问题
现有数值特征的embedding方法由于其基于离线专业技术特征工程所具有的的低容量或难以离散化的特点,使得其很难捕获信息知识。
现有的数值特征的embedding方法:
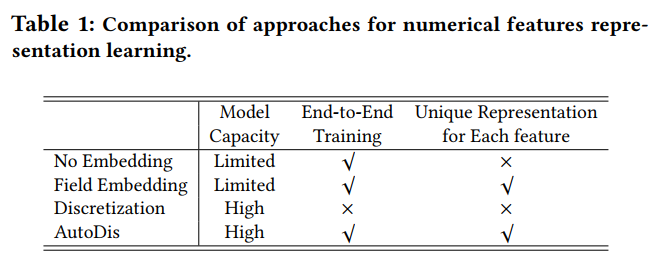
- No Embedding:直接使用原始的特征值或者其变换形式而不学习embedding。
- Field Embedding:将数值特征本身的field作为一个特征去生成embedding,而把数值本身作为权重去乘以这个embedding。即所有特征值共享这个filed的embedding,只是不同的特征值对应该embedding不同的线性变换。
- Discretization:将数值特征转换成类别特征。即将数值映射到不同的桶中。
前两种方法因为其低容量将会导致较差的性能。而最后一种方法是次优的,因为其离散化规则不能以CTR模型的最终目标进行优化。
离散化embedding存在的问题
- 这种方法一般是两阶段完成,因此没法直接针对目标任务进行优化。
- 相似的值但是会有不相似的embedding,即两个相似的特征值被划分到两个桶中。
- 不相似的值但有相似的embedding,即一个桶中包含的元素跨度比较大,但是这些元素都有着相似的embedding。
本文思路
因此,该文为CTR预测问题中的数值特征提出了一种新颖的embedding学习框架(AutoDis)。该框架具有高模型容量、端到端训练和表示唯一性等特点。AutoDis
AutoDis包含三个组成:元嵌入(meta-learning)、自动离散(automatic discretization)和聚合(aggregation)。与其余数值embedding的区别
meta-embedding
meta-embedding其实就是每一个桶的embedding。其有助于学习域内共享的全局知识。Automatic Discretization
为了捕获数值特征值和设计的meta-embedding之间的复杂联系,精心设计了一个可微地自动离散模块。
具体地,带有跳跃连接的两层NN用于将特征值离散成多个桶: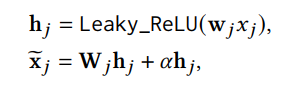
特征值的投影结果。其中,代表特征值投影到第h个桶的输出。
然后利用softmax捕获meta-embedding和特征值之间的关联: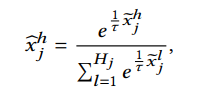
最终,简要概括: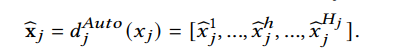
一个特征值经过离散模块的输出一个向量。该向量中的每一个值分别代表了特征值与相应桶(元embedding)之间的关联性。这种离散方式可以理解为一种软离散,相比于hard离散,该种方式没有将一个特征直接离散到一个桶里。Aggregation
采用加权平均聚合的方式将特征自动离散化得到的向量和meta-embedding element-wise相乘再相加得到该特征最终的embedding。
,其中 表示第j个field的meta-embedding矩阵,其行数代表该域对应的桶的数量。框图
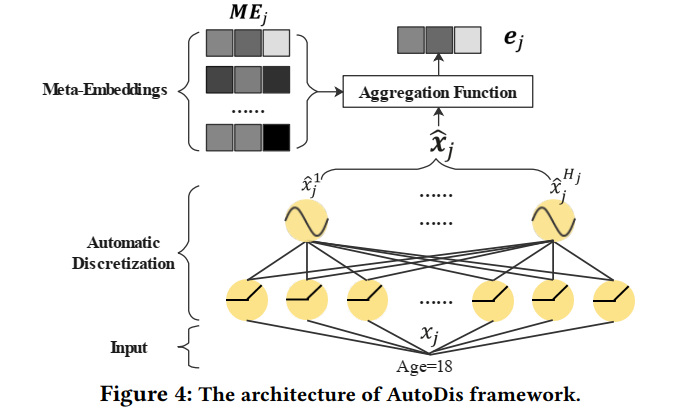
效果
选用DeepFM作为CTR模型,用不同的embedding的方法比较结果: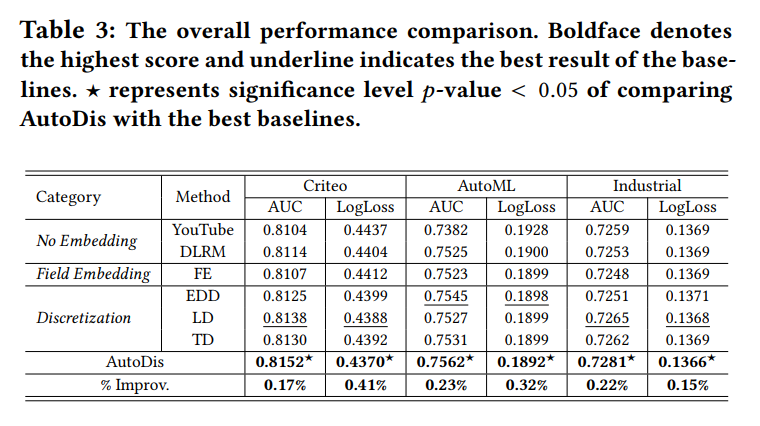
验证Autodis是一个插拔框架的实验: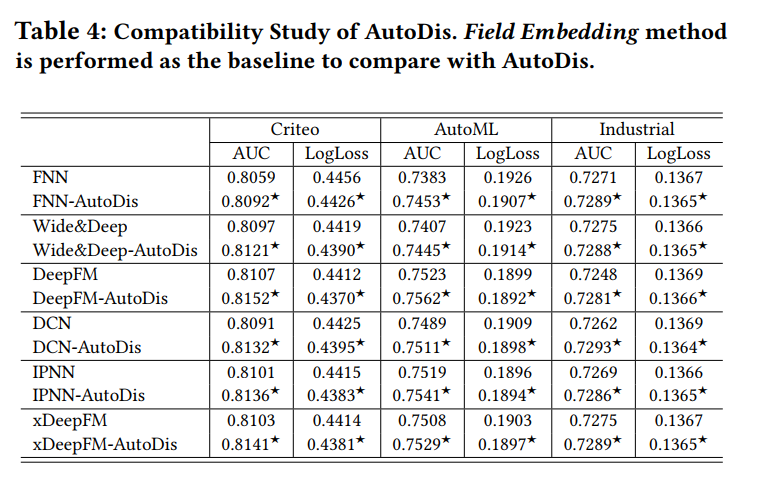

若有收获,就点个赞吧
0 人点赞
