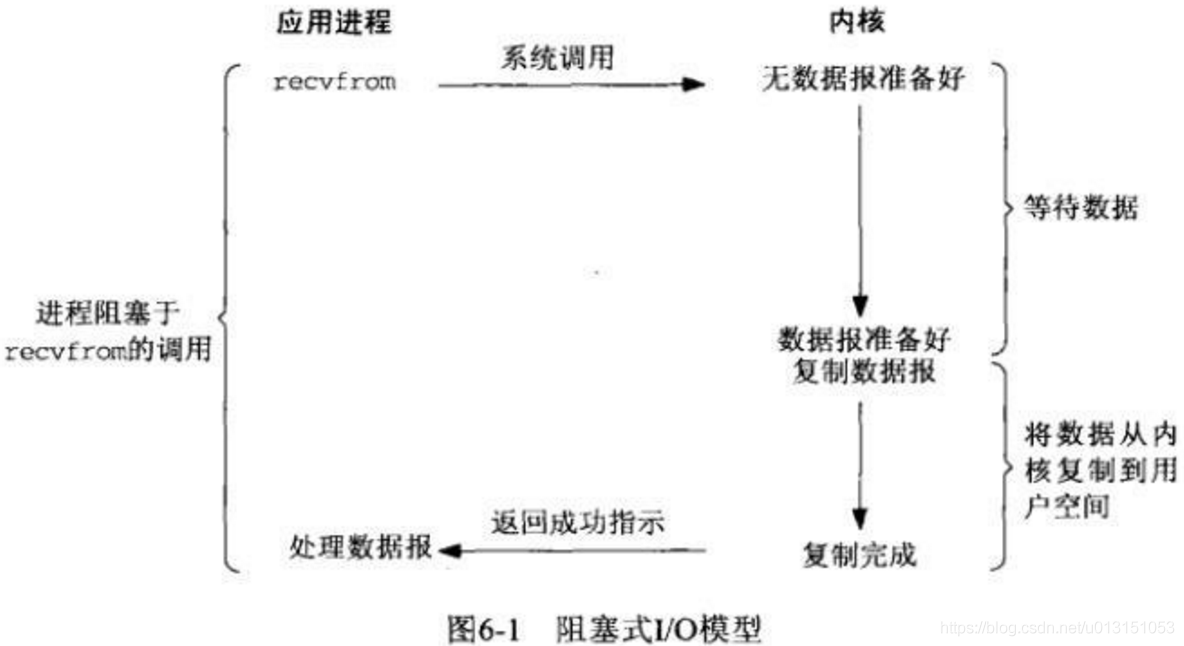
- NoBlocking IO 同步非阻塞
进程轮询等待数据过程,若轮询时数据还没准备好,可以做其它事,当数据准备好之后,就阻塞在处理数据阶段,直至返回。
当对一个非阻塞 socket 执行读操作时,如果 kernel 中的数据还没有准备好,那么它并不会 block 用户进程,而是立刻返回一个 error。用户进程需要不断地主动进行 read 操作,一旦数据准备好了,就会把数据拷贝到用户内存。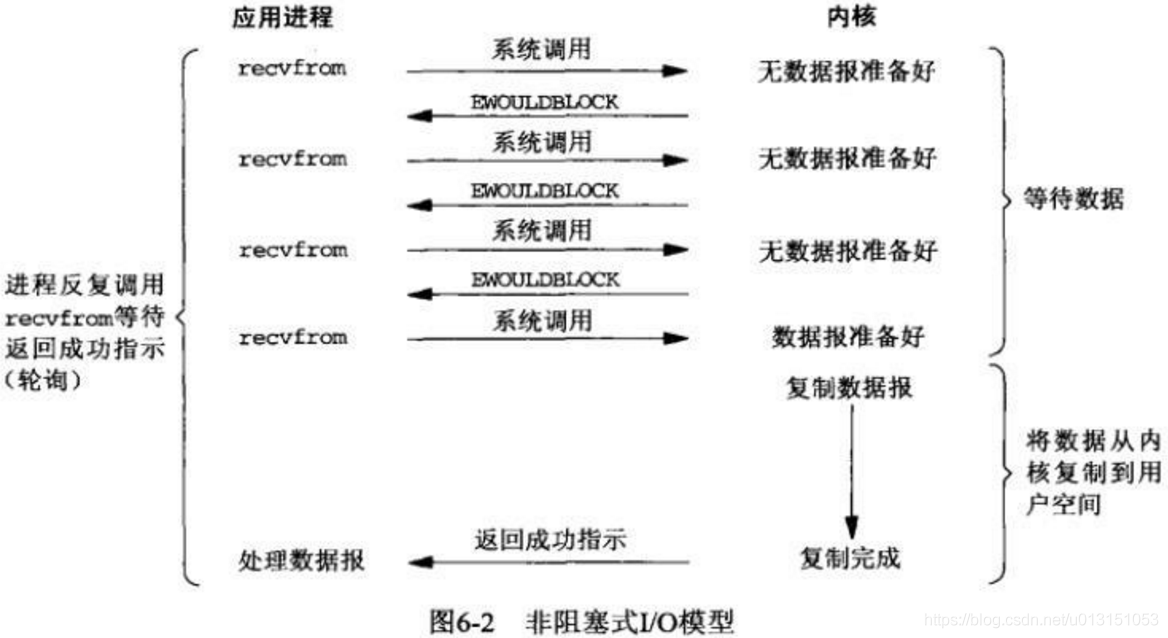
- IO Multiplexing 多路复用
内核每次轮询多个进程的等待数据过程,有一个准备好了,就执行后面的数据处理过程。
