- 说一下的 Dubbo 的工作原理?注册中心挂了可以继续通信吗?
- Dubbo 支持哪些序列化协议?说一下 Hessian 的数据结构?PB 知道吗?为什么 PB 的效率是最高的?
- Dubbo 负载均衡策略和高可用策略都有哪些?动态代理策略呢?
- Dubbo 的 SPI 思想是什么?
- 如何基于 Dubbo 进行服务治理、服务降级、失败重试以及超时重试?
- 分布式服务接口的幂等性如何设计(比如不能重复扣款)?
- 分布式服务接口请求的顺序性如何保证?
- 如何自己设计一个类似 Dubbo 的 RPC 框架?
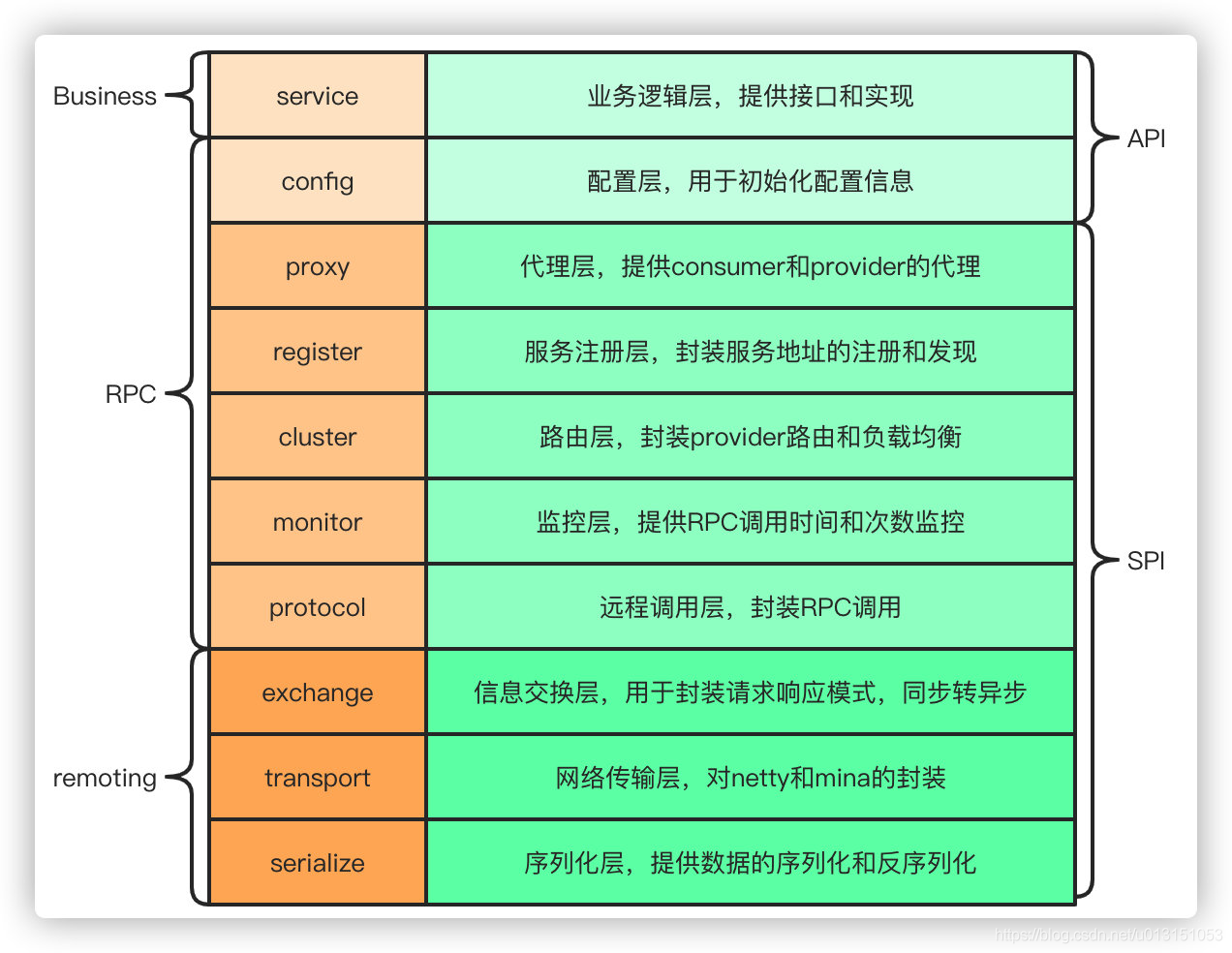
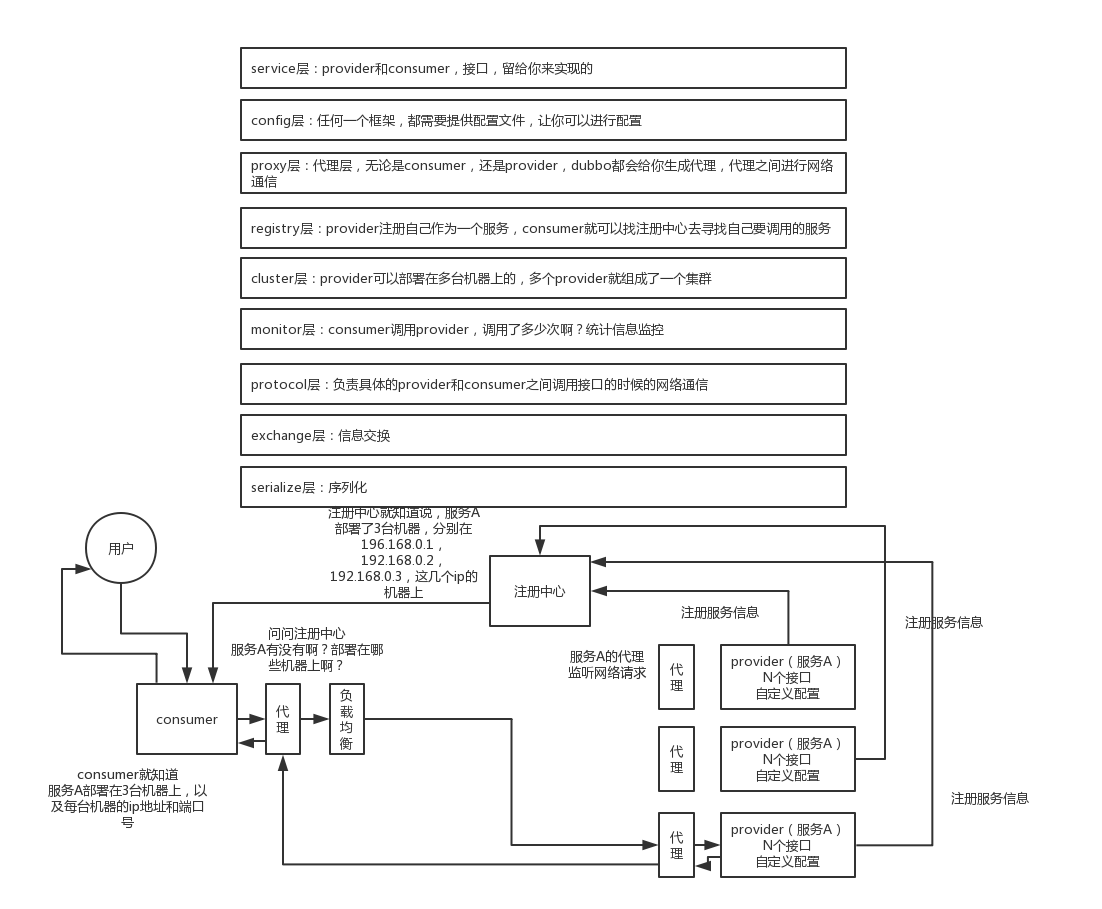
通信、序列化协议
默认就是走 dubbo 协议,单一长连接,进行的是 NIO 异步通信,基于 hessian 作为序列化协议。使用的场景是:传输数据量小(每次请求在 100kb 以内),但是并发量很高,以及服务消费者机器数远大于服务提供者机器数的情况。
Dubbo 自 2.7.5 版本开始支持 gRPC 协议,对于计划使用 HTTP/2 通信,或者想利用 gRPC 带来的 Stream、反压、Reactive 编程等能力的开发者来说, 都可以考虑启用 gRPC 协议。
负载均衡策略
- RandomLoadBalance 默认,随机调用实现负载均衡,可以对 provider 不同实例设置不同的权重,会按照权重来负载均衡,权重越大分配流量越高
- RoundRobinLoadBalance ,默认就是均匀地将流量打到各个机器上去,但是如果各个机器的性能不一样,容易导致性能差的机器负载过高