这种 IO 方式也称为 event driven IO,通过使用 select/poll/epoll 在单个进程中同时处理多个网络连接的 IO。例如,当用户进程调用了 select,那么整个进程会被 block,通过不断地轮询所负责的所有 socket,当某个 socket 的数据准备好了,select 就会返回。这个时候用户进程再调用 read 操作,将数据从 kerne l拷贝到用户进程。
在IO复用模型中,实际上对于每一个 socket,一般都设置成为 non-blocking,但是,整个用户进程其实是一直被 block 的,先是被 select 函数 block,再是被 socket IO 第二阶段 block。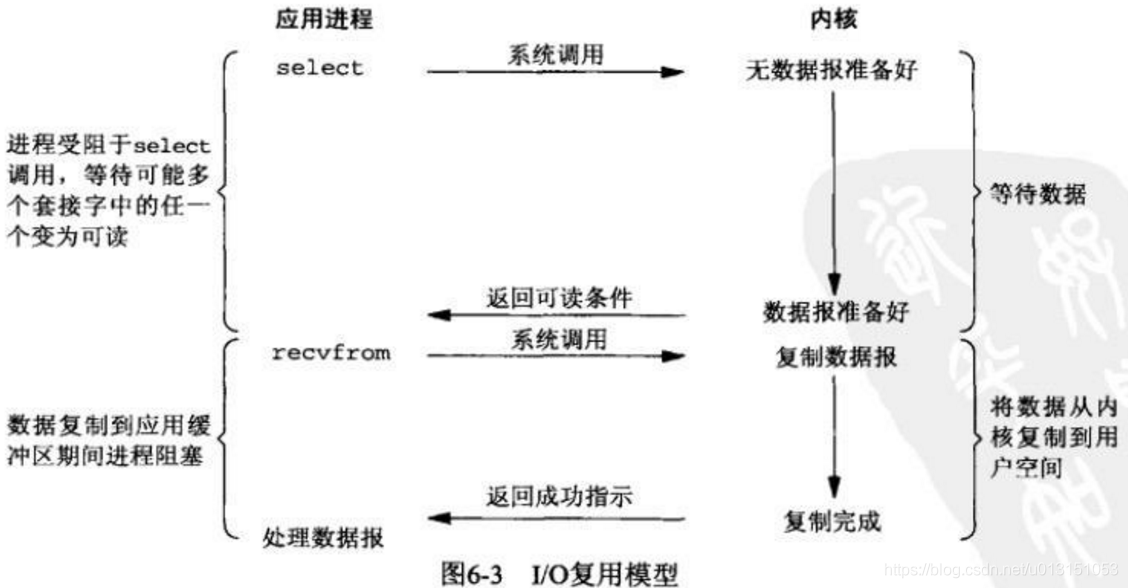
- Signal-Driven IO 信号驱动
数据准备好时,进程收到信号,然后进程进行下一步的数据处理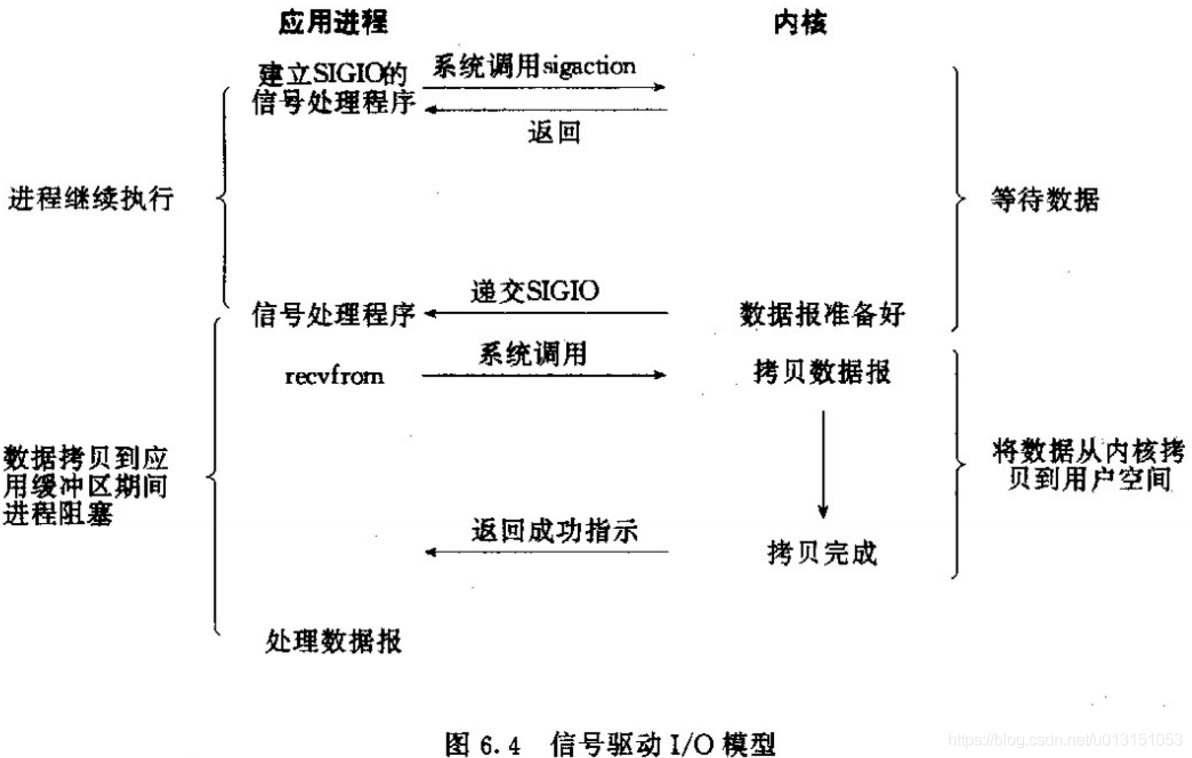
- Asynchronous IO
进程在数据准备过程中处理其它事情,当数据等待和数据处理都完成之后,内核会向进程发送通知。
在 linux 异步 IO 中,用户进程发起 read 操作之后,直接返回,去做其它的事。而另一方面,从 kernel 的角度,当它受到一个 asynchronous read 之后,kernel 会等待数据准备完成,然后将数据拷贝到用户内存,当这一切都完成之后,kernel 会给用户进程发送一个 signal,告诉它 read 操作完成了。也就是说两个阶段都不会阻塞线程。它就像是用户进程将整个 IO 操作交给了他人(kernel)完成,然后他人做完后发信号通知。在此期间,用户进程不需要去检查 IO 操作的状态,也不需要主动的去拷贝数据。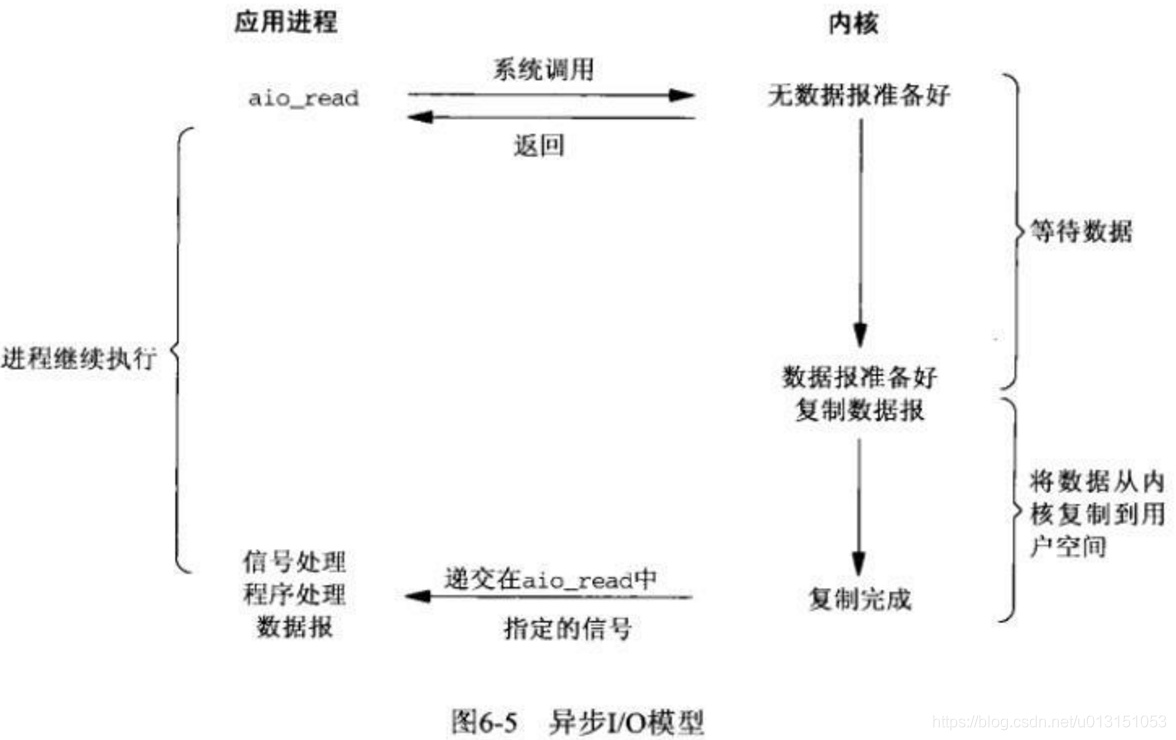
五种 IO 模型比较

若有收获,就点个赞吧
0 人点赞