- LeastActiveLoadBalance,活跃调用数越小,表明该服务提供者效率越高,单位时间内可处理更多的请求,那么此时请求会优先分配给该服务提供者。
ConsistentHashLoadBalance,一致性 Hash 算法,相同参数的请求一定分发到一个 provider 上去,provider 挂掉的时候,会基于虚拟节点均匀分配剩余的流量,抖动不会太大。如果你需要的不是随机负载均衡,是要一类请求都到一个节点,那就走这个一致性 Hash 策略。
集群容错策略
Failover Cluster 模式 ,失败自动切换,自动重试其他机器,默认就是这个,常见于读操作。(失败重试其它机器)
- Failfast Cluster 模式,一次调用失败就立即失败,常见于非幂等性的写操作,比如新增一条记录(调用失败就立即失败)
- Failsafe Cluster 模式,出现异常时忽略掉,常用于不重要的接口调用,比如记录日志。
- Failback Cluster 模式,失败了后台自动记录请求,然后定时重发,比较适合于写消息队列这种。
- Forking Cluster 模式,并行调用多个 provider,只要一个成功就立即返回。常用于实时性要求比较高的读操作,但是会浪费更多的服务资源,可通过 forks=”2” 来设置最大并行数。
- Broadcast Cluster 模式,逐个调用所有的 provider。任何一个 provider 出错则报错(从 2.1.0 版本开始支持)。通常用于通知所有提供者更新缓存或日志等本地资源信息。
参考
https://doocs.github.io/advanced-java/#/docs/distributed-system/dubbo-operating-principle

若有收获,就点个赞吧
0 人点赞
